

- GLM 4.5 contre Qwen3 235B 2507 : comparaison architecturale
- GLM 4.5 contre Qwen3 235B 2507 : comparaison des benchmarks
- GLM 4.5 contre Qwen3 235B thinking 2507 : comparaison des capacités
- GLM 4.5 contre Qwen 3 235B 2507 : comparaison d’efficacité
- Meilleur LLM pour les tâches de raisonnement complexes : GLM 4.5 ou Qwen 3 235B 2507
- Comment accéder à GLM 4.5 ou Qwen 3 235B 2507 ?
- Guide pour plateformes tierces
Cet article propose une comparaison exhaustive et à jour de GLM 4.5 et de Qwen3 235B 2507, deux des modèles de langage open source les plus avancés disponibles aujourd’hui. En détaillant leurs architectures, leurs capacités de raisonnement, leur efficacité, leurs résultats aux benchmarks, leur tarification et leur facilité d’utilisation, cet article vous aide à :
- Comprendre les différences clés entre les modèles en termes de conception technique, de performances et de scénarios de déploiement.
- Identifier le modèle qui correspond le mieux à vos besoins – que vous privilégiiez la gestion des longs contextes, la rentabilité, la profondeur de raisonnement ou les capacités de génération de code.
GLM 4.5 contre Qwen3 235B 2507 : comparaison architecturale
| Fonctionnalité | Qwen3 235B A22B Instruct 2507 | GLM 4.5 |
|---|---|---|
| Taille du modèle | 235B paramètres totaux 22B paramètres actifs |
355B paramètres totaux, 32B paramètres actifs |
| Open source | Oui | Oui |
| Architecture | MoE (Mixture of Experts) | MoE (Mixture of Experts) |
| Longueur de contexte | 262 144 tokens | 128 000 tokens |
| Langues supportées | Multilingue | Chinois et anglais |
| Multimodal | Texte vers texte | Texte vers texte |
| Modes de raisonnement | Pas de « mode de réflexion » (aucune chaîne de pensée interne ni blocs thinking) |
Prend en charge à la fois le « mode de réflexion » et le « mode sans réflexion » |
| Améliorations | Ajusté par instructions pour mieux suivre les consignes Optimisé pour la génération de texte général, le raisonnement, les maths, les sciences, le code et l’utilisation d’outils Meilleur alignement avec les préférences humaines dans les tâches ouvertes et subjectives |
Optimiseur MuonClip à une échelle sans précédent Nouvelles techniques d’optimisation pour la stabilité du passage à l’échelle Raisonnement hybride : mode réflexion pour les raisonnements complexes et l’utilisation d’outils Mode sans réflexion pour des réponses instantanées |
Quel est l’impact du nombre de paramètres (235B) sur les performances de Qwen-3 ?
L’énorme nombre de 235 milliards de paramètres confère à Qwen 3 une base de connaissances gigantesque et une grande capacité de compréhension nuancée. L’architecture MoE est la clé pour rendre cette échelle pratique. En n’activant qu’environ 22 milliards de paramètres à la fois, le modèle atteint les capacités de connaissance et de raisonnement associées à sa grande taille totale, tout en ayant un coût d’inférence proche de celui d’un modèle dense beaucoup plus petit. Cela offre un excellent équilibre entre qualité de performance et efficacité de calcul, permettant de s’attaquer à des problèmes complexes sans le coût prohibitif d’un modèle dense de 235B.
