

Destaques Principais
Multimodal, Multilíngue, Contexto Longo: O Gemma 3 27B processa texto e imagens, suporta mais de 140 idiomas e lida com até 128K tokens para entradas longas.
Pontuação Elo: Alcançou uma pontuação Elo de 1339, classificando-se entre os 10 melhores modelos globalmente.
Compatibilidade com GPU Única: Oferece desempenho superior em uma única GPU NVIDIA H100, superando concorrentes que exigem múltiplas GPUs.
Acesso pela Novita AI: A Novita AI oferece uma API econômica e um playground gratuito para explorar as capacidades do Gemma 3 27B — experimente agora!
Lançado em 12 de março de 2025, o Gemma 3 27B é uma adição significativa à linha de modelos de linguagem de código aberto do Google. Como o maior modelo da família Gemma 3, além das variações ajustadas por instruções com funcionalidades específicas, ele visa oferecer um equilíbrio entre desempenho e acessibilidade. Este artigo fornece uma visão geral prática e técnica do Gemma 3 27B, detalhando sua arquitetura, capacidades, desempenho em benchmarks e testes práticos, considerações de hardware e métodos de acesso.
O que é o Gemma 3 27B?
Características Notáveis
- Suporte Multilíngue Avançado: Com seu novo tokenizador, o Gemma 3 é altamente eficaz em mais de 140 idiomas.
- Entrada Multimodal: A capacidade de processar tanto imagens quanto texto o torna uma ferramenta versátil para uma variedade de aplicações.
- Janela de Contexto Estendida: A capacidade de 128K tokens permite lidar com entradas extensas e detalhadas.
- Código Aberto e Amigável à Comunidade: Sendo de código aberto, o modelo incentiva a experimentação da comunidade e a adoção ampla.
Data de Lançamento, Tamanho do Modelo, Código Aberto
- 12 de março de 2025
- 27 bilhões de parâmetros
Esse tamanho posiciona o Gemma 3 como um modelo substancial, capaz de lidar com tarefas complexas e diversas de forma eficaz. - Modelo Aberto: Lançado como um modelo de código aberto pelo Google.
Idiomas Suportados
-
Suporta mais de 140 idiomas
- Apresenta um novo tokenizador projetado para melhor suporte multilíngue, tornando-o altamente versátil em aplicações globais.
Arquitetura do Modelo
- Tecnologia: Construído usando a mesma pesquisa e tecnologia que alimentam os modelos Gemini 2.0 do Google.
- Treinamento:
- Treinado em 14 trilhões de tokens usando TPUs do Google.
- Utilizou o JAX Framework para treinamento eficiente e escalável.
- Técnicas Utilizadas:
- Destilação
- Aprendizado por Reforço (incluindo RLHF, RLMF, RLEF)
- Mesclagem de Modelos
- Essas técnicas aprimoram o desempenho do modelo em áreas críticas como matemática, codificação e seguimento de instruções.
Capacidade Multimodal
- Multimodal: Sim
- Processa imagens e texto como entrada e gera saída de texto.
- Codificador de Visão: Baseado no SigLIP.
Janela de Contexto
-
128K tokens
- Permite que o modelo processe e compreenda grandes quantidades de informação para tarefas sofisticadas.
- Detalhes do Pré-treinamento:
- Inicialmente pré-treinado com sequências de 32k e posteriormente escalado para 128k.
- Alcançado através de ajustes nos embeddings posicionais usando RoPE (Rotary Positional Embeddings).
Precisão de Quantização
-
Precisão de treinamento padrão: bfloat16
- Nota de Desempenho: Os modelos têm melhor desempenho usando bfloat16, e a qualidade pode degradar com outras precisões.
-
Opções de Quantização:
- Experimentos da comunidade com níveis de quantização como Q8 gguf quant, EXL2 e IQ4_XS para otimizar o uso de VRAM.
| Nível de Precisão | Apenas Pesos (GB) | Pesos + Cache KV (GB) |
|---|---|---|
| bf16 (Cru) | 54.0 | 72.7 |
| INT4 | 14.1 | 32.8 |
| INT4 (blocos=32) | 15.3 | 34.0 |
| SFP8 | 27.4 | 46.1 |
Benchmark do Gemma 3 27B
Desempenho em Chat
O Gemma 3 27B demonstrou capacidades excepcionais em avaliações recentes, alcançando uma pontuação Elo de 1339 no LMSys Chatbot Arena. Esse desempenho o coloca entre os 10 melhores modelos, incluindo modelos fechados líderes, o1-preview, e destaca sua força em avaliações de preferência humana. Além disso, o Gemma 3 27B atinge essa alta pontuação exigindo apenas uma única GPU NVIDIA H100, ao contrário de concorrentes que dependem de até 32 GPUs para desempenho semelhante.
