

يشهد مشهد الحوسبة الذكية تحولًا ثوريًا مع أحدث تقدّم من NVIDIA من بنية Hopper إلى Blackwell. في مارس 2025، كشفت NVIDIA عن منصة مصنع الذكاء الاصطناعي Blackwell Ultra، مما يمثل تحولًا محوريًا نحو عصر الاستدلال بالذكاء الاصطناعي. لا تمثل هذه المنصة تحسنًا تدريجيًا فحسب، بل قفزة تحويلية تتيح قدرات غير مسبوقة في تدريب الذكاء الاصطناعي والاستدلال والاستنتاج.
تمثل الرحلة من Hopper إلى Blackwell قفزة كبيرة في التكنولوجيا، صُممت لتلبية المتطلبات المتطورة للذكاء الاصطناعي والحوسبة عالية الأداء. ستتناول هذه المدونة الميزات الرئيسية لكلا البنيتين، مع إبراز التطورات التقنية وتأثيرها الأوسع على تطوير الذكاء الاصطناعي.
نظرة عامة على بنية NVIDIA Hopper
الأساس التقني
تم بناء بنية Hopper، التي سُميت على اسم رائدة الحوسبة Grace Hopper، على تقنية معالجة TSMC 4nm. قدمت الجيل الرابع من Tensor Cores ورائدة محول Transformer Engine، المصمم خصيصًا لتسريع أعباء عمل الذكاء الاصطناعي. تضمنت البنية تقنية الترابط NVLink 4.0 واستخدمت ذاكرة HBM3، مما وضع معايير جديدة للحوسبة عالية الأداء.
مقاييس الأداء الرئيسية
تمثل بنية Hopper قفزة كبيرة في تقنية GPU، حيث تقدم تحسينات كبيرة عبر مقاييس أداء متعددة مع الحفاظ على التركيز على كفاءة مراكز البيانات. من التحسينات الهائلة في أداء الذكاء الاصطناعي إلى تحسين عمليات الذاكرة وقدرات الترابط المتقدمة، تثبت Hopper نفسها كحل شامل لتحديات الحوسبة الحديثة.
الميزات الرئيسية لبنية Hopper:
- تحسينات الأداء الحسابي:
- دعم تنسيق FP8 مع زيادة 6 أضعاف في إنتاجية FP32
- تحسين 3 أضعاف في أداء FP64
- زيادة 30 ضعفًا في أداء الذكاء الاصطناعي
- تحسين الذاكرة والتعليمات:
- تحسين زمن انتقال وإنتاجية عمليات الذاكرة
- تحسين أداء تعليمات tensor core
- تقنية الترابط:
- دعم PCIe Gen 5
- الجيل الرابع من NVLink
- قدرات ترابط محسّنة
- خصائص مركز البيانات:
- التركيز على كفاءة الطاقة
- مناسبة للنشر واسع النطاق
- مُحسَّنة لمراكز البيانات المتقدمة وتطبيقات الذكاء الاصطناعي
الاختراقات والتحسينات الكبرى
- Transformer Engine: يتيح تعديلات دقيقة في الدقة، مما يحسّن أعباء عمل الذكاء الاصطناعي.
- تعليمات DPX: تعزز مهام البرمجة الديناميكية، مثل محاذاة التسلسل.
- الذاكرة المشتركة الموزعة: تحسّن الاتصال بين وحدات GPU المتعددة وقابلية التوسع.
بنية Blackwell: ما الجديد والمُحسَّن؟
أبرز النقاط التقنية
تم الإعلان عن بنية Blackwell في مؤتمر GTC 2024، وهي مصممة لإحداث ثورة في الذكاء الاصطناعي التوليدي وأعباء عمل الذكاء الاصطناعي واسعة النطاق. تتميز بتقنية NVLink المتقدمة، و Tensor Cores المخصصة، ومحرك RAS، مما يتيح نماذج ذكاء اصطناعي في الوقت الفعلي تصل إلى 10 تريليونات معلمة. تهدف Blackwell إلى تقليل استهلاك الطاقة للاستدلال بالذكاء الاصطناعي بنسبة تصل إلى 25 مرة.
