

AI 運算的格局正因 NVIDIA 從 Hopper 到 Blackwell 架構的最新進展,見證一場革命性的轉變。2025 年 3 月,NVIDIA 發表了 Blackwell Ultra AI 工廠平台,標誌著邁向 AI 推理時代的關鍵轉折點。此平台不僅是漸進式的改進,更是一次變革性的飛躍,實現了 AI 訓練、推理和推論上前所未有的能力。
從 Hopper 到 Blackwell 的歷程,代表了一項重大的技術飛躍,旨在滿足人工智慧(AI)與高效能運算(HPC)不斷演進的需求。本文將深入探討兩種架構的主要特性,強調其技術進展以及對 AI 發展的廣泛影響。
NVIDIA Hopper 架構概覽
技術基礎
Hopper 架構以運算先驅 Grace Hopper 命名,採用台積電 4nm 製程技術。它引入了第四代 Tensor Core,並開創了 Transformer Engine,專門設計用於加速 AI 工作負載。該架構配備了 NVLink 4.0 互連技術,並採用 HBM3 記憶體,為高效能運算樹立了新標竿。
主要效能指標
Hopper 架構代表了 GPU 技術的重大躍進,在多項效能指標上帶來顯著提升,同時維持對資料中心效率的重視。從 AI 效能的驚人提升、到記憶體操作的增強,以及先進的互連能力,Hopper 為現代運算挑戰提供了全面的解決方案。
Hopper 架構的主要特色:
- 計算效能提升:
- 支援 FP8 格式,FP32 吞吐量提升 6 倍
- FP64 效能提升 3 倍
- AI 效能提升 30 倍
- 記憶體與指令最佳化:
- 改善記憶體操作延遲與吞吐量
- 最佳化 tensor core 指令效能
- 互連技術:
- 支援 PCIe Gen 5
- 第四代 NVLink
- 增強互連能力
- 資料中心特性:
- 注重能源效率
- 適合大規模部署
- 針對先進資料中心與 AI 應用最佳化
重大突破與改進
- Transformer Engine:實現動態精度調整,最佳化 AI 工作負載。
- DPX 指令:增強動態規劃任務(如序列比對)。
- 分散式共享記憶體:改善多 GPU 通訊與可擴展性。
Blackwell 架構:新穎之處與改進
關鍵技術亮點
