

這篇文章對目前兩個最先進的開源大型語言模型——GLM 4.5 與 Qwen3 235B 2507 進行了全面且最新的比較。透過剖析它們的架構、推理能力、效率、基準測試結果、價格與可用性,本文將幫助您:
- 了解兩者在技術設計、效能與部署場景上的關鍵差異。
- 找出最適合您需求的模型——無論您重視長上下文處理、成本效益、推理深度,還是程式碼生成能力。
GLM 4.5 VS Qwen3 235B 2507:架構比較
| 功能 | Qwen3 235B A22B Instruct 2507 | GLM 4.5 |
|---|---|---|
| 模型大小 | 235B 總參數 22B 活躍參數 |
355B 總參數,32B 活躍參數 |
| 開源 | 是 | 是 |
| 架構 | MoE(混合專家) | MoE(混合專家) |
| 上下文長度 | 262,144 個 token | 128,000 個 token |
| 語言支援 | 多語言 | 中文與英文 |
| 多模態 | 文字到文字 | 文字到文字 |
| 推理模式 | 無「思考模式」(無內部鏈式思考或 thinking 區塊) |
支援「思考模式」與「非思考模式」 |
| 改進 | 指令微調以提升指令遵循能力 針對一般文字生成、推理、數學、科學、程式碼與工具使用最佳化 在開放式與主觀任務中提升與人類偏好的一致性 |
前所未有規模的 MuonClip 最佳化器 新穎的最佳化技術以確保擴展穩定性 混合推理:思考模式用於複雜推理與工具使用 非思考模式用於即時回答 |
參數數量(235B)對 Qwen-3 的效能有何影響?
龐大的 2350 億參數賦予 Qwen 3 龐大的知識庫以及高度細膩的理解能力。MoE 架構是讓這個規模得以實務應用的關鍵。每次只啟動約 220 億參數,使得該模型在推理成本上接近小得多的密集模型,卻能擁有與其大總參數規模相當的知識與推理能力。這在效能品質與運算效率之間取得了絕佳平衡,使其能夠處理複雜問題,而無需承受 235B 密集模型的高昂成本。
GLM 4.5 VS Qwen3 235B 2507:基準測試比較