إبراز التحسينات الكبيرة في الأداء
تقدم البنية الجديدة مكاسب أداء غير مسبوقة:
- تحسين 3 أضعاف في أداء FP8
- قدرات تدريب ذكاء اصطناعي أسرع 4 مرات
- زيادة 40 ضعفًا في أداء الاستدلال
- نسب كفاءة طاقة أفضل بشكل ملحوظ
تتيح هذه التحسينات تدريبًا أسرع لنماذج الذكاء الاصطناعي الأكبر وعمليات استدلال أكثر كفاءة.
المقارنة التقنية: Hopper مقابل Blackwell
يمثل الانتقال من بنية Hopper (H100) إلى Blackwell (B200) قفزة تقنية كبيرة في تصميم GPU. تُظهر بنية Blackwell الجديدة تحسينات جوهرية عبر جميع المقاييس الرئيسية، مع تقدم ملحوظ في عدد الترانزستورات وعرض النطاق الترددي للذاكرة وسرعة الترابط وأداء الذكاء الاصطناعي.
يوفر الجدول التالي مقارنة مفصلة للمواصفات بين الجيلين:
| الميزة | Hopper (H100) | Blackwell (B200) |
|---|---|---|
| التصنيع | TSMC 4N (80 مليار ترانزستور) | TSMC 4NP (208 مليار ترانزستور) |
| الذاكرة | 80 GB HBM3 (3 TB/s) | 144 GB HBM3e (4.8 TB/s) |
| NVLink | الجيل الرابع (900 GB/s) | الجيل الخامس (1.8 TB/s) |
| أداء الذكاء الاصطناعي | 4 PFLOPS (FP16) | 20 PFLOPS (FP16) |
| كفاءة الطاقة | خط الأساس | تحسين 25 ضعفًا في الاستدلال |
| حالات الاستخدام الرئيسية | أعباء عمل الذكاء الاصطناعي / HPC العامة | الذكاء الاصطناعي التوليدي، نماذج تريليون المعلمة |
Hopper و Blackwell في تطبيقات الذكاء الاصطناعي الواقعية
منتجات بنية Hopper
بنية Hopper متوفرة عبر عدة خطوط إنتاج:
| المنتج | H100 SXM | H100 PCIe | H200 SXM |
|---|---|---|---|
| الذاكرة | 80GB HBM3 | 80GB HBM2e | 141GB HBM3e |
| عرض النطاق الترددي للذاكرة | 3.35 TB/s | 2.04 TB/s | 4.8 TB/s |
| NVLink | 900 GB/s | غير متاح | 900 GB/s |
| أقصى TDP | حتى 700W | 350W | حتى 700W |
| وحدات GPU متعددة المثيلات | حتى 7 MIGs بسعة 10GB | غير متاح | حتى 7 MIGs بسعة 16.5GB |
منتجات بنية Blackwell
تقدم Blackwell جيلًا جديدًا من مسرعات الذكاء الاصطناعي:
| المنتج | B100 | B200 | GB200 (Grace Blackwell) |
|---|---|---|---|
| التصميم | GPU Blackwell | GPU Blackwell | وحدتا GPU B200 + وحدة معالجة مركزية Grace |
| الذاكرة | 192GB HBM3e | 192GB HBM3e | 384GB HBM3e |
| عرض النطاق الترددي للذاكرة | 8 TB/s | 8 TB/s | 16 TB/s |
| NVLink | 1.8 TB/s (الجيل الخامس) | 1.8 TB/s (الجيل الخامس) | 1.8 TB/s (الجيل الخامس) |
| أداء FP4 | 7 PFLOPS | 9 PFLOPS | 20 PFLOPS |
| TDP | 700W | 1000W | غير متاح |
قدرات تدريب نماذج الذكاء الاصطناعي التوليدي
تُظهر كلتا البنيتين قدرات استثنائية في تدريب نماذج الذكاء الاصطناعي الكبيرة، حيث تظهر Blackwell سرعات تدريب أسرع تصل إلى 3 أضعاف مقارنة بـ Hopper. تشمل التحسينات الرئيسية معالجة Transformer المحسّنة وعرض النطاق الترددي للذاكرة المحسّن وقدرات معالجة متوازية أكثر كفاءة. تتيح البنيتان تدريب نماذج لغة متزايدة الضخامة مع تقليل استهلاك الطاقة ووقت التدريب.
