

- Présentation de l’architecture Hopper de NVIDIA
- Architecture Blackwell : Quoi de neuf et quelles améliorations ?
- Comparaison technique : Hopper vs. Blackwell
- Applications IA réelles de Hopper et Blackwell
- Blackwell Ultra : La prochaine évolution du calcul IA
- Choisissez Novita AI comme partenaire GPU de confiance
- Conclusion
Le paysage du calcul IA connaît une transformation révolutionnaire avec la dernière avancée de NVIDIA, passant des architectures Hopper à Blackwell. En mars 2025, NVIDIA a dévoilé la plateforme Blackwell Ultra AI Factory, marquant un tournant décisif vers l’ère du raisonnement IA. Cette plateforme ne représente pas seulement une amélioration incrémentale, mais un bond transformateur qui permet des capacités sans précédent en matière d’entraînement, de raisonnement et d’inférence IA.
Le passage de Hopper à Blackwell constitue un bond technologique majeur, conçu pour répondre aux exigences évolutives de l’intelligence artificielle (IA) et du calcul haute performance (HPC). Cet article de blog explore les caractéristiques clés des deux architectures, en mettant en lumière leurs avancées techniques et leur impact plus large sur le développement de l’IA.
Présentation de l’architecture Hopper de NVIDIA
Fondations techniques
L’architecture Hopper, nommée d’après la pionnière de l’informatique Grace Hopper, a été construite sur le procédé 4 nm de TSMC. Elle a introduit les Tensor Cores de quatrième génération et a été pionnière du Transformer Engine, spécialement conçu pour accélérer les charges de travail IA. L’architecture intégrait la technologie d’interconnexion NVLink 4.0 et utilisait la mémoire HBM3, établissant de nouvelles normes pour le calcul haute performance.
Indicateurs de performance clés
L’architecture Hopper représente un bond significatif dans la technologie GPU, offrant des améliorations substantielles sur plusieurs indicateurs de performance tout en maintenant l’accent sur l’efficacité des centres de données. Des gains spectaculaires de performance IA à l’amélioration des opérations mémoire et aux capacités d’interconnexion avancées, Hopper s’impose comme une solution complète pour les défis informatiques modernes.
Caractéristiques clés de l’architecture Hopper :
- Améliorations des performances de calcul :
- Prise en charge du format FP8 avec une multiplication par 6 du débit FP32
- Multiplication par 3 des performances FP64
- Multiplication par 30 des performances IA
- Optimisation de la mémoire et des instructions :
- Latence et débit améliorés des opérations mémoire
- Performances optimisées des instructions des cœurs tensoriels
- Technologie d’interconnexion :
- Prise en charge du PCIe Gen 5
- NVLink de quatrième génération
- Capacités d’interconnexion améliorées
- Caractéristiques pour centre de données :
- Accent sur l’efficacité énergétique
- Adapté au déploiement à grande échelle
- Optimisé pour les centres de données avancés et les applications IA
Principales avancées et améliorations
- Transformer Engine : Permet des ajustements dynamiques de précision, optimisant les charges de travail IA.
- Instructions DPX : Améliorent les tâches de programmation dynamique, comme l’alignement de séquences.
- Mémoire partagée distribuée : Améliore la communication multi-GPU et l’évolutivité.
Architecture Blackwell : Quoi de neuf et quelles améliorations ?
Points forts technologiques clés
L’architecture Blackwell, annoncée à GTC 2024, est conçue pour révolutionner l’IA générative et les charges de travail IA à grande échelle. Elle intègre une technologie NVLink avancée, des Tensor Cores personnalisés et un moteur RAS, permettant des modèles IA en temps réel avec jusqu’à 10 000 milliards de paramètres. Blackwell vise à réduire considérablement la consommation d’énergie pour l’inférence IA, jusqu’à 25 fois.
