

重點摘要
- 本指南提供完整的逐步教學,教你如何下載並執行 Llama 3.2 1B——一款強大且易於使用的語言模型。
- 了解模型的能力、系統需求以及逐步安裝流程。
- 找到常見安裝問題的解決方案,並探索在行動裝置上執行 Llama 3.2 1B 的選項。
- 了解如何利用如 NovitaAI 等平台來簡化存取與實作。
- 本指南適合初學者,提供清晰簡潔的路徑讓你能體驗這項強大技術。
Llama 3.2 1B 是一款輕量級語言模型,擁有 10 億個參數,專為提供強大的自然語言處理能力(如文字生成、摘要、問答)而設計,同時將計算需求降到最低。與 GPT-3 等大型模型相比,它的尺寸較小,非常適合資源受限的環境,能在不需強大硬體的情況下提供高效能。
此外,Llama 3.2 1B 針對行動裝置進行了最佳化,開發者可透過雲端 API 將其整合至行動應用程式,同時支援 Android 與 iOS 裝置。基準測試結果證實,Llama 3.2 1B 在準確度和效率上具有競爭力,在性能與成本效益之間取得良好平衡。本指南將說明如何在本機下載、安裝與執行 Llama 3.2 1B,或透過 Novita AI 簡化的 API 在行動平台上輕鬆部署。
認識 Llama 3.2 1B
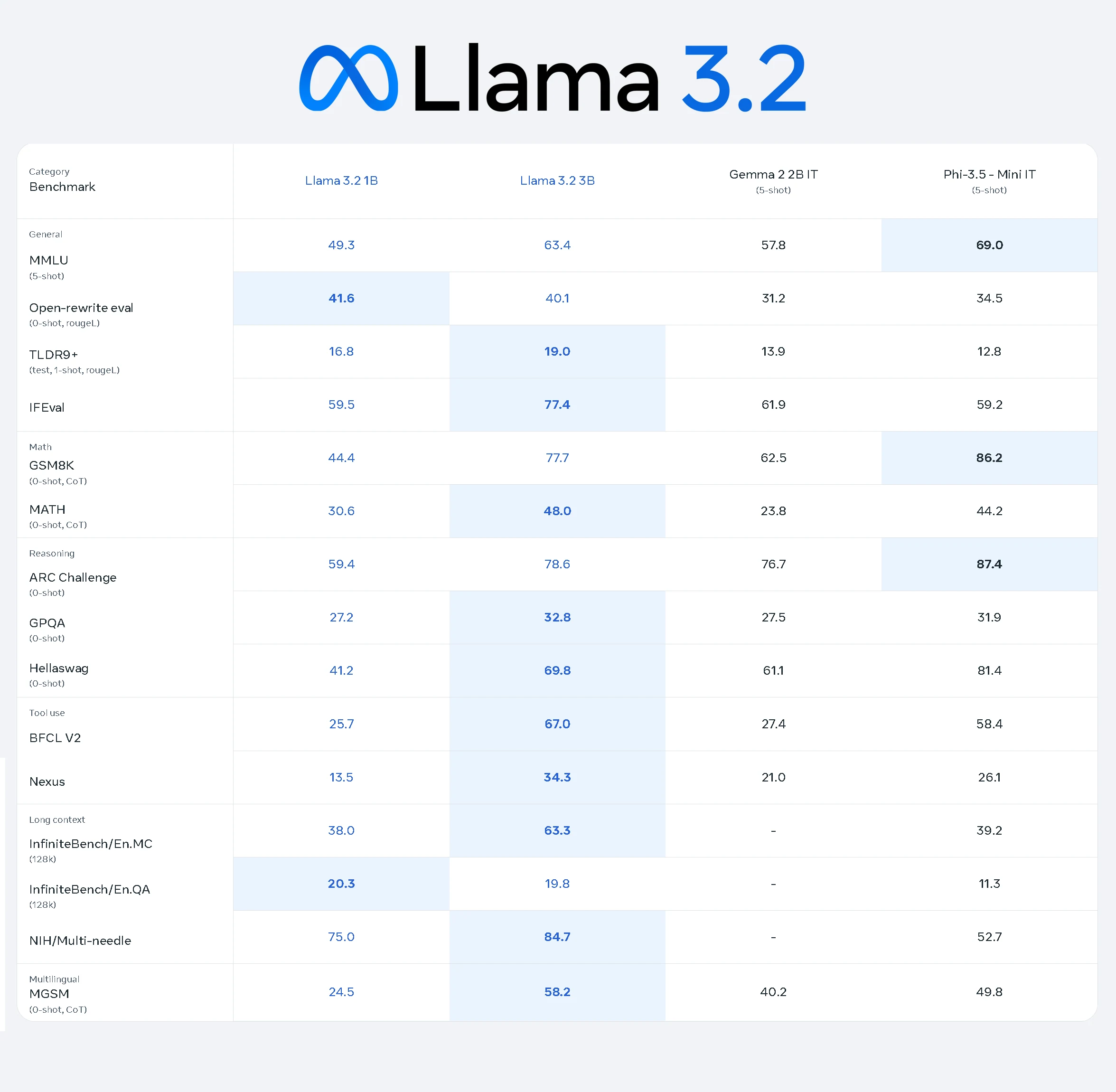
Llama 3.2 1B 模型在各種任務上展現穩定的效能,凸顯其作為輕量卻有效 AI 模型的能力:
- 一般任務:MMLU 分數 49.3,顯示在一般知識任務上有中等表現。
- 數學任務:GSM8K 分數 44.4,MATH 分數 30.6,反映基本的推理與算術能力。
- 推理能力:ARC Challenge 分數 59.4,Hellaswag 分數 41.2,展現邏輯推理潛力。
- 工具使用:BFCL V2 分數 25.7,顯示有限但可用的工具使用能力。
- 長上下文:InfiniteBench/En.MC 分數 38.0,展現對長上下文任務的處理能力。
- 多語言任務:MGSM 分數 24.5,表示基礎的多語言理解能力。
如何在電腦上安裝 Llama 3.2 1B?
步驟 1:設定環境
在執行 Llama 3.2 1B 之前,你需要先確認系統是否就緒。無論你使用 Windows、macOS 還是 Linux,請確保擁有適合 AI 工作的環境。Llama 3.2 1B 需要:
- 64 位元作業系統:Windows、macOS 或 Linux。
- 記憶體:至少 8GB RAM 以順暢運作;16GB 以上更適合執行較大模型。
- 儲存空間:確保有至少 20GB 的可用空間來容納模型檔案。