Blackwell Ultra: التطور التالي في الحوسبة الذكية
أُعلن عنه في 18 مارس 2025 في مؤتمر GTC 2025، ويمثل Blackwell Ultra أحدث تطور لمنصة الحوسبة الذكية من NVIDIA.
المواصفات التقنية والتحسينات
- يتضمن خط الإنتاج GB300 NVL72 و HGX B300 NVL16
- يوفر GB300 NVL72 أداء ذكاء اصطناعي أكبر بنسبة 1.5x مقارنة بـ GB200 NVL72
- بالمقارنة مع بنية Hopper، يحقق HGX B300 NVL16 ما يلي:
- استدلال أسرع 11 مرة
- حوسبة أكبر 7 مرات
- ذاكرة أكبر 4 مرات
- يدمج NVIDIA Spectrum-X Ethernet و Quantum-X800 InfiniBand، مما يوفر إنتاجية بيانات تبلغ 800 جيجابت/ثانية لكل GPU
- يتميز بوحدات BlueField-3 DPU للاتصال متعدد المستأجرين ومرونة حوسبة GPU واكتشاف الأمان في الوقت الفعلي
حلول الذاكرة والتبريد المتقدمة
- يستخدم ConnectX-8 SuperNIC لقدرات RDMA عالية الأداء
- مُحسَّن لمصانع الذكاء الاصطناعي ومراكز البيانات السحابية للتخلص من اختناقات الأداء
- يدعم تكوينات متنوعة:
- 72 GPU من Blackwell Ultra
- 36 وحدة معالجة مركزية Grace تعتمد على Arm Neoverse
- تصميم على مستوى الرف يعمل كوحدة GPU عملاقة واحدة
ميزات تحسين LLM
- مُحسَّن للاستدلال بالذكاء الاصطناعي والذكاء الاصطناعي العامل:
- يدعم الاستدلال والتخطيط التكراري للمشكلات المعقدة متعددة الخطوات
- قادر على توليد فيديو اصطناعي في الوقت الفعلي للتدريب
- الدعم البرمجي:
- إطار عمل NVIDIA Dynamo الجديد مفتوح المصدر للاستدلال
- دعم نماذج NVIDIA Llama Nemotron Reason
- التكامل مع منصة برمجيات NVIDIA AI Enterprise
- من المتوقع أن يتوفر عبر كبار مصنعي الخوادم ومزودي الخدمات السحابية في النصف الثاني من عام 2025
اختر Novita AI كشريك GPU الموثوق
مع استمرار تطور الحوسبة الذكية مع بنى NVIDIA الرائدة، يصبح اختيار شريك GPU السحابي المناسب أمرًا بالغ الأهمية. تقدم Novita AI منصة شاملة توفر الوصول إلى وحدات GPU عالية الأداء مع مزايا كبيرة في التكلفة.
إذا كنت مهتمًا بـ Novita AI، فاتبع هذه الخطوات للبدء:
الخطوة1: إنشاء حساب
قم بزيارة موقع Novita AI الإلكتروني لإنشاء حساب. بعد الانتهاء من التسجيل، انتقل إلى قسم “GPUs” لاستكشاف الموارد المتاحة وبدء رحلتك مع الذكاء الاصطناعي.

الخطوة2: اختر GPU الخاص بك
تقدم منصتنا مجموعة متنوعة من القوالب المعدة مسبقًا والمصممة خصيصًا لتلبية متطلباتك المحددة، بالإضافة إلى المرونة لإنشاء قوالب مخصصة حسب الحاجة.
