

Die Landschaft des KI-Computings erlebt eine revolutionäre Veränderung mit NVIDIAs neuestem Fortschritt von der Hopper- zur Blackwell-Architektur. Im März 2025 stellte NVIDIA die Blackwell Ultra KI-Factory-Plattform vor, die einen entscheidenden Wandel hin zum Zeitalter des KI-Reasonings markiert. Diese Plattform ist nicht nur eine inkrementelle Verbesserung, sondern ein transformativer Sprung, der beispiellose Fähigkeiten im KI-Training, Reasoning und Inferenz ermöglicht.
Die Reise von Hopper zu Blackwell stellt einen bedeutenden Technologiesprung dar, der die sich wandelnden Anforderungen von künstlicher Intelligenz (KI) und High-Performance-Computing (HPC) erfüllen soll. Dieser Blogbeitrag wird die wichtigsten Merkmale beider Architekturen untersuchen, ihre technischen Fortschritte und die breitere Auswirkung auf die KI-Entwicklung hervorheben.
Überblick über NVIDIAs Hopper-Architektur
Technische Grundlage
Die Hopper-Architektur, benannt nach der Computerpionierin Grace Hopper, basierte auf TSMCs 4nm-Prozesstechnologie. Sie führte die Tensor Cores der vierten Generation ein und war Vorreiter des Transformer Engine, der speziell zur Beschleunigung von KI-Workloads entwickelt wurde. Die Architektur verfügte über die NVLink 4.0-Interconnect-Technologie und nutzte HBM3-Speicher, wodurch neue Maßstäbe für High-Performance-Computing gesetzt wurden.
Wichtige Leistungskennzahlen
Die Hopper-Architektur stellt einen bedeutenden Sprung in der GPU-Technologie dar und liefert erhebliche Verbesserungen bei mehreren Leistungskennzahlen, während der Fokus auf Rechenzentrumseffizienz erhalten bleibt. Von dramatischen KI-Leistungssteigerungen über verbesserte Speicheroperationen bis hin zu fortschrittlichen Interconnect-Fähigkeiten etabliert sich Hopper als umfassende Lösung für moderne Rechnerherausforderungen.
Hauptmerkmale der Hopper-Architektur:
- Verbesserungen der Rechenleistung:
- FP8-Formatunterstützung mit 6-fachem FP32-Durchsatzanstieg
- 3-fache Verbesserung der FP64-Leistung
- 30-fache Steigerung der KI-Leistung
- Speicher- und Befehlsoptimierung:
- Verbesserte Latenz und Durchsatz von Speicheroperationen
- Optimierte Leistung von Tensor-Core-Befehlen
- Interconnect-Technologie:
- PCIe Gen 5-Unterstützung
- NVLink der vierten Generation
- Erweiterte Interconnect-Fähigkeiten
- Rechenzentrumseigenschaften:
- Fokus auf Energieeffizienz
- Geeignet für großflächige Bereitstellung
- Optimiert für fortschrittliche Rechenzentren und KI-Anwendungen
Wichtige Durchbrüche und Verbesserungen
- Transformer Engine: Ermöglicht dynamische Präzisionsanpassungen, optimiert KI-Workloads.
- DPX-Befehle: Verbessern dynamische Programmieraufgaben wie Sequenzalignment.
- Verteilter gemeinsamer Speicher: Verbessert die Multi-GPU-Kommunikation und Skalierbarkeit.
Blackwell-Architektur: Was ist neu und verbessert?
Wichtigste technologische Highlights
Die Blackwell-Architektur, angekündigt auf der GTC 2024, wurde entwickelt, um generative KI und groß angelegte KI-Workloads zu revolutionieren. Sie verfügt über fortschrittliche NVLink-Technologie, maßgeschneiderte Tensor Cores und eine RAS-Engine, die Echtzeit-KI-Modelle mit bis zu 10 Billionen Parametern ermöglicht. Blackwell zielt darauf ab, den Energieverbrauch für KI-Inferenz um bis zu 25-mal zu senken.