Blackwell 架構在 GTC 2024 上發表,旨在徹底改變生成式 AI 與大規模 AI 工作負載。它配備了先進的 NVLink 技術、自訂 Tensor Core 以及 RAS 引擎,能夠支援多達 10 兆個參數的即時 AI 模型。Blackwell 的目標是將 AI 推論的能源消耗減少高達 25 倍。
突出顯著的效能提升
新架構帶來了前所未有的效能增益:
- FP8 效能提升 3 倍
- AI 訓練速度提升 4 倍
- 推論效能提升 40 倍
- 顯著改善的能效比
這些改進使得更大 AI 模型的訓練更快速,推論操作也更有效率。
技術比較:Hopper 與 Blackwell
NVIDIA 從 Hopper(H100)到 Blackwell(B200)架構的轉型,標誌著 GPU 設計上的一項重大技術飛躍。新的 Blackwell 架構在所有關鍵指標上均展現顯著進步,尤其是在電晶體數量、記憶體頻寬、互連速度與 AI 效能方面。
下表提供了兩代規格的詳細比較:
| 特點 | Hopper(H100) | Blackwell(B200) |
|---|---|---|
| 製程 | TSMC 4N(800 億電晶體) | TSMC 4NP(2080 億電晶體) |
| 記憶體 | 80 GB HBM3(3 TB/s) | 144 GB HBM3e(4.8 TB/s) |
| NVLink | 第四代(900 GB/s) | 第五代(1.8 TB/s) |
| AI 效能 | 4 PFLOPS(FP16) | 20 PFLOPS(FP16) |
| 能源效率 | 基準線 | 推論提升 25 倍 |
| 主要應用 | 廣泛 AI/HPC 工作負載 | 生成式 AI、兆參數模型 |
Hopper 與 Blackwell 在實際 AI 應用中的表現
Hopper 架構產品
Hopper 架構可應用於多條產品線:
| 產品 | H100 SXM | H100 PCIe | H200 SXM |
|---|---|---|---|
| 記憶體 | 80GB HBM3 | 80GB HBM2e | 141GB HBM3e |
| 記憶體頻寬 | 3.35 TB/s | 2.04 TB/s | 4.8 TB/s |
