

Wichtige Highlights
Llama 4 Scout: Ein hochmodernes multimodales Modell mit Unterstützung für Text- und Bildeingaben bei einer Kontextlänge von 10 Mio. Token, ideal für fortgeschrittenes Reasoning, Aufgaben mit erweitertem Gedächtnis und kosteneffiziente skalengroße Ausgaben.
Llama 3.3 70B: Auf reine Texteingaben mit einer Kontextlänge von 131 K Token beschränkt, glänzt jedoch bei Code-Aufgaben mit präzisen Implementierungen und geringeren Hardware-Anforderungen.
Leistung: Llama 4 Scout führt bei Reasoning, Wissen und Kosteneffizienz, während Llama 3.3 70B bei Code-Aufgaben leicht besser abschneidet.
Hardware-Anforderungen: Llama 4 Scout erfordert deutlich höhere Rechenressourcen, während Llama 3.3 70B für allgemeine Anwendungen zugänglicher ist.
Llama 4 Scout und Llama 3.3 70B repräsentieren zwei leistungsstarke große Sprachmodelle, die für unterschiedliche Anwendungsfälle konzipiert sind. Die multimodalen Fähigkeiten von Llama 4 Scout und die 10 Mio. Token Kontextlänge machen es geeignet für fortgeschrittenes Reasoning und Aufgaben mit erweitertem Gedächtnis. Llama 3.3 70B hingegen glänzt mit Effizienz, Code-Leistung und geringeren Hardware-Anforderungen, ideal für allgemeine Zwecke. Dieser Leitfaden beleuchtet ihre Unterschiede und hilft Ihnen, je nach Bedarf das richtige Modell auszuwählen.
Einführung
Llama 4 Scout unterstützt multimodale Verarbeitung und kann dadurch verschiedene Datentypen wie Text und Bilder für komplexe Aufgaben wie visuelles Reasoning und Datensynthese verarbeiten. Seine 10 Mio. Token Kontextlänge ermöglicht die Verarbeitung massiver sequenzieller Daten und eignet sich daher ideal für Anwendungen, die erweitertes Gedächtnis und Kontextbewusstsein erfordern.
Llama 4 Scout
| Kategorie | Punkt | Details |
|---|---|---|
| Basisinfo | Modellgröße | 109B Parameter (17B aktiv/Token) |
| Open Source | Offen | |
| Architektur | 16 Mixture-of-Experts (MoE) | |
| Kontext | Unterstützt bis zu 10 Mio. Token | |
| Sprachunterstützung | Unterstützte Sprachen | Vorab trainiert auf 200 Sprachen. Unterstützt Arabisch, Englisch, Französisch, Deutsch, Hindi, Indonesisch, Italienisch, Portugiesisch, Spanisch, Tagalog, Thai und Vietnamesisch. |
| Multimodal | Fähigkeit | Eingabe: Mehrsprachiger Text und Bilder; Ausgabe: Mehrsprachiger Text und Code |
| Training | Trainingsdaten | ~40 Billionen Token |
| Vorab-Training | MetaP: Adaptive Expertenkonfiguration + Mid-Training | |
| Nachbereitung | SFT (Einfache Daten) → RL (Schwierige Daten) → DPO | |
| Modellgröße nach Präzision | Tensor-Typ | BF16 |
Llama 3.3 70B
| Kategorie | Punkt | Details |
|---|---|---|
| Basisinfo | Modellgröße | 70B Parameter |
| Open Source | Offen | |
| Architektur | Optimierte Transformer Architektur, GQA | |
| Kontext | 131K | |
| Sprachunterstützung | Unterstützte Sprachen | Unterstützt acht Sprachen |
| Multimodal | Fähigkeit | Text zu Text |
| Training | Trainingsdaten | 15 Billionen Token |
| Trainingsmethode | Supervised Fine-Tuning (SFT) und Reinforcement Learning with Human Feedback (RLHF) | |
| Modellgröße nach Präzision | Tensor-Typ | BF16 |
Benchmark-Vergleich
Nachdem wir die grundlegenden Eigenschaften jedes Modells dargelegt haben, betrachten wir nun ihre Leistung in verschiedenen Benchmarks. Dieser Vergleich hilft, ihre Stärken in verschiedenen Bereichen zu veranschaulichen.
| Kategorie | Benchmark | Llama 4 Scout | Llama 3.3 70B |
|---|---|---|---|
| Code | LiveCodeBench | 32.8 | 33.3 |
| Reasoning | MMLU Pro | 74.3 | 68.9 |
| Wissen | GPQA Diamond | 57.2 | 50.5 |
| Preise (Novita AI) | 1 Mio. Eingabe-Token | $0.10 | $0.10 |
| 1 Mio. Ausgabe-Token | $0.13 | $0.39 |
Wählen Sie Llama 4 Scout für vielfältige Aufgaben, die Reasoning, Wissen und Kosteneffizienz priorisieren. Entscheiden Sie sich für Llama 3.3 70B, wenn die Code-Leistung die primäre Anforderung ist.
