

核心要点
- 本指南提供了全面的分步指南,帮助你下载并运行 Llama 3.2 1B,这是一个强大且易于访问的语言模型。
- 了解该模型的能力、系统要求以及逐步安装流程。
- 找到常见安装问题的解决方案,并探索在移动设备上运行 Llama 3.2 1B 的选项。
- 了解如何利用 NovitaAI 等平台来简化访问和实现。
- 本指南面向初学者,提供清晰简洁的路径,让你体验这一强大模型。
Llama 3.2 1B 是一个拥有 10 亿参数的轻量级语言模型,旨在提供强大的 NLP 能力,如文本生成、摘要和问答,同时最大程度降低计算要求。与 GPT-3 等更大模型相比,其较小的体积使其非常适合资源受限的环境,无需大量硬件即可提供高性能。
此外,Llama 3.2 1B 针对移动使用进行了优化,允许开发者通过基于云的 API 将其集成到移动应用中,使其在 Android 和 iOS 设备上均可访问。基准测试证实,Llama 3.2 1B 在准确性和效率方面具有竞争力,在性能和成本效益之间取得了良好平衡。本指南将介绍如何本地下载、安装并运行 Llama 3.2 1B,或通过 Novita AI 的简化 API 访问它,以便在移动平台上轻松部署。
理解 Llama 3.2 1B
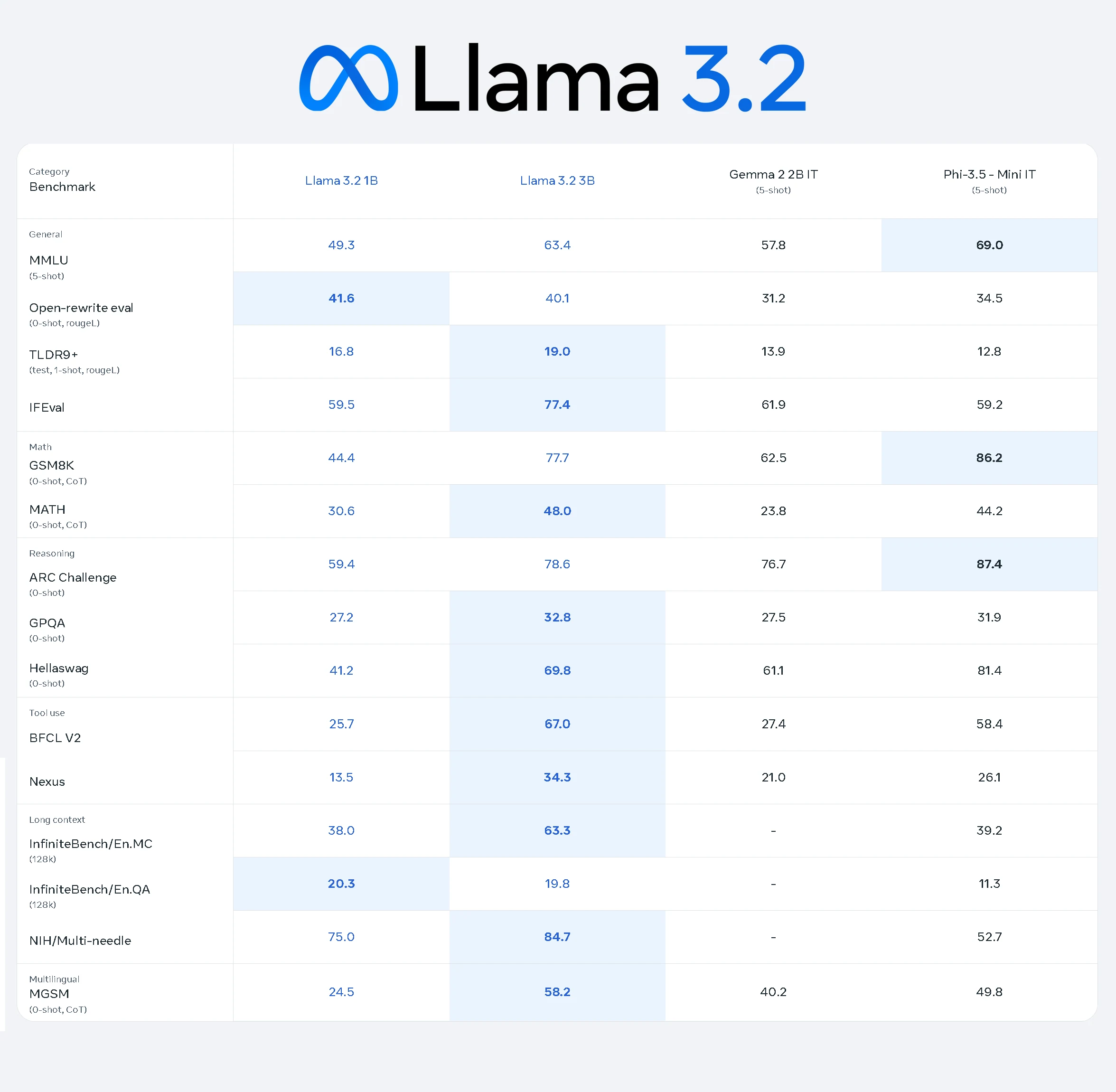
Llama 3.2 1B 模型在各种任务中表现出稳定的性能,展示了其作为轻量级但高效 AI 模型的能力:
- 通用任务:在 MMLU 上获得 49.3 分,表明在通用知识任务中表现中等。
- 数学任务:在 GSM8K 上获得 44.4 分,在 MATH 上获得 30.6 分,反映了基本的推理和算术能力。
- 推理:在 ARC Challenge 上表现良好,得分 59.4;在 Hellaswag 上得分 41.2,突显了其逻辑推理潜力。
- 工具使用:在 BFCL V2 上得分 25.7,显示有限但功能性的工具使用能力。
- 长上下文:在 InfiniteBench/En.MC 上获得 38.0 分,表明在处理扩展上下文任务方面表现尚可。
- 多语言任务:在 MGSM 上记录得分为 24.5,表明具有基础的多语言理解能力。
如何在计算机上安装 Llama 3.2 1B?
第一步:设置环境
在你运行 Llama 3.2 1B 之前,需要确保系统准备就绪。无论你使用的是 Windows、macOS 还是 Linux,请确保拥有适合 AI 工作负载的环境。Llama 3.2 1B 需要:
- 64 位操作系统:Windows、macOS 或 Linux。
- RAM:至少 8GB 才能顺利运行;16GB 或更高容量是运行更大模型的理想选择。