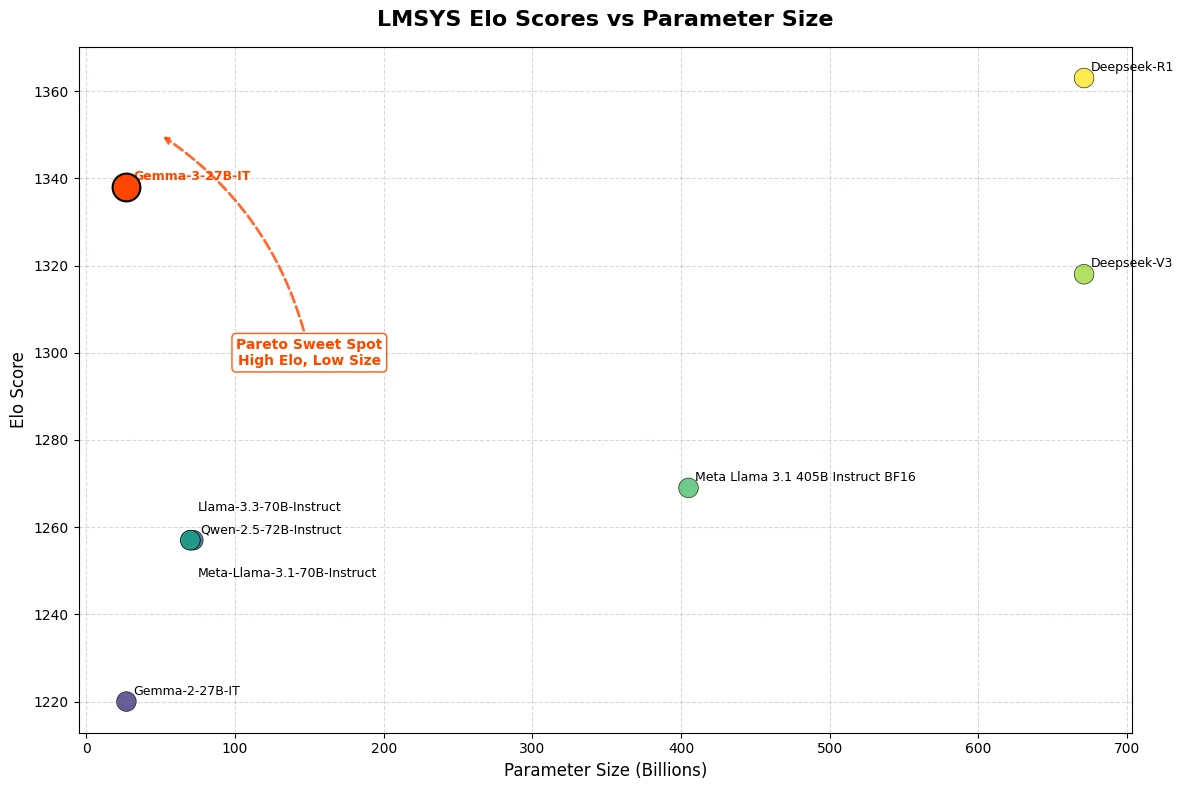
Do Hugging Face
Desempenho em Benchmarks Específicos
A versão ajustada por instruções, Gemma 3 27B IT, obteve resultados competitivos em uma variedade de avaliações, muitas vezes rivalizando com modelos Gemini fechados:
| Benchmark | Pontuação | Descrição |
|---|---|---|
| MMLU-Pro | 67.5 | Desempenho forte em compreensão de linguagem em múltiplas tarefas. |
| LiveCodeBench | 29.7 | Demonstra sucesso moderado em desafios de codificação ao vivo. |
| Bird-SQL | 54.4 | Resultados competitivos em geração e compreensão de consultas SQL. |
| GPQA Diamond | 42.4 | Desempenho sólido em resposta a perguntas de propósito geral. |
| MATH | 69.0 | Excelente em resolução de problemas matemáticos complexos. |
| FACTS Grounding | 74.9 | Excelente fundamentação factual e precisão em tarefas baseadas em conhecimento. |
| MMMU | 64.9 | Desempenho forte em tarefas de compreensão multimodal. |
| SimpleQA | 10.0 | Desempenho inferior em resposta a perguntas básicas baseadas em fatos, deixando espaço para melhorias. |
Requisitos de Hardware do Gemma 3 27B
O Gemma 3 27B é descrito como o “modelo mais capaz que você pode executar em uma única GPU”!
