

** 主なハイライト **
** マルチモーダル、多言語、長いコンテキスト **: Gemma 3 27B はテキストと画像を処理し、140以上の言語をサポートし、最大128Kトークンの長い入力を処理できます。
** Eloスコア **: Eloスコア1339を達成し、世界のトップ10モデルにランクインしました。
** シングルGPU対応 **: 単一のNVIDIA H100 GPUでトップパフォーマンスを実現し、複数のGPUを必要とする競合モデルを凌駕します。
** Novita AI でアクセス **: Novita AI は、Gemma 3 27B の機能を試すための費用対効果の高いAPIと無料プレイグラウンドを提供しています。今すぐお試しください!
2025年3月12日にリリースされた Gemma 3 27B は、Googleのオープンソース大規模言語モデルの重要な追加製品です。特定の機能を持つ指示チューニングバージョンを除けば、Gemma 3 ファミリーの中で最大のモデルであり、パフォーマンスとアクセシビリティのバランスを目指しています。この記事では、Gemma 3 27B の実用的かつ技術的な概要、アーキテクチャ、機能、ベンチマークおよび実用的なテストでのパフォーマンス、ハードウェア要件、アクセス方法について詳しく説明します。
Gemma 3 27B とは?
** 注目すべき機能 **
- ** 高度な多言語サポート **: 新しいトークナイザーにより、Gemma 3 は140以上の言語で高い効果を発揮します。
- ** マルチモーダル入力 **: 画像とテキストの両方を処理できるため、幅広いアプリケーションで多用途に使用できます。
- ** 拡張コンテキストウィンドウ **: 128Kトークンの容量により、大規模で詳細な入力を処理できます。
- ** オープンソースでコミュニティフレンドリー **: オープンソースであるため、コミュニティによる実験と幅広い採用が促進されます。
** リリース日、モデルサイズ 、 オープンソース **
- ** 2025年3月12日 **
- ** 270億パラメータ **
このサイズにより、Gemma 3 は複雑で多様なタスクを効果的に処理できる強力なモデルとして位置づけられます。 - ** オープンモデル **: Google によってオープンソースモデルとしてリリースされました。
** 対応言語 **
- ** 140以上の言語をサポート **
- グローバルなアプリケーションで非常に汎用性の高い、** 新しいトークナイザー ** を搭載し、** 多言語サポート ** が向上しています。
** モデルアーキテクチャ **
- ** テクノロジー **: Google の Gemini 2.0 モデル を支える同じ研究とテクノロジーを使用して構築されています。
- ** トレーニング **:
- Google TPU を使用して 14兆トークン でトレーニング。
- 効率的でスケーラブルなトレーニングのために JAX フレームワーク を活用。
- ** 使用されたテクニック **:
- ** 蒸留 **
- ** 強化学習 ** (RLHF、RLMF、RLEF を含む)
- ** モデルマージ **
- これらのテクニックにより、** 数学 、 コーディング 、 指示追従 ** などの重要な分野でのパフォーマンスが向上します。
** マルチモーダル機能 **
- ** マルチモーダル **: はい
- ** 画像とテキストの両方を入力として処理 ** し、** テキスト出力 ** を生成します。
