

Destaques Principais
Llama 4 Scout: Um modelo multimodal de ponta que suporta entradas de texto e imagem com um comprimento de contexto de 10M, ideal para raciocínio avançado, tarefas de memória estendida e saídas em larga escala com custo eficiente.
Llama 3.3 70B: Limitado a entradas somente texto com um comprimento de contexto de 131K, mas se destaca em tarefas de codificação com implementações concisas e requisitos de hardware mais baixos.
Desempenho: Llama 4 Scout lidera em raciocínio, conhecimento e eficiência de custo, enquanto Llama 3.3 70B tem desempenho ligeiramente melhor em tarefas de codificação.
Requisitos de Hardware: Llama 4 Scout exige recursos computacionais significativamente maiores, enquanto Llama 3.3 70B é mais acessível para aplicações de uso geral.
Llama 4 Scout e Llama 3.3 70B representam dois modelos de linguagem grandes e poderosos, projetados para casos de uso distintos. As capacidades multimodais do Llama 4 Scout e seu comprimento de contexto de 10M o tornam adequado para raciocínio avançado e tarefas de memória estendida. Em contraste, o Llama 3.3 70B brilha em eficiência, desempenho de codificação e requisitos de hardware mais baixos, sendo ideal para aplicações de uso geral. Este guia explora suas diferenças e ajuda você a escolher o modelo certo com base em suas necessidades.
Introdução Básica
O Llama 4 Scout suporta processamento multimodal, permitindo que ele lide com diversos tipos de dados, como texto e imagem, para tarefas complexas como raciocínio visual e síntese de dados. Seu comprimento de contexto de 10M permite processar dados sequenciais massivos, tornando-o ideal para aplicações que exigem memória estendida e consciência de contexto.
Llama 4 Scout
| Categoria | Item | Detalhes |
|---|---|---|
| Informações Básicas | Tamanho do Modelo | 109B parâmetros (17B ativos/token) |
| Código Aberto | Aberto | |
| Arquitetura | 16 Mixture-of-Experts (MoE) | |
| Contexto | Suporta até 10M tokens | |
| Suporte a Idiomas | Idiomas Suportados | Pré-treinado em 200 idiomas. Suporta Árabe, Alemão, Hindi, Indonésio, Inglês, Francês, Italiano, Português, Tagalo, Tailandês, Vietnamita. |
| Multimodal | Capacidade | Entrada: texto multilíngue e imagem; Saída: texto multilíngue e código |
| Treinamento | Dados de Treinamento | ~40 trilhões de tokens |
| Pré-Treinamento | MetaP: Configuração Adaptativa de Especialistas + Treinamento intermediário | |
| Pós-Treinamento | SFT (Easy Data) → RL (Hard Data) → DPO | |
| Tamanho do Modelo por Precisão | Tipo de Tensor | BF16 |
Llama 3.3 70B
| Categoria | Item | Detalhes |
|---|---|---|
| Informações Básicas | Tamanho do Modelo | 70B parâmetros |
| Código Aberto | Aberto | |
| Arquitetura | Arquitetura Transformer Otimizada, GQA | |
| Contexto | 131K | |
| Suporte a Idiomas | Idiomas Suportados | Suporta oito idiomas |
| Multimodal | Capacidade | Texto para texto |
| Treinamento | Dados de Treinamento | 15 trilhões de tokens |
| Método de Treinamento | Ajuste Fino Supervisionado (SFT) e Aprendizado por Reforço com Feedback Humano (RLHF) | |
| Tamanho do Modelo por Precisão | Tipo de Tensor | BF16 |
Comparação de Benchmarks
Agora que estabelecemos as características básicas de cada modelo, vamos nos aprofundar em seu desempenho em vários benchmarks. Esta comparação ajudará a ilustrar seus pontos fortes em diferentes áreas.
| Categoria | Benchmark | Llama 4 Scout | Llama 3.3 70B |
|---|---|---|---|
| Codificação | LiveCodeBench | 32,8 | 33,3 |
| Raciocínio | MMLU Pro | 74,3 | 68,9 |
| Conhecimento | GPQA Diamond | 57,2 | 50,5 |
| Preços (Novita AI) | 1M Tokens de Entrada | $0,10 | $0,10 |
| 1M Tokens de Saída | $0,13 | $0,39 |
Escolha o Llama 4 Scout para tarefas diversas que priorizam raciocínio, conhecimento e eficiência de custo. Opte pelo Llama 3.3 70B se o desempenho em codificação for o requisito principal.