GLM 4.5 contre Qwen3 235B 2507 : comparaison des benchmarks
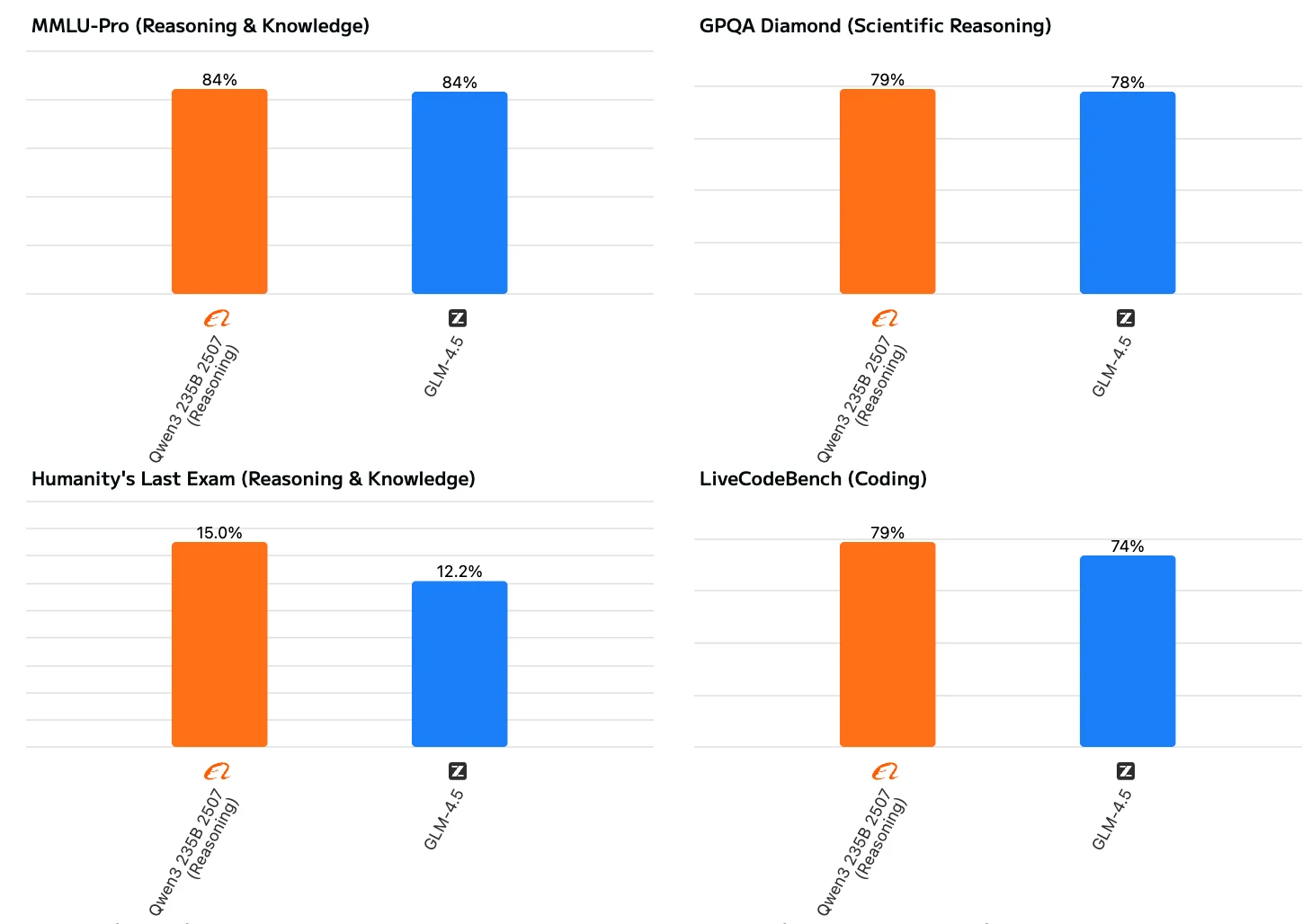
Qwen3 235B A22B Instruct 2507 montre des performances plus équilibrées et globales. Il excelle non seulement dans les domaines traditionnels comme la connaissance, le raisonnement, le codage et les mathématiques, mais il démontre également de solides capacités en matière de compréhension de longs contextes et de gestion de tâches complexes. Bien que GLM 4.5 obtienne de bons résultats dans l’ensemble, il est nettement moins performant que Qwen3 sur les tâches plus exigeantes comme les mathématiques, le suivi d’instructions et le raisonnement en contexte long.