Améliorations significatives des performances
La nouvelle architecture offre des gains de performance sans précédent :
- Multiplication par 3 des performances FP8
- Capacités d’entraînement IA 4 fois plus rapides
- Multiplication par 40 des performances d’inférence
- Rapports d’efficacité énergétique nettement meilleurs
Ces améliorations permettent un entraînement plus rapide de modèles IA plus volumineux et des opérations d’inférence plus efficaces.
Comparaison technique : Hopper vs. Blackwell
La transition de NVIDIA de l’architecture Hopper (H100) à Blackwell (B200) marque un bond technologique significatif dans la conception des GPU. La nouvelle architecture Blackwell montre des améliorations substantielles sur tous les indicateurs clés, avec des avancées notables en nombre de transistors, bande passante mémoire, vitesse d’interconnexion et performance IA.
Le tableau suivant fournit une comparaison détaillée des spécifications entre les deux générations :
| Caractéristique | Hopper (H100) | Blackwell (B200) |
|---|---|---|
| Fabrication | TSMC 4N (80 milliards transistors) | TSMC 4NP (208 milliards transistors) |
| Mémoire | 80 Go HBM3 (3 To/s) | 144 Go HBM3e (4,8 To/s) |
| NVLink | 4e génération (900 Go/s) | 5e génération (1,8 To/s) |
| Performance IA | 4 PFLOPS (FP16) | 20 PFLOPS (FP16) |
| Efficacité énergétique | Référence | Amélioration de 25x en inférence |
| Cas d’usage principaux | Charges de travail IA/HPC générales | IA générative, modèles à des milliards de paramètres |
Applications IA réelles de Hopper et Blackwell
Produits de l’architecture Hopper
L’architecture Hopper est disponible dans plusieurs gammes de produits :
| Produit | H100 SXM | H100 PCIe | H200 SXM |
|---|---|---|---|
| Mémoire | 80 Go HBM3 | 80 Go HBM2e | 141 Go HBM3e |
| Bande passante mémoire | 3,35 To/s | 2,04 To/s | 4,8 To/s |
| NVLink | 900 Go/s | N/A | 900 Go/s |
| TDP max | Jusqu’à 700 W | 350 W | Jusqu’à 700 W |
| GPU multi-instance | Jusqu’à 7 MIG à 10 Go | N/A | Jusqu’à 7 MIG à 16,5 Go |
Produits de l’architecture Blackwell
Blackwell introduit une nouvelle génération d’accélérateurs IA :
| Produit | B100 | B200 | GB200 (Grace Blackwell) |
|---|---|---|---|
| Conception | GPU Blackwell | GPU Blackwell | 2× GPU B200 + CPU Grace |
| Mémoire | 192 Go HBM3e | 192 Go HBM3e | 384 Go HBM3e |
| Bande passante mémoire | 8 To/s | 8 To/s | 16 To/s |
| NVLink | 1,8 To/s (5e gén.) | 1,8 To/s (5e gén.) | 1,8 To/s (5e gén.) |
| Performance FP4 | 7 PFLOPS | 9 PFLOPS | 20 PFLOPS |
| TDP | 700 W | 1 000 W | N/A |
Capacités d’entraînement des modèles d’IA générative
Les deux architectures montrent des capacités exceptionnelles pour l’entraînement de grands modèles IA, Blackwell offrant des vitesses d’entraînement jusqu’à 3 fois plus rapides que Hopper. Les améliorations clés incluent un traitement transformateur amélioré, une bande passante mémoire optimisée et des capacités de parallélisme plus efficaces. Ces architectures permettent l’entraînement de modèles de langage de plus en plus volumineux tout en réduisant la consommation d’énergie et le temps d’entraînement.
Blackwell Ultra : La prochaine évolution du calcul IA
Annoncé le 18 mars 2025 à GTC 2025, Blackwell Ultra représente la dernière évolution de la plateforme de calcul IA de NVIDIA.
