

- GLM 4.5V против Gemma 3 27B: Сравнение архитектуры
- GLM 4.5V против Gemma 3 27B: Сравнение по бенчмаркам
- GLM 4.5V против Gemma 3 27B: Сравнение аппаратных требований
- GLM 4.5V против Gemma 3 27B: Плюсы и минусы
- GLM 4.5V против Gemma 3 27B: Какая модель лучше подходит для ответов на вопросы?
- Novita AI: Более экономически эффективный и стабильный провайдер API GLM 4.5V
- Создайте простой инструмент для распознавания изображений с помощью MCP и GLM
При выборе большой языковой модели для ответов на вопросы, мультимодальных задач или приложений на основе ИИ как GLM 4.5V (от Zhipu AI), так и Gemma 3 27B (от Google DeepMind) выделяются как ведущие открытые конкуренты. Они значительно отличаются по архитектуре, требованиям к оборудованию, производительности и гибкости развертывания. Понимание этих различий поможет вам выбрать подходящую модель для ваших нужд — будь то передовая точность, экономически эффективное развертывание или поддержка нескольких языков. Вы можете ознакомиться с выводом в конце статьи!
GLM 4.5V против Gemma 3 27B: Сравнение архитектуры
| Параметр | GLM 4.5V (Zhipu GLM-4.5 Vision) | Gemma 3 (27B) |
|---|---|---|
| Разработчик | Zhipu AI | Google DeepMind |
| Архитектура | Mixture-of-Experts (MoE) transformer 106B total parameters, only ~12B activated per input |
Dense Transformer 27B parameters, all activated for every input |
| Мультимодальные возможности | Vision-Language Model (VLM): accepts images + text as input, outputs text | Multimodal: accepts images + text as input, outputs text |
| Количество параметров | 106 billion (sparse, ~12B per query) | 27 billion (dense, all active) |
| Контекстное окно | 128K tokens | 128K tokens (on 4B/12B/27B models) |
| Механизм экспертов | MoE: specialist subnetworks (“experts”) for different tasks, routed by a gating network | No expert mechanism: standard dense transformer |
| Режимы рассуждений/ответов | “Agent-native” architecture: hybrid thinking (complex reasoning) and immediate response modes | Standard transformer reasoning |
| Вызов функций/инструменты | Built-in function calling: can autonomously use code/web tools | No explicit function calling built-in |
| Поддержка нескольких языков | Multilingual (number not specified) | Native support for 140+ languages |
| Обучающие данные | Not fully disclosed (emphasizes large-scale multimodal data) | 14 trillion tokens (text, code, math, millions of images) |
| Цель оптимизации | Sparsity, efficiency, massive knowledge, multimodal reasoning, tool use | Portability, versatility, long context, multilingual, single-accelerator deployment |
| Открытый исходный код | Yes | Yes |
