

主なポイント
- このガイドでは、強力でアクセスしやすい言語モデルであるLlama 3.2 1Bをダウンロードして実行するための包括的な手順を説明します。
- モデルの機能、システム要件、ステップバイステップのインストールプロセスについて学びます。
- よくあるインストールの問題の解決策や、モバイルデバイスでLlama 3.2 1Bを実行する方法をご紹介します。
- NovitaAIなどのプラットフォームを活用して、アクセスと実装を簡素化する方法をご紹介します。
- このガイドは初心者向けに、Llama 3.2 1Bのパワーを体験するための明確で簡潔な道筋を提供します。
Llama 3.2 1B は、10億パラメータを備えた軽量な言語モデルで、テキスト生成、要約、質問応答などの強力なNLP機能を提供しながら、計算リソースの要件を最小限に抑えるように設計されています。GPT-3のような大規模モデルと比較してサイズが小さいため、リソースが制限された環境に最適で、大規模なハードウェアを必要とせずに高いパフォーマンスを実現します。
さらに、Llama 3.2 1Bはモバイルでの使用に最適化されており、開発者はクラウドベースのAPIを介してモバイルアプリに統合でき、AndroidおよびiOSデバイスの両方でアクセスできます。ベンチマークテストでは、Llama 3.2 1Bが競争力のある精度と効率を提供し、パフォーマンスと費用対効果のバランスが優れていることが確認されています。このガイドでは、Llama 3.2 1Bをローカルでダウンロード、インストール、実行する方法、またはNovita AIの簡略化されたAPIを介してアクセスし、モバイルプラットフォームに簡単にデプロイする方法を説明します。
Llama 3.2 1Bについて理解する
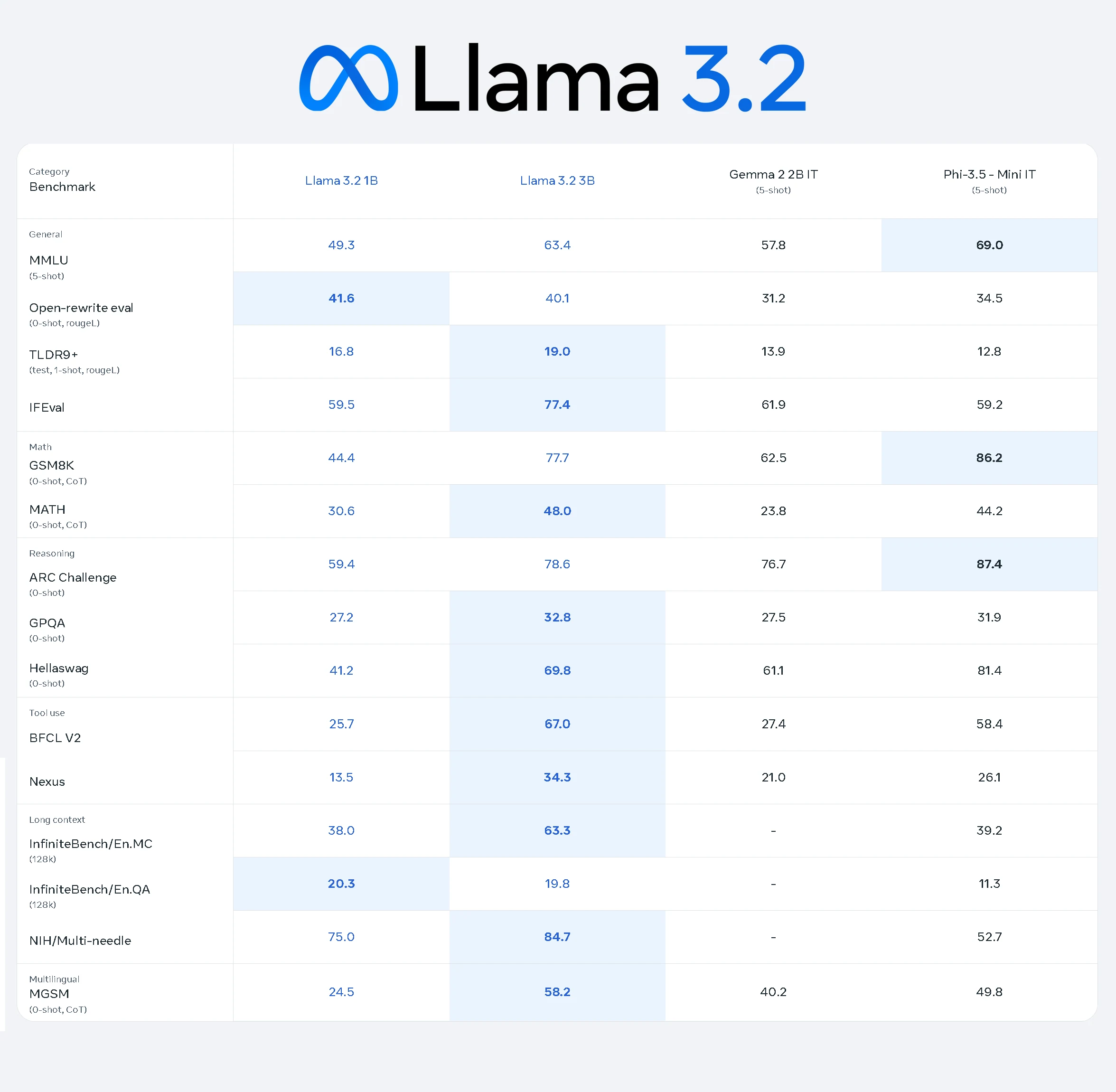
Llama 3.2 1Bモデルは、さまざまなタスクで堅実なパフォーマンスを発揮し、軽量でありながら効果的なAIモデルとしての能力を示しています。
- 一般的なタスク: MMLUで49.3をスコアし、一般的な知識タスクで中程度のパフォーマンスを示しています。
- 数学タスク: GSM8Kで44.4、MATHで30.6をスコアし、基本的な推論と計算能力を反映しています。
- 推論: ARC Challengeで59.4、Hellaswagで41.2と良好なスコアを達成し、論理推論の可能性を示しています。
- ツール使用: BFCL V2で25.7をスコアし、限定的ながら機能的なツール使用能力を示しています。
- 長いコンテキスト: InfiniteBench/En.MCで38.0を達成し、拡張コンテキストタスクを適切に処理できることを示しています。
- 多言語タスク: MGSMで24.5を記録し、基本的な多言語理解を示しています。
Llama 3.2 1Bをコンピュータにインストールする方法
ステップ1: 環境のセットアップ
Llama 3.2 1Bを実行する前に、システムが準備できていることを確認する必要があります。Windows、macOS、Linuxのいずれを使用していても、AIワークロードに適した環境を用意してください。Llama 3.2 1Bに必要なものは次のとおりです。
- 64ビットOS: Windows、macOS、またはLinux。
- RAM: スムーズな動作には少なくとも8GB、より大きなモデルを実行するには16GB以上が理想的です。
