

Sumérgete en la guía completa de benchmarks de LLMs para conocer los principales benchmarks y perspectivas de la industria. Visita nuestro blog para más detalles.
Aspectos Clave
- Comprender el propósito y la importancia de los benchmarks de LLM en el aprendizaje automático
- Explorar los componentes clave y los tipos de benchmarks utilizados en la evaluación de LLMs
- Descubrir los modelos de evaluación de benchmarks para diferentes aplicaciones de LLM, como la generación de código y la comprensión del lenguaje natural
- Obtener comparaciones detalladas de modelos populares de LLM, incluidas las series GPT y las variantes de BERT
- Aprender sobre el papel de los rankings (leaderboards) en la evaluación comparativa de LLMs y cómo influyen en el desarrollo de LLMs
- Explorar los desafíos y limitaciones de los benchmarks actuales y el futuro de benchmarks más inclusivos y completos
- Descubrir las tendencias emergentes en la evaluación comparativa de LLM, incluida la integración de escenarios del mundo real y la ética de la IA
Introducción
A medida que más modelos de lenguaje grandes (LLMs) ingresan al mercado, se vuelve esencial que las organizaciones y los usuarios exploren de manera eficiente este ecosistema en expansión e identifiquen los modelos que se alinean con sus necesidades específicas. Un enfoque práctico para facilitar este proceso de toma de decisiones es comprender las puntuaciones de los benchmarks.
Esta guía explora el concepto de benchmarks de LLM, analiza los benchmarks más comunes y sus componentes, y destaca las limitaciones de confiar exclusivamente en las puntuaciones de los benchmarks como único indicador del rendimiento de un modelo.
¿Qué son los Benchmarks de LLM?

Un benchmark de LLM es una herramienta de evaluación estandarizada diseñada para medir el rendimiento de los modelos de lenguaje de IA. Por lo general, incluye un conjunto de datos, un conjunto de preguntas o tareas y un método de puntuación. Los modelos se prueban con estos benchmarks y suelen recibir puntuaciones del 0 al 100, que reflejan su rendimiento.
¿Por Qué son Importantes?
Los benchmarks son cruciales para las organizaciones, incluidos gerentes de producto, desarrolladores y usuarios, ya que ofrecen una medida clara y objetiva de las capacidades de un LLM. Al utilizar un conjunto uniforme de evaluaciones, los benchmarks simplifican el proceso de comparar diferentes modelos, lo que facilita la elección del más adecuado para necesidades específicas.
Además, los benchmarks son invaluables para los desarrolladores de LLM y los investigadores de IA porque proporcionan un marco cuantitativo para evaluar cómo se ve un buen rendimiento. Las puntuaciones de los benchmarks destacan tanto las fortalezas como las debilidades de un modelo. Esta información permite a los desarrolladores comparar sus modelos con los de la competencia y realizar las mejoras necesarias. La claridad que proporcionan los benchmarks bien diseñados fomenta la transparencia dentro de la comunidad de LLM, promoviendo la colaboración y acelerando el progreso general del desarrollo de modelos de lenguaje.

Benchmarks Populares de LLM
Aquí hay una selección de los benchmarks de LLM más utilizados, junto con sus pros y contras.
ARC
El AI2 Reasoning Challenge (ARC) es un benchmark de preguntas y respuestas (QA) diseñado específicamente para evaluar el conocimiento y la capacidad de razonamiento de un LLM. El conjunto de datos de ARC incluye 7,787 preguntas de opción múltiple de ciencias con cuatro opciones cada una, que cubren contenido adecuado para estudiantes de 3.º a 9.º grado. Estas preguntas se clasifican en conjuntos Fáciles y de Desafío, cada uno diseñado para probar diferentes tipos de conocimiento como factual, definicional, propositivo, espacial, procedimental, experimental y algebraico.