Spécifications techniques et améliorations
- La gamme de produits comprend GB300 NVL72 et HGX B300 NVL16
- GB300 NVL72 offre 1,5 fois plus de performance IA que GB200 NVL72
- HGX B300 NVL16 par rapport à l’architecture Hopper permet :
- 11 fois plus rapide en inférence
- 7 fois plus de calcul
- 4 fois plus de mémoire
- Intègre NVIDIA Spectrum-X Ethernet et Quantum-X800 InfiniBand, offrant un débit de données de 800 Gb/s par GPU
- Comprend les DPU BlueField-3 pour le réseau multi-locataire, l’élasticité du calcul GPU et la détection de sécurité en temps réel
Solutions avancées de mémoire et de refroidissement
- Utilise ConnectX-8 SuperNIC pour des capacités RDMA haute performance
- Optimisé pour les usines IA et les centres de données cloud afin d’éliminer les goulots d’étranglement de performance
- Prend en charge plusieurs configurations :
- 72 GPU Blackwell Ultra
- 36 CPU Grace basés sur Arm Neoverse
- Conception à l’échelle du rack fonctionnant comme un seul GPU massif
Fonctionnalités d’optimisation LLM
- Optimisé pour le raisonnement IA et l’IA agentique :
- Prend en charge le raisonnement et la planification itérative pour des problèmes complexes à plusieurs étapes
- Capable de génération de vidéos synthétiques en temps réel pour l’entraînement
- Support logiciel :
- Nouveau framework d’inférence open-source NVIDIA Dynamo
- Support des modèles NVIDIA Llama Nemotron Reason
- Intégration avec la plateforme logicielle NVIDIA AI Enterprise
