

Points clés
- Ce guide propose un parcours complet pour télécharger et exécuter Llama 3.2 1B, un modèle de langage puissant et accessible.
- Apprenez les capacités du modèle, les prérequis système et le processus d’installation pas à pas.
- Trouvez des solutions aux problèmes d’installation courants et explorez les options pour exécuter Llama 3.2 1B sur appareils mobiles.
- Découvrez comment tirer parti de plateformes comme NovitaAI pour un accès et une implémentation simplifiés.
- Ce guide s’adresse aux débutants, offrant un chemin clair et concis pour découvrir la puissance
Llama 3.2 1B est un modèle de langage léger avec 1 milliard de paramètres, conçu pour offrir des capacités de NLP puissantes telles que la génération de texte, le résumé et la réponse aux questions, tout en minimisant les besoins en calcul. Sa taille plus petite par rapport à des modèles plus grands comme GPT-3 le rend idéal pour les environnements à ressources limitées, offrant des performances élevées sans nécessiter de matériel étendu.
De plus, Llama 3.2 1B est optimisé pour une utilisation mobile, permettant aux développeurs de l’intégrer dans des applications mobiles via des API cloud, le rendant accessible aussi bien sur les appareils Android que iOS. Les tests de référence confirment que Llama 3.2 1B offre une précision et une efficacité compétitives, avec un bon équilibre entre performances et rentabilité. Ce guide couvre comment télécharger, installer et exécuter Llama 3.2 1B en local ou y accéder via l’API simplifiée de Novita AI pour un déploiement facile sur les plateformes mobiles.
Comprendre Llama 3.2 1B
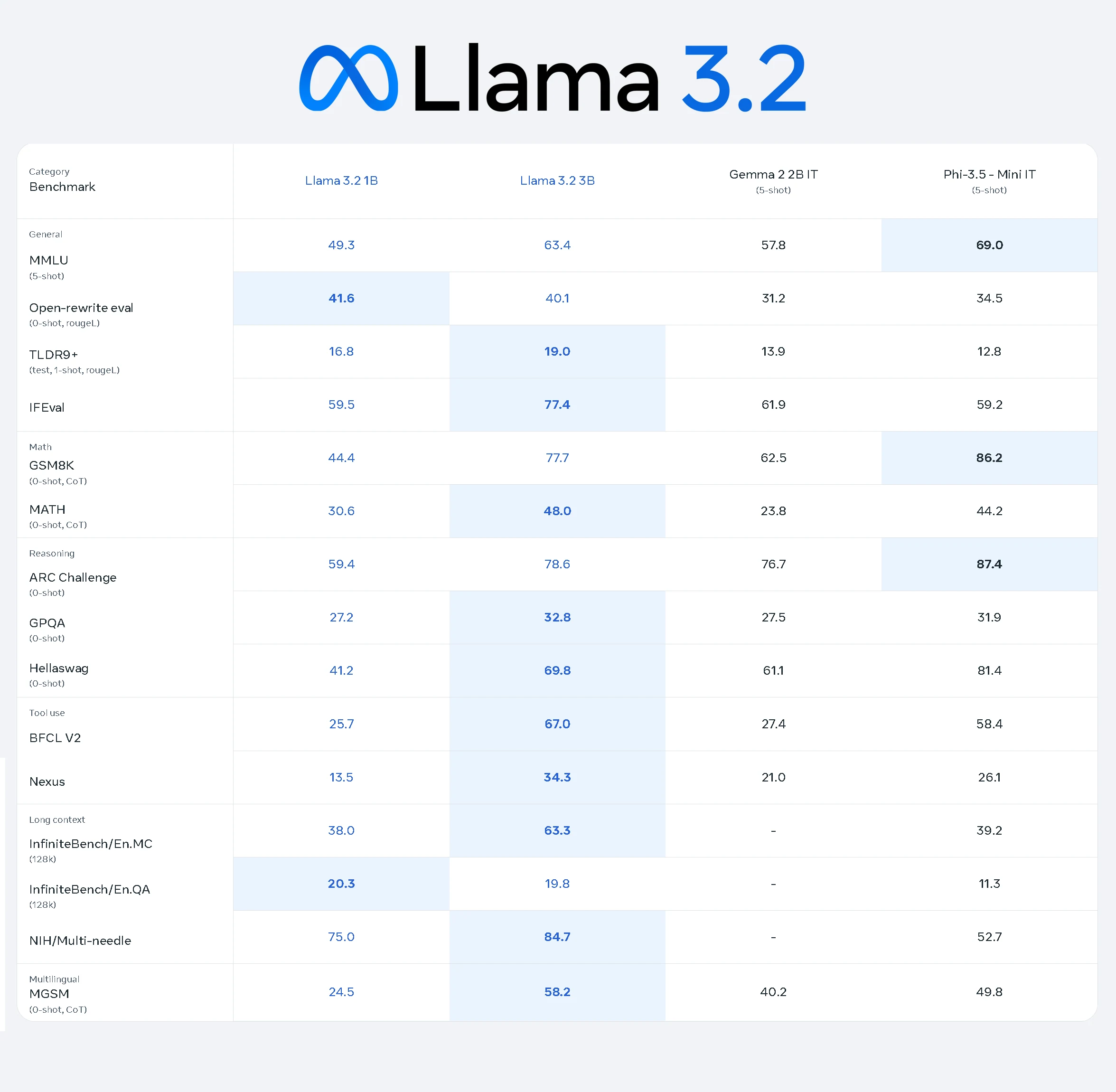
Le modèle Llama 3.2 1B démontre des performances solides sur diverses tâches, mettant en avant ses capacités en tant que modèle IA léger mais efficace :
- Tâches générales : obtient un score de 49,3 sur MMLU, indiquant des performances modérées dans les tâches de connaissances générales.
