

- GLM 4.5V VS Gemma 3 27B : Comparaison d'architecture
- GLM 4.5V VS Gemma 3 27B : Comparaison de benchmarks
- GLM 4.5V VS Gemma 3 27B : Comparaison matérielle
- GLM 4.5V VS Gemma 3 27B : Avantages et inconvénients
- GLM 4.5V VS Gemma 3 27B : Quel modèle est le mieux adapté pour les questions-réponses ?
- Novita AI : Fournisseur d'API GLM 4.5V plus rentable et stable
- Construire un outil de reconnaissance d'image simple en utilisant MCP et GLM.
Lors du choix d’un grand modèle de langage pour la réponse aux questions, les tâches multimodales ou les applications pilotées par l’IA, GLM 4.5V (par Zhipu AI) et Gemma 3 27B (par Google DeepMind) se distinguent comme des concurrents open source de premier plan. Ils diffèrent considérablement en termes d’architecture, de besoins matériels, de performances et de flexibilité de déploiement. Comprendre ces différences vous aide à choisir le modèle adapté à vos besoins, qu’il s’agisse de précision de pointe, d’un déploiement rentable ou d’une prise en charge multilingue. Vous pouvez consulter la conclusion en bas de l’article !
GLM 4.5V VS Gemma 3 27B : Comparaison d’architecture
| Caractéristique | GLM 4.5V (Zhipu GLM-4.5 Vision) | Gemma 3 (27B) |
|---|---|---|
| Développeur | Zhipu AI | Google DeepMind |
| Architecture | Transformeur à mélange d’experts (MoE) 106 milliards de paramètres au total, seulement ~12 milliards activés par entrée |
Transformeur dense 27 milliards de paramètres, tous activés pour chaque entrée |
| Capacité multimodale | Modèle vision-langage (VLM) : accepte des images + du texte en entrée, produit du texte en sortie | Multimodal : accepte des images + du texte en entrée, produit du texte en sortie |
| Nombre de paramètres | 106 milliards (épars, ~12 milliards par requête) | 27 milliards (dense, tous actifs) |
| Fenêtre de contexte | 128 000 tokens | 128 000 tokens (sur les modèles 4B/12B/27B) |
| Mécanisme d’experts | MoE : sous-réseaux spécialisés (« experts ») pour différentes tâches, acheminés par un réseau de portes | Pas de mécanisme d’experts : transformeur dense standard |
| Modes de raisonnement/réponse | Architecture « native agent » : raisonnement hybride (raisonnement complexe) et modes de réponse immédiate | Raisonnement par transformeur standard |
| Appel de fonctions/outils | Appel de fonctions intégré : peut utiliser de manière autonome des outils code/web | Pas d’appel de fonctions explicite intégré |
| Prise en charge multilingue | Multilingue (nombre non spécifié) | Prise en charge native de plus de 140 langues |
| Données d’entraînement | Pas entièrement divulguées (met l’accent sur des données multimodales à grande échelle) | 14 billions de tokens (texte, code, mathématiques, millions d’images) |
| Focus d’optimisation | Éparsité, efficacité, connaissance massive, raisonnement multimodal, utilisation d’outils | Portabilité, polyvalence, contexte long, multilingue, déploiement sur un seul accélérateur |
| Open Source | Oui | Oui |
| Applications typiques | Raisonnement complexe, compréhension multimodale, utilisation autonome d’outils (code, recherche), analyse de documents longs | Chat multilingue/multimodal, compréhension de texte et d’images, gestion de contexte long, déploiement léger |
GLM 4.5V met l’accent sur l’éparsité (MoE), la spécialisation des experts, l’efficacité de calcul et l’utilisation d’outils, ce qui le rend adapté au raisonnement multimodal complexe et aux tâches de contexte long. Gemma 3 27B présente une architecture dense, portable et multilingue avec de solides capacités de contexte long et multimodales, conçue pour être efficace et polyvalente pour un large éventail de déploiements.
