

The landscape of AI computing is witnessing a revolutionary transformation with NVIDIA’s latest advancement from Hopper to Blackwell architectures. In March 2025, NVIDIA unveiled the Blackwell Ultra AI factory platform, marking a pivotal shift toward the age of AI reasoning. This platform represents not just an incremental improvement but a transformative leap that enables unprecedented capabilities in AI training, reasoning, and inference.
The journey from Hopper to Blackwell represents a significant leap in technology, designed to meet the evolving demands of artificial intelligence (AI) and high-performance computing (HPC). This blog will delve into the key features of both architectures, highlighting their technical advancements and the broader impact on AI development.
Overview of NVIDIA’s Hopper Architecture
Technical Foundation
The Hopper architecture, named after computing pioneer Grace Hopper, was built on TSMC’s 4nm process technology. It introduced the fourth-generation Tensor Cores and pioneered the Transformer Engine, specifically designed to accelerate AI workloads. The architecture featured NVLink 4.0 interconnect technology and utilized HBM3 memory, setting new standards for high-performance computing.
Key Performance Metrics
The Hopper architecture represents a significant leap in GPU technology, delivering substantial improvements across multiple performance metrics while maintaining focus on data center efficiency. From dramatic AI performance boosts to enhanced memory operations and advanced interconnect capabilities, Hopper establishes itself as a comprehensive solution for modern computing challenges.
Key features of the Hopper architecture:
- Computational Performance Improvements:
- FP8 format support with 6x FP32 throughput increase
- 3x improvement in FP64 performance
- 30x boost in AI performance
- Memory and Instruction Optimization:
- Enhanced memory operation latency and throughput
- Optimized tensor core instruction performance
- Interconnect Technology:
- PCIe Gen 5 support
- Fourth-generation NVLink
- Enhanced interconnectivity capabilities
- Data Center Characteristics:
- Focus on energy efficiency
- Suitable for large-scale deployment
- Optimized for advanced data centers and AI applications
Major Breakthroughs and Improvements
- Transformer Engine: Enables dynamic precision adjustments, optimizing AI workloads.
- DPX Instructions: Enhance dynamic programming tasks, such as sequence alignment.
- Distributed Shared Memory: Improves multi-GPU communication and scalability.
Blackwell Architecture: What’s New and Improved?
Key technological highlights
The Blackwell architecture, announced at GTC 2024, is designed to revolutionize generative AI and large-scale AI workloads. It features advanced NVLink technology, custom Tensor Cores, and a RAS engine, enabling real-time AI models with up to 10 trillion parameters. Blackwell aims to significantly reduce energy usage for AI inference by up to 25 times.
Highlight significant performance improvements
The new architecture delivers unprecedented performance gains:
- 3x improvement in FP8 performance
- 4x faster AI training capabilities
- 40x boost in inference performance
- Significantly better power efficiency ratios
These improvements enable faster training of larger AI models and more efficient inference operations.
Technical Comparison: Hopper vs. Blackwell
NVIDIA’s transition from Hopper (H100) to Blackwell (B200) architecture marks a significant technological leap in GPU design. The new Blackwell architecture demonstrates substantial improvements across all key metrics, with notable advancements in transistor count, memory bandwidth, interconnect speed, and AI performance.