ARC pretende ofrecer una evaluación más robusta y desafiante en comparación con benchmarks de QA anteriores como el Stanford Question and Answer Dataset (SQuAD) o el Stanford Natural Language Inference (SNLI). Estos benchmarks anteriores evaluaban principalmente la capacidad de un modelo para identificar respuestas correctas a partir de un texto dado. En cambio, las preguntas de ARC exigen razonamiento sobre evidencia distribuida: la información necesaria para responder una pregunta está integrada en un pasaje, lo que obliga a un modelo de lenguaje a aprovechar su comprensión y habilidades de razonamiento en lugar de depender de la mera memorización de datos.
Pros y Contras del Benchmark ARC
Pros
- El conjunto de datos de ARC es variado y exigente, lo que empuja a los proveedores de IA a mejorar las habilidades de QA mediante la síntesis de información de múltiples oraciones, en lugar de simplemente recuperar datos.
Contras
- Limitado a preguntas de ciencias, lo que restringe su aplicabilidad en dominios de conocimiento más amplios.
- La construcción del corpus no es completamente transparente y el conjunto de datos contiene numerosos errores.
TruthfulQA

Si bien los modelos de lenguaje grandes (LLMs) pueden generar respuestas coherentes y articuladas, la precisión sigue siendo un desafío. El benchmark TruthfulQA aborda esto evaluando la capacidad de los LLMs para producir respuestas veraces, centrándose especialmente en reducir las tendencias de los modelos a generar respuestas fabricadas (“alucinadas”).
Los LLMs pueden dar respuestas inexactas debido a varios factores: datos de entrenamiento insuficientes sobre temas específicos, entrenamiento con datos con errores u objetivos de entrenamiento que favorecen inadvertidamente respuestas incorrectas, denominadas “falsedades imitativas”.
El diseño del conjunto de datos de TruthfulQA alienta a los modelos a seleccionar estas falsedades imitativas en lugar de respuestas veraces. Evalúa la veracidad de las respuestas de un LLM según su alineación con la realidad factual. El benchmark desalienta las respuestas no comprometidas como “No lo sé” al evaluar también la informatividad de las respuestas.
Compuesto por 817 preguntas en 38 dominios, incluyendo finanzas, salud y política, TruthfulQA evalúa modelos a través de dos tareas. La primera consiste en generar respuestas a preguntas, calificadas de 0 a 1 por evaluadores humanos según la precisión. La segunda tarea implica una decisión de verdadero/falso para un conjunto de preguntas de opción múltiple. Los resultados de ambas tareas se combinan para formar la puntuación final.
Pros y Contras de TruthfulQA
Pros
- Cuenta con un conjunto de datos variado, lo que proporciona una prueba integral en múltiples áreas de conocimiento.
- Trabaja activamente contra la propensión de los LLMs a generar información falsa, promoviendo así la precisión.
Contras
- El enfoque en el conocimiento general significa que podría no medir eficazmente la veracidad en campos especializados.
WinoGrande
WinoGrande es un benchmark diseñado para evaluar las capacidades de razonamiento de sentido común de los modelos de lenguaje grandes (LLMs) y es una extensión del Winograd Schema Challenge (WSC). Presenta una serie de desafíos de resolución de pronombres, con pares de oraciones casi idénticas que difieren según una palabra desencadenante, cada una requiere la selección de la interpretación correcta del pronombre.

El conjunto de datos de WinoGrande amplía significativamente el WSC con 44,000 problemas bien elaborados y obtenidos de la comunidad. Para aumentar la complejidad de las tareas y minimizar sesgos como los artefactos de anotación, se empleó el algoritmo AFLITE, que se basa en el enfoque de filtrado adversarial utilizado en HellaSwag.
Pros y Contras del Benchmark WinoGrande
Pros
- Cuenta con un conjunto de datos grande y obtenido de la comunidad, que ha sido cuidadosamente seleccionado mediante intervención algorítmica para garantizar un mayor grado de desafío y equidad.
Contras
- A pesar de los esfuerzos por eliminar el sesgo, aún existen artefactos de anotación (patrones que insinúan inadvertidamente la respuesta correcta) dentro del conjunto de datos. El gran tamaño del corpus dificulta erradicar por completo estos sesgos con AFLITE.
