

Puntos clave
Multimodal, multilingüe, contexto largo: Gemma 3 27B procesa texto e imágenes, admite más de 140 idiomas y maneja hasta 128K tokens para entradas largas.
Puntuación Elo: Logró una puntuación Elo de 1339, situándose entre los 10 mejores modelos a nivel mundial.
Compatibilidad con una sola GPU: Ofrece un rendimiento superior en una sola GPU NVIDIA H100, superando a competidores que requieren múltiples GPUs.
Acceso en Novita AI: Novita AI ofrece una API rentable y un playground gratuito para explorar las capacidades de Gemma 3 27B—¡pruébalo ahora!
Publicado el 12 de marzo de 2025, Gemma 3 27B es una incorporación significativa a la oferta de modelos de lenguaje grandes de código abierto de Google. Como el modelo más grande de la familia Gemma 3, además de las variantes ajustadas por instrucciones con funcionalidades específicas, busca brindar un equilibrio entre rendimiento y accesibilidad. Este artículo ofrece una visión práctica y técnica de Gemma 3 27B, detallando su arquitectura, capacidades, rendimiento en benchmarks y pruebas prácticas, consideraciones de hardware y métodos de acceso.
¿Qué es Gemma 3 27B?
Características destacadas
- Soporte multilingüe avanzado: Con su nuevo tokenizador, Gemma 3 es altamente efectivo en más de 140 idiomas.
- Entrada multimodal: La capacidad de procesar tanto imágenes como texto lo convierte en una herramienta versátil para una variedad de aplicaciones.
- Ventana de contexto extendida: La capacidad de 128K tokens permite manejar entradas extensas y detalladas.
- Código abierto y orientado a la comunidad: Al ser de código abierto, el modelo fomenta la experimentación comunitaria y una adopción amplia.
Fecha de lanzamiento, tamaño del modelo, Código abierto
- 12 de marzo de 2025
- 27 mil millones de parámetros
Este tamaño posiciona a Gemma 3 como un modelo sustancial capaz de manejar tareas complejas y diversas de manera efectiva. - Modelo abierto: Publicado como modelo de código abierto por Google.
Idiomas compatibles
-
Admite más de 140 idiomas
- Cuenta con un nuevo tokenizador diseñado para un mejor soporte multilingüe, lo que lo hace muy versátil en aplicaciones globales.
Arquitectura del modelo
- Tecnología: Construido con la misma investigación y tecnología que impulsan los modelos Gemini 2.0 de Google.
- Entrenamiento:
- Entrenado con 14 billones de tokens usando TPUs de Google.
- Aprovechó el Framework JAX para un entrenamiento eficiente y escalable.
- Técnicas utilizadas:
- Destilación
- Aprendizaje por refuerzo (incluyendo RLHF, RLMF, RLEF)
- Fusión de modelos
- Estas técnicas mejoran el rendimiento del modelo en áreas críticas como matemáticas, codificación y seguimiento de instrucciones.
Capacidad multimodal
- Multimodal: Sí
- Procesa imágenes y texto como entrada y genera salida de texto.
- Codificador de visión: Basado en SigLIP.
Ventana de contexto
-
128K tokens
- Permite al modelo procesar y comprender grandes cantidades de información para tareas sofisticadas.
- Detalles del preentrenamiento:
- Inicialmente preentrenado con secuencias de 32k y luego escalado a 128k.
- Logrado mediante ajustes en las incrustaciones posicionales usando RoPE (Rotary Positional Embeddings).
Precisión de cuantización