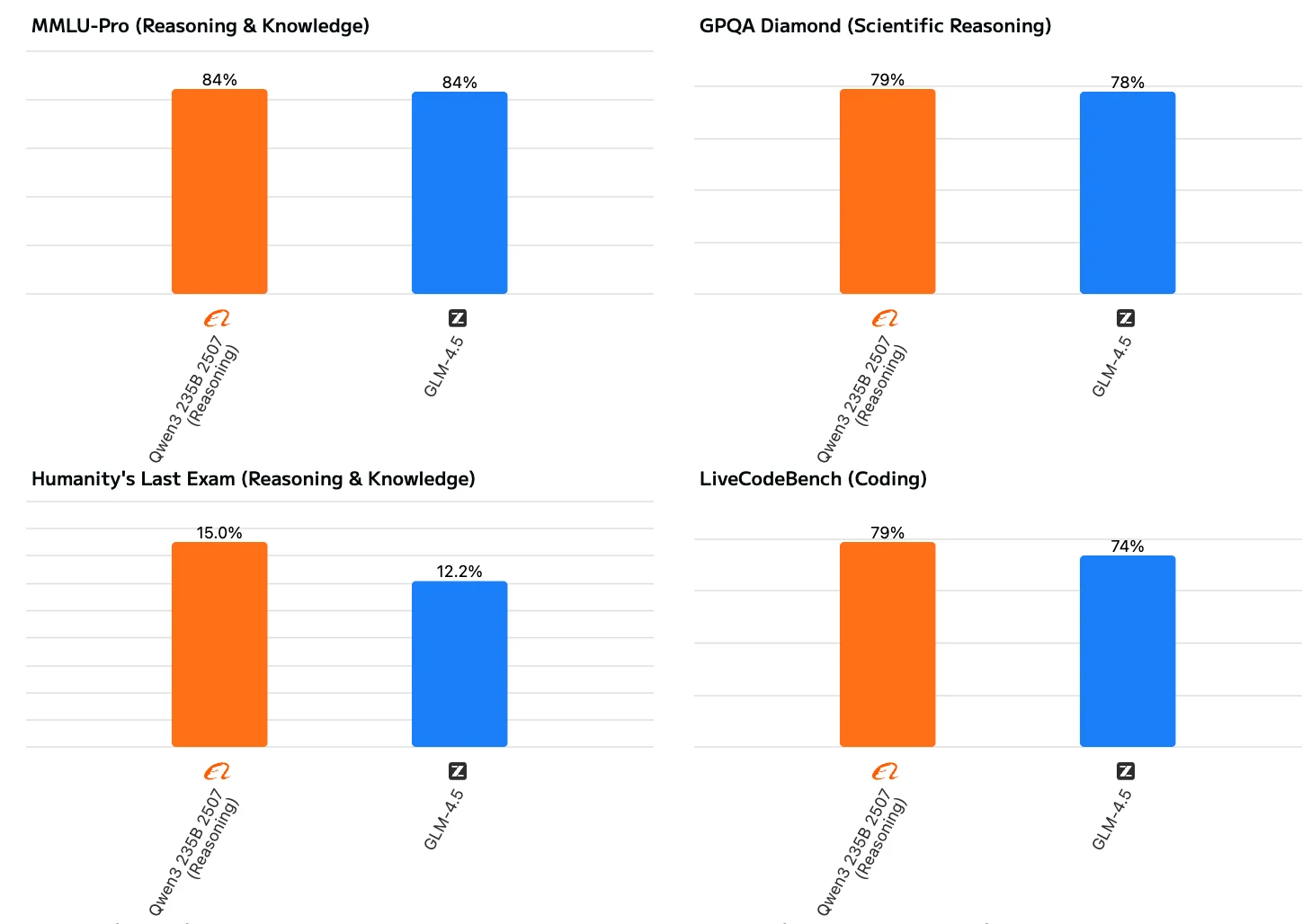
Qwen3 235B A22B Instruct 2507 展現出更均衡且全面的效能。它不僅在知識、推理、程式碼與數學等傳統領域表現優異,在長上下文理解與處理複雜任務方面也表現出強大的能力。儘管 GLM 4.5 整體表現不錯,但在數學、指令遵循與長上下文推理等更具挑戰性的任務上明顯落後於 Qwen3。
GLM 4.5 VS Qwen3 235B thinking 2507:能力比較
推理能力
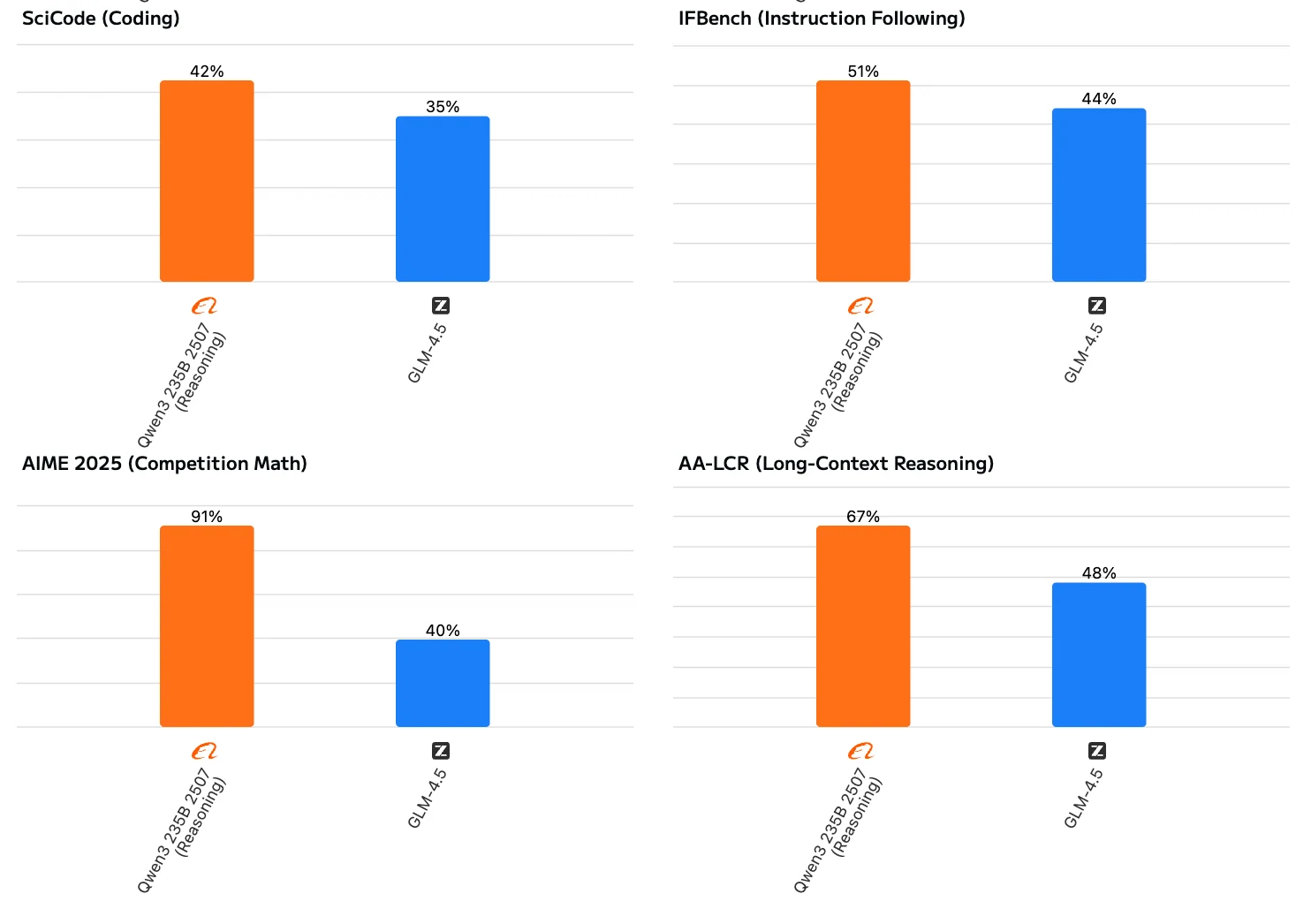
Qwen3 235B Thinking 2507 展現出略強於 GLM 4.5 的推理能力,從推理基準測試(71.0 vs 68.8)便可看出。這意味著 Qwen3 特別適合涉及複雜邏輯推理與問題解決的任務。然而,GLM 4.5 在智能體與程式碼任務上表現更均衡,使其成為更廣泛用例中更具多功能性的選擇。
泛化能力
-