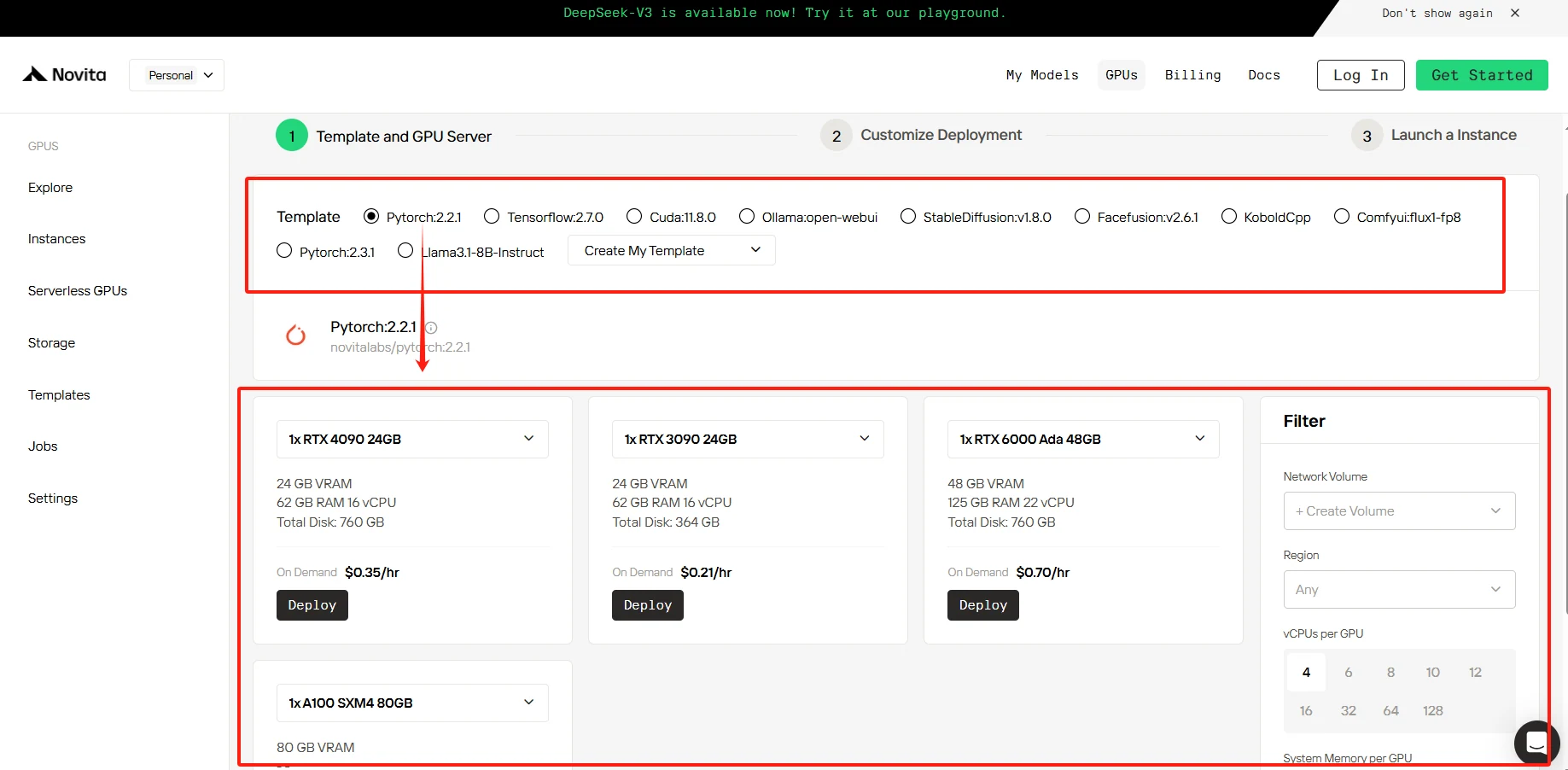
جرب وحدات GPU عالية الأداء من Novita AI
الخطوة3: تخصيص الإعداد الخاص بك
أطلق مشروعك اليوم مع 60 جيجابايت من تخزين الحاويات المجاني - بدون تكاليف مسبقة. قم بتوسيع سعة التخزين حسب الطلب مع نمو أعباء عمل الذكاء الاصطناعي الخاصة بك، وادفع فقط مقابل المساحة الإضافية التي تحتاجها.