Se você quiser ver mais comparações, confira estes artigos:
- A VRAM de um único H100 Consegue Executar o Llama 4 Scout?
- DeepSeek R1 vs OpenAI o1: Arquiteturas Distintas de GRPO e PPO
- Guia: Acessando o Llama 4 Scout Localmente, Via API ou em GPUs na Nuvem
Comparação de Velocidade
Se quiser testar por conta própria, você pode iniciar uma avaliação gratuita no site da Novita AI.

Experimente a Demonstração do Llama 4 Scout Agora!
Comparação de Velocidade
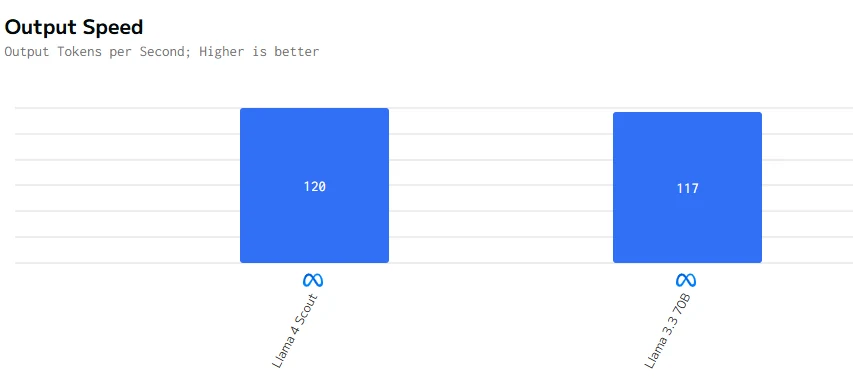
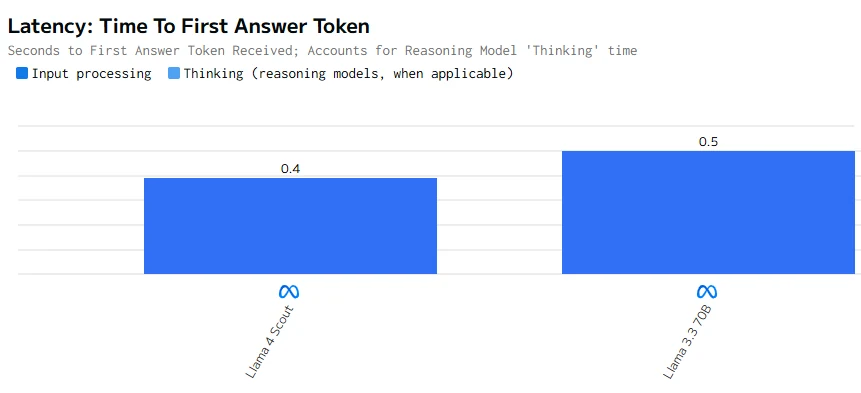
O Llama 4 Scout é mais rápido tanto na geração de tokens quanto na produção do primeiro token. Essas qualidades o tornam mais adequado para aplicações que exigem baixa latência e alta capacidade de resposta.
Requisitos de Hardware
| Modelo | Comprimento do Contexto | VRAM Int4 | Necessidades de GPU (Int4) | VRAM FP16 | Necessidades de GPU (FP16) |
|---|---|---|---|---|---|
| Llama 3.3 70B | 131K Tokens | 194,14GB | 4xH100 | ||
| Llama 4 Scout | 4K Tokens | ~99,5 GB | 1× H100 | ~345 GB | 8× H100 |
| 128K Tokens | ~334 GB | 8× H100 | ~579 GB | 8× H100 | |
| 10M Tokens | ~18,8 TB | 240× H100 | Mesmo que INT4 (dominância de KV Cache) | 240× H100 |
Requisitos de Hardware: O Llama 3.3 70B mantém requisitos de hardware mais baixos, mesmo para comprimentos de contexto estendidos (131K tokens com 4× H100). Em contraste, o Llama 4 Scout é intensivo em hardware, especialmente para tarefas que envolvem 128K ou 10M tokens.