| Типичные сценарии использования | Complex reasoning, multimodal understanding, autonomous tool use (code, search), long document analysis | Multilingual/multimodal chat, text and image understanding, long-context handling, lightweight deployment |
GLM 4.5V ориентирован на разреженность (MoE), специализацию экспертов, эффективные вычисления и использование инструментов, что делает его подходящим для сложных мультимодальных рассуждений и задач с длинным контекстом. Gemma 3 27B имеет плотную, портативную и многоязычную архитектуру с сильными возможностями работы с длинным контекстом и мультимодальностью, разработанную для эффективности и универсальности в широком диапазоне сценариев развертывания.
GLM 4.5V против Gemma 3 27B: Сравнение по бенчмаркам
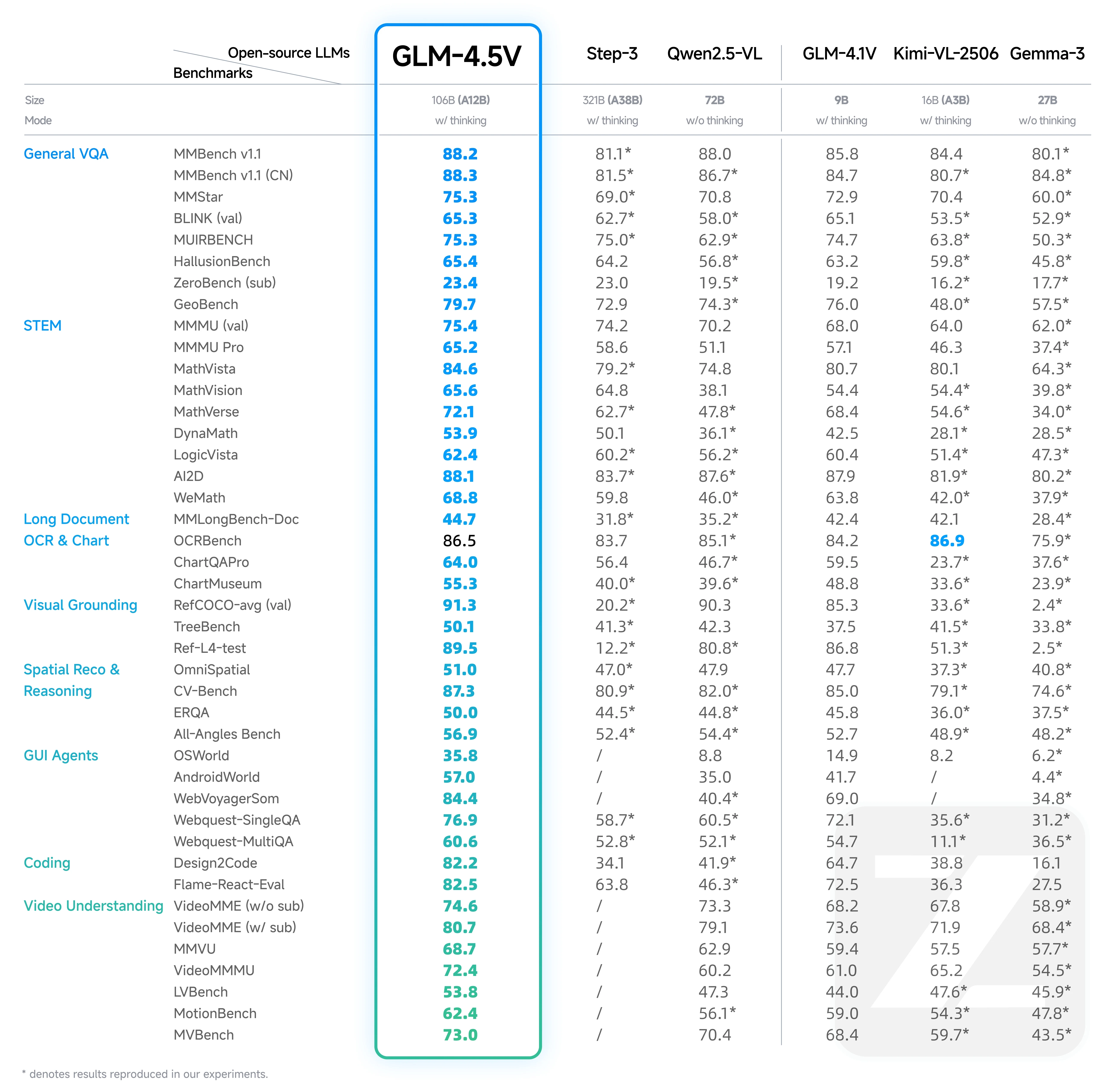
From Hugging Face
Gemma-3 27B отстает от всех топовых моделей (особенно GLM-4.5V и Qwen2.5-VL) почти по всем основным задачам, включая VQA, рассуждения в области STEM, OCR, написание кода и понимание видео.
Даже по сравнению с меньшими моделями, такими как GLM-4.1V и Kimi-VL-2506, Gemma-3 редко занимает лидирующие позиции и часто отстает, особенно в продвинутых мультимодальных задачах.
Основная причина — плотная трансформерная архитектура Gemma-3 без специализации экспертов, что делает ее менее конкурентоспособной в сложных мультимодальных и рассуждающих бенчмарках.
GLM 4.5V против Gemma 3 27B: Сравнение аппаратных требований
Модель GLM-4.5V:
- Количество параметров модели: 106 миллиардов (смесь экспертов, примерно 12 миллиардов активируется во время вывода).
- Требования к оборудованию для вывода:
- Рекомендуется: 8× NVIDIA H100 GPUs (точность FP16).
- Альтернативные конфигурации:
- 4× H100 GPUs (версия Air/квантованная, FP16).
- 2× H100 GPUs (квантование FP8).
- Требования к оперативной памяти видеокарт (VRAM) для вывода (FP16):
- Полная модель: примерно 16 графических процессоров H100, каждый с 80 ГБ VRAM.
- Версия Air:
- 4× H100 GPUs (FP16).
- 2× H100 GPUs (8-битное/FP8 квантование).
- Хотя требование к VRAM ниже, чем у плотных моделей с более чем 100 миллиардами параметров, оно остается значительным.
Модель Gemma 3 27B:
- Количество параметров модели: 27 миллиардов (плотная).
- Требования к оборудованию для вывода:
- Одна видеокарта с 48 ГБ VRAM (точность FP16).
- Потребительские видеокарты (с 4-битным квантованием).
- Требования к оперативной памяти видеокарт (VRAM) для вывода (FP16):
- Одна видеокарта на 48 ГБ (FP16).
- С помощью техник квантования требование к VRAM для модели Gemma 3 27B можно снизить с 54 ГБ (BF16) до 14,1 ГБ (int4), что позволяет запускать ее на потребительских видеокартах, таких как NVIDIA RTX 3090.