- ストレージ: モデルファイルを格納するために、少なくとも20GBの空き容量を確保してください。
Llama 3.2 1BはPythonで構築されているため、Python環境(バージョン3.7以上)をインストールしてください。
ステップ2: 必要な依存関係のインストール
Llama 3.2 1Bを効率的に実行するには、いくつかのPythonライブラリが必要です。これには以下が含まれます。
- TensorFlow または PyTorch(選択したフレームワークによる)。
- Hugging Faceの Transformers ライブラリ(モデルのロードと操作のため)。
- NumPy(数値演算とデータ処理のため)。
必要な依存関係をインストールするには、コマンドラインインターフェース(CLI)を開き、次のコマンドを実行します。
pip install torch transformers numpy
TensorFlowを使用する場合は、torch を tensorflow に置き換えてください。
ステップ3: 公式ソースからLlama 3.2 1Bをダウンロード
次に、モデルファイルをダウンロードする必要があります。ファイルが安全で最新であることを確認するために、公式ソースを使用することが重要です。Llama 3.2 1Bは、Hugging Face などのプラットフォームや公式リポジトリから入手できます。Llama 3.2 1Bの該当ページにアクセスし、モデルの重みと設定ファイルをダウンロードしてください。
あるいは、GitHub を使用してリポジトリを直接クローンすることもできます。
git clone https://github.com/llama3.2/llama-1b
ステップ4: インストールウィザードの実行
必要なファイルをダウンロードしたら、Llama 3.2 1Bリポジトリが提供するインストールウィザードを実行します。これにより、環境がセットアップされ、追加の要件がインストールされ、モデルを実行するためのすべてが整っていることが確認されます。
python setup.py install
この手順は、インターネットの速度やシステムのパフォーマンスによって時間がかかる場合があります。
ステップ5: インストールの確認
インストール後、すべてが正しく機能していることを確認することが重要です。これを行うには、次のテストコマンドを実行します。
python -c "import llama; print(llama.__version__)"
モデルが正しくインストールされていれば、ターミナルに Llama 3.2 1B のバージョンが表示されます。エラーがある場合は、セットアップ手順と依存関係を再度確認してください。
ステップ6: Llama 3.2 1Bを正常に実行
すべてのセットアップが完了したら、モデルを実行します。Llama 3.2 1Bをロードして実行する簡単なPythonスクリプトを作成します。
from transformers import LlamaForCausalLM, LlamaTokenizer
# モデルとトークナイザーをロード
model = LlamaForCausalLM.from_pretrained("llama-3.2-1b")
tokenizer = LlamaTokenizer.from_pretrained("llama-3.2-1b")
# サンプル入力テキスト
input_text = "こんにちは、今日はどのようにお手伝いできますか?"