- 存储:确保至少有 20GB 的可用空间来容纳模型文件。
确保安装 Python 环境(版本 3.7 或更高),因为 Llama 3.2 1B 是用 Python 构建的。
第二步:安装所需依赖
Llama 3.2 1B 需要多个 Python 库才能高效运行。这些包括:
- TensorFlow 或 PyTorch(取决于你选择的框架)。
- Hugging Face 的 Transformers 库,用于模型加载和操作。
- NumPy,用于数值运算和数据处理。
要安装必要的依赖项,请打开命令行界面(CLI)并执行以下命令:
pip install torch transformers numpy
如果你使用 TensorFlow,请将 torch 替换为 tensorflow。
第三步:从官方源下载 Llama 3.2 1B
接下来,你需要下载模型文件。务必使用官方源以确保文件安全且是最新的。Llama 3.2 1B 可在 Hugging Face 或官方仓库等平台上获取。访问 Llama 3.2 1B 的相应页面,下载模型权重和配置文件。
或者,你也可以使用 GitHub 直接克隆仓库:
git clone https://github.com/llama3.2/llama-1b
第四步:运行安装向导
下载完所需文件后,运行 Llama 3.2 1B 仓库提供的安装向导。这将设置环境、安装额外依赖项,并确保一切就绪以运行模型。
python setup.py install
此步骤可能需要一些时间,具体取决于你的互联网速度和系统性能。
第五步:验证安装
安装完成后,验证一切是否正常运行至关重要。为此,请运行以下测试命令:
python -c "import llama; print(llama.__version__)"
如果模型安装正确,你应该会在终端中看到 Llama 3.2 1B 的版本号。如果出现任何错误,请再次检查安装说明和依赖项。
第六步:成功运行 Llama 3.2 1B
现在一切都已设置好,是时候运行模型了。创建一个简单的 Python 脚本来加载并运行 Llama 3.2 1B:
from transformers import LlamaForCausalLM, LlamaTokenizer
# 加载模型和分词器
model = LlamaForCausalLM.from_pretrained("llama-3.2-1b")
tokenizer = LlamaTokenizer.from_pretrained("llama-3.2-1b")
# 示例输入文本
input_text = "你好,今天我能为你做些什么?"
