

Points clés
Multimodal, multilingue, contexte long : Gemma 3 27B traite le texte et les images, prend en charge plus de 140 langues et gère jusqu’à 128K tokens pour des entrées longues.
Score Elo : A obtenu un score Elo de 1339, se classant parmi les 10 meilleurs modèles mondiaux.
Compatibilité mono-GPU : Offre des performances de pointe sur un seul GPU NVIDIA H100, surpassant des concurrents nécessitant plusieurs GPU.
Accès via Novita AI : Novita AI propose une API économique et un terrain de jeu gratuit pour explorer les capacités de Gemma 3 27B — essayez-le maintenant !
Publié le 12 mars 2025, Gemma 3 27B est un ajout important à la gamme de modèles de langage open source de Google. En tant que modèle le plus volumineux de la famille Gemma 3, en dehors des variantes ajustées par instructions avec des fonctionnalités spécifiques, il vise à offrir un équilibre entre performance et accessibilité. Cet article propose un aperçu pratique et technique de Gemma 3 27B, détaillant son architecture, ses capacités, ses performances dans les benchmarks et tests pratiques, ses considérations matérielles et ses méthodes d’accès.
Qu’est-ce que Gemma 3 27B ?
Caractéristiques notables
- Support multilingue avancé : Grâce à son nouveau tokenizer, Gemma 3 est très efficace dans plus de 140 langues.
- Entrée multimodale : La capacité de traiter à la fois des images et du texte en fait un outil polyvalent pour une gamme d’applications.
- Fenêtre de contexte étendue : La capacité de 128K tokens permet de traiter des entrées longues et détaillées.
- Open source et convivial pour la communauté : Étant open source, le modèle encourage l’expérimentation communautaire et une large adoption.
Date de publication, taille du modèle, Open source
- 12 mars 2025
- 27 milliards de paramètres
Cette taille positionne Gemma 3 comme un modèle substantiel capable de gérer efficacement des tâches complexes et variées. - Modèle ouvert : Publié en tant que modèle open source par Google.
Langues prises en charge
-
Prend en charge plus de 140 langues
- Dispose d’un nouveau tokenizer conçu pour un meilleur support multilingue, le rendant très polyvalent dans les applications mondiales.
Architecture du modèle
- Technologie : Construit en utilisant les mêmes recherche et technologie qui alimentent les modèles Gemini 2.0 de Google.
- Entraînement :
- Entraîné sur 14 billions de tokens à l’aide des TPU Google.
- A utilisé le framework JAX pour un entraînement efficace et scalable.
- Techniques utilisées :
- Distillation
- Apprentissage par renforcement (y compris RLHF, RLMF, RLEF)
- Fusion de modèles
- Ces techniques améliorent les performances du modèle dans des domaines critiques tels que les mathématiques, le codage et le suivi d’instructions.
Capacité multimodale
- Multimodal : Oui
- Traite à la fois des images et du texte en entrée et génère une sortie textuelle.
- Encodeur visuel : Basé sur SigLIP.
Fenêtre de contexte
-
128K tokens
- Permet au modèle de traiter et de comprendre de grandes quantités d’informations pour des tâches sophistiquées.
- Détails du pré-entraînement :
- Initialement pré-entraîné avec des séquences de 32k, puis augmenté à 128k.
- Obtenu via des ajustements des encodages positionnels à l’aide de RoPE (Rotary Positional Embeddings) .
Précision de quantification
-
Précision d’entraînement par défaut : bfloat16
- Note de performance : Les modèles fonctionnent mieux en bfloat16, et la qualité peut se dégrader avec d’autres précisions.
-
Options de quantification :
- Expériences communautaires avec des niveaux de quantification tels que Q8 gguf quant, EXL2 et IQ4_XS pour optimiser l’utilisation de la VRAM.
| Niveau de précision | Poids uniquement (Go) | Poids + KV Caching (Go) |
|---|---|---|
| bf16 (Brut) | 54.0 | 72.7 |
| INT4 | 14.1 | 32.8 |
| INT4 (blocs=32) | 15.3 | 34.0 |
| SFP8 | 27.4 | 46.1 |
Benchmark de Gemma 3 27B
Performance en chat
Gemma 3 27B a démontré des capacités exceptionnelles dans les évaluations récentes, obtenant un score Elo de 1339 sur le LMSys Chatbot Arena. Cette performance le place parmi les 10 meilleurs modèles, y compris les modèles propriétaires leaders, o1-preview, et souligne sa force dans les évaluations de préférence humaine. De plus, Gemma 3 27B atteint ce score élevé tout en ne nécessitant qu’un seul GPU NVIDIA H100, contrairement à ses concurrents qui dépendent de jusqu’à 32 GPU pour des performances similaires.