GLM 4.5 contre Qwen3 235B thinking 2507 : comparaison des capacités
Capacités de raisonnement
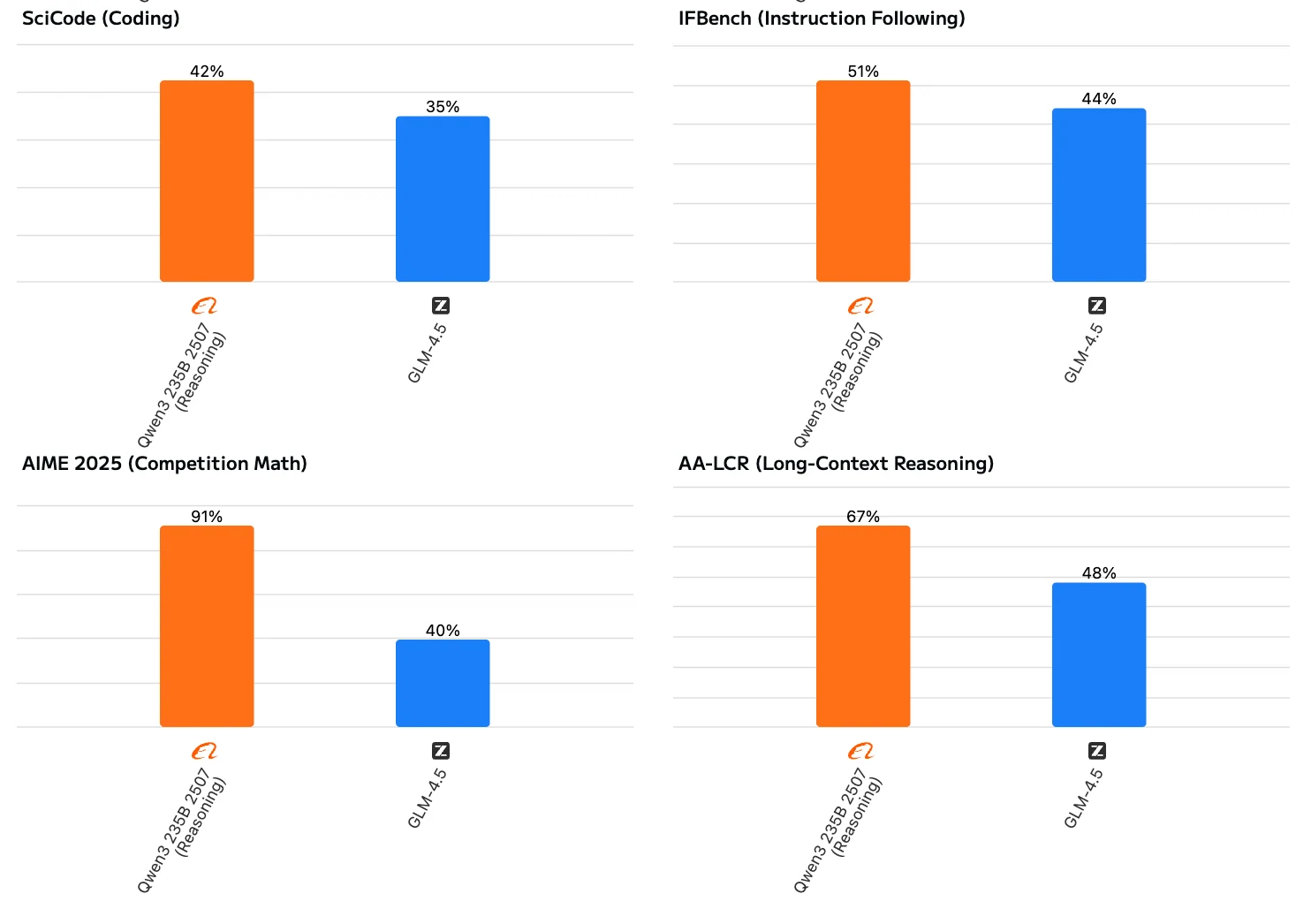
Qwen3 235B Thinking 2507 démontre des capacités de raisonnement légèrement supérieures à celles de GLM 4.5, comme le montrent les benchmarks de raisonnement (71,0 contre 68,8). Cela signifie que Qwen3 est particulièrement adapté aux tâches impliquant une inférence logique complexe et la résolution de problèmes. Cependant, GLM 4.5 offre des performances plus équilibrées dans les tâches agentiques et de codage, ce qui en fait un choix plus polyvalent pour des cas d’usage plus larges.