# 分词并生成输出
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs)
# 解码输出
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
运行此脚本以查看模型的实际效果。如果它产生了文本输出,说明你已成功安装并配置了 Llama 3.2 1B。
在移动设备上运行 Llama 3.2 1B
由于资源密集的特性,在移动设备上运行 Llama 3.2 1B 模型面临着独特的挑战。然而,云计算和移动优化的进步使得通过 API 访问这些模型或直接在设备上运行轻量级版本成为可能。以下是针对 Android 和 iOS 用户的详细指南。
针对 Android 用户
由于模型的高计算要求,直接在 Android 设备上运行 Llama 3.2 1B 可能很困难。以下是访问云服务的分步指南:
- 安装 API 客户端:
- 从 Google Play 商店下载并安装诸如 Postman 或 Insomnia 之类的 API 客户端。这些工具便于与基于云的 API 进行通信。
- 访问云实例:
- 获取托管在云端的 Llama 3.2 1B 实例的 API 端点。这通常涉及注册提供 Llama 模型的服务,例如 Hugging Face 或 Meta 的 API 产品。
- 发送请求:
- 使用 API 客户端发送请求。以下是在 Android 中使用
Retrofit进行 API 请求的代码示例: - 服务器处理你的输入并返回结果,你可以直接在 API 客户端中查看。
- 使用 API 客户端发送请求。以下是在 Android 中使用
- 考虑本地选项:
- 如果你更喜欢本地运行模型,请寻找为移动设备优化的 Llama 3.2 量化版本,它们可以在保持性能的同时减少内存使用。这些模型可以在具有足够 RAM(通常至少 6GB)的设备上运行。
针对 iOS 用户
在 iOS 上访问 Llama 3.2 的过程与 Android 类似,但包含了额外的本地执行选项:
- 安装 API 客户端:
- 使用诸如 Postman 之类的 API 客户端应用,或专为与 AI 模型交互设计的应用。
- 访问云 API:
- 连接到托管在云服务器上的 Llama 3.2 1B API,因为直接在 iOS 设备上运行完整模型通常不可行,除非拥有大量资源。
- 处理请求:
- 在 API 客户端中输入数据并发送请求,然后从服务器接收结果。
import Foundation
func sendRequest() {
let url = URL(string: "https://api.novita.ai/your/api/endpoint")! // 替换为你的端点
var request = URLRequest(url: url)
request.httpMethod = "POST"
request.setValue("Bearer YOUR_API_KEY", forHTTPHeaderField: "Authorization")
request.setValue("application/json", forHTTPHeaderField: "Content-Type")
let input = ["input": "你好,今天我能为你做些什么?"]