- Disponibilité prévue via les principaux fabricants de serveurs et fournisseurs de services cloud au second semestre 2025
Choisissez Novita AI comme partenaire GPU de confiance
Alors que le calcul IA continue d’évoluer avec les architectures révolutionnaires de NVIDIA, choisir le bon partenaire cloud GPU devient crucial. Novita AI propose une plateforme complète qui donne accès à des GPU haute performance avec des avantages de coût significatifs.
Si Novita AI vous intéresse, suivez ces étapes pour commencer :
Étape 1 : Créez un compte**
Rendez-vous sur le site de Novita AI pour créer un compte. Après l’inscription, dirigez-vous vers la section « GPUs » pour explorer les ressources disponibles et commencer votre aventure IA.

[Essayez Novita AI dès maintenant](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell)
Étape 2 : Sélectionnez votre GPU****
Notre plateforme propose une variété de modèles préconfigurés adaptés à vos besoins spécifiques, ainsi que la possibilité de créer des modèles personnalisés.
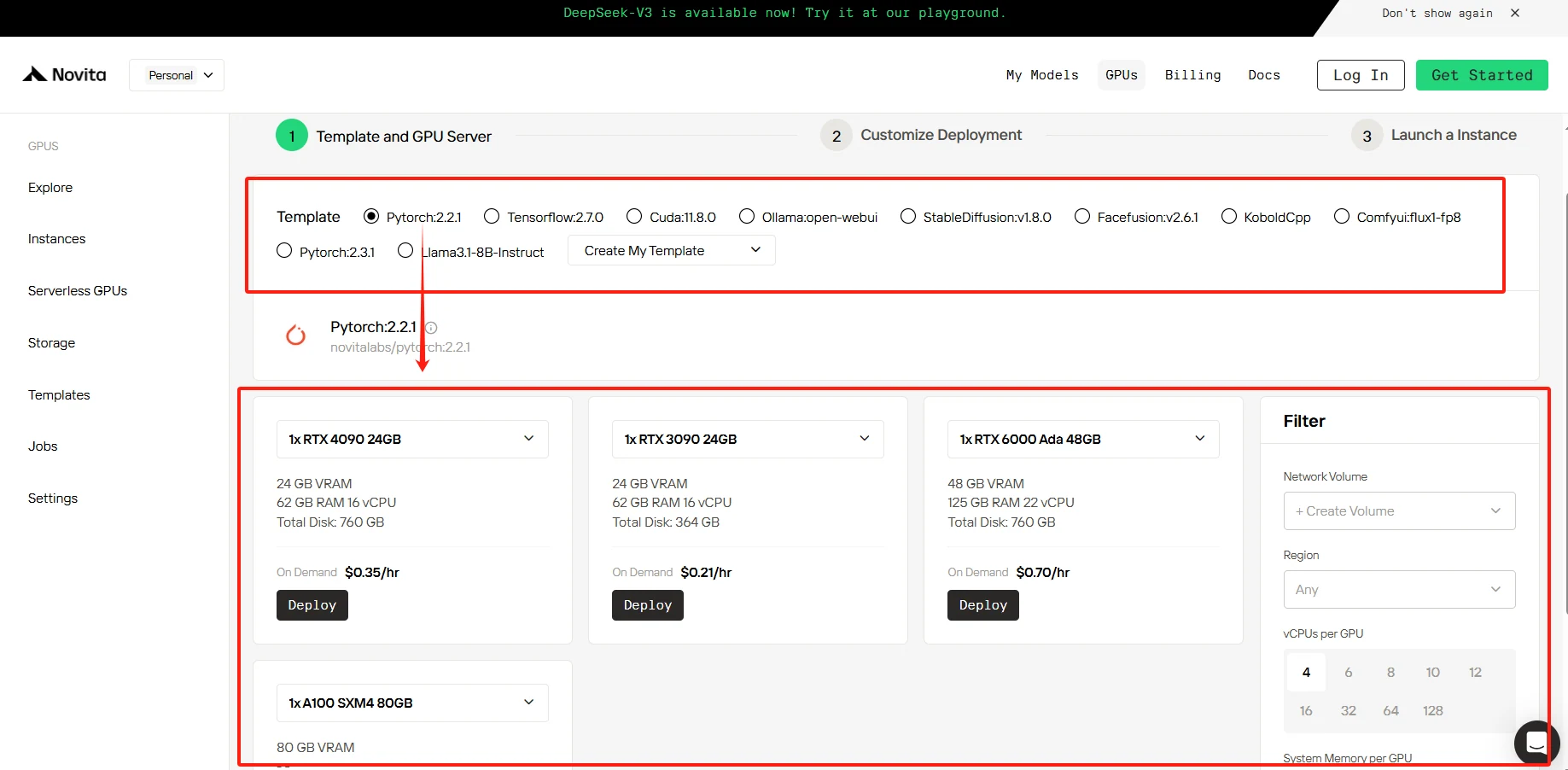
[Essayez les GPU haute performance de Novita AI](https://novita.ai/gpus-console/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell)
Étape 3 : Personnalisez votre configuration****
Lancez votre projet dès aujourd’hui avec 60 Go de stockage conteneur gratuit – sans frais initiaux. Augmentez le stockage à la demande à mesure que vos charges de travail IA grandissent, en ne payant que pour l’espace supplémentaire nécessaire.