-
Precisión de entrenamiento predeterminada: bfloat16
- Nota de rendimiento: Los modelos funcionan mejor con bfloat16, y la calidad puede degradarse con otras precisiones.
-
Opciones de cuantización:
- Experimentos comunitarios con niveles de cuantización como Q8 gguf quant, EXL2 e IQ4_XS para optimizar el uso de VRAM.
| Nivel de precisión | Solo pesos (GB) | Pesos + almacenamiento en caché KV (GB) |
|---|---|---|
| bf16 (sin procesar) | 54.0 | 72.7 |
| INT4 | 14.1 | 32.8 |
| INT4 (bloques=32) | 15.3 | 34.0 |
| SFP8 | 27.4 | 46.1 |
Benchmark de Gemma 3 27B
Rendimiento en chat
Gemma 3 27B ha demostrado capacidades sobresalientes en evaluaciones recientes, logrando una puntuación Elo de 1339 en LMSys Chatbot Arena. Este rendimiento lo sitúa entre los 10 mejores modelos, incluidos los principales modelos de código cerrado como o1-preview, y destaca su solidez en evaluaciones de preferencia humana. Además, Gemma 3 27B alcanza esta alta puntuación requiriendo solo una GPU NVIDIA H100, a diferencia de competidores que dependen de hasta 32 GPUs para un rendimiento similar.
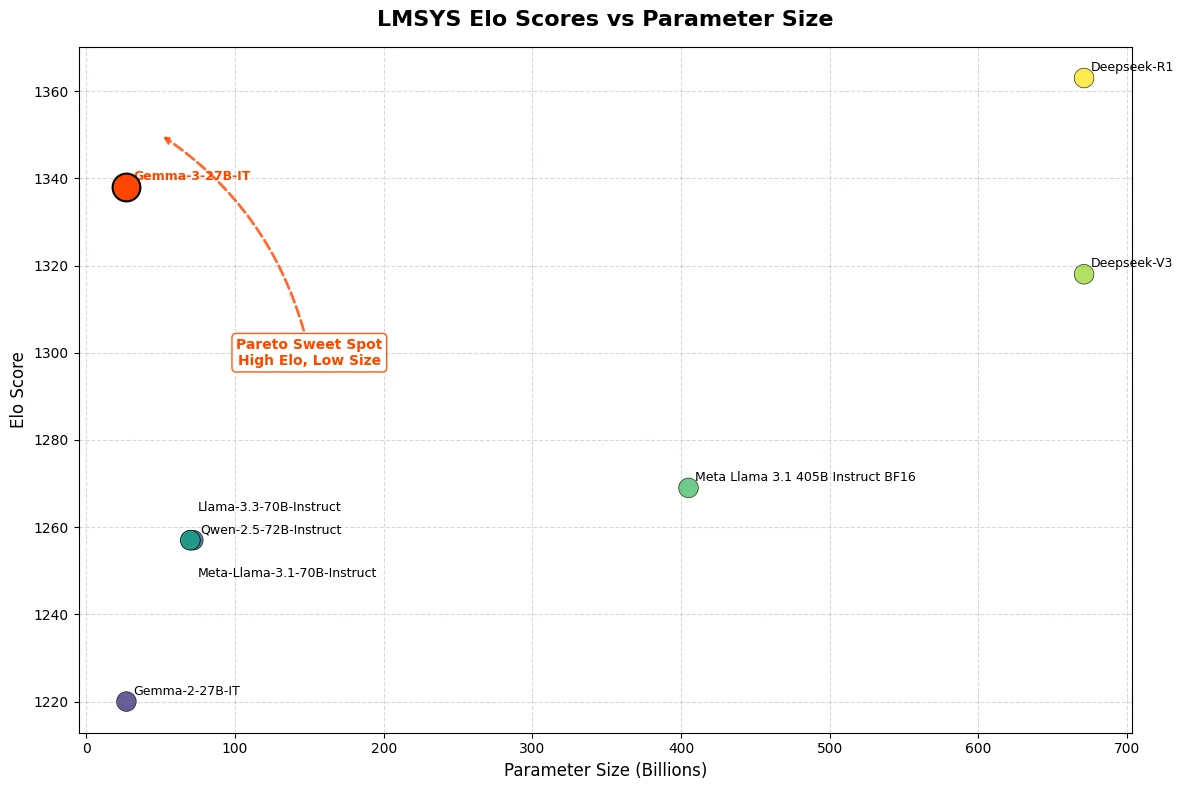
De Hugging Face
Rendimiento en benchmarks específicos
La versión ajustada por instrucciones, Gemma 3 27B IT, obtuvo resultados competitivos en una variedad de evaluaciones, a menudo rivalizando con los modelos Gemini cerrados:
| Benchmark | Puntuación | Descripción |
|---|---|---|
| MMLU-Pro | 67.5 | Rendimiento sólido en comprensión del lenguaje multitarea. |
| LiveCodeBench | 29.7 | Éxito moderado en desafíos de codificación en vivo. |
| Bird-SQL | 54.4 | Resultados competitivos en generación y comprensión de consultas SQL. |
| GPQA Diamond | 42.4 | Rendimiento sólido en respuestas a preguntas de propósito general. |
| MATH | 69.0 | Destaca en la resolución de problemas matemáticos complejos. |
| FACTS Grounding | 74.9 | Excelente fundamentación fáctica y precisión en tareas basadas en conocimiento. |
| MMMU | 64.9 | Rendimiento sólido en tareas de comprensión multimodal. |
| SimpleQA | 10.0 | Rendimiento más bajo en respuestas a preguntas básicas de hechos, lo que deja margen de mejora. |
Requisitos de hardware de Gemma 3 27B
¡Gemma 3 27B se describe como el “modelo más capaz que puedes ejecutar en una sola GPU” !
De Google
| Configuración | Requisito de VRAM | Notas |
|---|---|---|
| Implementación en la nube | Aproximadamente 80 GB de VRAM (una o varias GPUs) | Se recomiendan GPUs A100 o H100 para un rendimiento óptimo en la nube. O RTX 4090 24 GB (x3) |
| Apple Silicon | Gemma 3 4B compatible mediante mlx-vlm | Gemma 3 4B se envía con soporte desde el primer día en mlx-vlm, una librería de código abierto para ejecutar modelos de visión-lenguaje en dispositivos Apple Silicon, incluidas Macs y iPhones. |
Prueba de Gemma 3 27B
Código
Prompt: Crea una simulación en JavaScript de una esfera 3D giratoria compuesta por letras del alfabeto. Las letras más cercanas deben tener un color más brillante, mientras que las más lejanas deben aparecer en color gris.
Salida: Parece que el modelo no siguió completamente el prompt. En su lugar, generó un anillo giratorio con letras. Además, las dos primeras vistas previas fallaron debido a un brillo insuficiente.