Généralisation
- GLM 4.5 a été conçu pour unifier diverses capacités sans sacrifier les performances dans un domaine particulier, ce qui reflète une forte emphase sur la généralisation. Il a été entraîné sur 15 billions de tokens de texte général plus 8 billions de tokens de données spécialisées, ce qui lui confère une base de connaissances large et profonde.
- Qwen3 235B Thinking 2507 démontre également une bonne généralisation, avec des données d’entraînement couvrant 36 billions de tokens dans 119 langues. Cependant, le développement de variantes spécialisées comme les modèles « Thinking » et « Coder » suggère une stratégie d’optimisation pour des tâches spécifiques, ce qui peut parfois compromettre une certaine généralité.
GLM 4.5 contre Qwen 3 235B 2507 : comparaison d’efficacité
Comparaison de vitesse
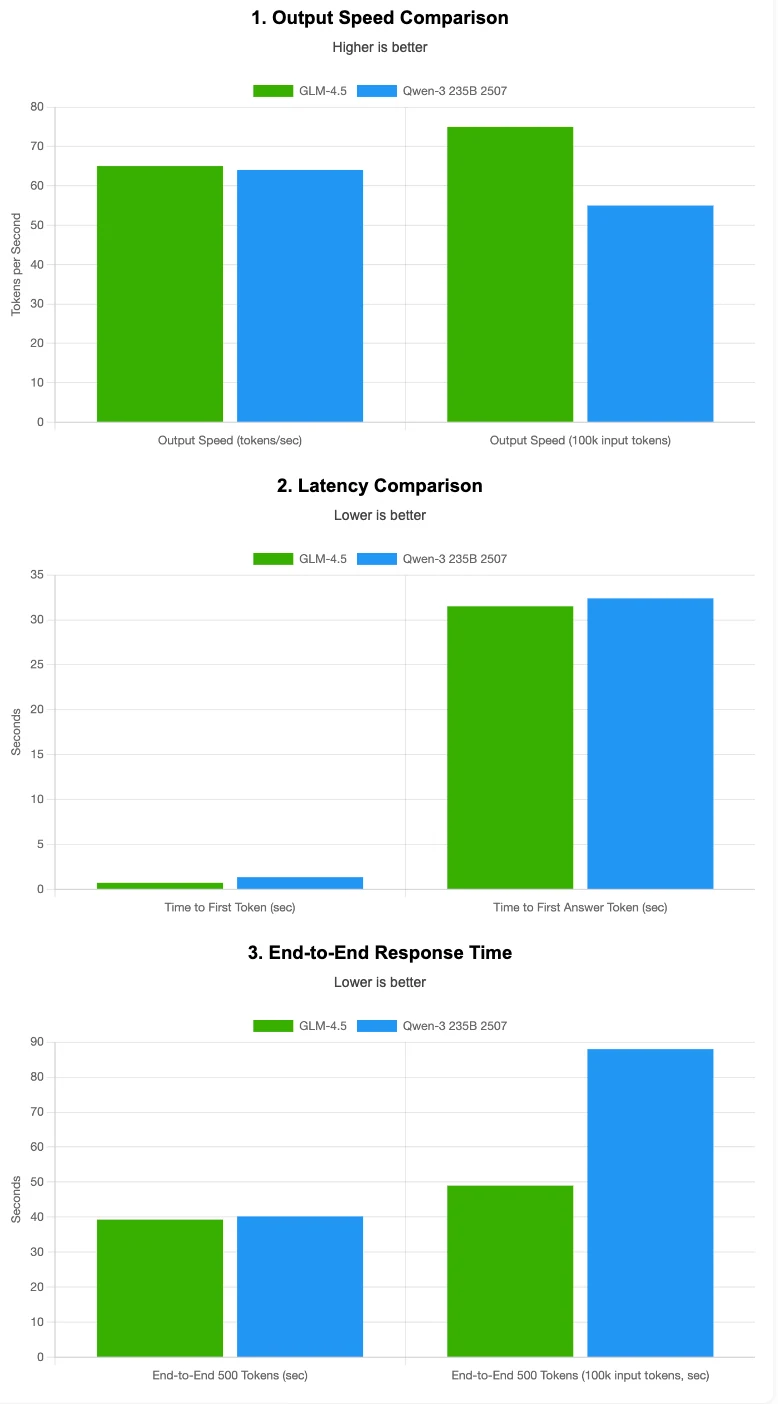
D’après Artificial Analysis