let jsonData = try? JSONSerialization.data(withJSONObject: input)
request.httpBody = jsonData
let task = URLSession.shared.dataTask(with: request) { data, response, error in
if let data = data, let response = response {
print("响应: \(response)")
// 根据需要处理数据
}
}
task.resume()
}
- 本地运行(如果适用):
- 最近的更新允许在某些 iOS 设备(iPhone 12 Pro 及更新机型)上使用优化的应用(如 Private LLM)本地运行 Llama 3.2。这种设置确保所有处理都在设备上进行,增强了隐私性,因为不会向外部服务器发送任何数据。
关键考量
- 资源需求:Llama 3.2 模型需要大量计算资源,在没有优化的情况下,直接在标准移动设备上执行是不切实际的。
- 隐私与安全:利用云服务会引发数据隐私问题;因此,建议尽可能使用本地模型。
- 模型变体:Llama 3.2 系列包括多种尺寸(10 亿和 30 亿参数)以及专门为移动部署设计的量化版本,在性能和资源使用之间提供了权衡。
在 Novita AI 上轻松运行 Llama 3.2 1B
如何通过 Novita AI 访问 Llama 3.2-1B API
本指南将帮助你使用 Novita AI 平台轻松访问 Llama 3.2-1B API。请按照以下简单步骤开始。
第一步:注册 Novita AI
访问 Novita AI 网站。点击 注册 按钮创建账户。
第二步:导航到模型 API 部分
登录后,转到仪表盘中的 API 部分。在可用 API 列表中查找 Llama 3.2-1B 模型。
第三步:获取你的 API 密钥
点击 Llama 3.2-1B 模型链接。你将找到生成或查看 API 密钥的选项。复制此密钥,因为你需要它来发送 API 请求。
第四步:将 API 集成到你的应用中
- 探索 LLM API 参考文档,了解可用 API 和模型。
- 使用你首选的编程语言发送 HTTP 请求。
以下是一个使用 Python 和 requests 库的简单示例:
import requests
url = "https://api.novita.ai/llama-3.2-1b"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"input": "你好,今天我能为你做些什么?"
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
- 将
YOUR_API_KEY替换为你之前复制的 API 密钥。
第五步:测试你的集成
运行你的脚本,确保它能正确与 Llama 3.2-1B API 通信。检查响应中是否有任何错误,并根据需要调整你的请求。
使用 Novita AI API 的优势
- 无需复杂设置:API 可以立即使用,无需安装或本地基础设施。
- 可扩展性:无需硬件限制,轻松扩展你的应用。
- 成本效益:仅为使用的计算资源付费。
在本地计算机上或通过 Novita AI 等云服务运行和使用 Llama 3.2 1B 比以往任何时候都更容易。通过遵循本指南中概述的步骤,你可以利用这一尖端模型执行各种自然语言处理任务。无论你是在构建聊天机器人、进行数据分析,还是仅仅探索 AI,Llama 3.2 1B 都是一个极好的工具。
常见问题解答:
- 如何将 Llama 3.2 1B 更新到最新版本? 查看官方仓库的最新版本,并按照更新说明操作。
- 保护 Llama 3.2 1B 安装的最佳实践是什么? 保持软件更新,使用防火墙和 VPN,并限制网络访问仅限授权用户。
- 如何在 Windows 上本地运行 Llama 3.2? 安装 Python 和依赖项,下载模型,然后使用脚本或命令行界面运行它。
Novita AI 是一站式云平台,助力你的 AI 雄心。集成 API、无服务器、GPU 实例——你所需的经济高效的工具。消除基础设施,免费入门,让你的 AI 愿景成为现实。
推荐阅读
- [1. 解锁 Llama 3.2 的能力:多模态用例与应用](http://Unlocking the Power of Llama 3.2: Multimodal Use Cases and Applications)
- [2. 如何访问 Llama 3.2:简化你的 AI 开发流程](http://How to Access Llama 3.2: Streamlining Your AI Development Process)
- 3. Llama 3.2 对比 Claude 3.5:哪种 AI 模型适合你的项目?



