

Key Highlights
Llama 4 Scout: A cutting-edge multimodal model supporting text and image inputs with a 10M context length, ideal for advanced reasoning, extended memory tasks, and cost-efficient large-scale outputs.
Llama 3.3 70B: Limited to text-only inputs with a 131K context length but excels in coding tasks with concise implementations and lower hardware requirements.
Performance: Llama 4 Scout leads in reasoning, knowledge, and cost efficiency, while Llama 3.3 70B performs slightly better in coding tasks.
Hardware Requirements: Llama 4 Scout demands significantly higher computational resources, whereas Llama 3.3 70B is more accessible for general-purpose applications.
Llama 4 Scout and Llama 3.3 70B represent two powerful large language models designed for distinct use cases. Llama 4 Scout’s multimodal capabilities and 10M context length make it suitable for advanced reasoning and extended memory tasks. In contrast, Llama 3.3 70B shines in efficiency, coding performance, and lower hardware requirements, making it ideal for general-purpose applications. This guide explores their differences and helps you choose the right model based on your needs.
Basic Introduction
Llama 4 Scout supports multimodal processing, enabling it to handle diverse data types like text and images for complex tasks such as visual reasoning and data synthesis. Its 10M context length allows it to process massive sequential data, making it ideal for applications requiring extended memory and context awareness.
Llama 4 Scout
| Category | Item | Details |
|---|---|---|
| Basic Info | Model Size | 109B parameters (17B active/token) |
| Open Source | Open | |
| Architecture | 16 Mixture-of-Experts (MoE) | |
| Context | Supports up to 10M tokens | |
| Language Support | Supported Languages | Pre-trained on 200 languages. Supports Arabic, English, French, German, Hindi, Indonesian, Italian, Portuguese, Spanish, Tagalog, Thai, and Vietnamese. |
| Multimodal | Capability | Input: Multilingual text and image; Output: Multilingual text and code |
| Training | Training Data | ~40 trillion tokens |
| Pre-Training | MetaP: Adaptive Expert Configuration + Mid-training | |
| Post-Training | SFT (Easy Data) → RL (Hard Data) → DPO | |
| Model Size by Precision | Tensor Type | BF16 |
Llama 3.3 70B
| Category | Item | Details |
|---|---|---|
| Basic Info | Model Size | 70B parameters |
| Open Source | Open | |
| Architecture | Optimized Transformer Architecture, GQA | |
| Context | 131K | |
| Language Support | Supported Languages | Supports eight languages |
| Multimodal | Capability | Text to text |
| Training | Training Data | 15 trillion tokens |
| Training Method | Supervised Fine-Tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF) | |
| Model Size by Precision | Tensor Type | BF16 |
Benchmark Comparison
Now that we’ve established the basic characteristics of each model, let’s delve into their performance across various benchmarks. This comparison will help illustrate their strengths in different areas.
| Category | Benchmark | Llama 4 Scout | Llama 3.3 70B |
|---|---|---|---|
| Coding | LiveCodeBench | 32.8 | 33.3 |
| Reasoning | MMLU Pro | 74.3 | 68.9 |
| Knowledge | GPQA Diamond | 57.2 | 50.5 |
| Pricing (Novita AI) | 1M Input Tokens | $0.10 | $0.10 |
| 1M Output Tokens | $0.13 | $0.39 |
Choose Llama 4 Scout for diverse tasks that prioritize reasoning, knowledge, and cost efficiency. Opt for Llama 3.3 70B if coding performance is the primary requirement.
If you want to see more comparisons, you can check out these articles:
- Can a Single H100’s VRAM Handle Running Llama 4 Scout?
- DeepSeek R1 vs OpenAI o1: Distinct Architectures of GRPO and PPO
- Guide: Accessing Llama 4 Scout Locally, Through API, or on Cloud GPUs
Speed Comparison
If you want to test it yourself, you can start a free trial on the Novita AI website.