Razonamiento
Prompt: Empiezas con 14 manzanas. Emma toma 3 pero devuelve 2. Se te caen 7 y recoges 4. Leo toma 4 y da 5. Tomas 1 manzana de Emma y la cambias con Leo por 3 manzanas, luego le das esas 3 a Emma, quien te da una manzana y una naranja. Zara toma tu manzana y te da una pera. Cambias la pera con Leo por una manzana. Más tarde, Zara cambia una manzana por una naranja y la intercambia contigo por otra manzana. ¿Cuántas peras tienes? Responde solo lo que se pregunta.
Salida: En cuestión de segundos, analizó eficientemente todos los escenarios y calculó con precisión el número total de peras.
Análisis de imagen
Prompt: Dime cuántas veces aumentó la puntuación Elo de gemma 2 27b a gemma 3 27b?
De Google
Salida: Identificó correctamente los números pero no calculó los múltiplos como indicaba el prompt; en su lugar, solo calculó la diferencia.
Basado en la imagen, aquí está el cálculo:
- Puntuación Elo de Gemma 2 27B: 1220
- Puntuación Elo de Gemma 3 27B: 1338
Incremento: 1338 - 1220 = 118
La puntuación Elo aumentó en 118 puntos de Gemma 2 27B a Gemma 3 27B.
¿Cómo acceder a Gemma 3 27B?
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de Modelos.

¡Prueba la Demo de Gemma 3 27B ahora!
Paso 2: Comienza tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 3: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página de “Configuración” y copia la clave API como se indica en la imagen.

Paso 4: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.

Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<TU Clave API de Novita AI>",
)
model = "google/gemma-3-27b-it"
stream = True # o False
max_tokens = 2048
system_content = """Sé un asistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Gemma 3 27B es un potente modelo de código abierto de Google que ofrece un sólido razonamiento, capacidades multimodales, soporte multilingüe y una fácil integración con plataformas como Hugging Face, todo mientras se ejecuta en hardware de consumo.
Preguntas frecuentes
¿Cuántos parámetros tiene Gemma 3 27B?
Gemma 3 27B tiene 27 mil millones de parámetros.
¿Gemma 3 27B es multimodal?
Sí, admite entradas de imagen y texto.
¿Qué hardware se recomienda para ejecutar Gemma 3 27B?
Para uso local, se recomienda una GPU con al menos 24 GB de VRAM, siendo beneficioso más VRAM para tamaños de contexto más grandes. También se puede implementar en plataformas en la nube como Hugging Face Inference Endpoints con varias opciones de GPU. O puedes elegir una API efectiva como Novita AI para usarlo.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona una nube de GPU asequible y confiable para construir y escalar.