GLM 4.5 的設計目標是在不犧牲任一領域效能的前提下整合多樣化能力,反映出對泛化能力的高度重視。它使用 15 兆個一般文本 token 加上 8 兆個專業資料 token 進行訓練,因此擁有廣泛且深入的知識庫。
-
Qwen3 235B Thinking 2507 也展現出強大的泛化能力,訓練資料涵蓋 119 種語言、共 36 兆個 token。然而,像是「Thinking」與「Coder」等專業化變體的開發,顯示出其針對特定任務進行最佳化的策略,有時可能會犧牲部分通用性。
GLM 4.5 vs Qwen 3 235B 2507:效率比較
速度比較
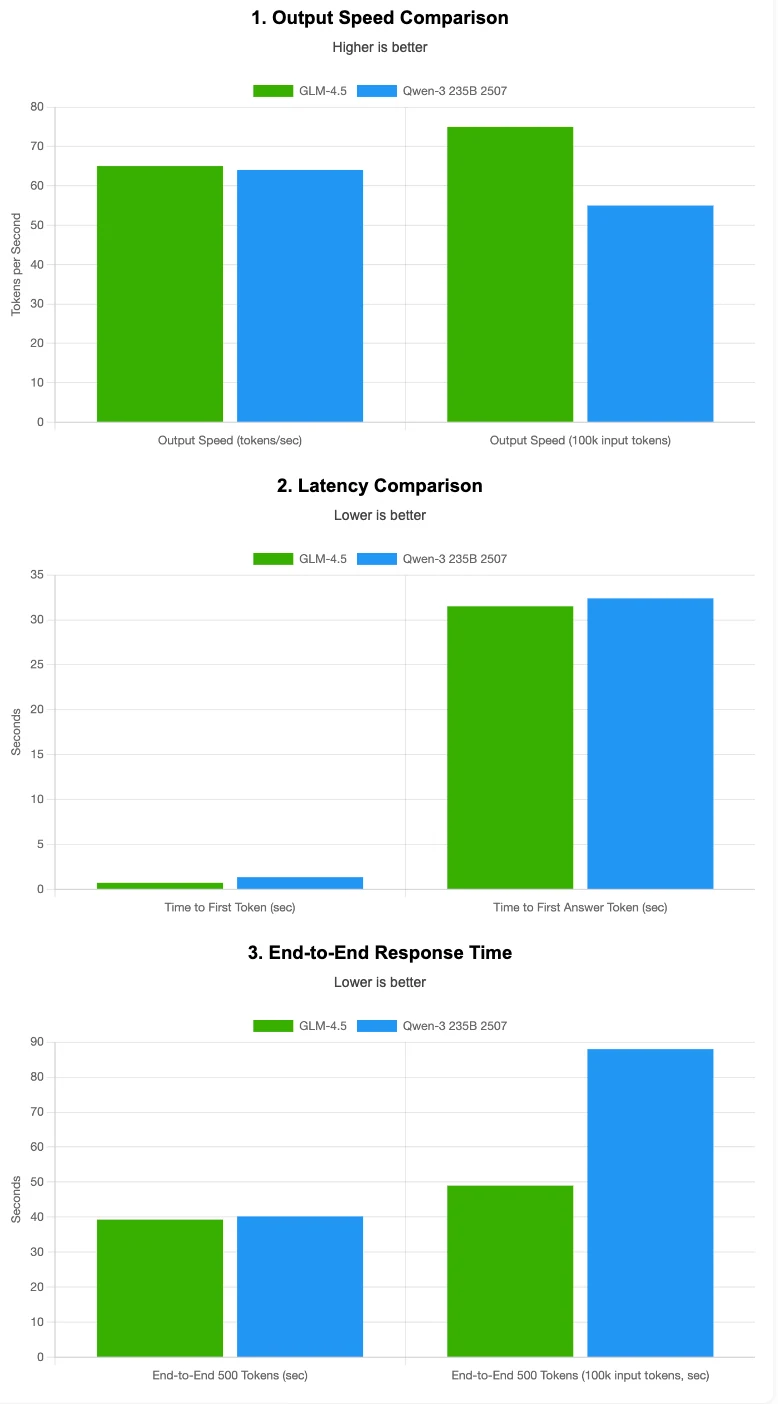
資料來源:Artificial Analysis
GLM 4.5 的輸出速度略快,延遲更低,尤其在處理長輸入上下文時更為明顯。Qwen 3 235B 2507 在短上下文時速度接近,但隨著輸入規模增加,速度下降更為顯著。
Novita AI 價格比較
| 模型 | 上下文長度 | 輸入價格(每百萬 token) | 輸出價格(每百萬 token) |