Speed Comparison
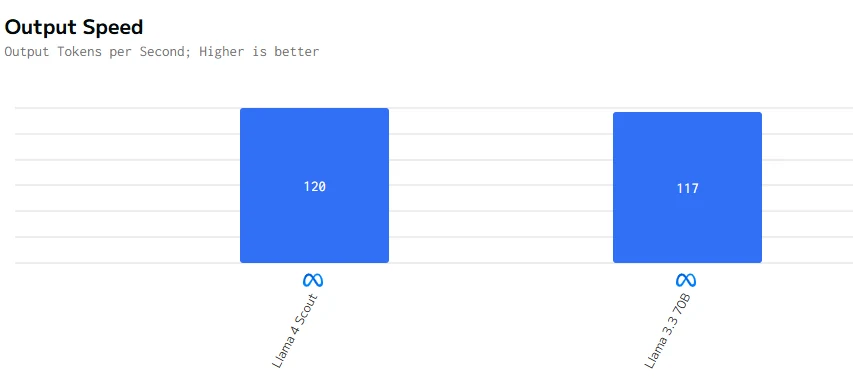
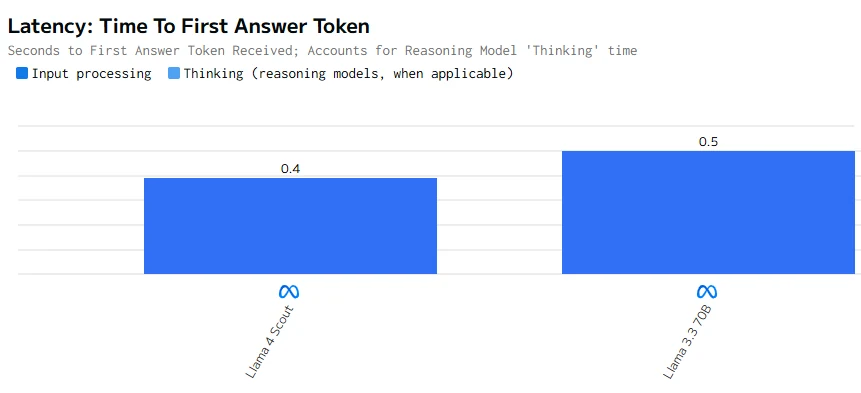
Llama 4 Scout is both faster in token generation and quicker in producing the first token. These qualities make it better suited for applications requiring low latency and high responsiveness.
Hardware Requiremments
| Model | Context Length | Int4 VRAM | GPU Needs (Int4) | FP16 VRAM | GPU Needs (FP16) |
|---|---|---|---|---|---|
| Llama 3.3 70B | 131K Tokens | 194.14GB | 4xH100 | ||
| Llama 4 Scout | 4K Tokens | ~99.5 GB | 1× H100 | ~345 GB | 8× H100 |
| 128K Tokens | ~334 GB | 8× H100 | ~579 GB | 8× H100 | |
| 10M Tokens | ~18.8 TB | 240× H100 | Same as INT4 (KV Cache dominance) | 240× H100 |
Hardware Requirements: Llama 3.3 70B maintains lower hardware requirements, even for extended context lengths (131K tokens with 4× H100). In contrast, Llama 4 Scout is hardware-intensive, especially for tasks involving 128K or 10M tokens.
Scalability: Llama 4 Scout supports ultra-long context lengths (up to 10M tokens), but at the cost of extreme computational resources, making it suitable for niche, high-budget applications.
Practicality: Llama 3.3 70B is better suited for general-purpose use cases with high efficiency and resource accessibility. Llama 4 Scout is ideal for specialized scenarios requiring massive token contexts, but its demands make it less practical for typical environments.
Applications and Use Cases
Llama 4 Scout Applications:
- Multimodal Tasks: Ideal for tasks involving text and images, such as visual question answering, image captioning, or multimodal reasoning.
- Extended Context Processing: With its 10M context length, it excels in analyzing long documents, historical data, or large-scale conversations.
- High-Performance Reasoning: Suitable for advanced reasoning tasks like scientific analysis, complex problem solving, and decision-making.
- Cost-Efficient Outputs: Optimized for tasks requiring large-scale text generation with minimal cost for output tokens.
Llama 3.3 70B Applications:
- Coding and Programming: Performs slightly better in coding tasks, making it a strong choice for software development, debugging, and code generation.
- Moderate Context Requirements: Supports up to 131K tokens, suitable for applications like document analysis, summarization, or medium-length conversations.
- General-Purpose Use: Works well for a wide range of tasks, including content creation, question answering, and casual reasoning, where extreme context length or multimodal capability is not required.
- Budget-Friendly for Inputs: A practical choice for tasks with heavy input processing needs, given its balanced cost structure.
Llama 4 Scout vs Llama 3.3 70B: Tasks
Task 1: Logical Reasoning
Prompt: “You walk into a room and see a bed. On the bed there are two dogs, four cats, a giraffe, five cows, and a duck. There are also three chairs and a table. How many legs are on the floor?”