¿Qué son los Rankings de LLM?
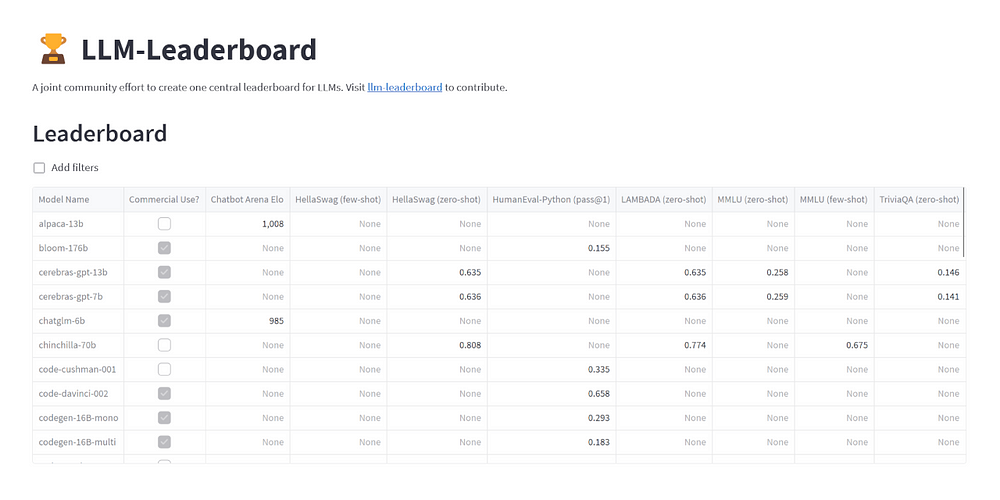
Si bien comprender las implicaciones de varios benchmarks para el rendimiento de un LLM es crucial, también es importante comparar cómo se posicionan los diferentes modelos entre sí para identificar el más adecuado para necesidades específicas. Aquí es donde los rankings de LLM se vuelven valiosos.
Un ranking de LLM es una clasificación publicada que enumera el rendimiento de varios modelos de lenguaje en benchmarks específicos. Los desarrolladores de benchmarks a menudo mantienen sus propios rankings, pero también existen rankings independientes que brindan una evaluación más amplia al comparar modelos en múltiples benchmarks.
Un ejemplo destacado de estos rankings independientes se puede encontrar en HuggingFace, que evalúa y clasifica una amplia gama de LLMs de código abierto basándose en seis benchmarks principales: ARC, HellaSwag, MMLU, TruthfulQA, WinoGrande y GSM8K. Estos rankings ofrecen una visión general completa de las capacidades del modelo, facilitando decisiones informadas al elegir un modelo de lenguaje.
Cómo Influyen los Rankings en el Desarrollo de LLMs
Los rankings tienen una influencia significativa en el desarrollo y la mejora de los LLMs. A continuación, se presentan algunas formas clave en que los rankings impactan el desarrollo de LLMs:
- Comparación de rendimiento: Los rankings proporcionan una plataforma para que los desarrolladores e investigadores comparen el rendimiento de diferentes LLMs y obtengan información sobre sus fortalezas y debilidades relativas.
- Incentivo para la mejora: Los rankings crean un entorno competitivo que alienta a los desarrolladores de LLMs a mejorar continuamente el rendimiento y las capacidades de sus modelos.
- Colaboración comunitaria: Los rankings fomentan la colaboración y el intercambio de conocimientos dentro de la comunidad de IA. Los desarrolladores pueden aprender de los modelos de mejor rendimiento y colaborar para abordar desafíos comunes y mejorar las puntuaciones de los benchmarks.
- Benchmarks impulsados por la comunidad: Los rankings a menudo incorporan benchmarks impulsados por la comunidad, lo que permite a desarrolladores y usuarios contribuir con sus propias tareas y evaluaciones para crear benchmarks más completos e inclusivos.