Escalabilidade: O Llama 4 Scout suporta comprimentos de contexto ultra-longos (até 10M tokens), mas ao custo de recursos computacionais extremos, tornando-o adequado para aplicações de nicho e alto orçamento.
Praticidade: O Llama 3.3 70B é mais adequado para casos de uso de uso geral com alta eficiência e acessibilidade a recursos. O Llama 4 Scout é ideal para cenários especializados que exigem contextos massivos de tokens, mas suas demandas o tornam menos prático para ambientes típicos.
Aplicações e Casos de Uso
Aplicações do Llama 4 Scout:
- Tarefas Multimodais: Ideal para tarefas envolvendo texto e imagem, como resposta a perguntas visuais, legendagem de imagens ou raciocínio multimodal.
- Processamento de Contexto Estendido: Com seu comprimento de contexto de 10M, destaca-se na análise de documentos longos, dados históricos ou conversas em grande escala.
- Raciocínio de Alto Desempenho: Adequado para tarefas de raciocínio avançado como análise científica, resolução de problemas complexos e tomada de decisão.
- Saídas com Custo Eficiente: Otimizado para tarefas que exigem geração de texto em larga escala com custo mínimo para tokens de saída.
Aplicações do Llama 3.3 70B:
- Codificação e Programação: Apresenta desempenho ligeiramente melhor em tarefas de codificação, sendo uma escolha forte para desenvolvimento de software, depuração e geração de código.
- Requisitos de Contexto Moderados: Suporta até 131K tokens, adequado para aplicações como análise de documentos, sumarização ou conversas de comprimento médio.
- Uso Geral: Funciona bem para uma ampla gama de tarefas, incluindo criação de conteúdo, resposta a perguntas e raciocínio casual, onde comprimento de contexto extremo ou capacidade multimodal não são necessários.
- Custo-Benefício para Entradas: Uma escolha prática para tarefas com necessidades pesadas de processamento de entrada, dada sua estrutura de custos equilibrada.
Llama 4 Scout vs Llama 3.3 70B: Tarefas
Tarefa 1: Raciocínio Lógico
Prompt: “Você entra em uma sala e vê uma cama. Na cama há dois cachorros, quatro gatos, uma girafa, cinco vacas e um pato. Há também três cadeiras e uma mesa. Quantas pernas estão no chão?”
Llama 4 Scout

Llama 3.3 70B

Avaliação:
- Precisão: O Llama 3.3 70B fornece a resposta mais completa (
22 pernas), pois inclui tanto as pernas da cama quanto as pernas da pessoa, que o Llama 4 Scout deixou de lado. - Clareza: O Llama 4 Scout fornece uma explicação mais estruturada e detalhada, facilitando o acompanhamento do processo de raciocínio.
- Interpretação: A inclusão das pernas da pessoa pelo Llama 3.3 70B é discutível dependendo da intenção da pergunta. Se a pergunta exclui explicitamente a pessoa, a resposta seria
$20$pernas.