| NVLink | 900 GB/s | 不適用 | 900 GB/s |
| 最大 TDP | 高達 700W | 350W | 高達 700W |
| 多實例 GPU | 最多 7 個 MIG @10GB | 不適用 | 最多 7 個 MIG @16.5GB |
Blackwell 架構產品
Blackwell 推出了新一代 AI 加速器:
| 產品 | B100 | B200 | GB200(Grace Blackwell) |
|---|---|---|---|
| 設計 | Blackwell GPU | Blackwell GPU | 2× B200 GPU + Grace CPU |
| 記憶體 | 192GB HBM3e | 192GB HBM3e | 384GB HBM3e |
| 記憶體頻寬 | 8 TB/s | 8 TB/s | 16 TB/s |
| NVLink | 1.8 TB/s(第五代) | 1.8 TB/s(第五代) | 1.8 TB/s(第五代) |
| FP4 效能 | 7 PFLOPS | 9 PFLOPS | 20 PFLOPS |
| TDP | 700W | 1000W | 不適用 |
生成式 AI 模型訓練能力
兩種架構在訓練大型 AI 模型方面均展現卓越能力,其中 Blackwell 的訓練速度比 Hopper 快高達 3 倍。主要改進包括強化 Transformer 處理、最佳化記憶體頻寬,以及更高效的平行處理能力。這些架構能夠訓練越來越大的語言模型,同時降低功耗與訓練時間。
Blackwell Ultra:AI 運算的下一階段演進
Blackwell Ultra 於 2025 年 3 月 18 日在 GTC 2025 上發表,代表 NVIDIA AI 運算平台的最新演進。
技術規格與改進
- 產品線包括 GB300 NVL72 與 HGX B300 NVL16
- GB300 NVL72 的 AI 效能比 GB200 NVL72 提升 1.5 倍
- HGX B300 NVL16 與 Hopper 架構相比:
- 推論速度提升 11 倍
- 運算能力提升 7 倍
- 記憶體容量提升 4 倍