Hervorhebung signifikanter Leistungsverbesserungen
Die neue Architektur liefert beispiellose Leistungssteigerungen:
- 3-fache Verbesserung der FP8-Leistung
- 4-fach schnellere KI-Trainingsfähigkeiten
- 40-fache Steigerung der Inferenzleistung
- Deutlich bessere Energieeffizienzverhältnisse
Diese Verbesserungen ermöglichen schnelleres Training größerer KI-Modelle und effizientere Inferenzoperationen.
Technischer Vergleich: Hopper vs. Blackwell
NVIDIAs Übergang von der Hopper- (H100) zur Blackwell- (B200) Architektur markiert einen bedeutenden Technologiesprung im GPU-Design. Die neue Blackwell-Architektur zeigt erhebliche Verbesserungen bei allen wichtigen Kennzahlen, mit bemerkenswerten Fortschritten bei Transistoranzahl, Speicherbandbreite, Interconnect-Geschwindigkeit und KI-Leistung.
Die folgende Tabelle bietet einen detaillierten Vergleich der Spezifikationen zwischen den beiden Generationen:
| Merkmal | Hopper (H100) | Blackwell (B200) |
|---|---|---|
| Fertigung | TSMC 4N (80B Transistoren) | TSMC 4NP (208B Transistoren) |
| Speicher | 80 GB HBM3 (3 TB/s) | 144 GB HBM3e (4,8 TB/s) |
| NVLink | 4. Generation (900 GB/s) | 5. Generation (1,8 TB/s) |
| KI-Leistung | 4 PFLOPS (FP16) | 20 PFLOPS (FP16) |
| Energieeffizienz | Basislinie | 25-fache Verbesserung bei Inferenz |
| Wichtige Anwendungsfälle | Breite KI/HPC-Workloads | Generative KI, Billionen-Parameter-Modelle |
Hopper und Blackwell in realen KI-Anwendungen
Produkte der Hopper-Architektur
Die Hopper-Architektur ist in mehreren Produktlinien verfügbar:
| Produkt | H100 SXM | H100 PCIe | H200 SXM |
|---|---|---|---|
| Speicher | 80GB HBM3 | 80GB HBM2e | 141GB HBM3e |
| Speicherbandbreite | 3,35 TB/s | 2,04 TB/s | 4,8 TB/s |
| NVLink | 900 GB/s | N/A | 900 GB/s |
| Max. TDP | Bis zu 700W | 350W | Bis zu 700W |
| Multi-Instance GPUs | Bis zu 7 MIGs @10GB | N/A | Bis zu 7 MIGs @16,5GB |
Produkte der Blackwell-Architektur
Blackwell führt eine neue Generation von KI-Beschleunigern ein:
| Produkt | B100 | B200 | GB200 (Grace Blackwell) |
|---|---|---|---|
| Design | Blackwell GPU | Blackwell GPU | 2× B200 GPUs + Grace CPU |
| Speicher | 192GB HBM3e | 192GB HBM3e | 384GB HBM3e |
| Speicherbandbreite | 8 TB/s | 8 TB/s | 16 TB/s |
| NVLink | 1,8 TB/s (5. Gen) | 1,8 TB/s (5. Gen) | 1,8 TB/s (5. Gen) |
| FP4-Leistung | 7 PFLOPS | 9 PFLOPS | 20 PFLOPS |
| TDP | 700W | 1000W | N/A |
Fähigkeiten zum Training generativer KI-Modelle
Beide Architekturen zeigen außergewöhnliche Fähigkeiten beim Training großer KI-Modelle, wobei Blackwell im Vergleich zu Hopper bis zu 3-mal schnellere Trainingsgeschwindigkeiten demonstriert. Wichtige Verbesserungen umfassen eine verbesserte Transformer-Verarbeitung, optimierte Speicherbandbreite und effizientere Parallelverarbeitungsfähigkeiten. Die Architekturen ermöglichen das Training zunehmend großer Sprachmodelle bei gleichzeitiger Reduzierung von Stromverbrauch und Trainingszeit.
Blackwell Ultra: Die nächste Evolution im KI-Computing
Am 18. März 2025 auf der GTC 2025 angekündigt, stellt Blackwell Ultra die neueste Evolution von NVIDIAs KI-Computing-Plattform dar.