|---|---|---|---|
| Qwen3 235B A22B Thinking 2507 | 131,072 | $0.3 | $3.0 |
| GLM 4.5 | 131,072 | $0.6 | $2.2 |
GLM 4.5 提供更佳的效率,更適合處理大量輸出或長上下文視窗的任務,特別是當回應時間至關重要時。
Qwen3 235B A22B Thinking 2507 則提供較低的輸入成本,若您的工作負載偏重提示詞而非輸出,那麼這點會很有吸引力。
複雜推理任務的最佳 LLM:GLM 4.5 還是 Qwen 3 235B 2507
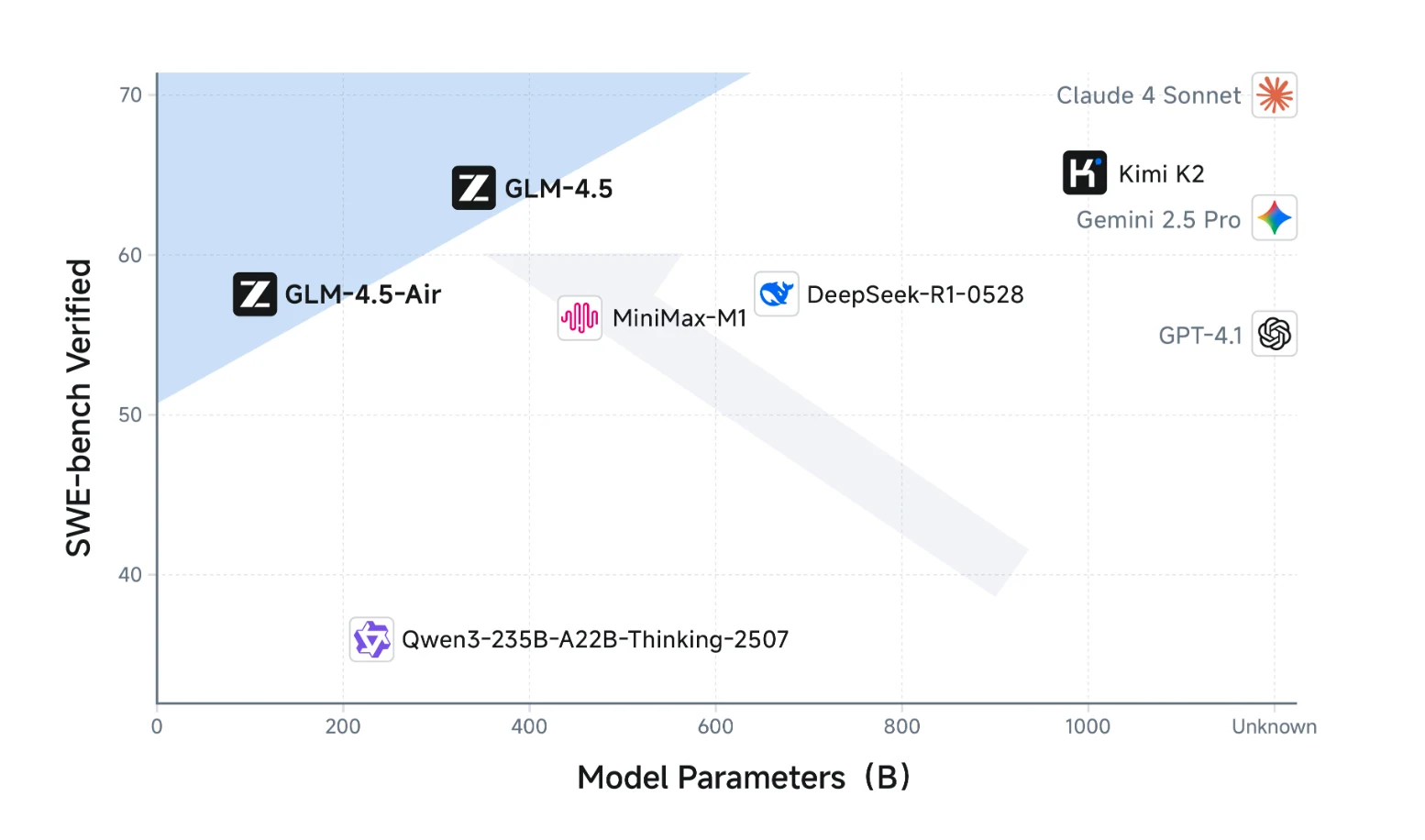
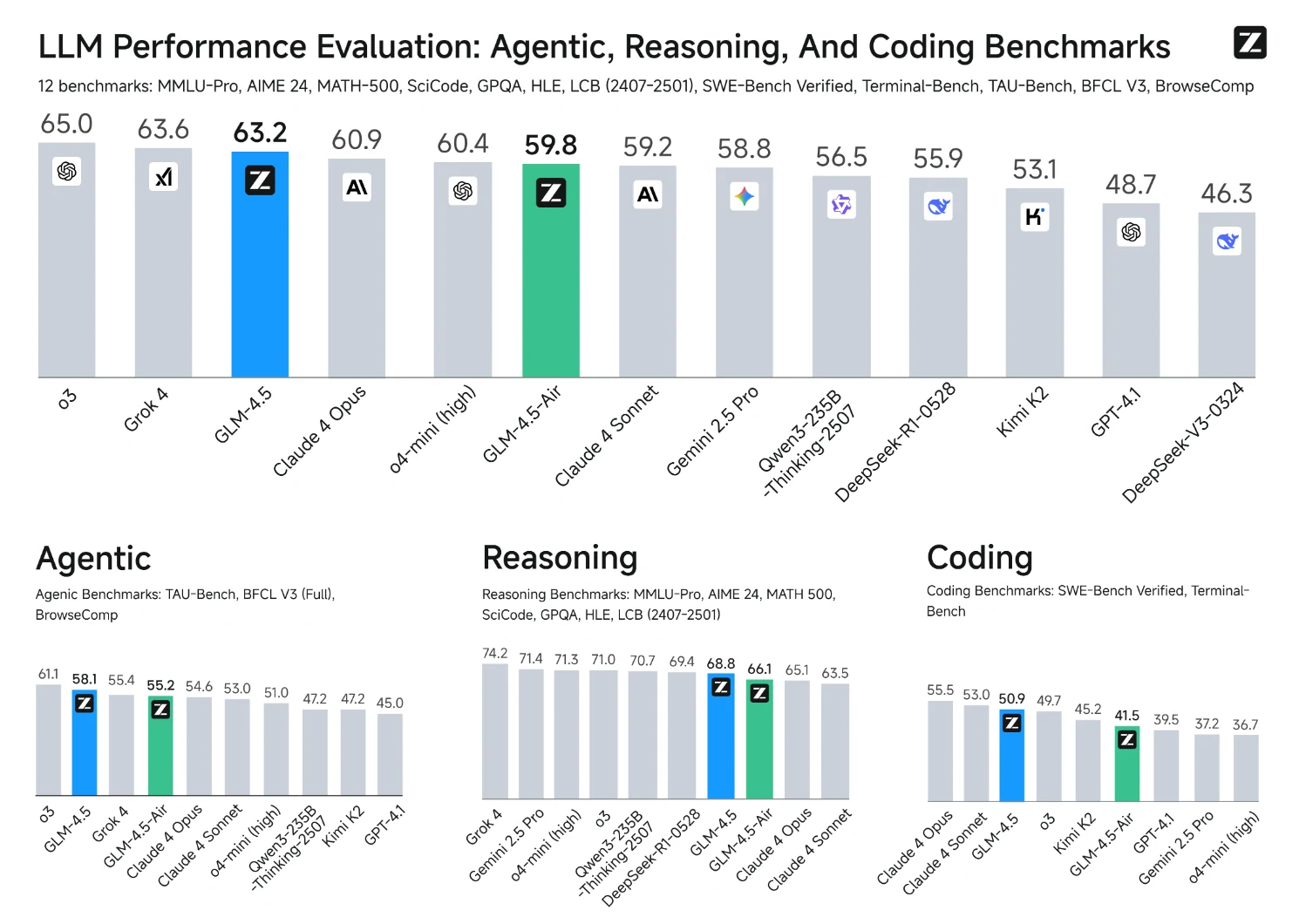
此圖表顯示 GLM-4.5 系列在複雜推理(SWE-bench Verified)上表現更優,勝過其他參數規模相近甚至更大的模型。
提示:製作一個 Flappy Bird 遊戲
| 維度 | Qwen 3 235B | GLM-4.5 |
|---|---|---|
| 易用性 | 貼上即用,依賴最少,非常適合快速原型與測試 | 結構良好,適合進一步擴展或團隊開發 |
| 遊戲真實性 | 高度忠於原作,核心機制簡單明瞭 | 高度忠實,特別注重視覺效果與互動細節 |
| 程式碼風格 | 現代前端風格,簡潔明瞭,適合獨立開發 | 教育/工程風格,模組化且清晰,適合團隊或教學 |
| 視覺效果 | 簡單實用,適合技術展示 | 精緻美觀,適合簡報與作品集 |
| 擴展性 | 強大,易於整合到更複雜的網頁專案中 | 強大,易於封裝以進行業務邏輯或功能擴展 |
| 使用者體驗 | 互動友善,實用性高 | 互動優化,UI/UX 更精緻 |
Qwen 3 235B 較適用於需要 簡潔、快速整合與精簡程式碼 的場景——非常適合原型設計與學習。GLM 4.5 更適用於需要 教學、可維護性與視覺美感 的場景——非常適合工程或課堂使用。
如何存取 GLM 4.5 或 Qwen 3 235B 2507?