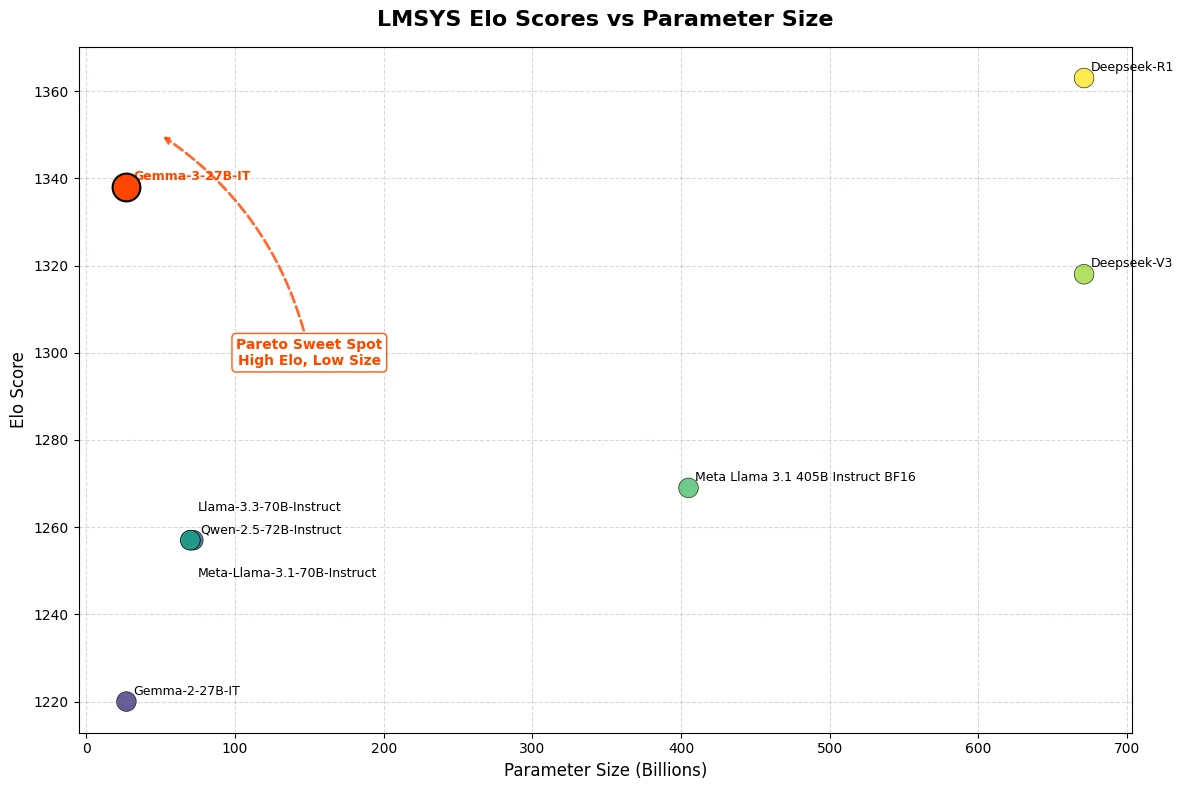
De Hugging Face
Performances dans des benchmarks spécifiques
La version ajustée par instructions, Gemma 3 27B IT, a obtenu des résultats compétitifs dans une gamme d’évaluations, rivalisant souvent avec les modèles Gemini fermés :
| Benchmark | Score | Description |
|---|---|---|
| MMLU-Pro | 67.5 | Performance solide en compréhension du langage multitâche. |
| LiveCodeBench | 29.7 | Succès modéré dans les défis de codage en direct. |
| Bird-SQL | 54.4 | Résultats compétitifs en génération et compréhension de requêtes SQL. |
| GPQA Diamond | 42.4 | Performance solide en réponse à des questions générales. |
| MATH | 69.0 | Excelle dans la résolution de problèmes mathématiques complexes. |
| FACTS Grounding | 74.9 | Excellent ancrage factuel et précision dans les tâches basées sur la connaissance. |
| MMMU | 64.9 | Performance solide dans les tâches de compréhension multimodale. |
| SimpleQA | 10.0 | Performance inférieure dans les questions de base factuelles, laissant place à l’amélioration. |
Configuration matérielle requise pour Gemma 3 27B
Gemma 3 27B est décrit comme le « modèle le plus performant que vous pouvez exécuter sur un seul GPU » !
De Google
| Configuration | VRAM nécessaire | Notes |
|---|---|---|
| Déploiement cloud | Environ 80 Go de VRAM (mono/multi-GPU) | Les GPU A100 ou H100 sont recommandés pour des performances optimales en cloud. Ou RTX 4090 24 Go (x3) |
| Apple Silicon | Gemma 3 4B pris en charge via mlx-vlm | Gemma 3 4B bénéficie d’un support dès le premier jour dans mlx-vlm, une bibliothèque open source pour exécuter des modèles vision-langage sur les appareils Apple Silicon, y compris les Mac et les iPhones. |
Test de Gemma 3 27B
Code
Prompt : Créez une simulation JavaScript d’une sphère 3D en rotation composée d’alphabets. Les lettres les plus proches doivent être d’une couleur plus vive, tandis que les plus éloignées doivent apparaître en gris.