GLM 4.5V VS Gemma 3 27B : Comparaison de benchmarks
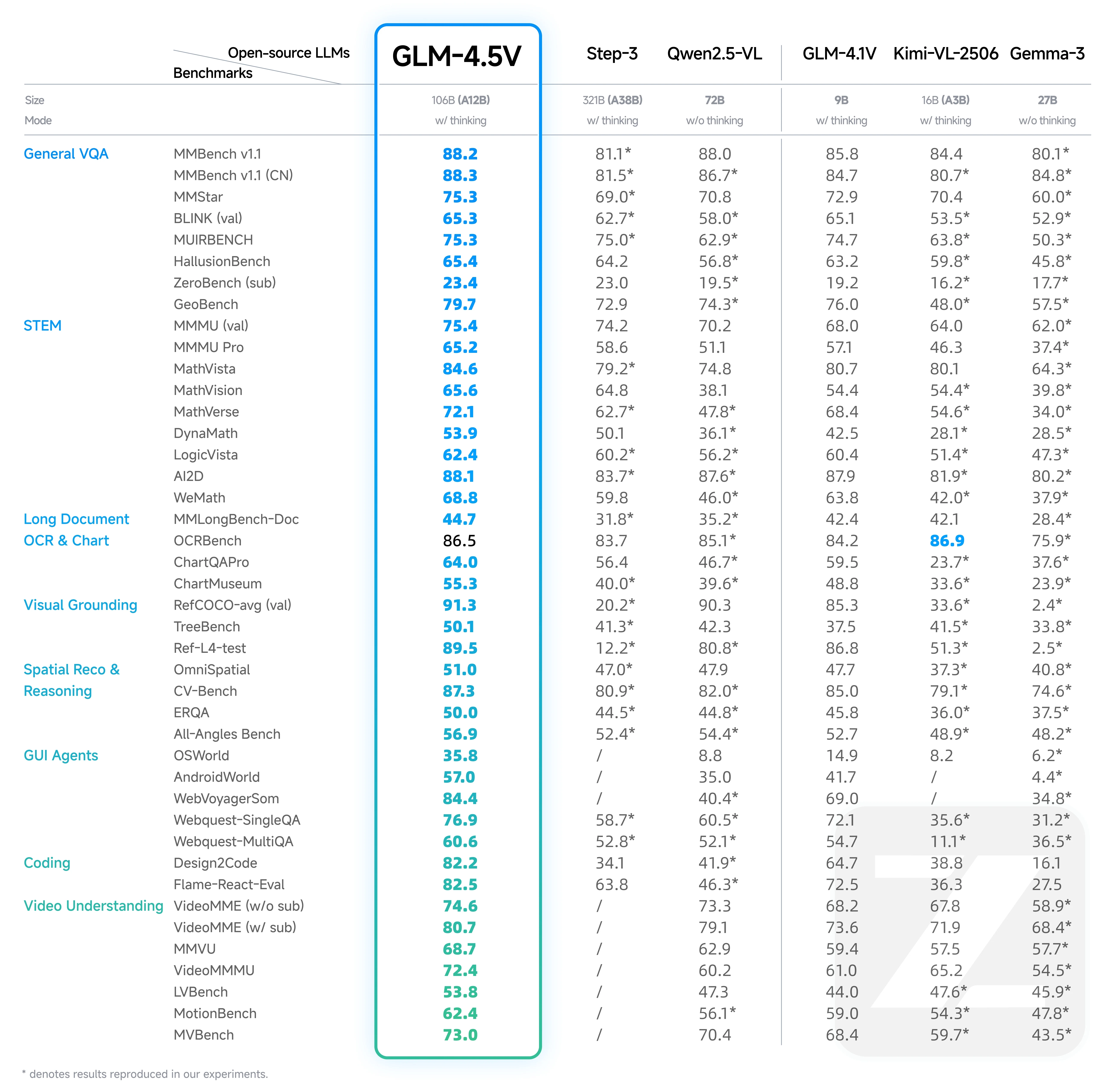
Depuis Hugging Face
Gemma-3 27B est à la traîne derrière tous les modèles de premier plan (en particulier GLM-4.5V et Qwen2.5-VL) sur presque toutes les tâches majeures, notamment les VQA, le raisonnement STEM, l’OCR, le code et la compréhension vidéo.
Même comparé à des modèles plus petits comme GLM-4.1V et Kimi-VL-2506, Gemma-3 est rarement en tête et est souvent en retard, en particulier sur les tâches multimodales avancées.
La raison principale est l’architecture de transformeur dense de Gemma-3 sans spécialisation d’experts, ce qui la rend moins compétitive sur les benchmarks de raisonnement et multimodaux exigeants.
GLM 4.5V VS Gemma 3 27B : Comparaison matérielle
Modèle GLM-4.5V :
- Paramètres du modèle : 106 milliards (mélange d’experts, environ 12 milliards actifs pendant l’inférence).
- Besoins matériels pour l’inférence :
- Recommandé : 8× GPU NVIDIA H100 (précision FP16).
- Configurations alternatives :
- 4× GPU H100 (version Air/quantifiée, FP16).
- 2× GPU H100 (quantification FP8).
- Besoins en VRAM pour l’inférence (FP16) :
- Modèle complet : Environ 16× GPU H100, chacun avec 80 Go de VRAM.
- Version Air :
- 4× GPU H100 (FP16).
- 2× GPU H100 (8 bits/FP8).
- Même si les besoins en VRAM sont inférieurs à ceux des modèles denses de plus de 100 milliards de paramètres, ils restent importants.
Modèle Gemma 3 27B :
- Paramètres du modèle : 27 milliards (dense).
- Besoins matériels pour l’inférence :
- GPU unique avec 48 Go de VRAM (précision FP16).
- GPU grand public (avec quantification 4 bits).
- Besoins en VRAM pour l’inférence (FP16) :
- GPU unique 48 Go (FP16).
- Grâce aux techniques de quantification, les besoins en VRAM du modèle Gemma 3 27B peuvent être réduits de 54 Go (BF16) à 14,1 Go (int4), ce qui lui permet de fonctionner sur des GPU grand public comme le NVIDIA RTX 3090.