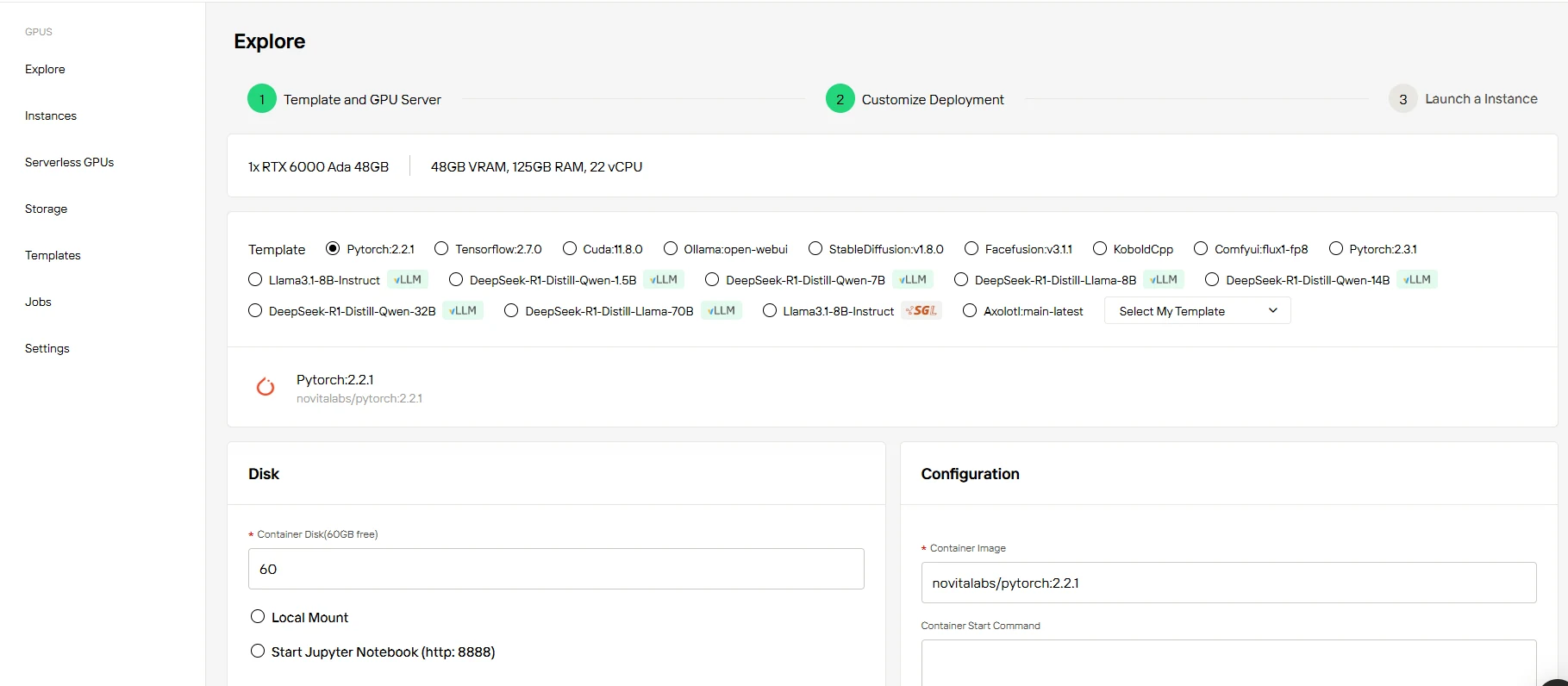
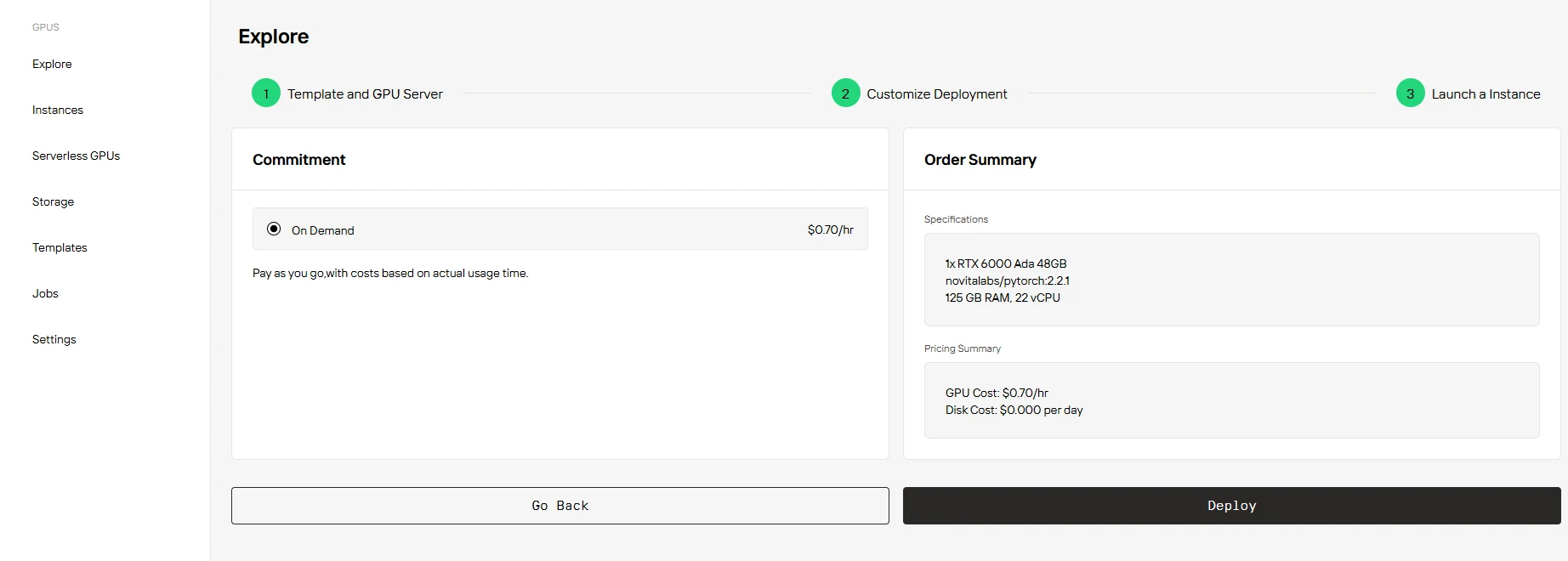
Étape 4 : Lancez votre instance****
Sélectionnez simplement « On Demand », confirmez vos paramètres et le prix, puis cliquez sur « Deploy » pour commencer.
Conclusion
Le passage de Hopper à Blackwell représente un bond significatif dans les capacités de calcul IA. Alors que Hopper a établi de nouvelles normes pour l’entraînement IA et le calcul scientifique, Blackwell repousse ces limites avec des améliorations spectaculaires en matière de performance, d’efficacité et de polyvalence. Cette évolution fait non seulement progresser le leadership technique de NVIDIA, mais accélère également l’adoption plus large de l’IA dans tous les secteurs. En regardant vers l’avenir, ces avancées architecturales continueront de permettre de nouvelles possibilités dans l’intelligence artificielle et le calcul scientifique.
Questions fréquentes
Qu’est-ce qui rend le Blackwell Ultra différent des GPU Blackwell standard ?
Blackwell Ultra représente le sommet de l’architecture avec des améliorations de performance supplémentaires, des solutions de refroidissement avancées et des fonctionnalités spécialisées optimisées spécifiquement pour l’entraînement et l’inférence de grands modèles de langage.
Quelle architecture GPU dois-je choisir pour mon projet IA ?
Le choix optimal dépend de vos besoins spécifiques. Hopper est idéal pour les workflows IA établis, tandis que Blackwell offre des performances supérieures pour les applications de pointe. Novita AI peut fournir des recommandations personnalisées en fonction de vos besoins.
Quelle est la difficulté de migrer des charges de travail de Hopper à Blackwell ?
NVIDIA a maintenu la compatibilité logicielle entre les générations, ce qui rend la migration relativement simple. La plupart des codes optimisés pour Hopper fonctionneront sur Blackwell sans modifications, bien qu’il soit recommandé de recompiler avec le dernier kit CUDA pour profiter des optimisations spécifiques à Blackwell.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell) est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU fiable et abordable pour construire et passer à l’échelle.
Lectures recommandées
Comparaison des GPU pour la modélisation IA : un guide complet
Quelle quantité de RAM est nécessaire pour le machine learning ?
Choisir le meilleur GPU pour le machine learning en 2025 : un guide complet



