

Aspectos destacados
Llama 4 Scout: Un modelo multimodal de vanguardia que admite entradas de texto e imagen con una longitud de contexto de 10M, ideal para razonamiento avanzado, tareas de memoria extendida y salidas a gran escala con bajo costo.
Llama 3.3 70B: Limitado a entradas de solo texto con una longitud de contexto de 131K, pero destaca en tareas de codificación con implementaciones concisas y requisitos de hardware más bajos.
Rendimiento: Llama 4 Scout lidera en razonamiento, conocimiento y eficiencia de costos, mientras que Llama 3.3 70B se desempeña ligeramente mejor en tareas de codificación.
Requisitos de hardware: Llama 4 Scout exige recursos computacionales significativamente mayores, mientras que Llama 3.3 70B es más accesible para aplicaciones de propósito general.
Llama 4 Scout y Llama 3.3 70B representan dos potentes modelos de lenguaje diseñados para casos de uso distintos. Las capacidades multimodales de Llama 4 Scout y su longitud de contexto de 10M lo hacen adecuado para razonamiento avanzado y tareas de memoria extendida. En contraste, Llama 3.3 70B brilla por su eficiencia, rendimiento en codificación y menores requisitos de hardware, lo que lo hace ideal para aplicaciones de propósito general. Esta guía explora sus diferencias y te ayuda a elegir el modelo adecuado según tus necesidades.
Introducción básica
Llama 4 Scout admite procesamiento multimodal, lo que le permite manejar diversos tipos de datos como texto e imágenes para tareas complejas como razonamiento visual y síntesis de datos. Su longitud de contexto de 10M le permite procesar datos secuenciales masivos, lo que lo hace ideal para aplicaciones que requieren memoria extendida y conciencia del contexto.
Llama 4 Scout
| Categoría | Elemento | Detalles |
|---|---|---|
| Información básica | Tamaño del modelo | 109B parámetros (17B activos/token) |
| Código abierto | Sí | |
| Arquitectura | 16 Mixture-of-Experts (MoE) | |
| Contexto | Soporta hasta 10M tokens | |
| Soporte de idiomas | Idiomas compatibles | Preentrenado en 200 idiomas. Soporta árabe, alemán, español, francés, hindi, indonesio, inglés, italiano, portugués, tagalo, tailandés y vietnamita. |
| Multimodal | Capacidad | Entrada: texto e imágenes multilingües; Salida: texto y código multilingües |
| Entrenamiento | Datos de entrenamiento | ~40 billones de tokens |
| Pre-entrenamiento | MetaP: Configuración adaptativa de expertos + entrenamiento intermedio | |
| Post-entrenamiento | SFT (datos fáciles) → RL (datos difíciles) → DPO | |
| Tamaño del modelo por precisión | Tipo de tensor | BF16 |
Llama 3.3 70B
| Categoría | Elemento | Detalles |
|---|---|---|
| Información básica | Tamaño del modelo | 70B parámetros |
| Código abierto | Sí | |
| Arquitectura | Arquitectura Transformer optimizada, GQA | |
| Contexto | 131K | |
| Soporte de idiomas | Idiomas compatibles | Soporta ocho idiomas |
| Multimodal | Capacidad | Texto a texto |
| Entrenamiento | Datos de entrenamiento | 15 billones de tokens |
| Método de entrenamiento | Ajuste fino supervisado (SFT) y aprendizaje por refuerzo con retroalimentación humana (RLHF) | |
| Tamaño del modelo por precisión | Tipo de tensor | BF16 |
Comparación de benchmarks
Ahora que hemos establecido las características básicas de cada modelo, profundicemos en su rendimiento en varios benchmarks. Esta comparación ayudará a ilustrar sus fortalezas en diferentes áreas.
| Categoría | Benchmark | Llama 4 Scout | Llama 3.3 70B |
|---|---|---|---|
| Codificación | LiveCodeBench | 32.8 | 33.3 |
| Razonamiento | MMLU Pro | 74.3 | 68.9 |
| Conocimiento | GPQA Diamond | 57.2 | 50.5 |
| Precio (Novita AI) | 1M tokens de entrada | $0.10 | $0.10 |
| 1M tokens de salida | $0.13 | $0.39 |
Elige Llama 4 Scout para tareas diversas que prioricen razonamiento, conocimiento y eficiencia de costos. Opta por Llama 3.3 70B si el rendimiento en codificación es el requisito principal.