Weitere Vergleiche finden Sie in diesen Artikeln:
- Can a Single H100’s VRAM Handle Running Llama 4 Scout?
- DeepSeek R1 vs OpenAI o1: Distinct Architectures of GRPO and PPO
- Guide: Accessing Llama 4 Scout Locally, Through API, or on Cloud GPUs
Geschwindigkeitsvergleich
Wenn Sie selbst testen möchten, können Sie auf der Novita AI Website eine kostenlose Testversion starten.

Geschwindigkeitsvergleich
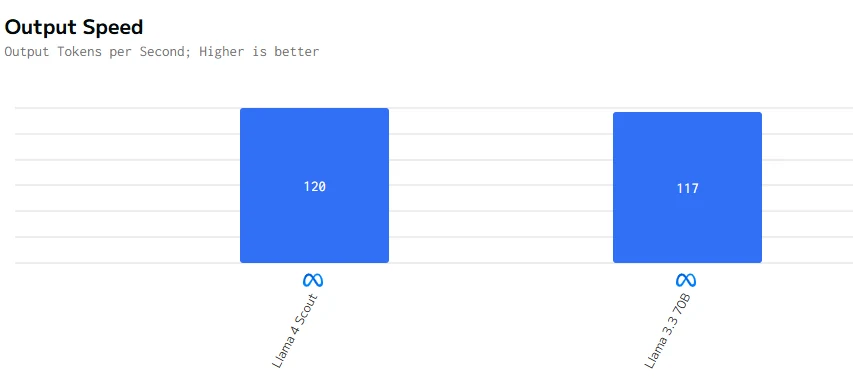
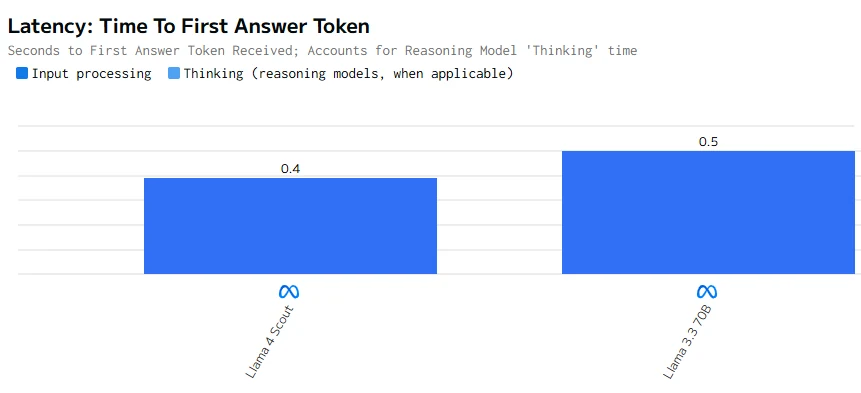
Llama 4 Scout ist sowohl bei der Token-Generierung schneller als auch beim ersten Token. Diese Eigenschaften machen es besser geeignet für Anwendungen, die niedrige Latenz und hohe Reaktionsfähigkeit erfordern.
Hardware-Anforderungen
| Modell | Kontextlänge | Int4 VRAM | GPU-Bedarf (Int4) | FP16 VRAM | GPU-Bedarf (FP16) |
|---|---|---|---|---|---|
| Llama 3.3 70B | 131K Token | 194,14 GB | 4× H100 | ||
| Llama 4 Scout | 4K Token | ~99,5 GB | 1× H100 | ~345 GB | 8× H100 |
| 128K Token | ~334 GB | 8× H100 | ~579 GB | 8× H100 | |
| 10 Mio. Token | ~18,8 TB | 240× H100 | Gleich wie INT4 (KV-Cache-Dominanz) | 240× H100 |
Hardware-Anforderungen: Llama 3.3 70B benötigt selbst bei erweiterten Kontextlängen (131K Token mit 4× H100) geringere Hardware-Ressourcen. Im Gegensatz dazu ist Llama 4 Scout hardwareintensiv, insbesondere bei Aufgaben mit 128K oder 10 Mio. Token.
Skalierbarkeit: Llama 4 Scout unterstützt ultra-lange Kontextlängen (bis zu 10 Mio. Token), jedoch zu Lasten enormer Rechenressourcen – geeignet für Nischenanwendungen mit hohem Budget.
Praktikabilität: Llama 3.3 70B ist besser für allgemeine Anwendungsfälle mit hoher Effizienz und Ressourcenzugänglichkeit geeignet. Llama 4 Scout ist ideal für spezialisierte Szenarien, die massive Token-Kontexte erfordern, aber seine Anforderungen machen es für typische Umgebungen weniger praktisch.
Anwendungen und Anwendungsfälle
Llama 4 Scout Anwendungen:
- Multimodale Aufgaben: Ideal für Aufgaben mit Text und Bildern, wie visuelle Fragebeantwortung, Bildbeschriftung oder multimodales Reasoning.