- 整合 NVIDIA Spectrum-X 乙太網路與 Quantum-X800 InfiniBand,提供每 GPU 800Gb/s 的資料吞吐量
- 配備 BlueField-3 DPU,支援多租戶網路、GPU 運算彈性與即時安全偵測
先進記憶體與冷卻解決方案
- 採用 ConnectX-8 SuperNIC,實現高效能 RDMA 能力
- 針對 AI 工廠與雲端資料中心最佳化,消除效能瓶頸
- 支援多種配置:
- 72 顆 Blackwell Ultra GPU
- 36 顆 Arm Neoverse 架構的 Grace CPU
- 機櫃級設計,如同單一大型 GPU 運作
LLM 最佳化功能
- 針對 AI 推理與代理式 AI 最佳化:
- 支援推理與迭代規劃,處理複雜多步驟問題
- 能夠即時生成合成影片進行訓練
- 軟體支援:
- 全新開源 NVIDIA Dynamo 推論框架
- 支援 NVIDIA Llama Nemotron Reason 模型
- 整合 NVIDIA AI Enterprise 軟體平台
- 預計於 2025 年下半年透過主要伺服器製造商與雲端服務供應商提供
選擇 Novita AI 作為您信賴的 GPU 合作夥伴
隨著 AI 運算持續因 NVIDIA 的革命性架構而演進,選擇正確的 GPU 雲端合作夥伴變得至關重要。Novita AI 提供一個全面的平台,讓您能夠以顯著的成本優勢存取高效能 GPU。
如果您對 Novita AI 感興趣,請按照以下步驟開始:
步驟 1:建立 ** 帳戶
造訪 Novita AI 網站註冊帳戶。完成註冊後,前往 「GPUs」 區段探索可用資源,展開您的 AI 旅程。

[立即試用 Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell)
步驟 2: 選擇您的 GPU****
我們的平台提供多種預先配置的範本,滿足您的特定需求,同時也提供自訂範本的靈活性。
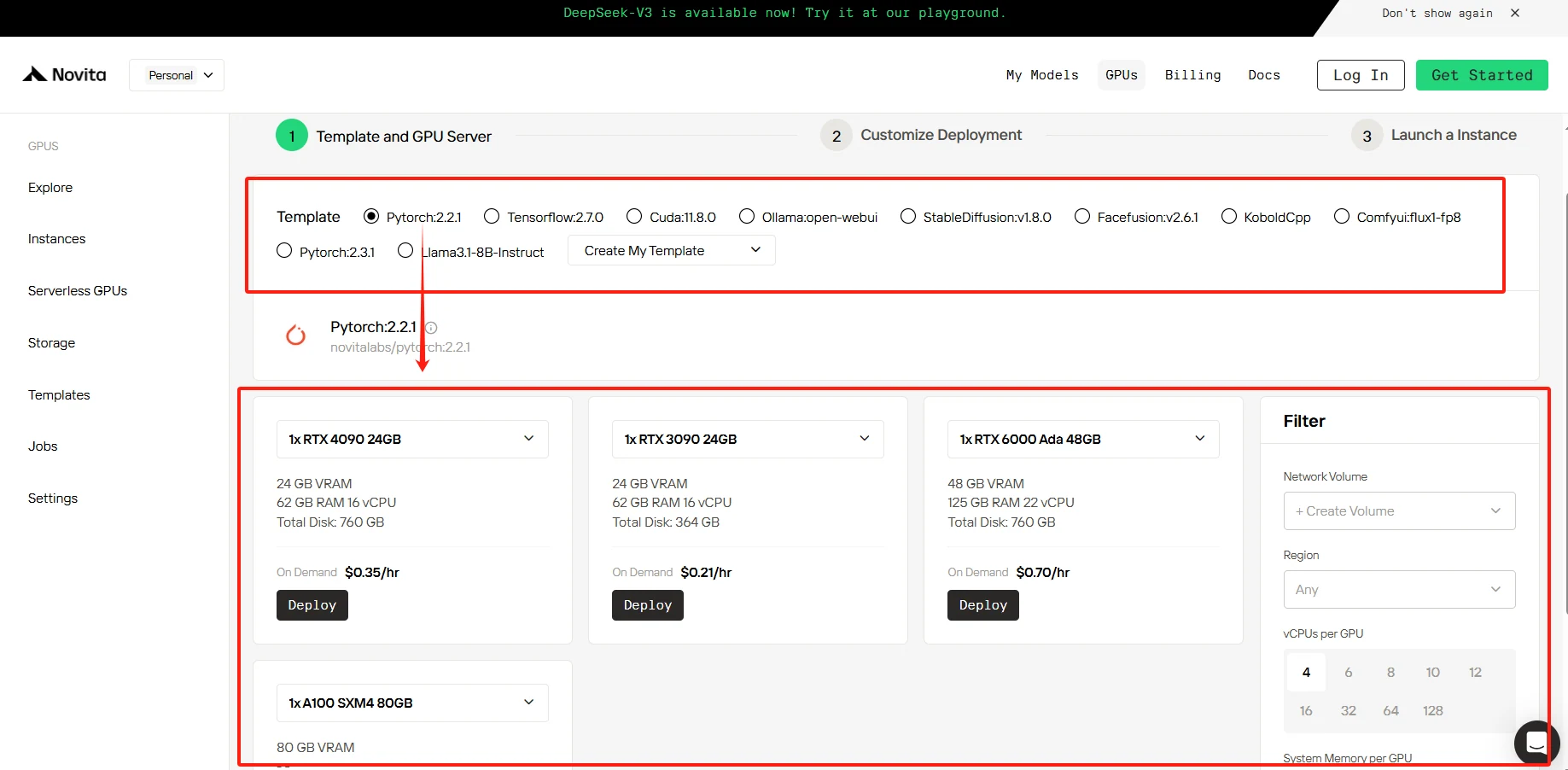
[試用 Novita AI 的高效能 GPU](https://novita.ai/gpus-console/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell)