Technische Spezifikationen und Verbesserungen
- Produktlinie umfasst GB300 NVL72 und HGX B300 NVL16
- GB300 NVL72 liefert 1,5-mal mehr KI-Leistung als GB200 NVL72
- HGX B300 NVL16 im Vergleich zur Hopper-Architektur erreicht:
- 11-mal schnellere Inferenz
- 7-mal mehr Rechenleistung
- 4-mal größeren Speicher
- Integriert NVIDIA Spectrum-X Ethernet und Quantum-X800 InfiniBand, bietet 800 Gb/s Datendurchsatz pro GPU
- Verfügt über BlueField-3 DPUs für Multi-Tenant-Netzwerke, GPU-Compute-Elastizität und Echtzeit-Sicherheitserkennung
Fortschrittliche Speicher- und Kühllösungen
- Nutzt ConnectX-8 SuperNIC für leistungsstarke RDMA-Fähigkeiten
- Optimiert für KI-Fabriken und Cloud-Rechenzentren zur Beseitigung von Leistungsengpässen
- Unterstützt verschiedene Konfigurationen:
- 72 Blackwell Ultra GPUs
- 36 Arm Neoverse-basierte Grace CPUs
- Rack-skalierbares Design, das als eine einzige massive GPU fungiert
LLM-Optimierungsfunktionen
- Optimiert für KI-Reasoning und agentische KI:
- Unterstützt Reasoning und iterative Planung für komplexe mehrstufige Probleme
- Fähig zur Echtzeit-Synthese von Videogen für das Training
- Softwareunterstützung:
- Neues Open-Source NVIDIA Dynamo Inference Framework
- Unterstützung für NVIDIA Llama Nemotron Reason Modelle
- Integration mit der NVIDIA AI Enterprise Softwareplattform
- Voraussichtliche Verfügbarkeit über große Serverhersteller und Cloud-Dienstanbieter in der zweiten Hälfte von 2025
Wählen Sie Novita AI als Ihren vertrauenswürdigen GPU-Partner
Da sich das KI-Computing mit NVIDIAs bahnbrechenden Architekturen weiterentwickelt, wird die Wahl des richtigen GPU-Cloud-Partners entscheidend. Novita AI bietet eine umfassende Plattform mit Zugang zu leistungsstarken GPUs bei erheblichen Kostenvorteilen.
Wenn Sie an Novita AI interessiert sind, befolgen Sie diese Schritte, um loszulegen:
Schritt 1: Ein Konto erstellen
Besuchen Sie die Website von Novita AI, um ein Konto zu registrieren. Nach der Registrierung gehen Sie zum Bereich „GPUs“, um verfügbare Ressourcen zu erkunden und Ihre KI-Reise zu beginnen.

[Jetzt Novita AI ausprobieren](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell)
Schritt 2: Wählen Sie Ihre GPU
Unsere Plattform bietet eine Vielzahl vorkonfigurierter Vorlagen, die auf Ihre spezifischen Anforderungen zugeschnitten sind, sowie die Flexibilität, bei Bedarf benutzerdefinierte Vorlagen zu erstellen.