GLM 4.5 est légèrement plus rapide en vitesse de sortie et a une latence plus faible, surtout avec de longs contextes d’entrée. Qwen 3 235B 2507 est proche pour les contextes courts mais ralentit davantage lorsque la taille d’entrée augmente.
Comparaison des prix sur Novita AI
| Modèle | Longueur de contexte | Prix d’entrée (/M tokens) | Prix de sortie (/M tokens) |
|---|---|---|---|
| Qwen3 235B A22B Thinking 2507 | 131 072 | 0,3 $ | 3,0 $ |
| GLM 4.5 | 131 072 | 0,6 $ | 2,2 $ |
GLM 4.5 offre une meilleure efficacité et est plus adapté aux tâches nécessitant de grandes sorties ou de longues fenêtres de contexte, surtout lorsque le temps de réponse est critique.
Qwen3 235B A22B Thinking 2507 propose des coûts d’entrée plus faibles, ce qui peut être intéressant si votre charge de travail est davantage axée sur les prompts que sur les sorties.
Meilleur LLM pour les tâches de raisonnement complexes : GLM 4.5 ou Qwen 3 235B 2507
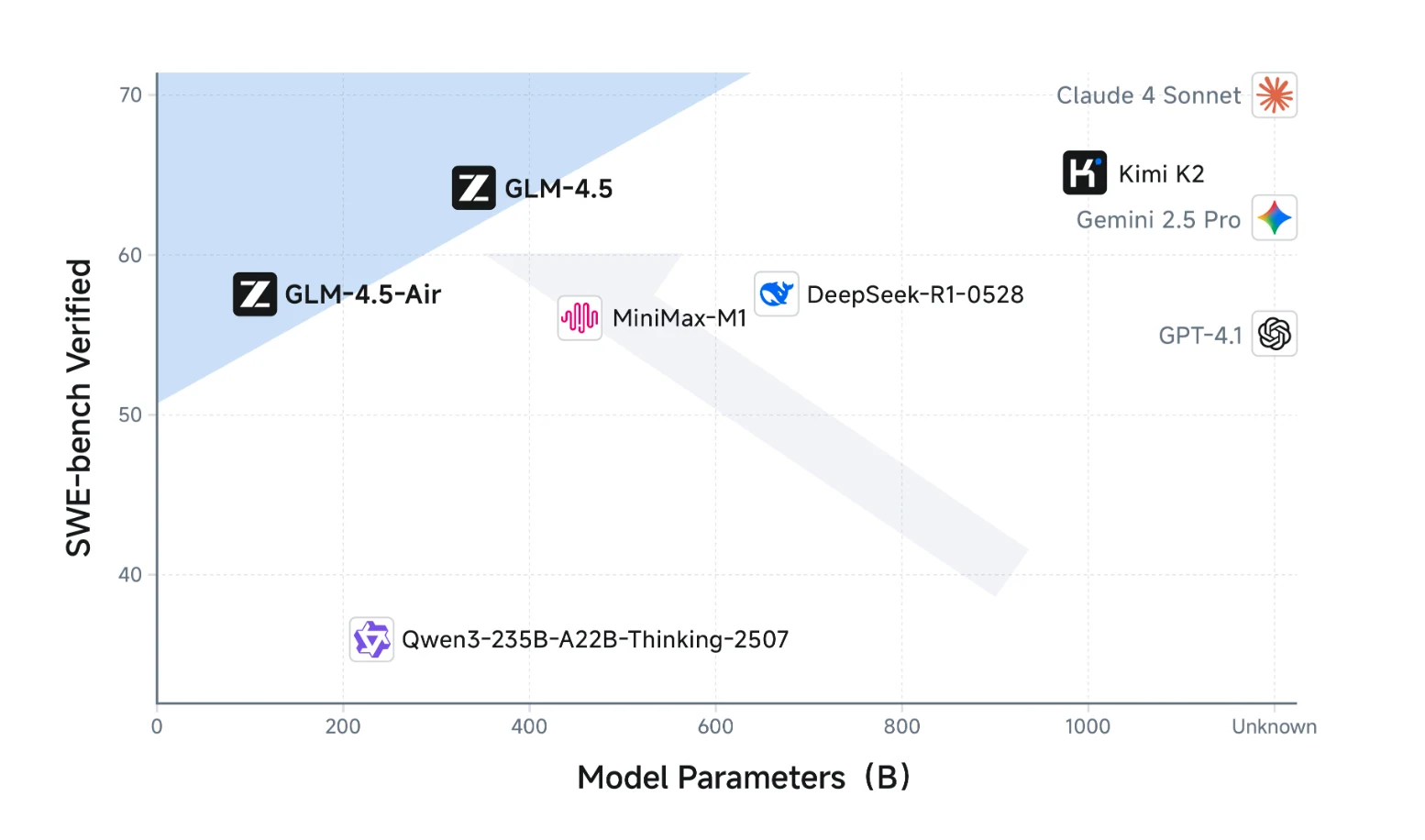
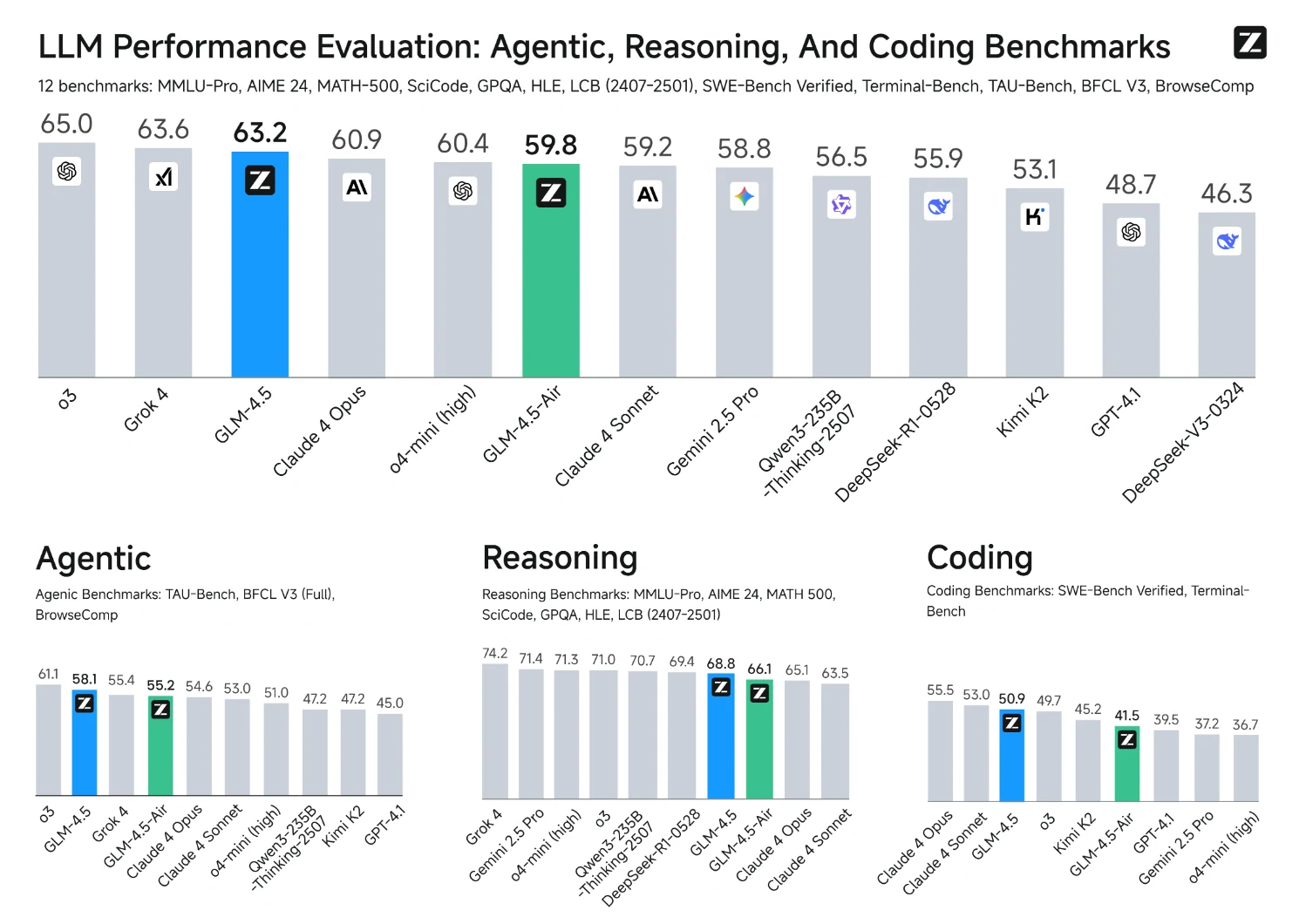
Ce graphique montre que la série GLM-4.5 atteint des performances supérieures sur le raisonnement complexe (SWE-bench Verified), surpassant d’autres modèles de taille similaire ou même beaucoup plus grande.
Prompt : Créer un jeu Flappy Bird
| Dimension | Qwen 3 235B | GLM-4.5 |
|---|---|---|
| Facilité d’utilisation | Copier-coller et jouer, dépendances minimales, idéal pour le prototypage et les tests rapides | Bien structuré, adapté à une extension ultérieure ou au développement en équipe |
| Fidélité au gameplay | Très fidèle à l’original, les mécanismes de base sont simples et clairs | Très fidèle, avec une attention particulière aux visuels et aux détails interactifs |
| Style de code | Style frontend moderne, concis et clair, excellent pour le développement individuel | Style éducatif/ingénierie, modulaire et clair, idéal pour les équipes/l’enseignement |
| Visuels | Simples et pratiques, bons pour les démos techniques | Soignés et raffinés, adaptés aux présentations et portfolios |
| Extensibilité | Forte, facile à intégrer dans des projets web plus complexes | Forte, facile à empaqueter pour la logique métier ou l’extension de fonctionnalités |
| Expérience utilisateur | Interaction conviviale, très utilisable | Interaction raffinée, UI/UX plus soigné |
Qwen 3 235B est meilleur pour les scénarios qui nécessitent minimalisme, intégration rapide et code concis — parfait pour le prototypage et l’apprentissage. GLM 4.5 est meilleur pour les scénarios qui exigent l’enseignement, la maintenabilité et l’esthétique visuelle — idéal pour une utilisation en ingénierie ou en classe.