# トークナイズして出力を生成
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs)
# 出力をデコード
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
このスクリプトを実行して、モデルが動作していることを確認します。テキスト出力が生成されれば、Llama 3.2 1Bのインストールと設定は成功です。
モバイルデバイスでLlama 3.2 1Bを実行する
モバイルデバイスでLlama 3.2 1Bモデルを実行することは、リソースを大量に消費する性質のため、特有の課題があります。しかし、クラウドコンピューティングとモバイル最適化の進歩により、APIを介してこれらのモデルにアクセスしたり、デバイス上で軽量バージョンを直接実行したりすることが可能になりました。以下は、AndroidおよびiOSユーザー向けにカスタマイズされた詳細なガイドです。
Androidユーザー向け
Llama 3.2 1BをAndroidデバイスで直接実行することは、高い計算要件のために困難です。クラウドサービスを介してアクセスするためのステップバイステップのガイドは次のとおりです。
- APIクライアントをインストールする:
- Google Playストアから Postman や Insomnia などのAPIクライアントをダウンロードしてインストールします。これらのツールは、クラウドベースのAPIとの通信を容易にします。
- クラウドインスタンスにアクセスする:
- クラウドホストされたLlama 3.2 1BインスタンスのAPIエンドポイントを取得します。これには通常、Hugging FaceやMetaのAPI提供など、Llamaモデルを提供するサービスにサインアップする必要があります。
- リクエストを送信する:
- APIクライアントを使用してリクエストを送信します。以下は、Androidで
Retrofitを使用してAPIリクエストを行うコード例です。 - サーバーが入力を処理し、結果を返します。APIクライアントで直接確認できます。
- APIクライアントを使用してリクエストを送信します。以下は、Androidで
- ローカルオプションを検討する:
- モデルをローカルで実行したい場合は、モバイルデバイスに最適化された量子化バージョンのLlama 3.2を探してください。これにより、メモリ使用量を削減しつつパフォーマンスを維持できます。これらのモデルは、十分なRAM(通常少なくとも6GB)を備えたデバイスで実行できます。
iOSユーザー向け
iOSでLlama 3.2にアクセスするプロセスはAndroidと似ていますが、ローカル実行のための追加オプションがあります。
-
APIクライアントをインストールする:
- Postman などのAPIクライアントアプリ、またはAIモデルと対話するための専用アプリを使用します。
-
クラウドAPIにアクセスする:
- クラウドサーバーでホストされているLlama 3.2 1B APIに接続します。完全なモデルをiOSデバイスで直接実行することは、大規模なリソースがない限り一般的には現実的ではありません。
-
リクエストを処理する:
- APIクライアントにデータを入力し、サーバーから結果を受け取るためにリクエストを送信します。
import Foundation
func sendRequest() {
let url = URL(string: "https://api.novita.ai/your/api/endpoint")! // 実際のエンドポイントに置き換えてください
var request = URLRequest(url: url)
request.httpMethod = "POST"
request.setValue("Bearer YOUR_API_KEY", forHTTPHeaderField: "Authorization")
request.setValue("application/json", forHTTPHeaderField: "Content-Type")
let input = ["input": "Hello, how can I assist you today?"]