Si deseas ver más comparaciones, puedes consultar estos artículos:
- ¿La VRAM de una sola H100 puede ejecutar Llama 4 Scout?
- DeepSeek R1 vs OpenAI o1: Arquitecturas distintas de GRPO y PPO
- Guía: Acceder a Llama 4 Scout localmente, a través de API o en GPU en la nube
Comparación de velocidad
Si deseas probarlo tú mismo, puedes iniciar una prueba gratuita en el sitio web de Novita AI.

¡Prueba la demo de Llama 4 Scout ahora!
Comparación de velocidad
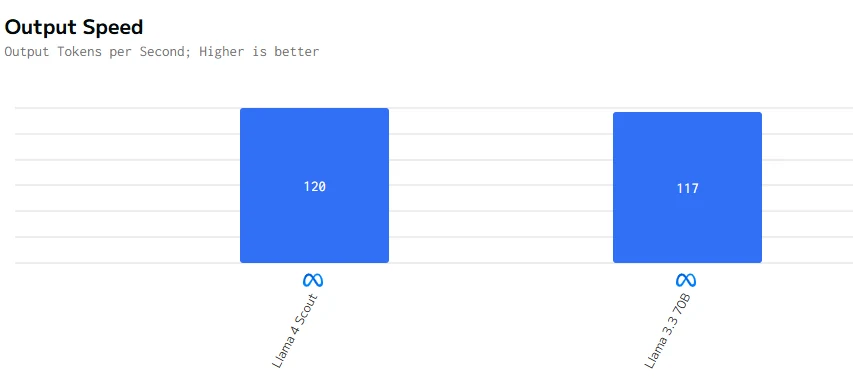
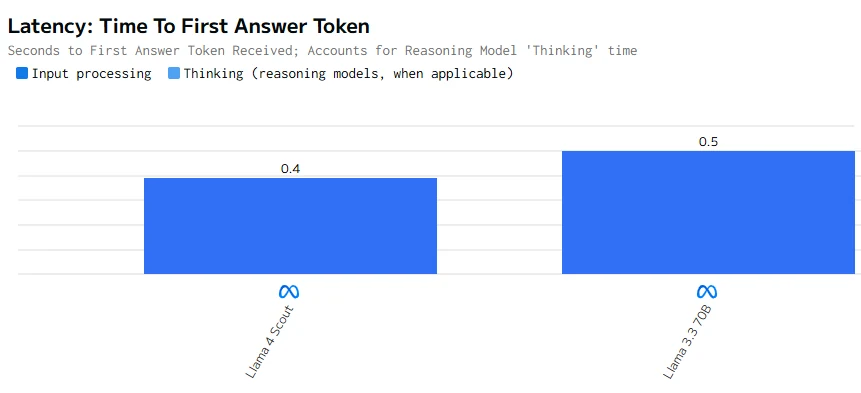
Llama 4 Scout es más rápido tanto en la generación de tokens como en la producción del primer token. Estas cualidades lo hacen más adecuado para aplicaciones que requieren baja latencia y alta capacidad de respuesta.
Requisitos de hardware
| Modelo | Longitud de contexto | VRAM Int4 | GPU necesarias (Int4) | VRAM FP16 | GPU necesarias (FP16) |
|---|---|---|---|---|---|
| Llama 3.3 70B | 131K tokens | 194.14 GB | 4xH100 | ||
| Llama 4 Scout | 4K tokens | ~99.5 GB | 1× H100 | ~345 GB | 8× H100 |
| 128K tokens | ~334 GB | 8× H100 | ~579 GB | 8× H100 | |
| 10M tokens | ~18.8 TB | 240× H100 | Igual que INT4 (predominio de KV Cache) | 240× H100 |
Requisitos de hardware: Llama 3.3 70B mantiene requisitos de hardware más bajos, incluso para longitudes de contexto extendidas (131K tokens con 4× H100). En contraste, Llama 4 Scout requiere mucho hardware, especialmente para tareas que involucran 128K o 10M tokens.