步驟 3: 自訂您的設定****
立即以 60GB 免費容器儲存空間啟動您的專案,無須前期成本。隨著 AI 工作負載成長,按需擴展儲存空間,僅需為您使用的額外空間付費。
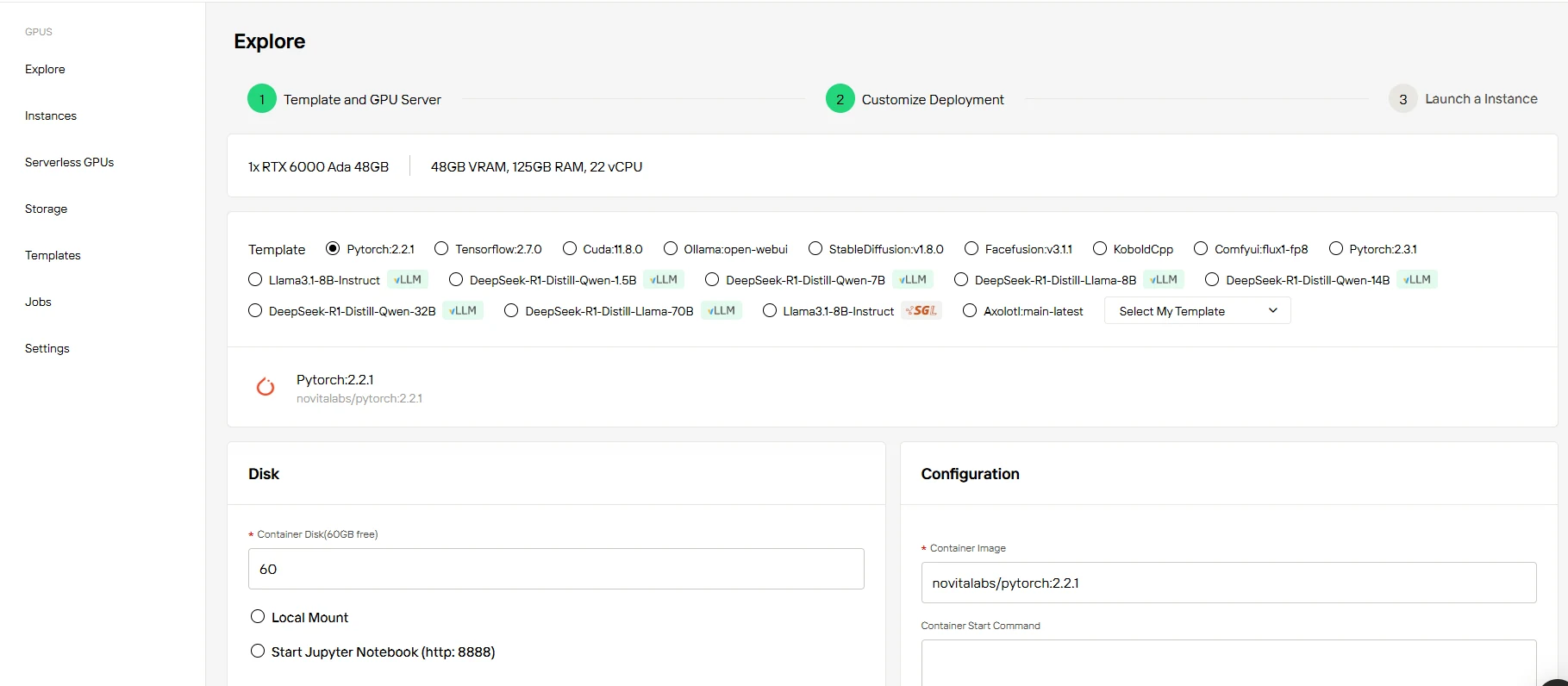
步驟 4: 啟動您的實例****
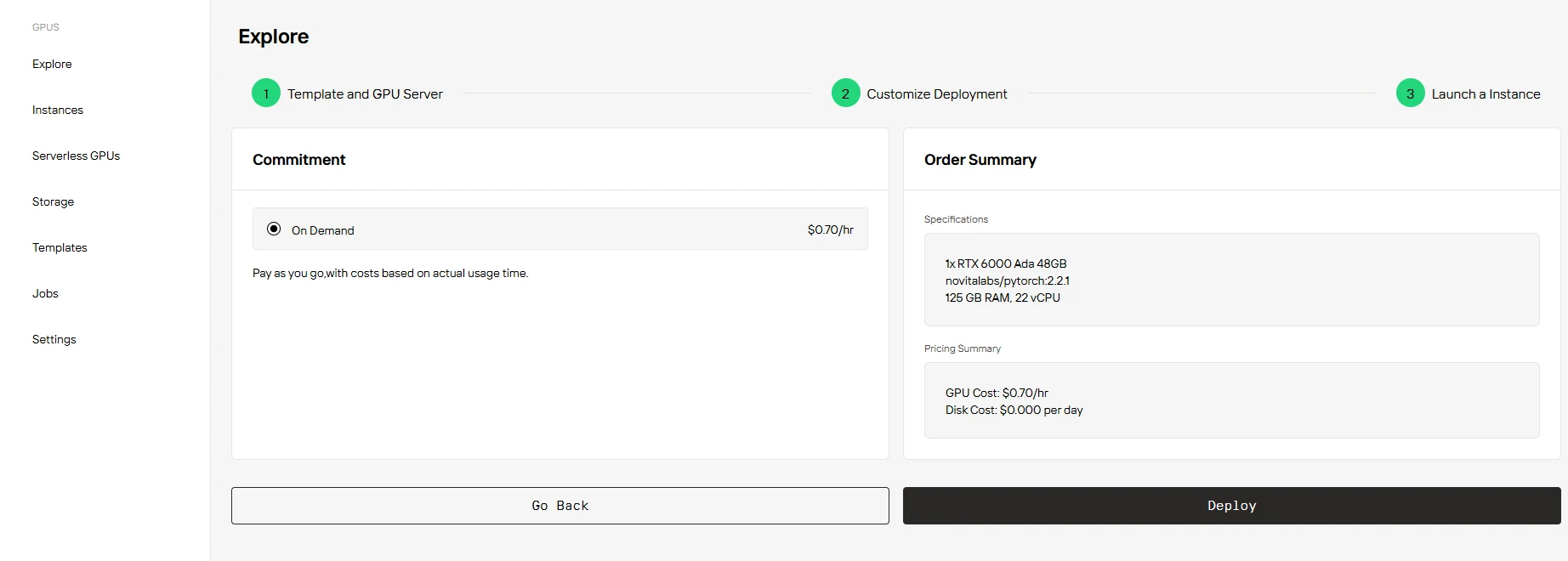
只需選擇 「On Demand」,確認設定與定價,然後按一下 「Deploy」 即可開始。
結論
從 Hopper 到 Blackwell 的歷程代表了 AI 運算能力的重大躍進。Hopper 為 AI 訓練與科學運算樹立了新標竿,而 Blackwell 則透過效能、效率與多功能性的巨大改進,進一步突破這些界限。這場演進不僅強化了 NVIDIA 的技術領導地位,也加速了 AI 在跨產業中的廣泛採用。展望未來,這些架構上的進展將持續為人工智慧與科學運算開啟新的可能性。
常見問題
Blackwell Ultra 與標準 Blackwell GPU 有何不同?
Blackwell Ultra 代表該架構的頂峰,具備額外的效能強化、先進冷卻解決方案,以及專門針對大型語言模型訓練與推論最佳化的功能。
我應該為我的 AI 專案選擇哪種 GPU 架構?
最佳選擇取決於您的特定需求。Hopper 適合既有的 AI 工作流程,而 Blackwell 則為尖端應用提供卓越效能。Novita AI 可根據您的需求提供個人化建議。
從 Hopper 遷移工作負載到 Blackwell 有多困難?
NVIDIA 保持了世代間的軟體相容性,使遷移相對直接。大多數為 Hopper 最佳化的程式碼無需修改即可在 Blackwell 上執行,但建議使用最新的 CUDA 工具套件重新編譯,以充分利用 Blackwell 特有的最佳化功能。
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell) 是一個 AI 雲端平台,為開發者提供透過簡單 API 部署 AI 模型的便利方式,同時也提供經濟且可靠的 GPU 雲端,用於建構與擴展應用。
推薦閱讀