GLM 4.5V против Gemma 3 27B: Плюсы и минусы
| Параметр | Плюсы GLM 4.5V | Минусы GLM 4.5V | Плюсы Gemma 3 27B | Минусы Gemma 3 27B |
|---|---|---|---|---|
| Производительность | Уровень state-of-the-art, близкий к GPT-4 по бенчмаркам - Отличается в рассуждениях, написании кода, понимании текста |
Очень высокие требования к оборудованию | Отличная производительность для своего размера, экономически эффективная | Не может сравниться с очень большими моделями (например, GLM-4.5/GPT-4) в самых сложных задачах |
| Архитектура | Смесь экспертов: специализация, более быстрый вывод на токен | Сложная конструкция, сложнее дообучать/отлаживать | Плотная модель, простая в использовании/развертывании | Нет MoE/экспертов, менее эффективна для сильно разнородных доменов |
| Длина контекста | Длинный контекст 128K токенов для больших документов/длинных диалогов | Окно контекста 128K токенов, отлично подходит для больших документов/диалогов | ||
| Мультимодальные возможности | Нативная поддержка зрения+языка, сильные возможности в мультимодальных задачах | Нативная поддержка изображений/текста, мультимодальность из коробки | ||
| Использование инструментов / Рассуждения | Встроенное использование инструментов, «режим рассуждений», отлично подходит для агентов и сложных ответов на вопросы | Возможное несоответствие экспертизы при сбое шлюзовой сети | Поддерживает вызов функций, совместима с API OpenAI | Меньше возможностей для агентов, требуется внешняя оркестрация для использования инструментов |
GLM 4.5V против Gemma 3 27B: Какая модель лучше подходит для ответов на вопросы?

Novita AI: Более экономически эффективный и стабильный провайдер API GLM 4.5V
API GLM-4.5V от Novita AI предлагает контекст 65,5K токенов, входные запросы стоят $0,60 за 1K токенов, выходные — $1,80 за 1K токенов, поддерживается вызов функций и структурированные выводы.
API Gemma 3 27B от Novita AI предлагает контекст 32K токенов, входные запросы стоят $0,119 за 1K токенов, выходные — $0,2 за 1K токенов, поддерживаются структурированные выводы.
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Попробуйте GLM4.5V и Gemma 3 27B прямо сейчас!
Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, подходящую для ваших задач.

Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.

Шаг 4: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с LLM Novita AI. Ниже приведен пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Создайте простой инструмент для распознавания изображений с помощью MCP и GLM
Если вы хотите использовать возможности GLM — например, создать простой инструмент для распознавания изображений, чтобы продемонстрировать интеграцию визуального распознавания и рассуждений — вы можете использовать функциональность MCP, поддерживаемую Novita AI. Ниже приведен пример кода:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
GLM 4.5V идеально подходит, если вам нужна производительность уровня state-of-the-art для сложных рассуждений, крупномасштабного мультимодального понимания, ответов на вопросы по длинным документам или использования инструментов в стиле агентов — и у вас есть доступ к высокопроизводительным многопроцессорным серверам. Его архитектура смеси экспертов (MoE) дает ему преимущество в самых сложных задачах.
Gemma 3 27B выделяется практичностью в реальных условиях: ее легко развернуть на одной видеокарте или даже на потребительском оборудовании, она поддерживает более 140 языков, предлагает отличную производительность для своего размера и является экономически эффективной для большинства повседневных приложений.
Для большинства корпоративных систем, систем НИОКР или производственных систем ответов на вопросы/чат-ботов Gemma 3 27B является «достаточно хорошей» и намного проще в управлении. Если вам только изредка нужна абсолютная лучшая в своем классе точность на самых сложных запросах (и вы можете оправдать расходы на оборудование), рассмотрите GLM 4.5V; в противном случае Gemma остается лучшим выбором для эффективности и универсальности.
Стоит ли мне обновляться с Gemma 3 27B до GLM 4.5V?
Только если вам действительно нужна максимальная производительность для высокосложных многошаговых ответов на вопросы или продвинутых мультимодальных задач — и вы готовы инвестировать в значительно больше вычислительных ресурсов. Для большинства пользователей и большинства приложений Gemma 3 27B уже отлично подходит.
Каково основное различие в архитектуре?
GLM 4.5V использует архитектуру смеси экспертов (MoE), активируя специализированные подсети для разных задач, что обеспечивает большую точность в самых сложных проблемах. Gemma 3 27B является традиционным плотным трансформером — более простым, более портативным, но менее специализированным.
В каких случаях GLM 4.5V подходит лучше?
Когда вам нужна максимально возможная точность для экспертных ответов на вопросы, сложных рассуждений или крупномасштабных приложений зрения-языка — и у вас есть оборудование, которое может это поддерживать.
Novita AI — это универсальная облачная платформа, которая помогает реализовать ваши амбиции в области ИИ. Интегрированные API, бессерверные решения, GPU-инстансы — экономически эффективные инструменты, которые вам нужны. Избавьтесь от необходимости управления инфраструктурой, начните бесплатно и воплотите ваше видение ИИ в реальность.