The following table provides a detailed comparison of specifications between the two generations:
| Feature | Hopper (H100) | Blackwell (B200) |
|---|---|---|
| Fabrication | TSMC 4N (80B transistors) | TSMC 4NP (208B transistors) |
| Memory | 80 GB HBM3 (3 TB/s) | 144 GB HBM3e (4.8 TB/s) |
| NVLink | 4th-gen (900 GB/s) | 5th-gen (1.8 TB/s) |
| AI Performance | 4 PFLOPS (FP16) | 20 PFLOPS (FP16) |
| Energy Efficiency | Baseline | 25x improvement in inference |
| Key Use Cases | Broad AI/HPC workloads | Generative AI, trillion-param models |
Hopper and Blackwell in Real-World AI Applications
Hopper Architecture Products
The Hopper architecture is available across several product lines:
| Product | H100 SXM | H100 PCIe | H200 SXM |
|---|---|---|---|
| Memory | 80GB HBM3 | 80GB HBM2e | 141GB HBM3e |
| Memory Bandwidth | 3.35 TB/s | 2.04 TB/s | 4.8 TB/s |
| NVLink | 900 GB/s | N/A | 900 GB/s |
| Max TDP | Up to 700W | 350W | Up to 700W |
| Multi-Instance GPUs | Up to 7 MIGs @10GB | N/A | Up to 7 MIGs @16.5GB |
Blackwell Architecture Products
Blackwell introduces a new generation of AI accelerators:
| Product | B100 | B200 | GB200 (Grace Blackwell) |
|---|---|---|---|
| Design | Blackwell GPU | Blackwell GPU | 2× B200 GPUs + Grace CPU |
| Memory | 192GB HBM3e | 192GB HBM3e | 384GB HBM3e |
| Memory Bandwidth | 8 TB/s | 8 TB/s | 16 TB/s |
| NVLink | 1.8 TB/s (5th-gen) | 1.8 TB/s (5th-gen) | 1.8 TB/s (5th-gen) |
| FP4 Performance | 7 PFLOPS | 9 PFLOPS | 20 PFLOPS |
| TDP | 700W | 1000W | N/A |
Generative AI model training capabilities
Both architectures show exceptional capabilities in training large AI models, with Blackwell demonstrating up to 3x faster training speeds compared to Hopper. Key improvements include enhanced transformer processing, optimized memory bandwidth, and more efficient parallel processing capabilities. The architectures enable training of increasingly large language models while reducing power consumption and training time.
Blackwell Ultra: The Next Evolution in AI Computing
Announced on March 18, 2025, at GTC 2025, Blackwell Ultra represents the latest evolution of NVIDIA’s AI computing platform.
Technical Specifications and Improvements
- Product line includes GB300 NVL72 and HGX B300 NVL16
- GB300 NVL72 delivers 1.5x more AI performance than GB200 NVL72
- HGX B300 NVL16 compared to Hopper architecture achieves:
- 11x faster inference
- 7x more compute
- 4x larger memory
- Integrates NVIDIA Spectrum-X Ethernet and Quantum-X800 InfiniBand, providing 800Gb/s data throughput per GPU
- Features BlueField-3 DPUs for multi-tenant networking, GPU compute elasticity, and real-time security detection
Advanced Memory and Cooling Solutions
- Utilizes ConnectX-8 SuperNIC for high-performance RDMA capabilities
- Optimized for AI factories and cloud data centers to eliminate performance bottlenecks
- Supports various configurations:
- 72 Blackwell Ultra GPUs
- 36 Arm Neoverse-based Grace CPUs
- Rack-scale design functioning as a single massive GPU
LLM Optimization Features
- Optimized for AI reasoning and agentic AI:
- Supports reasoning and iterative planning for complex multi-step problems
- Capable of real-time synthetic video generation for training
- Software support:
- New open-source NVIDIA Dynamo inference framework
- Support for NVIDIA Llama Nemotron Reason models
- Integration with NVIDIA AI Enterprise software platform
- Expected availability through major server manufacturers and cloud service providers in second half of 2025
Choose Novita AI for your Trusted GPU Partner
As AI computing continues to evolve with NVIDIA’s groundbreaking architectures, choosing the right GPU cloud partner becomes crucial. Novita AI offers a comprehensive platform that provides access to high-performance GPUs with significant cost advantages
If you’re interested in Novita AI, follow these steps to get started:
Step1:Create an account
Visit Novita AI’s website to sign up for an account. After completing registration, head over to the “GPUs” section to explore available resources and start your AI journey.

[Try using Novita AI now](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell)
Step2:Select Your GPU
Our platform offers a variety of pre-configured templates tailored to your specific requirements, along with the flexibility to create custom templates as needed.