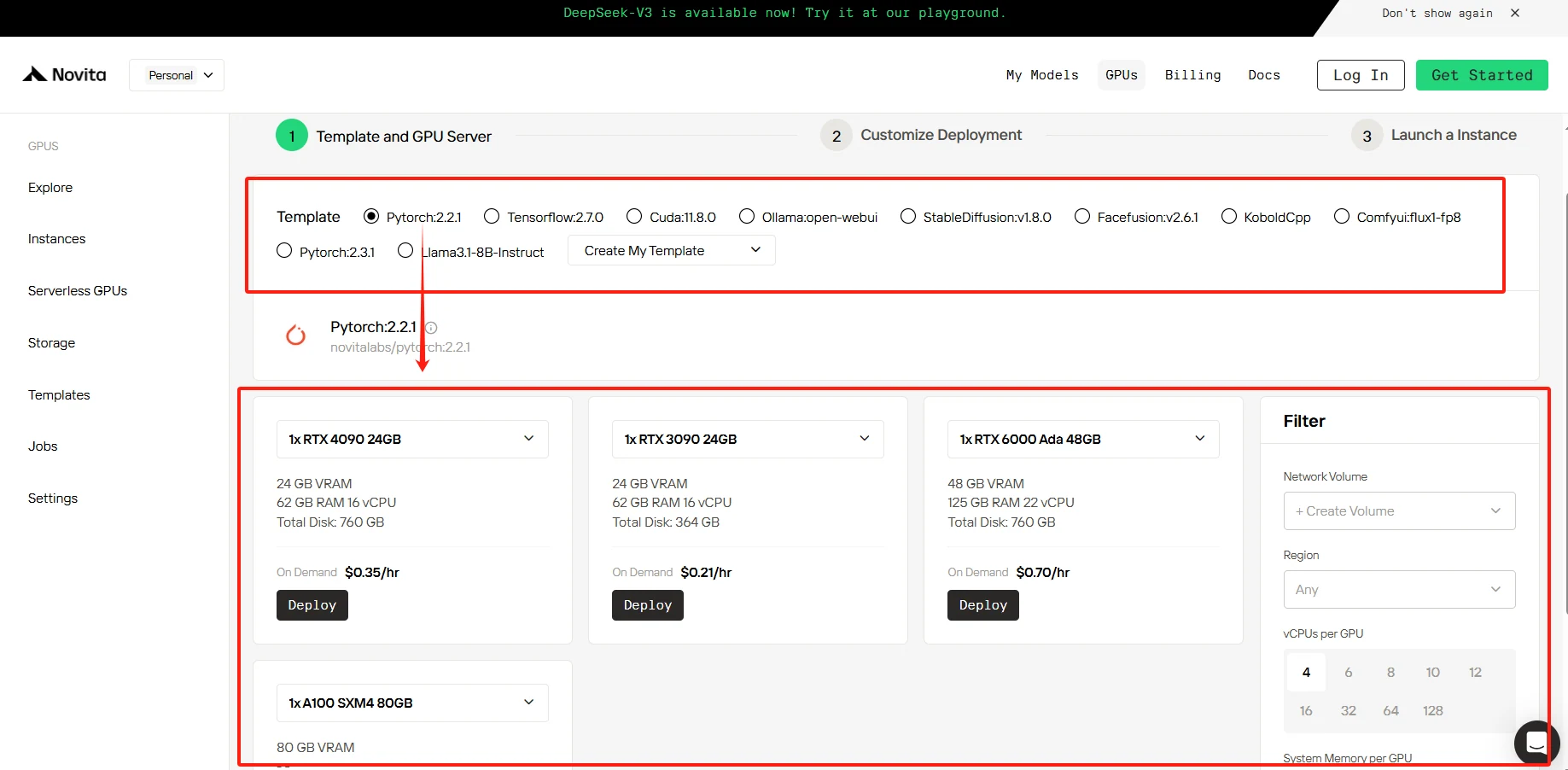
[Nvidias leistungsstarke GPUs von Novita AI testen](https://novita.ai/gpus-console/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell)
Schritt 3: Passen Sie Ihr Setup an
Starten Sie Ihr Projekt noch heute mit 60 GB kostenlosem Container-Speicher – ohne Vorabkosten. Skalieren Sie den Speicher nach Bedarf, wenn Ihre KI-Workloads wachsen, und zahlen Sie nur für den zusätzlichen Platz, den Sie benötigen.