- ** ビジョンエンコーダー **: SigLIP ベース。
** コンテキストウィンドウ **
- ** 128K トークン **
- モデルが高度なタスクのために 大量の情報を処理および理解 できるようにします。
- ** 事前トレーニングの詳細 **:
- 最初は **32k シーケンス ** で事前トレーニングされ、後に 128k に拡張。
- RoPE(回転位置埋め込み) を使用した ** 位置埋め込み** の調整によって達成。
** 量子化精度 **
- デフォルトのトレーニング精度: bfloat16
- ** パフォーマンス注記 **: モデルは bfloat16 で最適に動作し、他の精度では品質が低下する可能性があります。
- ** 量子化オプション **:
- コミュニティは Q8 gguf quant、EXL2、IQ4_XS などの量子化レベルで VRAM 使用量最適化を実験中。
| 精度レベル | 重みのみ (GB) | 重み + KV キャッシュ (GB) |
|---|---|---|
| bf16 (Raw) | 54.0 | 72.7 |
| INT4 | 14.1 | 32.8 |
| INT4 (blocks=32) | 15.3 | 34.0 |
| SFP8 | 27.4 | 46.1 |
Gemma 3 27B ベンチマーク
チャットパフォーマンス
Gemma 3 27B は最近の評価で優れた能力を示し、LMSys Chatbot Arena で Elo スコア 1339 を達成しました。このパフォーマンスにより、o1-preview などの主要なクローズドソースモデルを含む ** トップ10のベストモデル ** にランクインし、人間の嗜好評価における強みが際立っています。さらに、Gemma 3 27B はこの高いスコアを ** 単一の NVIDIA H100 GPU** のみで達成しており、競合他社は同様のパフォーマンスのために最大 32 GPU を必要とします。
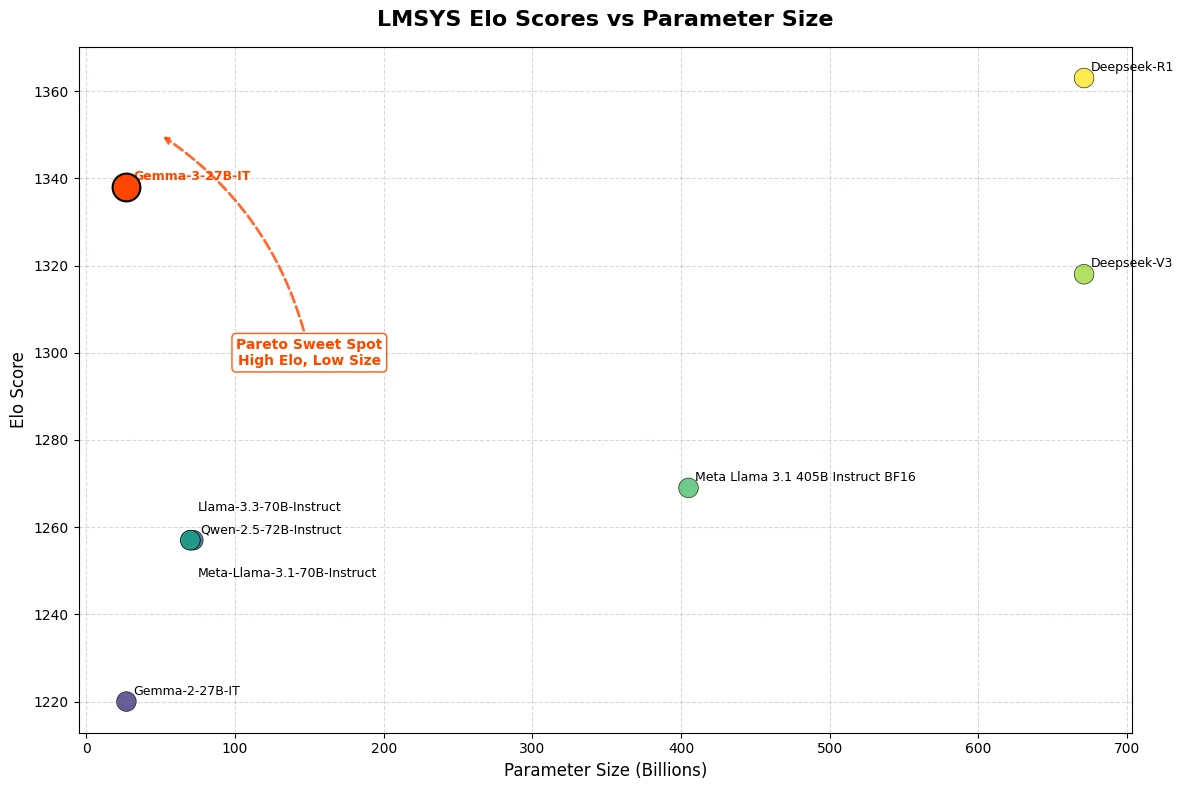
Hugging Face より
** 特定ベンチマークのパフォーマンス **
指示チューニングバージョンの Gemma 3 27B IT は、さまざまな評価で競争力のある結果を達成し、** クローズド Gemini モデル** に匹敵することがよくあります。
| **ベンチマーク ** | ** スコア ** | ** 説明** |
|---|---|---|
| MMLU-Pro | 67.5 | マルチタスク言語理解で強力なパフォーマンス。 |
| LiveCodeBench | 29.7 | ライブコーディングチャレンジで適度な成功を示す。 |
| Bird-SQL | 54.4 | SQLクエリ生成と理解で競争力のある結果。 |
| GPQA Diamond | 42.4 | 汎用質問応答で堅実なパフォーマンス。 |
| MATH | 69.0 | 複雑な数学的問題解決で優れる。 |
| FACTS Grounding | 74.9 | 知識ベースのタスクで優れた事実根拠と正確性。 |
| MMMU | 64.9 | マルチモーダル理解タスクで強力なパフォーマンス。 |
| SimpleQA | 10.0 | 基本的な事実に基づく質問応答ではパフォーマンスが低く、改善の余地あり。 |
Gemma 3 27B ハードウェア要件
Gemma 3 27B は、「単一のGPUで実行できる最も高性能なモデル」 と説明されています!