Comment accéder à GLM 4.5 ou Qwen 3 235B 2507 ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Lancez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page « Settings », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_UsudmdAIggvSInjIdO2HWaTCyXxTFOXDV8TH8UCPbA576Rs4AGqSA5ThNbelSDgdEGAWQcWXnAU2bHi5BueceA==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Guide pour plateformes tierces
Utilisation en CLI (Trae, Claude Code, Qwen Code)
Si vous souhaitez utiliser les meilleurs modèles de Novita AI (comme Qwen3-Coder, Kimi K2, DeepSeek R1, GLM 4.5) pour l’assistance au codage IA dans votre environnement local ou IDE, le processus est simple : obtenez votre clé API, installez l’outil, configurez les variables d’environnement et commencez à coder.
Pour les commandes de configuration détaillées et des exemples, consultez les tutoriels officiels :
- Trae : Guide étape par étape pour accéder aux modèles IA dans votre IDE
- Claude Code : Comment utiliser Kimi-K2 dans Claude Code sur Windows, Mac et Linux
- Qwen Code : Comment utiliser l’API compatible OpenAI dans Qwen Code (configuration en 60s !)
Flux multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents avancés en intégrant Novita AI avec le SDK OpenAI Agents :
- Prêt à l’emploi : Utilisez les LLM de Novita AI dans n’importe quel flux de travail OpenAI Agents.
- Prend en charge les transferts, le routage et l’utilisation d’outils : Concevez des agents capables de déléguer, trier ou exécuter des fonctions, le tout alimenté par les modèles Novita AI.
- Intégration Python : Définissez simplement le point de terminaison du SDK sur
https://api.novita.ai/v3/openaiet utilisez votre clé API.
Connectez l’API sur des plateformes tierces
- API compatible OpenAI : Profitez d’une migration et d’une intégration sans effort avec des outils comme Cline et Cursor, conçus pour la norme API OpenAI.
- Hugging Face : Utilisez des modèles dans Spaces, pipelines, ou avec la bibliothèque Transformers via les points de terminaison Novita AI.
- Frameworks d’agents et d’orchestration : Connectez facilement Novita AI avec des plateformes partenaires comme Continue, AnythingLLM,LangChain, Dify et Langflow via des connecteurs officiels et des guides d’intégration pas à pas.
GLM-4.5 et Qwen3 235B 2507 représentent tous deux des avancées de pointe dans la technologie LLM, mais chaque modèle excelle dans des domaines différents :
En résumé :
- Choisissez Qwen3 235B 2507 pour les tâches nécessitant de vastes fenêtres de contexte, une interaction multilingue et des variantes spécialisées « Thinking » ou « Coder ».
- Choisissez GLM-4.5 pour les applications où l’efficacité, le coût de sortie, la polyvalence et les cas d’usage avancés d’agent ou d’ingénierie sont primordiaux.
Questions fréquentes
Quelles sont les principales différences architecturales entre GLM-4.5 et Qwen3 235B 2507 ?
Les deux utilisent l’architecture Mixture of Experts (MoE). Qwen3 235B a 235B paramètres (22B actifs par inférence), tandis que GLM-4.5 en a 355B (32B actifs). Qwen3 235B offre une fenêtre de contexte plus longue (262 144 contre 128 000 tokens).
Quel modèle est le meilleur pour les tâches de raisonnement complexes ?
GLM-4.5 obtient des résultats supérieurs sur SWE-bench Verified pour le raisonnement complexe par rapport à la taille du modèle, mais Qwen3 235B 2507 est légèrement en tête sur certains benchmarks de raisonnement (par exemple 71,0 contre 68,8). GLM-4.5 prend en charge à la fois les modes « pensée » hybride et instantané, ce qui lui confère plus de flexibilité dans les flux de travail agentiques.
Comment ces modèles se comportent-ils en matière de codage et de suivi d’instructions ?
Les deux modèles sont parmi les meilleurs pour la génération de code et le suivi d’instructions. Qwen3 235B 2507 est ajusté par instructions pour des performances complètes, tandis que GLM-4.5 offre un support robuste pour l’utilisation d’outils, les tâches de codage agentique et une généralisation équilibrée.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA à l’aide de notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