- Tâches mathématiques : scores de 44,4 sur GSM8K et 30,6 sur MATH, reflétant des capacités de raisonnement et d’arithmétique de base.
- Raisonnement : bonnes performances avec un score de 59,4 sur ARC Challenge et 41,2 sur Hellaswag, soulignant son potentiel de raisonnement logique.
- Utilisation d’outils : score de 25,7 sur BFCL V2, montrant des capacités limitées mais fonctionnelles.
- Contextes longs : atteint 38,0 sur InfiniteBench/En.MC, démontrant une gestion correcte des tâches à contexte étendu.
- Tâches multilingues : enregistre un score de 24,5 sur MGSM, indiquant une compréhension multilingue de base.
Comment installer Llama 3.2 1B sur votre ordinateur ?
Étape 1 : Préparer votre environnement
Avant de pouvoir exécuter Llama 3.2 1B, vous devez vous assurer que votre système est prêt. Que vous utilisiez Windows, macOS ou Linux, assurez-vous d’avoir un environnement adapté aux charges de travail IA. Llama 3.2 1B nécessite :
- Un OS 64 bits : Windows, macOS ou Linux.
- RAM : au moins 8 Go pour un fonctionnement fluide ; 16 Go ou plus est idéal pour exécuter des modèles plus grands.
- Stockage : assurez-vous d’avoir au moins 20 Go d’espace libre pour accueillir les fichiers du modèle.
Assurez-vous d’installer un environnement Python (version 3.7 ou supérieure), car Llama 3.2 1B est construit avec Python.
Étape 2 : Installer les dépendances requises
Llama 3.2 1B nécessite plusieurs bibliothèques Python pour fonctionner efficacement. Cela inclut :
- TensorFlow ou PyTorch (selon le framework choisi).
- La bibliothèque Transformers de Hugging Face pour le chargement et la manipulation du modèle.
- NumPy pour les opérations numériques et le traitement des données.
Pour installer les dépendances nécessaires, ouvrez votre interface en ligne de commande (CLI) et exécutez les commandes suivantes :
pip install torch transformers numpy
Si vous utilisez TensorFlow, remplacez torch par tensorflow.
Étape 3 : Télécharger Llama 3.2 1B depuis les sources officielles
Ensuite, vous devrez télécharger les fichiers du modèle. Il est essentiel d’utiliser des sources officielles pour garantir que les fichiers sont sûrs et à jour. Llama 3.2 1B est disponible sur des plateformes comme Hugging Face ou depuis le dépôt officiel. Visitez la page appropriée pour Llama 3.2 1B et téléchargez les poids du modèle et les fichiers de configuration.
Vous pouvez également utiliser GitHub pour cloner directement le dépôt :
git clone https://github.com/llama3.2/llama-1b
Étape 4 : Exécuter l’assistant d’installation
Une fois que vous avez téléchargé les fichiers nécessaires, exécutez l’assistant d’installation fourni par le dépôt Llama 3.2 1B. Cela configurera l’environnement, installera les dépendances supplémentaires et s’assurera que tout est en place pour exécuter le modèle.
python setup.py install
Cette étape peut prendre un certain temps en fonction de votre vitesse Internet et des performances de votre système.