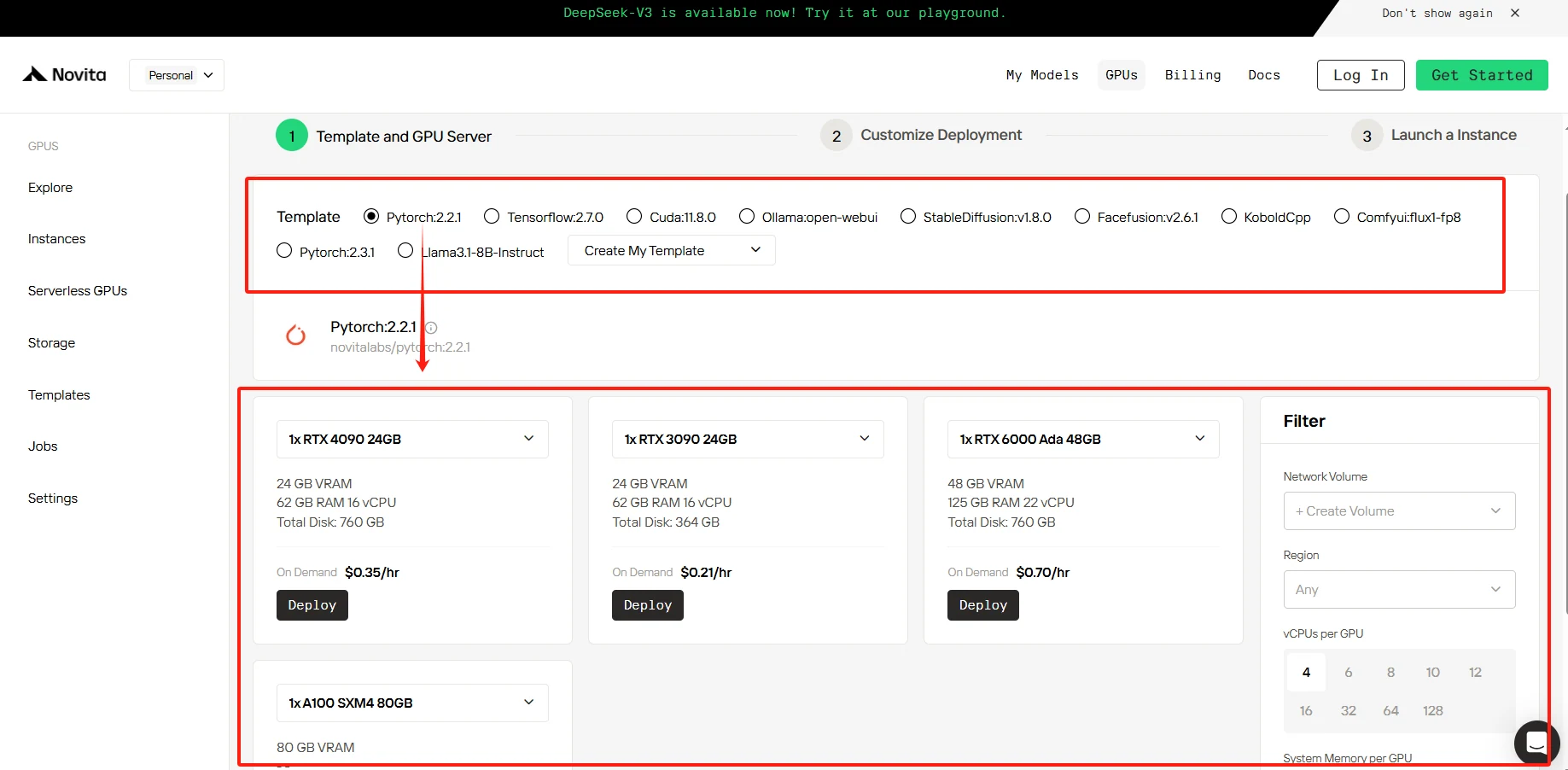
[Try Novita AI’s High-Performance GPUs](https://novita.ai/gpus-console/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell)
Step3:Customize Your Setup
Launch your project today with 60GB free container storage - no upfront costs. Scale storage on demand as your AI workloads grow, paying only for the extra space you need.