Do Google
| Configuração | Requisito de VRAM | Notas |
|---|---|---|
| Implantação em Nuvem | Cerca de 80GB VRAM (GPU única/múltipla) | GPUs A100 ou H100 são recomendadas para desempenho ideal de implantação em nuvem. Ou RTX 4090 24GB (x3). |
| Apple Silicon | Gemma 3 4B suportado via mlx-vlm | O Gemma 3 4B é enviado com suporte no dia zero no mlx-vlm, uma biblioteca open-source para executar modelos de visão-linguagem em dispositivos Apple Silicon, incluindo Macs e iPhones. |
Teste do Gemma 3 27B
Código
Prompt: Crie uma simulação em JavaScript de uma esfera 3D giratória composta por alfabetos. As letras mais próximas devem estar em uma cor mais brilhante, enquanto as mais distantes devem aparecer em cinza.
Saída: Parece que o modelo não seguiu totalmente o prompt. Em vez disso, gerou um anel giratório com alfabetos. Além disso, as duas primeiras pré-visualizações falharam devido ao brilho insuficiente.

Raciocínio
Prompt: Você começa com 14 maçãs. Emma pega 3, mas devolve 2. Você derruba 7 e pega 4. Leo pega 4 e dá 5. Você pega 1 maçã de Emma e troca com Leo por 3 maçãs, depois dá essas 3 para Emma, que lhe entrega uma maçã e uma laranja. Zara pega sua maçã e lhe dá uma pera. Você troca a pera com Leo por uma maçã. Mais tarde, Zara troca uma maçã por uma laranja e troca com você por outra maçã. Quantas peras você tem? Responda apenas o que foi perguntado.
Saída: Em questão de segundos, analisou eficientemente todos os cenários e calculou com precisão o total de peras.
Análise de Imagem
Prompt: Diga-me quantas vezes a pontuação elo aumentou do gemma 2 27b para o gemma 3 27b?
Do Google
Saída: Identificou com precisão os números, mas não calculou os múltiplos conforme instruído pelo prompt; em vez disso, calculou apenas a diferença.
Com base na imagem, aqui está o cálculo:
- Pontuação Elo do Gemma 2 27B: 1220
- Pontuação Elo do Gemma 3 27B: 1338
Aumento: 1338 - 1220 = 118
A pontuação Elo aumentou 118 pontos do Gemma 2 27B para o Gemma 3 27B.
Como Acessar o Gemma 3 27B?
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, ao mesmo tempo que fornece uma nuvem de GPU acessível e confiável para construir e escalar.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Experimente o Demo do Gemma 3 27B Agora!
Passo 2: Inicie seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 3: Obtenha sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Entrando na página “Settings“, você pode copiar a chave de API conforme indicado na imagem.

Passo 4: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de completions de chat para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<SUA Chave de API Novita AI>",
)
model = "google/gemma-3-27b-it"
stream = True # ou False
max_tokens = 2048
system_content = """Seja um assistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
O Gemma 3 27B é um modelo open-source poderoso do Google, oferecendo forte raciocínio, capacidades multimodais, suporte multilíngue e fácil integração com plataformas como Hugging Face, tudo isso rodando em hardware de consumo.
Perguntas Frequentes
Quantos parâmetros o Gemma 3 27B possui?
O Gemma 3 27B possui 27 bilhões de parâmetros.
O Gemma 3 27B é multimodal?
Sim, ele suporta entradas de imagem e texto.
Qual é o hardware recomendado para executar o Gemma 3 27B?
Para uso local, recomenda-se uma GPU com pelo menos 24GB de VRAM, sendo que mais VRAM é benéfico para tamanhos de contexto maiores. Ele também pode ser implantado em plataformas de nuvem como o Hugging Face Inference Endpoints com várias opções de GPU. Ou você pode escolher uma API eficaz como a Novita AI para usá-lo!
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, ao mesmo tempo que fornece uma nuvem de GPU acessível e confiável para construir e escalar.