- Erweiterte Kontextverarbeitung: Mit 10 Mio. Token Kontextlänge hervorragend geeignet für die Analyse langer Dokumente, historischer Daten oder großangelegter Konversationen.
- Hochleistungs-Reasoning: Geeignet für fortgeschrittene Reasoning-Aufgaben wie wissenschaftliche Analysen, komplexe Problemlösungen und Entscheidungsfindung.
- Kosteneffiziente Ausgaben: Optimiert für Aufgaben, die großvolumige Textgenerierung mit minimalen Kosten für Ausgabe-Token erfordern.
Llama 3.3 70B Anwendungen:
- Coding und Programmierung: Etwas besser bei Code-Aufgaben, daher eine gute Wahl für Softwareentwicklung, Debugging und Code-Generierung.
- Moderate Kontextanforderungen: Unterstützt bis zu 131K Token, geeignet für Anwendungen wie Dokumentenanalyse, Zusammenfassungen oder mittellange Konversationen.
- Allzwecknutzung: Funktioniert gut für eine breite Palette von Aufgaben, einschließlich Content-Erstellung, Fragebeantwortung und gelegentlichem Reasoning, wenn extreme Kontextlängen oder multimodale Fähigkeiten nicht erforderlich sind.
- Budgetfreundlich für Eingaben: Eine praktische Wahl für Aufgaben mit hohem Eingabeverarbeitungsbedarf, dank ausgewogener Kostenstruktur.
Llama 4 Scout vs. Llama 3.3 70B: Aufgaben
Aufgabe 1: Logisches Denken
Prompt: “Sie betreten einen Raum und sehen ein Bett. Auf dem Bett liegen zwei Hunde, vier Katzen, eine Giraffe, fünf Kühe und eine Ente. Außerdem gibt es drei Stühle und einen Tisch. Wie viele Beine befinden sich auf dem Boden?”
Llama 4 Scout

Llama 3.3 70B

Bewertung:
- Genauigkeit: Llama 3.3 70B liefert die vollständigere Antwort (
22 Beine), da es sowohl die Bettbeine als auch die Beine der Person einbezieht, was Llama 4 Scout übersehen hat. - Klarheit: Llama 4 Scout bietet eine strukturiertere und detailliertere Erklärung, wodurch der Reasoning-Prozess leichter nachvollziehbar ist.
- Interpretation: Die Einbeziehung der Beine der Person durch Llama 3.3 70B ist je nach Absicht der Frage diskutabel. Wenn die Frage die Person explizit ausschließt, lautet die Antwort
$20$Beine.
Aufgabe 2: Problemlösungsfähigkeiten
Prompt: “Schreiben Sie ein Programm, das ein Sudoku-Rätsel lösen kann”
Llama 4 Scout
Llama 3.3 70B
Bewertung:
- Llama 4 Scouts Implementierung ist besser für Anfänger oder diejenigen, die Klarheit und detaillierte Erklärungen priorisieren. Sie ist leichter nachvollziehbar und enthält ansprechende Ausgabeformatierung. Llama 3.3 70Bs Implementierung ist prägnanter und effizienter – eine gute Wahl für Benutzer, die mit Sudoku-Lösungsalgorithmen vertraut sind und kompakten Code bevorzugen.
Wie greife ich über die Novita API auf Llama 4 Scout und Llama 3.3 70B zu?
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Model Library.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite “Settings” auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Die Wahl zwischen Llama 4 Scout und Llama 3.3 70B hängt von Ihren Anforderungen ab. Für Aufgaben, die multimodale Eingaben, umfangreichen Speicher und fortgeschrittenes Reasoning erfordern, ist Llama 4 Scout die überlegene Wahl. Wenn Ihr Fokus auf Code, moderaten Kontextlängen und Hardware-Effizienz liegt, bietet Llama 3.3 70B eine praktischere Lösung. Erkunden Sie diese Modelle über Novita AI, um die perfekte Lösung für Ihre Anwendungen zu finden.
Häufig gestellte Fragen
Was macht Llama 4 Scout einzigartig?
Die Modelle 4B, 12B und 27B haben ein 128K-Kontextfenster, während das 1B-Modell ein 32K-Kontextfenster hat. Llama 4 Scout unterstützt multimodale Eingaben (Text und Bilder) und bietet eine beispiellose Kontextlänge von 10 Mio. Token – ideal für große Reasoning-Aufgaben, die Verarbeitung langer Dokumente und fortgeschrittene Entscheidungsaufgaben.
Wer sollte Llama 3.3 70B gegenüber Llama 4 Scout verwenden?
Llama 3.3 70B ist ideal für Benutzer, die sich auf Code, moderate Speicheranforderungen (131 K Token) und begrenzte Hardware-Ressourcen konzentrieren.
Wie greife ich auf Llama 4 Scout und Llama 3.3 70B zu?
Novita AI bietet eine erschwingliche und zuverlässige API für Sie.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API zu deployen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.