Étape 5 : Vérifier l’installation
Après l’installation, il est crucial de vérifier que tout fonctionne correctement. Pour ce faire, exécutez la commande de test suivante :
python -c "import llama; print(llama.__version__)"
Si le modèle est correctement installé, vous devriez voir la version de Llama 3.2 1B s’afficher dans le terminal. S’il y a des erreurs, revoyez les instructions d’installation et les dépendances.
Étape 6 : Exécuter Llama 3.2 1B avec succès
Maintenant que tout est configuré, il est temps d’exécuter le modèle. Créez un script Python simple pour charger et exécuter Llama 3.2 1B :
from transformers import LlamaForCausalLM, LlamaTokenizer
# Charger le modèle et le tokenizer
model = LlamaForCausalLM.from_pretrained("llama-3.2-1b")
tokenizer = LlamaTokenizer.from_pretrained("llama-3.2-1b")
# Exemple de texte d'entrée
input_text = "Bonjour, comment puis-je vous aider aujourd'hui ?"
# Tokeniser et générer la sortie
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs)
# Décoder la sortie
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Exécutez ce script pour voir le modèle en action. S’il produit une sortie textuelle, vous avez installé et configuré Llama 3.2 1B avec succès.
Exécuter Llama 3.2 1B sur un appareil mobile
L’exécution du modèle Llama 3.2 1B sur des appareils mobiles présente des défis uniques en raison de sa nature gourmande en ressources. Cependant, les progrès du cloud computing et de l’optimisation mobile ont rendu possible l’accès à ces modèles via des API ou l’exécution de versions plus légères directement sur les appareils. Vous trouverez ci-dessous un guide détaillé adapté aux utilisateurs Android et iOS.
Pour les utilisateurs Android
Exécuter Llama 3.2 1B directement sur des appareils Android peut être difficile en raison des besoins élevés en calcul. Voici un guide étape par étape pour y accéder via des services cloud :
- Installer un client API :
- Téléchargez et installez un client API tel que Postman ou Insomnia depuis le Google Play Store. Ces outils facilitent la communication avec les API cloud.
- Accéder à l’instance cloud :
- Obtenez le point de terminaison API d’une instance Llama 3.2 1B hébergée dans le cloud. Cela implique généralement de s’inscrire à un service proposant des modèles Llama, comme les offres API de Hugging Face ou de Meta.
- Envoyer des requêtes :
- Utilisez le client API pour envoyer des requêtes. Voici un exemple de code utilisant
Retrofitsous Android pour effectuer une requête API :
- Utilisez le client API pour envoyer des requêtes. Voici un exemple de code utilisant
- Considérer les options locales :
- Si vous préférez exécuter les modèles localement, recherchez des versions quantifiées de Llama 3.2 optimisées pour les appareils mobiles, qui réduisent l’utilisation de la mémoire tout en maintenant les performances. Ces modèles peuvent être exécutés sur des appareils avec suffisamment de RAM (généralement au moins 6 Go).
Pour les utilisateurs iOS
Le processus d’accès à Llama 3.2 sur iOS est similaire à celui d’Android, mais inclut des options supplémentaires pour une exécution locale :
- Installer un client API :
- Utilisez une application cliente API comme Postman ou une application dédiée conçue pour interagir avec les modèles d’IA.
- Accéder aux API cloud :
- Connectez-vous à l’API Llama 3.2 1B hébergée sur des serveurs cloud, car exécuter le modèle complet directement sur des appareils iOS n’est généralement pas réalisable sans ressources importantes.
- Traiter les requêtes :
- Saisissez vos données dans le client API et envoyez des requêtes pour recevoir les résultats du serveur.
import Foundation
func sendRequest() {
let url = URL(string: "https://api.novita.ai/your/api/endpoint")! // Remplacez par votre point de terminaison
var request = URLRequest(url: url)
request.httpMethod = "POST"
request.setValue("Bearer YOUR_API_KEY", forHTTPHeaderField: "Authorization")
request.setValue("application/json", forHTTPHeaderField: "Content-Type")
let input = ["input": "Bonjour, comment puis-je vous aider aujourd'hui ?"]
let jsonData = try? JSONSerialization.data(withJSONObject: input)
request.httpBody = jsonData
let task = URLSession.shared.dataTask(with: request) { data, response, error in
if let data = data, let response = response {
print("Réponse : \(response)")
// Traiter les données selon les besoins
}
}
task.resume()
}
- Exécuter localement (si applicable) :
- Des mises à jour récentes permettent d’exécuter Llama 3.2 localement sur certains appareils iOS (iPhone 12 Pro et ultérieurs) à l’aide d’applications optimisées comme Private LLM. Cette configuration garantit que tout le traitement s’effectue sur l’appareil, améliorant la confidentialité car aucune donnée n’est envoyée à des serveurs externes.