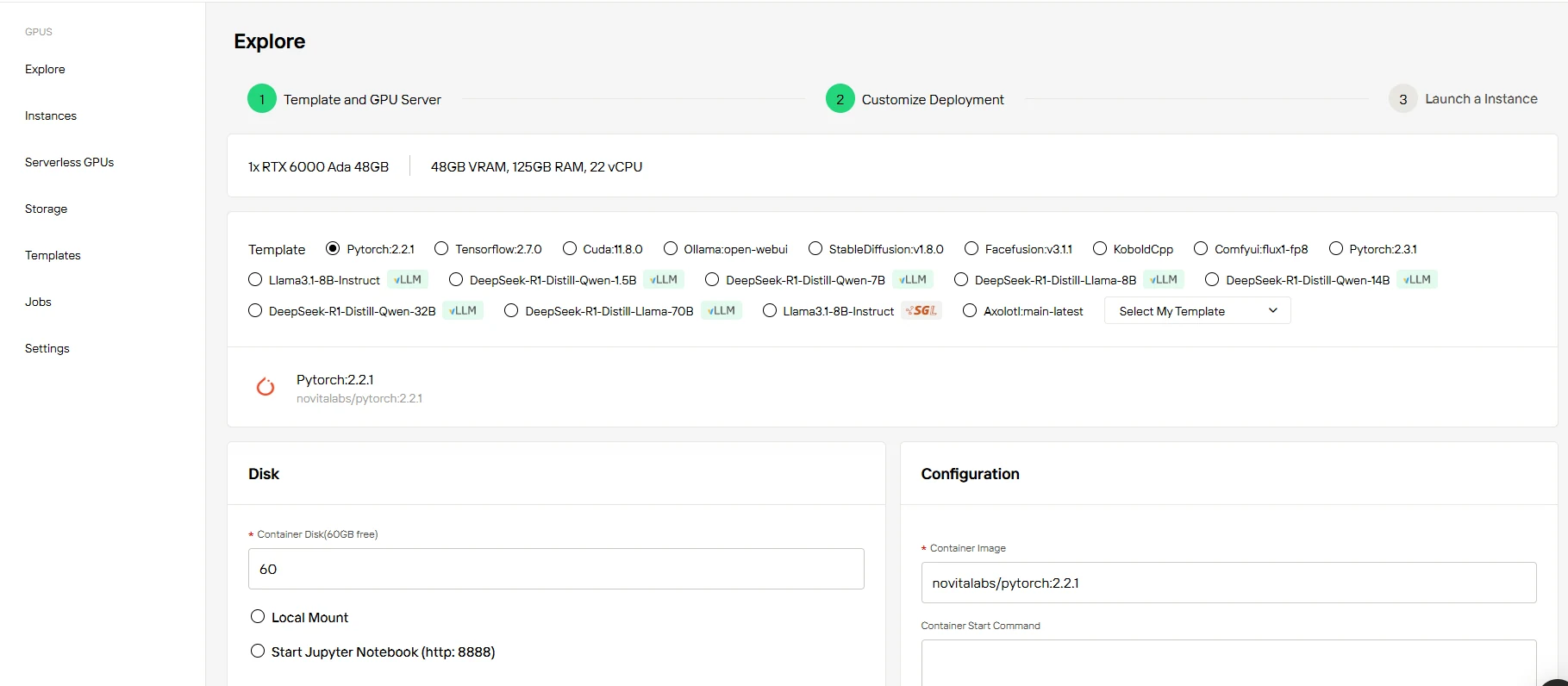
الخطوة4: تشغيل المثيل الخاص بك
ما عليك سوى تحديد “عند الطلب”، وتأكيد الإعدادات والتسعير، ثم النقر على “نشر” للبدء.