GLM 4.5V VS Gemma 3 27B : Avantages et inconvénients
| Dimension | Avantages de GLM 4.5V | Inconvénients de GLM 4.5V | Avantages de Gemma 3 27B | Inconvénients de Gemma 3 27B |
|---|---|---|---|---|
| Performances | État de l’art, quasi équivalent à GPT-4 sur les benchmarks - Excelle dans le raisonnement, le codage, la compréhension |
Besoins matériels très élevés | Excellentes performances pour sa taille, rentable | Ne peut pas égaler les modèles très volumineux (ex : GLM-4.5/GPT-4) sur les tâches les plus difficiles |
| Architecture | Mélange d’experts : spécialisation, inférence par token plus rapide | Conception complexe, plus difficile à affiner/déboguer | Modèle dense, facile à utiliser/déployer | Pas de MoE/experts, moins efficace pour des domaines très divers |
| Longueur de contexte | Contexte long de 128 000 tokens pour des documents/conversations longs | Fenêtre de contexte de 128 000 tokens, idéale pour des documents/conversations longs | ||
| Capacité multimodale | Vision+langage natif, performant sur les tâches multimodales | Prend en charge nativement image/texte, multimodal prêt à l’emploi | ||
| Utilisation d’outils / Raisonnement | Utilisation d’outils intégrée, « mode de réflexion », idéal pour les agents et les questions-réponses complexes | Potentielle inadéquation d’expertise si le routage échoue | Prend en charge l’appel de fonctions, compatible avec l’API OpenAI | Moins de fonctionnalités agentiques, nécessite une orchestration externe pour l’utilisation d’outils |
GLM 4.5V VS Gemma 3 27B : Quel modèle est le mieux adapté pour les questions-réponses ?

Novita AI : Fournisseur d’API GLM 4.5V plus rentable et stable
L’API GLM-4.5V de Novita AI offre un contexte de 65,5K, avec un tarif de 0,60 $/1K tokens en entrée, 1,80 $/1K tokens en sortie, et prend en charge l’appel de fonctions et les sorties structurées.
L’API Gemma 3 27B de Novita AI offre un contexte de 32K, avec un tarif de 0,119 $/1K tokens en entrée, 0,2 $/1K tokens en sortie, et prend en charge les sorties structurées.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez GLM4.5V et Gemma 3 27B dès maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.

Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Ceci est un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Construire un outil de reconnaissance d’image simple en utilisant MCP et GLM.
Si vous souhaitez exploiter les capacités de GLM, comme la construction d’un outil de reconnaissance d’image simple pour démontrer son intégration de reconnaissance visuelle et de raisonnement, vous pouvez utiliser la fonctionnalité MCP prise en charge par Novita AI. Voici le code exemple :
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
GLM 4.5V est idéal si vous avez besoin de performances de pointe pour un raisonnement complexe, une compréhension multimodale à grande échelle, des questions-réponses sur des documents longs ou une utilisation d’outils de type agent — et que vous avez accès à des serveurs multi-GPU haut de gamme. Son architecture à mélange d’experts (MoE) lui donne un avantage sur les tâches les plus difficiles.
Gemma 3 27B excelle dans la praticité du monde réel : il est facile à déployer sur un seul GPU voire sur du matériel grand public, prend en charge plus de 140 langues, offre d’excellentes performances pour sa taille et est rentable pour la plupart des applications quotidiennes.
Pour la plupart des systèmes d’entreprise, de R&D ou de production de questions-réponses/chatbots, Gemma 3 27B est « suffisant » et beaucoup plus facile à gérer. Si vous n’avez besoin que très occasionnellement d’une précision absolument la meilleure sur les requêtes les plus difficiles (et que vous pouvez justifier les dépenses matérielles), envisagez GLM 4.5V ; sinon, Gemma reste un choix de premier plan pour l’efficacité et la polyvalence.
Dois-je passer de Gemma 3 27B à GLM 4.5V ?
Seulement si vous avez vraiment besoin de performances maximales pour des questions-réponses multi-sauts très complexes ou des tâches multimodales avancées — et que vous êtes prêt à investir dans des ressources de calcul nettement plus importantes. Pour la plupart des utilisateurs et la plupart des applications, Gemma 3 27B est déjà excellent.
Quelle est la principale différence d’architecture ?
GLM 4.5V utilise une architecture à mélange d’experts (MoE), activant des sous-réseaux spécialisés pour différentes tâches, ce qui permet une plus grande précision sur les problèmes les plus difficiles. Gemma 3 27B est un transformeur dense traditionnel — plus simple, plus portable, mais moins spécialisé.
Où GLM 4.5V est-il mieux adapté ?
Lorsque vous avez besoin de la meilleure précision possible pour des questions-réponses de niveau expert, un raisonnement complexe ou des applications vision-langue à grande échelle — et que vous disposez du matériel pour le supporter.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions en matière d’IA. API intégrées, serverless, instance GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et concrétisez votre vision de l’IA.