Considérations clés
- Besoins en ressources : Le modèle Llama 3.2 nécessite des ressources de calcul importantes, rendant son exécution directe sur des appareils mobiles standard peu pratique sans optimisations.
- Confidentialité et sécurité : L’utilisation de services cloud soulève des préoccupations concernant la confidentialité des données ; il est donc recommandé d’utiliser des modèles locaux lorsque c’est possible.
- Variantes du modèle : La famille Llama 3.2 comprend différentes tailles (paramètres 1B et 3B) et des versions quantifiées spécialement conçues pour le déploiement mobile, offrant des compromis entre performances et utilisation des ressources.
Exécutez Llama 3.2 1B facilement sur Novita AI
Comment accéder à l’API Llama 3.2-1B via Novita AI
Ce guide vous aidera à accéder facilement à l’API Llama 3.2-1B en utilisant la plateforme Novita AI. Suivez ces étapes simples pour commencer.
Étape 1 : Inscrivez-vous sur Novita AI
Visitez le site Web de Novita AI. Cliquez sur le bouton S’inscrire pour créer un compte.
Étape 2 : Accédez à la section API du modèle
Après vous être connecté, allez dans la section API de votre tableau de bord. Recherchez le modèle Llama 3.2-1B listé parmi les API disponibles.
Étape 3 : Obtenez votre clé API
Cliquez sur le lien du modèle Llama 3.2-1B. Vous trouverez une option pour générer ou afficher votre clé API. Copiez cette clé, car vous en aurez besoin pour effectuer des requêtes API.
Étape 4 : Intégrez l’API dans votre application
- Explorez la référence de l’API LLM pour découvrir les API et modèles disponibles.
- Utilisez votre langage de programmation préféré pour effectuer des requêtes HTTP.
Voici un exemple simple utilisant Python avec la bibliothèque requests :
import requests
url = "https://api.novita.ai/llama-3.2-1b"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"input": "Bonjour, comment puis-je vous aider aujourd'hui ?"
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
- Remplacez
YOUR_API_KEYpar la clé API que vous avez copiée précédemment.
Étape 5 : Testez votre intégration
Exécutez votre script pour vous assurer qu’il communique correctement avec l’API Llama 3.2-1B. Vérifiez les éventuelles erreurs dans la réponse et ajustez vos requêtes si nécessaire.
Avantages de l’utilisation de l’API Novita AI
- Aucune configuration complexe : L’API est prête à être utilisée immédiatement, sans installation ni infrastructure locale.
- Extensibilité : Faites évoluer facilement vos applications sans limites matérielles.
- Rentabilité : Payez uniquement pour les ressources de calcul que vous utilisez.
Exécuter et utiliser Llama 3.2 1B sur votre machine locale ou via des services cloud comme Novita AI n’a jamais été aussi simple. En suivant les étapes décrites dans ce guide, vous pouvez exploiter la puissance de ce modèle de pointe pour diverses tâches de traitement du langage naturel. Que vous construisiez un chatbot, effectuiez une analyse de données ou exploriez simplement l’IA, Llama 3.2 1B est un outil fantastique à avoir à votre disposition.
Questions fréquemment posées :
- Comment mettre à jour Llama 3.2 1B vers la dernière version ? Vérifiez la dernière version sur le dépôt officiel et suivez les instructions de mise à jour.
- Quelles sont les bonnes pratiques pour sécuriser les installations de Llama 3.2 1B ? Maintenez les logiciels à jour, utilisez des pare-feu et des VPN, et limitez l’accès réseau aux utilisateurs autorisés.
- Comment exécuter Llama 3.2 localement sous Windows ? Installez Python et les dépendances, téléchargez le modèle et exécutez-le à l’aide d’un script ou d’une interface en ligne de commande.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions en IA. API intégrées, serverless, instances GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.
Lecture recommandée
- [1. Déverrouiller la puissance de Llama 3.2 : Cas d’usage et applications multimodaux](http://Déverrouiller la puissance de Llama 3.2 : Cas d’usage et applications multimodaux)
- [2. Comment accéder à Llama 3.2 : Rationaliser votre processus de développement IA](http://Comment accéder à Llama 3.2 : Rationaliser votre processus de développement IA)
- 3. Llama 3.2 vs Claude 3.5 : Quel modèle IA convient à votre projet ?