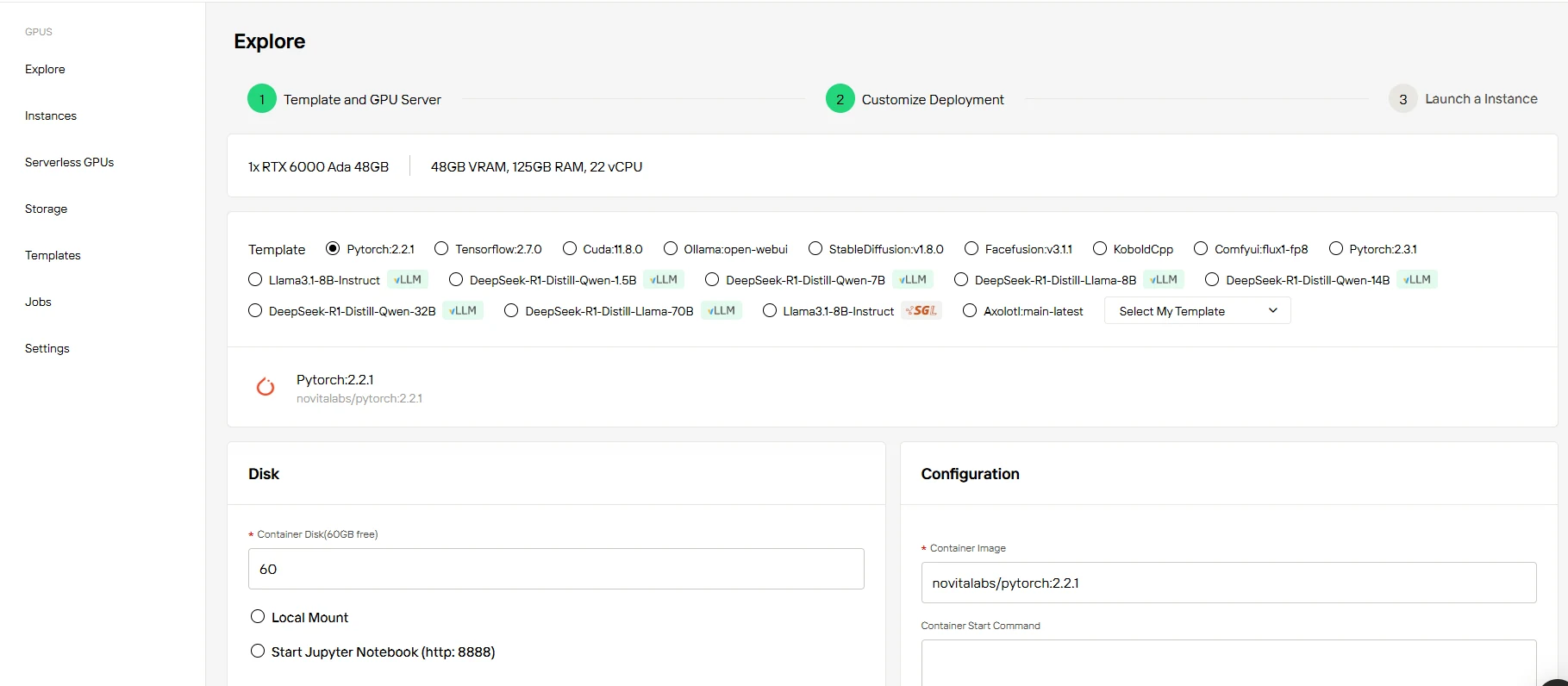
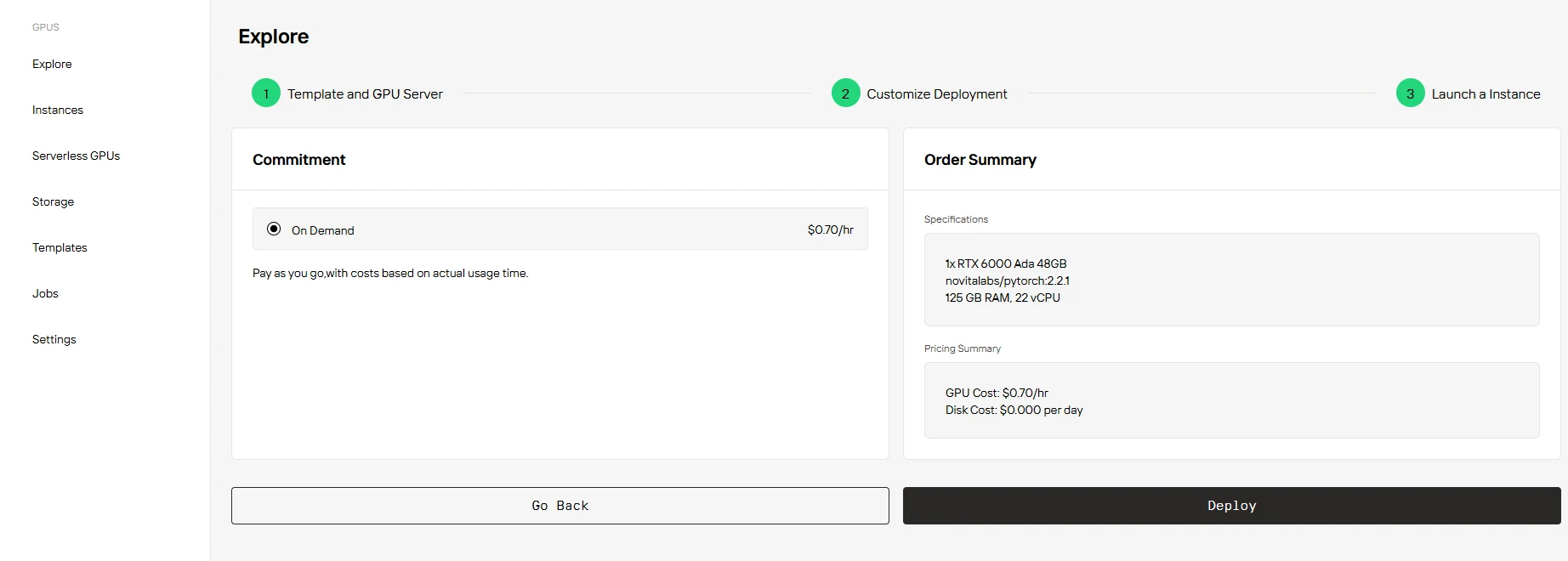
Schritt 4: Starten Sie Ihre Instanz
Wählen Sie einfach „On Demand“, bestätigen Sie Ihre Einstellungen und Preise, und klicken Sie auf „Deploy“, um loszulegen.
Fazit
Die Reise von Hopper zu Blackwell stellt einen bedeutenden Sprung in den KI-Computing-Fähigkeiten dar. Während Hopper neue Maßstäbe für KI-Training und wissenschaftliches Rechnen setzte, verschiebt Blackwell diese Grenzen mit dramatischen Verbesserungen bei Leistung, Effizienz und Vielseitigkeit noch weiter. Diese Entwicklung stärkt nicht nur NVIDIAs technologische Führungsposition, sondern beschleunigt auch die breitere Einführung von KI in allen Branchen. Wenn wir in die Zukunft blicken, werden diese architektonischen Fortschritte weiterhin neue Möglichkeiten in der künstlichen Intelligenz und im wissenschaftlichen Rechnen ermöglichen.
Häufig gestellte Fragen
Was unterscheidet Blackwell Ultra von den standardmäßigen Blackwell GPUs?
Blackwell Ultra repräsentiert den Höhepunkt der Architektur mit zusätzlichen Leistungsverbesserungen, fortschrittlichen Kühllösungen und speziellen Funktionen, die speziell für das Training und die Inferenz großer Sprachmodelle optimiert sind.
Welche GPU-Architektur sollte ich für mein KI-Projekt wählen?
Die optimale Wahl hängt von Ihren spezifischen Anforderungen ab. Hopper ist ideal für etablierte KI-Workloads, während Blackwell überlegene Leistung für Spitzenanwendungen bietet. Novita AI kann auf der Grundlage Ihrer Bedürfnisse persönliche Empfehlungen geben.
Wie schwierig ist die Migration von Workloads von Hopper zu Blackwell?
NVIDIA hat die Softwarekompatibilität zwischen den Generationen beibehalten, sodass die Migration relativ einfach ist. Die meisten für Hopper optimierten Codes laufen ohne Änderungen auf Blackwell, dennoch wird empfohlen, mit dem neuesten CUDA-Toolkit zu kompilieren, um die Blackwell-spezifischen Optimierungen zu nutzen.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell) ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, während sie gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.
Empfohlene Lektüre
GPU Vergleich für KI-Modellierung: Ein umfassender Leitfaden
Wie viel RAM wird für maschinelles Lernen benötigt?
Auswahl der besten GPU für maschinelles Lernen im Jahr 2025: Ein vollständiger Leitfaden