請安裝 Python 環境(版本 3.7 或更高),因為 Llama 3.2 1B 是使用 Python 建構的。
步驟 2:安裝所需依賴套件
Llama 3.2 1B 需要幾個 Python 函式庫才能有效執行,包括:
- TensorFlow 或 PyTorch(取決於你選擇的框架)。
- Transformers 函式庫(Hugging Face 提供)用於載入與操作模型。
- NumPy 用於數值運算與資料處理。
若要安裝必要的依賴套件,請開啟命令列介面(CLI)並執行以下指令:
pip install torch transformers numpy
如果你使用 TensorFlow,請將 torch 替換為 tensorflow。
步驟 3:從官方來源下載 Llama 3.2 1B
接下來,你需要下載模型檔案。務必使用官方來源以確保檔案安全且為最新版本。Llama 3.2 1B 可在 Hugging Face 等平台或官方儲存庫中取得。前往對應頁面下載模型權重與設定檔。
或者,你也可以使用 GitHub 直接複製儲存庫:
git clone https://github.com/llama3.2/llama-1b
步驟 4:執行安裝精靈
下載必要檔案後,執行 Llama 3.2 1B 儲存庫提供的安裝精靈。此步驟將設定環境、安裝其他需求,並確保一切就緒以執行模型。
python setup.py install
此步驟可能需要一些時間,取決於你的網路速度與系統性能。
步驟 5:驗證安裝
安裝完成後,務必驗證一切是否正常運作。為此,請執行以下測試指令:
python -c "import llama; print(llama.__version__)"
若模型正確安裝,你會在終端機看到 Llama 3.2 1B 的版本號。如果出現錯誤,請重新檢查設定步驟與依賴套件。
步驟 6:成功執行 Llama 3.2 1B
現在一切就緒,可以執行模型了。建立一個簡單的 Python 腳本來載入並執行 Llama 3.2 1B:
from transformers import LlamaForCausalLM, LlamaTokenizer
# 載入模型與分詞器
model = LlamaForCausalLM.from_pretrained("llama-3.2-1b")
tokenizer = LlamaTokenizer.from_pretrained("llama-3.2-1b")
# 範例輸入文字
input_text = "Hello, how can I help you today?"