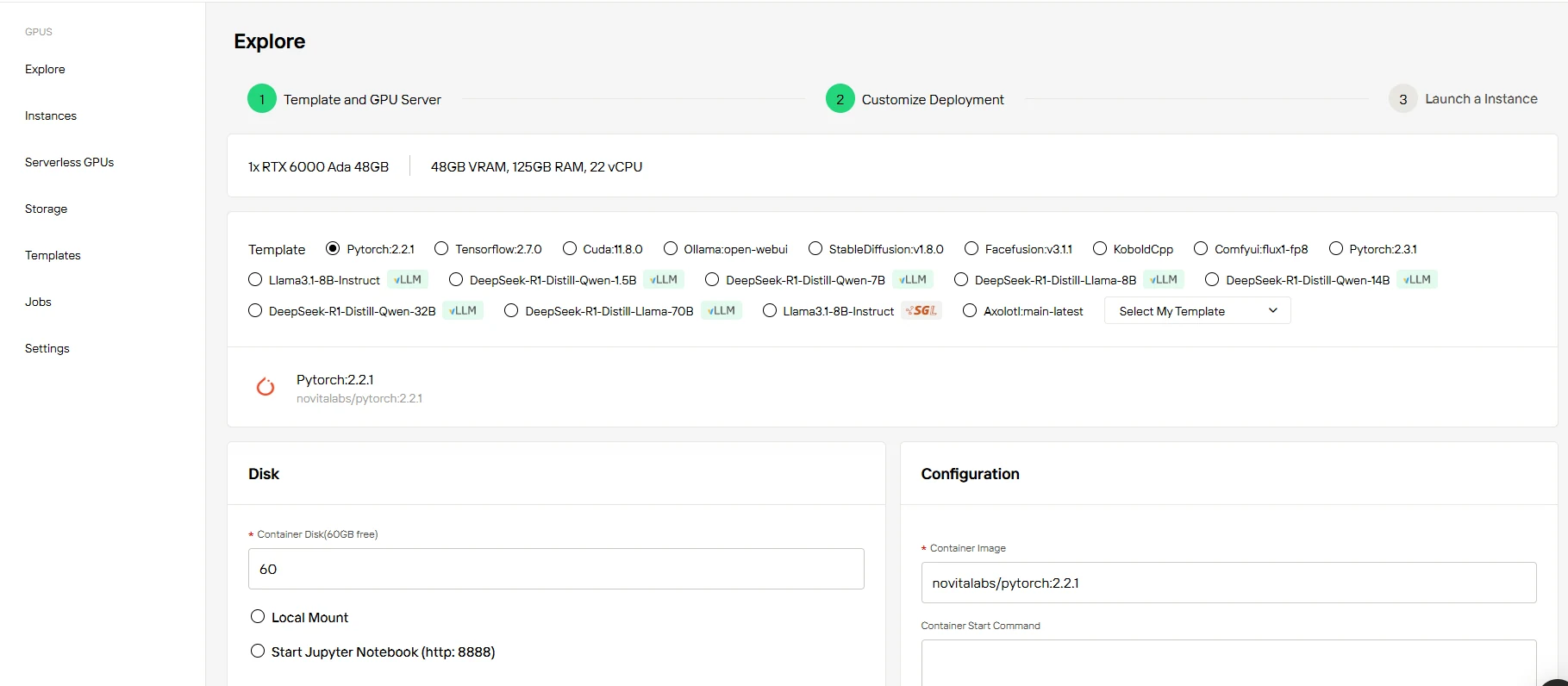
Step4:Launch Your Instance
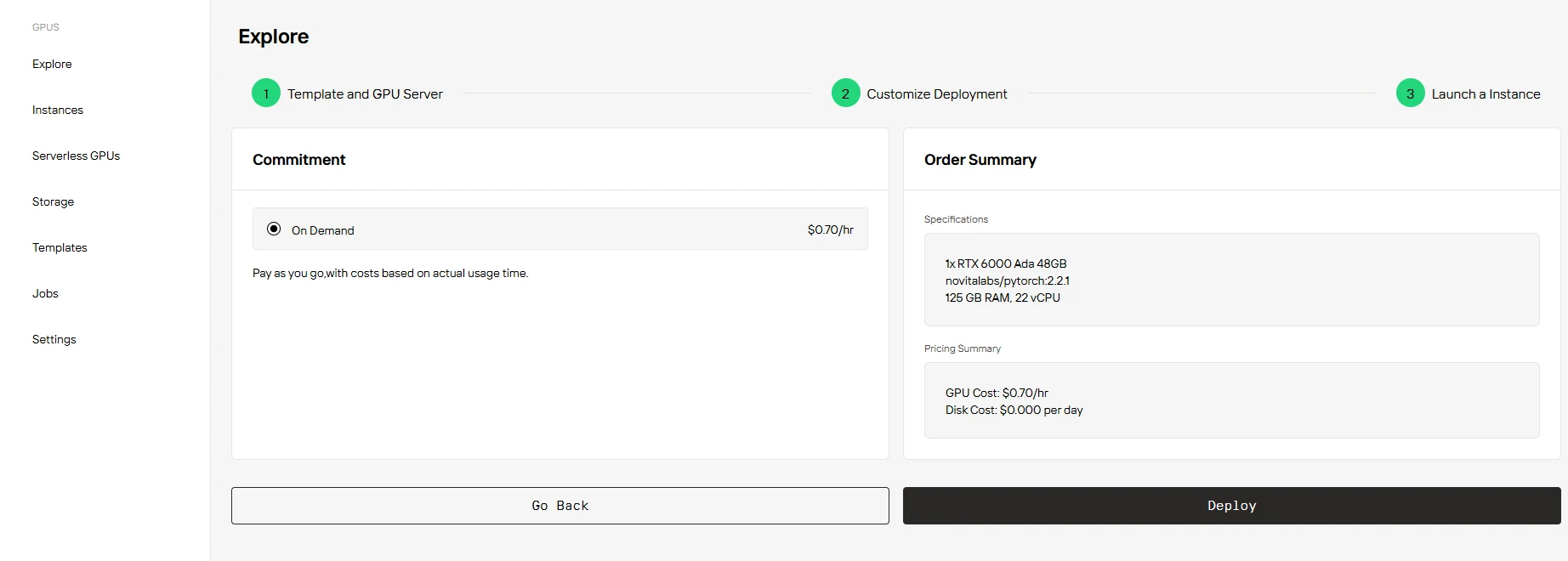
Simply select “On Demand”, confirm your settings and pricing, then hit “Deploy” to get started.
Conclusion
The journey from Hopper to Blackwell represents a significant leap in AI computing capabilities. While Hopper set new standards for AI training and scientific computing, Blackwell pushes these boundaries further with dramatic improvements in performance, efficiency, and versatility. This evolution not only advances NVIDIA’s technical leadership but also accelerates the broader adoption of AI across industries. As we look to the future, these architectural advancements will continue to enable new possibilities in artificial intelligence and scientific computing.
Frequently Asked Questions
What makes Blackwell Ultra different from standard Blackwell GPUs?
Blackwell Ultra represents the pinnacle of the architecture with additional performance enhancements, advanced cooling solutions, and specialized features optimized specifically for large language model training and inference.
Which GPU architecture should I choose for my AI project?
The optimal choice depends on your specific requirements. Hopper is ideal for established AI workflows, while Blackwell offers superior performance for cutting-edge applications. Novita AI can provide personalized recommendations based on your needs.
How difficult is it to migrate workloads from Hopper to Blackwell?
NVIDIA has maintained software compatibility between generations, making migration relatively straightforward. Most code optimized for Hopper will run on Blackwell without modifications, though recompiling with the latest CUDA toolkit is recommended to take advantage of Blackwell-specific optimizations.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Next Generation of AI Computing: NVIDIA’s Journey from Hopper to Blackwell) is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Recommended Reading
GPU Comparison for AI Modeling: A Comprehensive Guide
How Much RAM is Needed for Machine Learning?
Choosing the Best GPU for Machine Learning in 2025: A Complete Guide