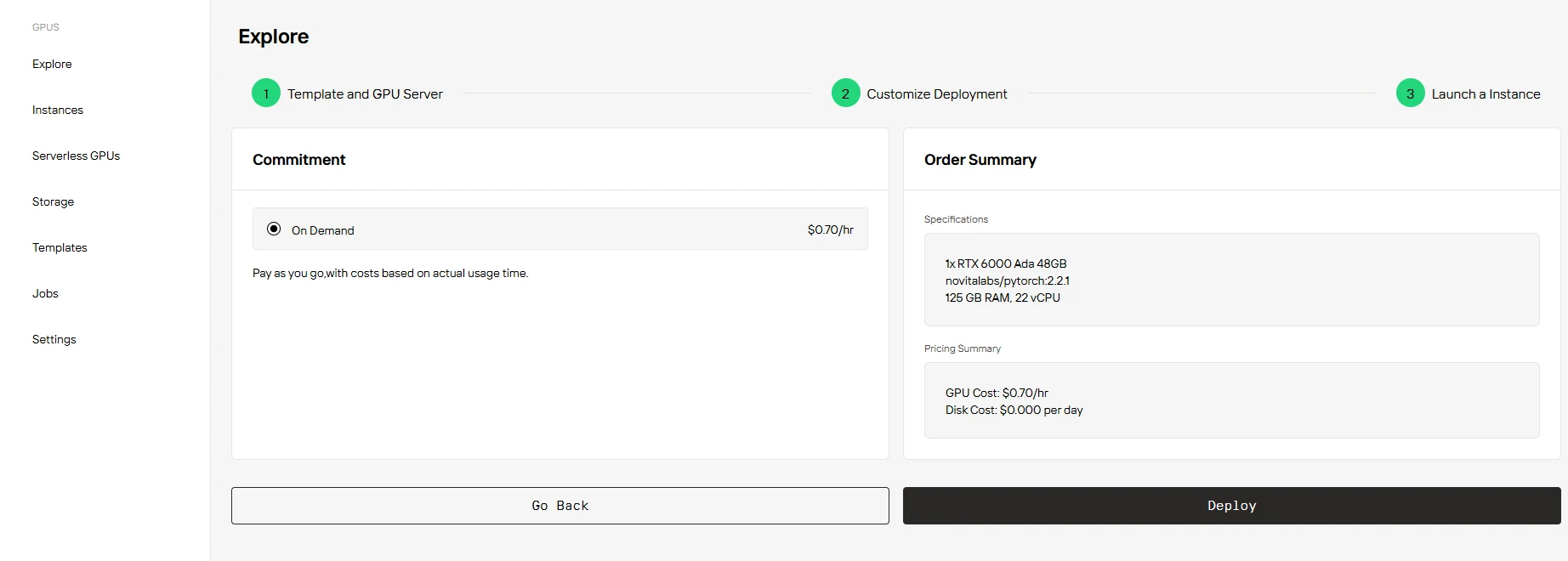
الخاتمة
تمثل الرحلة من Hopper إلى Blackwell قفزة كبيرة في قدرات الحوسبة الذكية. بينما وضعت Hopper معايير جديدة لتدريب الذكاء الاصطناعي والحوسبة العلمية، تدفع Blackwell هذه الحدود أكثر مع تحسينات دراماتيكية في الأداء والكفاءة والتنوع. لا يعزز هذا التطور الريادة التقنية لـ NVIDIA فحسب، بل يسرع أيضًا من التبني الأوسع للذكاء الاصطناعي عبر الصناعات. بينما نتطلع إلى المستقبل، ستستمر هذه التطورات المعمارية في تمكين إمكانيات جديدة في الذكاء الاصطناعي والحوسبة العلمية.
الأسئلة الشائعة
ما الذي يجعل Blackwell Ultra مختلفًا عن وحدات GPU Blackwell القياسية؟
يمثل Blackwell Ultra قمة البنية مع تحسينات أداء إضافية وحلول تبريد متقدمة وميزات متخصصة مُحسَّنة خصيصًا لتدريب نماذج اللغة الكبيرة والاستدلال.
أي بنية GPU يجب أن أختارها لمشروع الذكاء الاصطناعي الخاص بي؟
يعتمد الاختيار الأمثل على متطلباتك المحددة. Hopper مثالي لسير عمل الذكاء الاصطناعي الراسخ، بينما تقدم Blackwell أداءً فائقًا للتطبيقات المتطورة. يمكن لـ Novita AI تقديم توصيات مخصصة بناءً على احتياجاتك.
ما مدى صعوبة ترحيل أعباء العمل من Hopper إلى Blackwell؟
حافظت NVIDIA على التوافق البرمجي بين الأجيال، مما يجعل الترحيل بسيطًا نسبيًا. معظم الكود المحسّن لـ Hopper سيعمل على Blackwell دون تعديلات، على الرغم من أنه يُوصى بإعادة الترجمة باستخدام أحدث مجموعة أدوات CUDA للاستفادة من التحسينات الخاصة بـ Blackwell.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة لدينا، مع توفير GPU سحابي ميسور التكلفة وموثوق للبناء والتوسع.
قراءة موصى بها
مقارنة GPU لنمذجة الذكاء الاصطناعي: دليل شامل