# 分詞並生成輸出
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs)
# 解碼輸出
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
執行此腳本即可看到模型運作情形。如果成功產生文字輸出,你已成功安裝並設定好 Llama 3.2 1B。
在行動裝置上執行 Llama 3.2 1B
在行動裝置上執行 Llama 3.2 1B 模型因資源需求高而存在獨特挑戰。然而,雲端運算與行動最佳化的進展已使透過 API 存取模型,或在裝置上直接執行輕量版本變得可行。以下提供針對 Android 與 iOS 使用者的詳細指南。
Android 使用者
直接在 Android 裝置上執行 Llama 3.2 1B 由於計算需求高而較困難。以下為透過雲端服務存取的逐步步驟:
- 安裝 API 客戶端:
- 從 Google Play 商店下載並安裝 API 客戶端,例如 Postman 或 Insomnia。這些工具可促進與雲端 API 的通訊。
- 存取雲端實例:
- 取得雲端代管 Llama 3.2 1B 實例的 API 端點。通常需要註冊提供 Llama 模型的服務,例如 Hugging Face 或 Meta 的 API 服務。
- 發送請求:
- 使用 API 客戶端發送請求。以下為在 Android 中使用
Retrofit進行 API 請求的程式碼範例: - 伺服器會處理你的輸入並回傳結果,你可直接在 API 客戶端中檢視。
- 使用 API 客戶端發送請求。以下為在 Android 中使用
- 考慮本機選項:
- 若偏好在本機執行模型,請尋找針對行動裝置最佳化的量化版本 Llama 3.2,這類模型在保持效能的同時減少記憶體使用。這些模型可在具備足夠 RAM(通常至少 6GB)的裝置上執行。
iOS 使用者
iOS 存取 Llama 3.2 的流程與 Android 類似,但包含更多本機執行選項:
- 安裝 API 客戶端:
- 使用 API 客戶端應用程式,如 Postman,或專為與 AI 模型互動設計的應用程式。
- 存取雲端 API:
- 連線到位於雲端伺服器的 Llama 3.2 1B API,因為在 iOS 裝置上直接執行完整模型通常需要大量資源。
- 處理請求:
- 將資料輸入 API 客戶端並發送請求,以從伺服器接收結果。
import Foundation
func sendRequest() {
let url = URL(string: "https://api.novita.ai/your/api/endpoint")! // 請替換為你的端點
var request = URLRequest(url: url)
request.httpMethod = "POST"
request.setValue("Bearer YOUR_API_KEY", forHTTPHeaderField: "Authorization")
request.setValue("application/json", forHTTPHeaderField: "Content-Type")
let input = ["input": "Hello, how can I assist you today?"]