Escalabilidad: Llama 4 Scout admite longitudes de contexto ultra largas (hasta 10M tokens), pero a costa de recursos computacionales extremos, lo que lo hace adecuado para aplicaciones especializadas de alto presupuesto.
Practicidad: Llama 3.3 70B es más adecuado para casos de uso de propósito general con alta eficiencia y accesibilidad de recursos. Llama 4 Scout es ideal para escenarios especializados que requieren contextos de tokens masivos, pero sus demandas lo hacen menos práctico para entornos típicos.
Aplicaciones y casos de uso
Aplicaciones de Llama 4 Scout:
- Tareas multimodales: Ideal para tareas que involucran texto e imágenes, como respuesta a preguntas visuales, descripción de imágenes o razonamiento multimodal.
- Procesamiento de contexto extendido: Con su longitud de contexto de 10M, destaca en el análisis de documentos largos, datos históricos o conversaciones a gran escala.
- Razonamiento de alto rendimiento: Adecuado para tareas de razonamiento avanzado como análisis científico, resolución de problemas complejos y toma de decisiones.
- Salidas rentables: Optimizado para tareas que requieren generación de texto a gran escala con un costo mínimo por token de salida.
Aplicaciones de Llama 3.3 70B:
- Codificación y programación: Se desempeña ligeramente mejor en tareas de codificación, lo que lo convierte en una opción sólida para desarrollo de software, depuración y generación de código.
- Requisitos de contexto moderados: Admite hasta 131K tokens, adecuado para aplicaciones como análisis de documentos, resúmenes o conversaciones de mediana duración.
- Uso de propósito general: Funciona bien para una amplia variedad de tareas, incluyendo creación de contenido, respuesta a preguntas y razonamiento casual, donde no se requiere contexto extremo o capacidad multimodal.
- Rentable para entradas: Una opción práctica para tareas con necesidades intensivas de procesamiento de entrada, dada su estructura de costos equilibrada.
Llama 4 Scout vs Llama 3.3 70B: Tareas
Tarea 1: Razonamiento lógico
Prompt: “Entras en una habitación y ves una cama. En la cama hay dos perros, cuatro gatos, una jirafa, cinco vacas y un pato. También hay tres sillas y una mesa. ¿Cuántas patas hay en el suelo?”
Llama 4 Scout

Llama 3.3 70B

Revisión:
- Precisión: Llama 3.3 70B da la respuesta más completa (
22 patas), ya que incluye tanto las patas de la cama como las patas de la persona, que Llama 4 Scout omitió. - Claridad: Llama 4 Scout proporciona una explicación más estructurada y detallada, lo que facilita seguir el proceso de razonamiento.
- Interpretación: La inclusión de las patas de la persona por parte de Llama 3.3 70B es discutible según la intención de la pregunta. Si la pregunta excluye explícitamente a la persona, la respuesta sería
20patas.