Tarefa 2: Habilidades de Resolução de Problemas
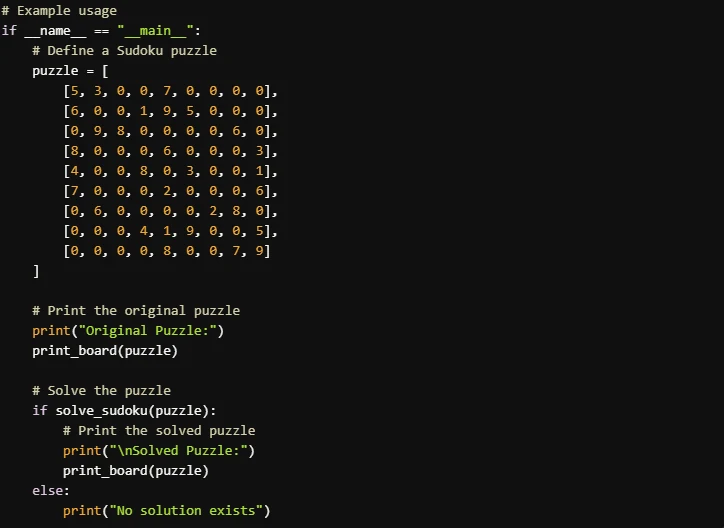
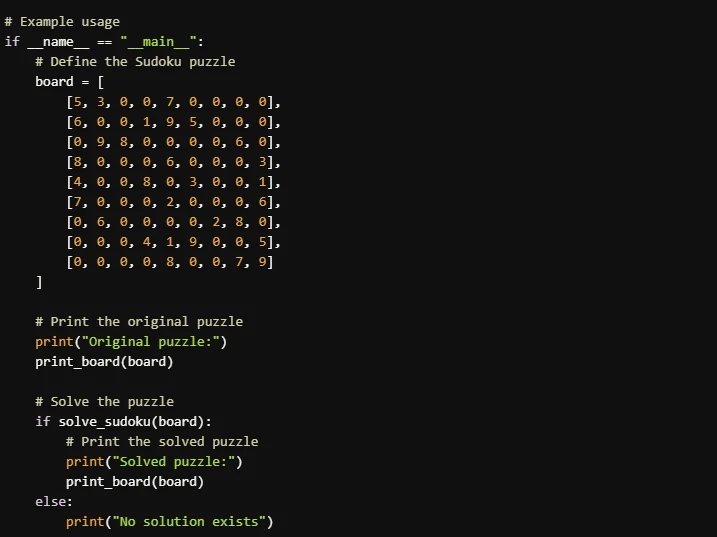
Prompt: “Escreva um programa que resolva um quebra-cabeça Sudoku”
Llama 4 Scout
Llama 3.3 70B
Avaliação:
- A implementação do Llama 4 Scout é melhor para iniciantes ou para quem prioriza clareza e explicações detalhadas. É mais fácil de acompanhar e inclui formatação de saída polida. A implementação do Llama 3.3 70B é mais concisa e eficiente, tornando-se uma boa escolha para usuários familiarizados com algoritmos de resolução de Sudoku que preferem código compacto.
Como Acessar o Llama 4 Scout e o Llama 3.3 70B via API da Novita?
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login em sua conta e clique no botão Model Library.

Experimente o Llama 4 Scout Agora!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie Sua Avaliação Gratuita
Inicie sua avaliação gratuita para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Entrando na página Settings, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias em seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Seja um assistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Escolher entre Llama 4 Scout e Llama 3.3 70B depende de suas necessidades. Para tarefas que exigem entradas multimodais, memória extensa e raciocínio avançado, o Llama 4 Scout é a escolha superior. Se seu foco for codificação, comprimentos de contexto moderados e eficiência de hardware, o Llama 3.3 70B oferece uma solução mais prática. Explore esses modelos através da Novita AI para encontrar o ajuste perfeito para suas aplicações.
Perguntas Frequentes
O que torna o Llama 4 Scout único?
Os modelos de 4B, 12B e 27B têm uma janela de contexto de 128K, enquanto o modelo de 1B tem uma janela de contexto de 32K. O Llama 4 Scout suporta entradas multimodais (texto e imagens) e oferece um comprimento de contexto inigualável de 10M, tornando-o perfeito para raciocínio em larga escala, processamento de documentos longos e tarefas avançadas de tomada de decisão.
Quem deve usar o Llama 3.3 70B em vez do Llama 4 Scout?
O Llama 3.3 70B é ideal para usuários focados em codificação, requisitos de memória moderados (131K tokens) e aqueles com recursos de hardware limitados.
Como acessar o Llama 4 Scout e o Llama 3.3 70B
A Novita AI fornece a API acessível e confiável para você.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem de GPU acessível e confiável para construir e escalar.