Llama 4 Scout

Llama 3.3 70B

Review:
- Accuracy: Llama 3.3 70B gives the more complete answer (
22 legs), as it includes both the bed legs and the person’s legs, which Llama 4 Scout missed. - Clarity: Llama 4 Scout provides a more structured and detailed explanation, making it easier to follow the reasoning process.
- Interpretation: Llama 3.3 70B’s inclusion of the person’s legs is debatable depending on the question’s intent. If the question explicitly excludes the person, the answer would be
$20$legs.
Task 2: Problem-Solving Skills
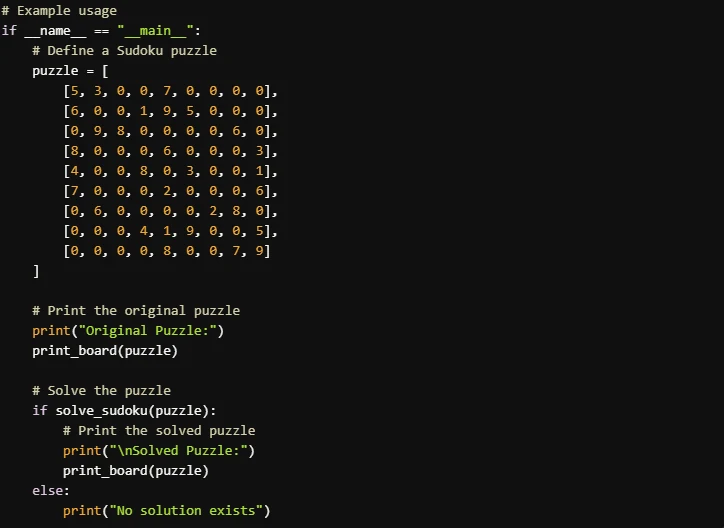
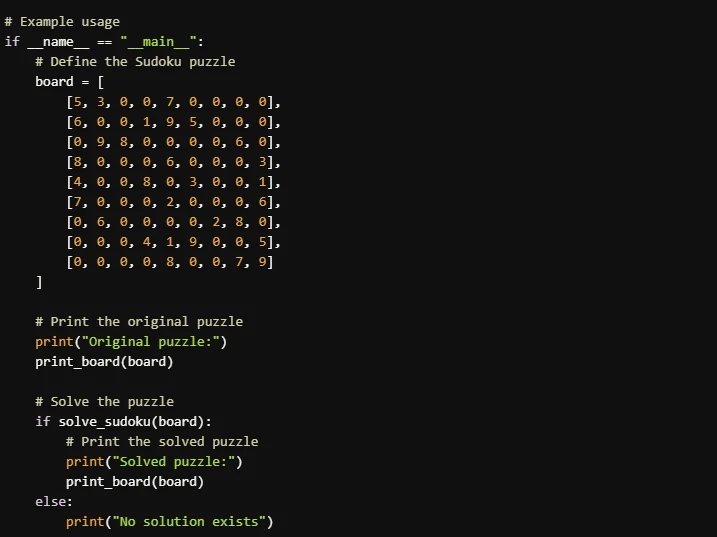
Prompt: “Write a program that can solve a Sudoku puzzle”
Llama 4 Scout
Llama 3.3 70B
Review:
- Llama 4 Scout’s implementation is better for beginners or those who prioritize clarity and detailed explanations. It is easier to follow and includes polished output formatting. Llama 3.3 70B’s implementation is more concise and efficient, making it a good choice for users who are familiar with Sudoku solving algorithms and prefer compact code.
How to Access Llama 4 Scout and Llama 3.3 70B via Novita API?
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Choosing between Llama 4 Scout and Llama 3.3 70B depends on your requirements. For tasks requiring multimodal inputs, extensive memory, and advanced reasoning, Llama 4 Scout is the superior choice. If your focus is on coding, moderate context lengths, and hardware efficiency, Llama 3.3 70B offers a more practical solution. Explore these models through Novita AI to find the perfect fit for your applications.
Frequently Asked Questions
What makes Llama 4 Scout unique?
The 4B, 12B, and 27B models have a 128K context window, while the 1B model has a 32K context window.Llama 4 Scout supports multimodal inputs (text and images) and offers an unparalleled 10M context length, making it perfect for large-scale reasoning, long document processing, and advanced decision-making tasks.
Who should use Llama 3.3 70B over Llama 4 Scout?
Llama 3.3 70B is ideal for users focused on coding, moderate memory requirements (131K tokens), and those with limited hardware resources.
How to access Llama 4 Scout and Llama 3.3 70B
Novita AI providing the affordable and reliable API for you.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