第一步:登入並存取模型庫
登入您的帳戶,然後點選 「Model Library」 按鈕。

第二步:選擇您的模型
瀏覽可用選項,然後選擇符合您需求的模型。
第三步:開始免費試用
開始免費試用,探索所選模型的功能。
第四步:取得您的 API 金鑰
為了向 API 進行身分驗證,我們會提供一組新的 API 金鑰。進入「Settings」頁面,按照圖片指示複製 API 金鑰。

第五步:安裝 API
使用對應於您程式語言的套件管理器安裝 API。
安裝完成後,將必要的程式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,即可開始與 Novita AI LLM 互動。以下是 Python 使用者使用聊天補全 API 的範例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_UsudmdAIggvSInjIdO2HWaTCyXxTFOXDV8TH8UCPbA576Rs4AGqSA5ThNbelSDgdEGAWQcWXnAU2bHi5BueceA==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
第三方平台指南
使用 CLI 工具(如 Trae、Claude Code、Qwen Code)
如果您想在本地環境或 IDE 中使用 Novita AI 的頂級模型(如 Qwen3-Coder、Kimi K2、DeepSeek R1、GLM 4.5)來進行 AI 輔助編碼,流程很簡單:取得您的 API 金鑰、安裝工具、設定環境變數,然後開始編碼。
如需詳細的設定指令與範例,請查閱官方教學:
- Trae:在 IDE 中存取 AI 模型的逐步指南
- Claude Code:如何在 Windows、Mac 與 Linux 上的 Claude Code 中使用 Kimi-K2
- Qwen Code:如何在 Qwen Code 中使用 OpenAI 相容 API(60 秒設定!)
使用 OpenAI Agents SDK 建立多智能體工作流程
將 Novita AI 與 OpenAI Agents SDK 整合,打造進階的多智能體系統:
- 即插即用:在任何 OpenAI Agents 工作流程中使用 Novita AI 的 LLM。
- 支援交接、路由與工具使用:設計能夠委派、分類或執行函式的智能體,全部由 Novita AI 的模型驅動。
- Python 整合:將 SDK 端點設定為
https://api.novita.ai/v3/openai,並使用您的 API 金鑰。
在第三方平台上連接 API
- OpenAI 相容 API:無痛遷移並整合至如 Cline 與 Cursor 等專為 OpenAI API 標準設計的工具。
- Hugging Face:透過 Novita AI 端點在 Spaces、pipeline 或 Transformers 函式庫中使用模型。
- 智能體與編排框架:透過官方連接器與逐步整合指南,輕鬆將 Novita AI 與合作夥伴平台如 Continue、AnythingLLM、LangChain、Dify 及 Langflow 連接。
GLM-4.5 與 Qwen3 235B 2507 都代表了 LLM 技術的最新進展,但每個模型各有擅長的領域:
總結:
- 若您需要處理超大上下文視窗、多語言互動,以及專門的「思考」或「程式碼」變體,請選擇 Qwen3 235B 2507。
- 若您的應用情境特別注重效率、輸出成本、通用性以及進階的智能體或工程用途,請選擇 GLM-4.5。
常見問題
GLM-4.5 與 Qwen3 235B 2507 在架構上的主要差異是什麼?
兩者都採用混合專家(MoE)架構。Qwen3 235B 擁有 235B 個參數(每次推理啟動 22B 個),而 GLM-4.5 則有 355B 個參數(啟動 32B 個)。Qwen3 235B 提供更長的上下文視窗(262,144 對比 128,000 個 token)。
哪個模型更適合複雜推理任務?
相對於模型規模,GLM-4.5 在 SWE-bench Verified 的複雜推理上取得了更優異的結果;但 Qwen3 235B 2507 在一些推理基準測試上略佔優勢(例如 71.0 對比 68.8)。GLM-4.5 同時支援混合「思考」模式與即時模式,使其在智能體工作流程中更具彈性。
這些模型在程式碼生成與指令遵循方面表現如何?
兩個模型在程式碼生成與指令遵循方面都屬於頂尖水準。Qwen3 235B 2507 經過指令微調,提供全面的效能;而 GLM-4.5 則在工具使用、智能體編碼任務與均衡泛化方面提供強勁支援。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 以輕鬆部署 AI 模型,同時也提供價格實惠且可靠的 GPU 雲端服務,用於建置與擴展 AI 應用。