Sortie : Il semble que le modèle n’ait pas entièrement suivi la consigne. Au lieu de cela, il a généré un anneau tournant avec des alphabets. De plus, les deux premières prévisualisations ont échoué en raison d’une luminosité insuffisante.

Raisonnement
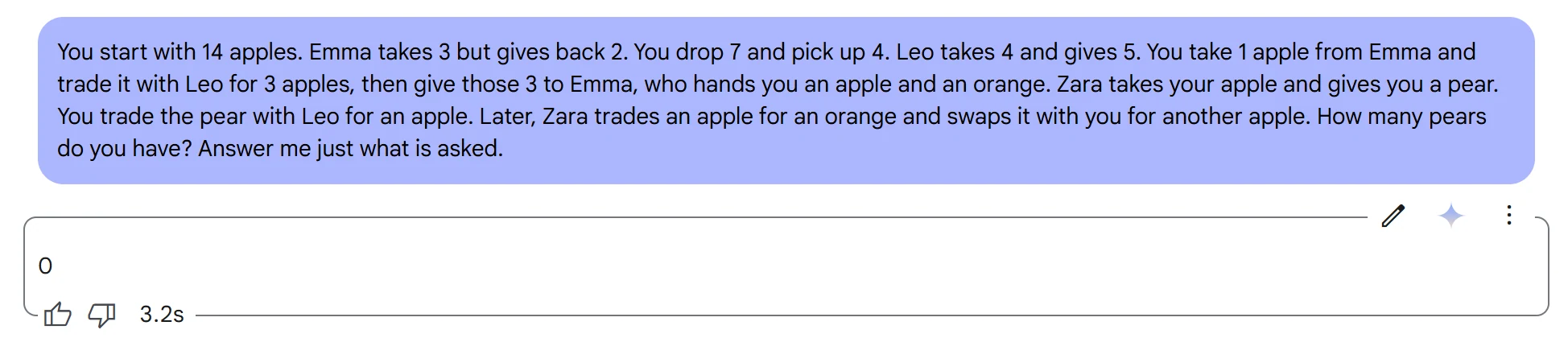
Prompt : Vous commencez avec 14 pommes. Emma en prend 3 mais en redonne 2. Vous en laissez tomber 7 et en ramassez 4. Leo en prend 4 et en donne 5. Vous prenez 1 pomme à Emma et l’échangez avec Leo contre 3 pommes, puis vous donnez ces 3 à Emma, qui vous donne une pomme et une orange. Zara prend votre pomme et vous donne une poire. Vous échangez la poire avec Leo contre une pomme. Plus tard, Zara échange une pomme contre une orange et l’échange avec vous contre une autre pomme. Combien de poires avez-vous ? Répondez uniquement à la question.
Sortie : En quelques secondes, il a analysé efficacement tous les scénarios et calculé avec précision le nombre total de poires.
Analyse d’image
Prompt : Dites-moi combien de fois le score Elo a augmenté de Gemma 2 27B à Gemma 3 27B ?
De Google
Sortie : A identifié correctement les nombres mais n’a pas calculé les multiples comme demandé dans la consigne ; n’a calculé que la différence.
D’après l’image, voici le calcul :
- Score Elo de Gemma 2 27B : 1220
- Score Elo de Gemma 3 27B : 1338
Augmentation : 1338 - 1220 = 118
Le score Elo a augmenté de 118 points de Gemma 2 27B à Gemma 3 27B.
Comment accéder à Gemma 3 27B ?
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Essayez la démo de Gemma 3 27B maintenant !
Étape 2 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 3 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En vous rendant sur la page « Settings », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 4 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "google/gemma-3-27b-it"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Salut !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Gemma 3 27B est un puissant modèle open source de Google, offrant un fort raisonnement, des capacités multimodales, un support multilingue, et une intégration facile avec des plateformes comme Hugging Face, tout en fonctionnant sur du matériel grand public.
Questions fréquentes
Combien de paramètres a Gemma 3 27B ?
Gemma 3 27B a 27 milliards de paramètres.
Gemma 3 27B est-il multimodal ?
Oui, il prend en charge les entrées d’images et de texte.
Quel matériel est recommandé pour exécuter Gemma 3 27B ?
Pour une utilisation locale, un GPU avec au moins 24 Go de VRAM est recommandé, plus de VRAM étant bénéfique pour des tailles de contexte plus grandes. Il peut également être déployé sur des plateformes cloud comme Hugging Face Inference Endpoints avec diverses options GPU. Ou vous pouvez choisir une API efficace comme Novita AI pour l’utiliser !
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