let jsonData = try? JSONSerialization.data(withJSONObject: input)
request.httpBody = jsonData
let task = URLSession.shared.dataTask(with: request) { data, response, error in
if let data = data, let response = response {
print("Response: \(response)")
// 視需要處理資料
}
}
task.resume()
}
- 在本機執行(如適用):
- 近期更新允許在特定 iOS 裝置(iPhone 12 Pro 及更新機型)上,使用最佳化應用程式(如 Private LLM)在本機執行 Llama 3.2。此設定確保所有處理在裝置上進行,增強隱私,因為不會將資料發送至外部伺服器。
重要考量
- 資源需求:Llama 3.2 模型需要大量計算資源,在未經最佳化的情況下,直接於一般行動裝置上執行並不實際。
- 隱私與安全:使用雲端服務可能引發資料隱私問題;因此建議在可行時使用本機模型。
- 模型變體:Llama 3.2 系列包含多種尺寸(1B 與 3B 參數)以及專門為行動部署設計的量化版本,在效能與資源使用之間提供取捨。
在 Novita AI 上輕鬆執行 Llama 3.2 1B
如何透過 Novita AI 存取 Llama 3.2-1B API
本指南將協助你輕鬆透過 Novita AI 平台存取 Llama 3.2-1B API。請依照以下簡單步驟開始使用。
步驟 1:註冊 Novita AI
前往 Novita AI 網站。按一下 Sign Up 按鈕建立帳戶。
步驟 2:導覽至模型 API 區塊
登入後,前往儀表板的 API 區塊。在可用 API 清單中尋找 Llama 3.2-1B 模型。
步驟 3:取得你的 API 金鑰
按一下 Llama 3.2-1B 模型連結。你會找到產生或檢視 API 金鑰的選項。複製此金鑰,你將需要它來進行 API 請求。
步驟 4:將 API 整合至你的應用程式
- 探索 LLM API 參考資料,了解可用的 API 與模型。
- 使用你最喜愛的程式語言發送 HTTP 請求。以下為使用 Python
requests函式庫的簡單範例:
import requests
url = "https://api.novita.ai/llama-3.2-1b"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"input": "Hello, how can I assist you today?"
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
- 將
YOUR_API_KEY替換為你先前複製的 API 金鑰。
步驟 5:測試你的整合
執行你的腳本,確認它能正確與 Llama 3.2-1B API 通訊。檢查回應中是否有任何錯誤,並視需要調整請求。
使用 Novita AI API 的優點
- 無複雜設定:API 可立即使用,無需安裝或本機基礎設施。
- 可擴展性:輕鬆擴展應用程式,不受硬體限制。
- 成本效益:僅需為使用的計算資源付費。
無論是在本機電腦上還是透過 Novita AI 等雲端服務執行 Llama 3.2 1B,都比以往更容易。按照本指南的步驟,你可以利用這款尖端模型處理各種自然語言任務。無論是建立聊天機器人、進行資料分析,還是單純探索 AI,Llama 3.2 1B 都是一款絕佳的工具。
常見問題與解答
- 如何將 Llama 3.2 1B 更新至最新版本? 請在官方儲存庫檢查最新版本,並依照更新說明進行。
- 保護 Llama 3.2 1B 安裝的最佳實踐是什麼? 保持軟體更新、使用防火牆和 VPN,並限制網路存取僅限授權使用者。
- 如何在 Windows 上本機執行 Llama 3.2? 安裝 Python 與依賴套件、下載模型,然後使用腳本或命令列介面執行。
Novita AI 是一個全能雲端平台,助力你的 AI 抱負。整合 API、無伺服器、GPU 實例——你所需的經濟高效工具。無需基礎設施,免費開始,讓你的 AI 願景成真。
推薦閱讀
- [1. 解鎖 Llama 3.2 的力量:多模態使用案例與應用](http://Unlocking the Power of Llama 3.2: Multimodal Use Cases and Applications)
- [2. 如何存取 Llama 3.2:簡化你的 AI 開發流程](http://How to Access Llama 3.2: Streamlining Your AI Development Process)
- 3. Llama 3.2 VS Claude 3.5:哪一個 AI 模型適合你的專案?