Google より
| **セットアップ ** | **VRAM要件 ** | ** 注記** |
|---|---|---|
| クラウドデプロイメント | 約80GB VRAM(シングル/マルチGPU) | 最適なクラウドデプロイメントパフォーマンスには A100 または H100 GPU を推奨。または RTX 4090 24GB (x3) |
| Apple Silicon | mlx-vlm を介して Gemma 3 4B をサポート | Gemma 3 4B は、Mac や iPhone を含む Apple Silicon デバイスで視覚言語モデルを実行するためのオープンソースライブラリ mlx-vlm で初日からサポートされています。 |
Gemma 3 27B テスト
コード
プロンプト: Create a JavaScript simulation of a rotating 3D sphere made up of alphabets. The closest letters should be in a brighter color, while the ones farthest away should appear in gray color.
出力: モデルはプロンプトに完全に従っていないようです。代わりに、アルファベットで構成された回転するリングを生成しました。また、最初の2つのプレビューは明るさが不十分で失敗しました。

推論
プロンプト: You start with 14 apples. Emma takes 3 but gives back 2. You drop 7 and pick up 4. Leo takes 4 and gives 5. You take 1 apple from Emma and trade it with Leo for 3 apples, then give those 3 to Emma, who hands you an apple and an orange. Zara takes your apple and gives you a pear. You trade the pear with Leo for an apple. Later, Zara trades an apple for an orange and swaps it with you for another apple. How many pears do you have? Answer me just what is asked.
出力: 数秒ですべてのシナリオを効率的に分析し、梨の総数を正確に計算しました。
画像分析
プロンプト: Tell me how many times the elo score increased from gemma 2 27b to gemma 3 27b?
Google より
出力: 数値を正確に識別しましたが、プロンプトで指示された倍数を計算せず、代わりに差のみを計算しました。
画像に基づいて、計算は以下の通りです。
- Gemma 2 27B Elo スコア: 1220
- Gemma 3 27B Elo スコア: 1338
増加: 1338 - 1220 = 118
Gemma 2 27B から Gemma 3 27B への Elo スコアの増加は 118 ポイントです。
Gemma 3 27B にアクセスする方法
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、同時に手頃で信頼性の高いGPUクラウドを提供して構築とスケーリングを実現します。
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ 2: 無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試します。
ステップ 3: API キーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに移動し、画像に示されているように API キーをコピーします。

ステップ 4: API をインストール
プログラミング言語に固有のパッケージマネージャーを使用して API をインストールします。

インストール後、開発環境に必要なライブラリをインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。これは、Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "google/gemma-3-27b-it"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Gemma 3 27B は Google の強力なオープンソースモデルであり、強力な推論、マルチモーダル機能、多言語サポート、Hugging Face などのプラットフォームとの簡単な統合を提供し、すべてコンシューマーグレードのハードウェアで実行できます。
よくある質問
Gemma 3 27B のパラメータ数はいくつですか?
Gemma 3 27B は 270億パラメータ です。
Gemma 3 27B はマルチモーダルですか?
はい、画像とテキストの両方の入力をサポートしています。
Gemma 3 27B を実行するための推奨ハードウェアは?
ローカルで使用する場合、少なくとも24GBのVRAMを搭載したGPU が推奨され、より大きなコンテキストサイズにはより多くのVRAMが有益です。また、Hugging Face Inference Endpoints などのクラウドプラットフォームにさまざまなGPUオプションでデプロイすることもできます。または、Novita AI のような効果的なAPIを選んで使用することもできます!
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、同時に構築とスケーリングのための手頃で信頼性の高いGPUクラウドを提供します。