let jsonData = try? JSONSerialization.data(withJSONObject: input)
request.httpBody = jsonData
let task = URLSession.shared.dataTask(with: request) { data, response, error in
if let data = data, let response = response {
print("Response: \(response)")
// 必要に応じてデータを処理
}
}
task.resume()
}
- ローカルで実行する(該当する場合):
- 最近のアップデートにより、Private LLM などの最適化されたアプリケーションを使用して、特定のiOSデバイス(iPhone 12 Pro以降)でLlama 3.2をローカルに実行できます。このセットアップにより、すべての処理がデバイス上で行われ、データが外部サーバーに送信されないため、プライバシーが向上します。
主な考慮事項
- リソース要件: Llama 3.2モデルはかなりの計算リソースを必要とするため、最適化なしでは標準的なモバイルデバイスでの直接実行は現実的ではありません。
- プライバシーとセキュリティ: クラウドサービスを利用するとデータプライバシーに関する懸念が生じるため、可能な場合はローカルモデルを使用することをお勧めします。
- モデルバリアント: Llama 3.2ファミリーには、さまざまなサイズ(1Bおよび3Bパラメータ)と、モバイル展開向けに特別に設計された量子化バージョンがあり、パフォーマンスとリソース使用量の間のトレードオフを提供します。
Novita AIでLlama 3.2 1Bを簡単に実行する
Novita AIを介してLlama 3.2-1B APIにアクセスする方法
このガイドでは、Novita AIのプラットフォームを使用してLlama 3.2-1B APIに簡単にアクセスする方法を説明します。以下の簡単な手順に従って開始してください。
ステップ1: Novita AIにサインアップ
Novita AIウェブサイトにアクセスします。Sign Up ボタンをクリックしてアカウントを作成します。
ステップ2: Model APIセクションに移動
ログイン後、ダッシュボードの API セクションに移動します。利用可能なAPIの中から Llama 3.2-1B モデルを見つけます。
ステップ3: APIキーを取得
Llama 3.2-1Bモデルリンクをクリックします。APIキーを生成または表示するオプションがあります。このキーをコピーします。APIリクエストを行う際に必要になります。
ステップ4: APIをアプリケーションに統合
- LLM APIリファレンスを参照して、利用可能なAPIとモデルを確認します。
- 好みのプログラミング言語を使用してHTTPリクエストを作成します。
以下は、requestsライブラリを使用したPythonの簡単な例です。
import requests
url = "https://api.novita.ai/llama-3.2-1b"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"input": "Hello, how can I assist you today?"
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
YOUR_API_KEYを先ほどコピーしたAPIキーに置き換えてください。
ステップ5: 統合をテスト
スクリプトを実行して、Llama 3.2-1B APIと正しく通信できることを確認します。応答のエラーを確認し、必要に応じてリクエストを調整します。
Novita AIのAPIを使用する利点
- 複雑なセットアップ不要: APIはすぐに使用でき、インストールやローカルインフラストラクチャは不要です。
- スケーラビリティ: ハードウェアの制限なくアプリケーションを簡単にスケールアップできます。
- コスト効率: 使用した計算リソースに対してのみ支払います。
ローカルマシンまたはNovita AIのようなクラウドベースのサービスでLlama 3.2 1Bを実行して使用することは、これまでになく簡単です。このガイドで説明した手順に従うことで、さまざまな自然言語処理タスクにこの最先端モデルのパワーを活用できます。チャットボットの構築、データ分析の実行、または単にAIの探求など、Llama 3.2 1Bは手元にある優れたツールです。
よくある質問
- Llama 3.2 1Bを最新バージョンに更新するにはどうすればよいですか? 公式リポジトリの最新リリースを確認し、更新手順に従ってください。
- Llama 3.2 1Bのインストールを安全に保つためのベストプラクティスは何ですか? ソフトウェアを最新の状態に保ち、ファイアウォールとVPNを使用し、ネットワークアクセスを許可されたユーザーに制限してください。
- WindowsでLlama 3.2をローカルに実行するにはどうすればよいですか? Pythonと依存関係をインストールし、モデルをダウンロードして、スクリプトまたはコマンドラインインターフェースを使用して実行します。
Novita AIは、AIの野望を実現するためのオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — 必要なコスト効率の高いツールを提供します。インフラストラクチャを排除し、無料で始めて、AIのビジョンを現実にしましょう。
おすすめの記事
- [1. Llama 3.2のパワーを解き放つ: マルチモーダルユースケースとアプリケーション](http://Unlocking the Power of Llama 3.2: Multimodal Use Cases and Applications)
- [2. Llama 3.2へのアクセス方法: AI開発プロセスを効率化する](http://How to Access Llama 3.2: Streamlining Your AI Development Process)
- 3. Llama 3.2 VS Claude 3.5: あなたのプロジェクトに最適なAIモデルはどちらですか?