Tarea 2: Habilidades de resolución de problemas
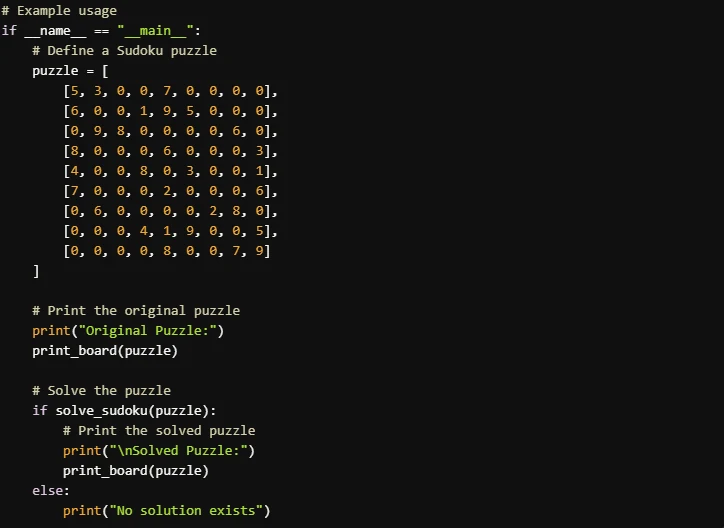
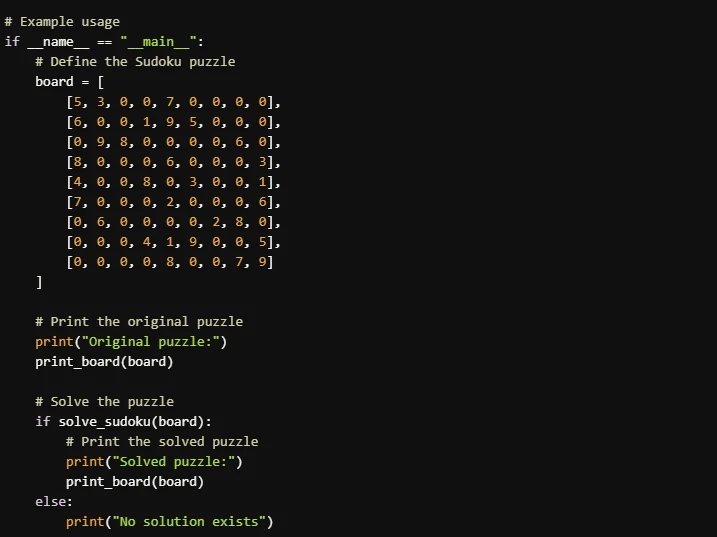
Prompt: “Escribe un programa que pueda resolver un rompecabezas de Sudoku”
Llama 4 Scout
Llama 3.3 70B
Revisión:
- La implementación de Llama 4 Scout es mejor para principiantes o quienes priorizan la claridad y las explicaciones detalladas. Es más fácil de seguir e incluye formato de salida pulido. La implementación de Llama 3.3 70B es más concisa y eficiente, lo que la convierte en una buena opción para usuarios familiarizados con algoritmos de resolución de Sudoku que prefieren código compacto.
Cómo acceder a Llama 4 Scout y Llama 3.3 70B a través de Novita API?
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega entre las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página de Settings y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el administrador de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<TU Clave API de Novita AI>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # o False
max_tokens = 2048
system_content = """Sé un asistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Elegir entre Llama 4 Scout y Llama 3.3 70B depende de tus requisitos. Para tareas que requieren entradas multimodales, memoria extensa y razonamiento avanzado, Llama 4 Scout es la opción superior. Si tu enfoque es la codificación, longitudes de contexto moderadas y eficiencia de hardware, Llama 3.3 70B ofrece una solución más práctica. Explora estos modelos a través de Novita AI para encontrar la opción perfecta para tus aplicaciones.
Preguntas frecuentes
¿Qué hace único a Llama 4 Scout?
Los modelos de 4B, 12B y 27B tienen una ventana de contexto de 128K, mientras que el modelo de 1B tiene una ventana de contexto de 32K. Llama 4 Scout admite entradas multimodales (texto e imágenes) y ofrece una longitud de contexto sin precedentes de 10M, lo que lo hace perfecto para razonamiento a gran escala, procesamiento de documentos largos y tareas avanzadas de toma de decisiones.
¿Quién debería usar Llama 3.3 70B en lugar de Llama 4 Scout?
Llama 3.3 70B es ideal para usuarios centrados en codificación, requisitos de memoria moderados (131K tokens) y aquellos con recursos de hardware limitados.
¿Cómo acceder a Llama 4 Scout y Llama 3.3 70B?
Novita AI ofrece una API confiable y asequible para ti.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una manera sencilla de implementar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona una nube GPU asequible y confiable para construir y escalar.