Modelos con Mejor Rendimiento en los Rankings Actuales
Los rankings actuales muestran los modelos con mejor rendimiento en varios benchmarks. Estos modelos han demostrado un rendimiento y capacidades excepcionales en sus respectivas tareas de lenguaje. A continuación, se presentan algunos ejemplos de modelos de alto rendimiento en los rankings actuales:
- GPT-4: GPT-4, la última iteración de la serie GPT, ha mantenido consistentemente una posición superior en múltiples benchmarks, mostrando sus avanzadas habilidades de generación de lenguaje.
- novita.ai es una plataforma integral para la creatividad sin límites que te da acceso a más de 100 APIs, incluyendo APIs de LLM. Novita AI ofrece compatibilidad con el estándar de API de OpenAI, lo que facilita la integración en aplicaciones existentes.

¿Cuáles son los Problemas con la Evaluación Comparativa de LLMs?
Si bien los benchmarks de LLM son útiles para evaluar las capacidades de los modelos de lenguaje, deben usarse como guías y no como indicadores definitivos del rendimiento de un modelo. He aquí por qué:
- Fuga de datos de benchmark: Los modelos pueden ser entrenados con los mismos datos utilizados en los benchmarks, lo que lleva a un sobreajuste donde parecen funcionar bien en las tareas del benchmark sin dominar realmente las habilidades subyacentes. Esto puede dar lugar a puntuaciones que no reflejan con precisión las capacidades del modelo en el mundo real.
- Desajuste con el uso real: Los benchmarks a menudo no capturan la complejidad y la imprevisibilidad de las aplicaciones del mundo real. Prueban modelos en entornos controlados, que pueden diferir significativamente de los entornos prácticos donde el modelo se utilizará realmente.
- Limitaciones en la prueba de IA conversacional: Para LLMs basados en conversación, benchmarks como MT-Bench pueden no representar completamente los desafíos de las conversaciones reales, que pueden variar ampliamente en longitud y complejidad.
- Conocimiento general vs. especializado: Los benchmarks suelen utilizar conjuntos de datos con conocimiento general amplio, lo que dificulta medir el rendimiento de un modelo en dominios especializados. Por lo tanto, cuanto más específico sea un caso de uso, menos relevante podría ser una puntuación de benchmark.
Conclusión
En conclusión, comprender y utilizar los benchmarks de LLM es crucial para evaluar y mejorar los modelos de lenguaje. Estos benchmarks proporcionan un marco estandarizado para la comparación y el desarrollo, impulsando la innovación y el progreso en el campo del procesamiento del lenguaje natural. Al profundizar en los matices de los diferentes tipos de benchmarks, métricas y modelos, los investigadores y desarrolladores pueden mejorar el rendimiento y la aplicabilidad de los LLMs. A pesar de desafíos como el sesgo y la equidad, el futuro promete benchmarks más inclusivos y completos, que integren escenarios del mundo real y consideraciones éticas. Manténgase informado sobre las tendencias emergentes y contribuya activamente a la evolución de las prácticas de evaluación comparativa de LLM para un panorama de IA más avanzado y éticamente sólido.
Preguntas Frecuentes
¿Con qué frecuencia se actualizan los benchmarks y por qué?
Los benchmarks se actualizan periódicamente para reflejar los estándares en evolución y los avances en el aprendizaje automático. A medida que surgen nuevos modelos y técnicas, los benchmarks deben actualizarse para proporcionar evaluaciones precisas y mantenerse al día con los últimos desarrollos en el campo.
novita.ai, la plataforma integral para la creatividad sin límites que te da acceso a más de 100 APIs. Desde generación de imágenes y procesamiento de lenguaje hasta mejora de audio y manipulación de video, con pago por uso económico, te libera de las molestias del mantenimiento de GPU mientras construyes tus propios productos. Pruébalo gratis.
Lectura recomendada
Motor de Inferencia de LLM de Novita AI: el mayor rendimiento y la inferencia más barata disponibles



