

- GLM 4.5 vs Qwen3 235B 2507: Architekturvergleich
- GLM 4.5 vs Qwen3 235B 2507: Benchmark-Vergleich
- GLM 4.5 vs Qwen3 235B thinking 2507: Fähigkeitenvergleich
- GLM 4.5 vs Qwen 3 235B 2507: Effizienzvergleich
- Bestes LLM für komplexe Denkaufgaben: GLM 4.5 oder Qwen 3 235B 2507
- Wie greife ich auf GLM 4.5 oder Qwen 3 235B 2507 zu?
- Leitfaden für Drittanbieterplattformen
Dieser Artikel bietet einen umfassenden und aktuellen Vergleich von GLM 4.5 und Qwen3 235B 2507, zwei der fortschrittlichsten Open-Source-LLMs, die heute verfügbar sind. Durch die Analyse ihrer Architekturen, Denkfähigkeiten, Effizienz, Benchmark-Ergebnisse, Preise und Benutzerfreundlichkeit hilft dir der Artikel:
- Die wesentlichen Unterschiede zwischen den Modellen in technischem Design, Leistung und Einsatzszenarien zu verstehen.
- Das für deine Bedürfnisse am besten geeignete Modell zu identifizieren – ob du Wert auf lange Kontexte, Kosteneffizienz, tiefgehendes Denken oder Code-Generierung legst.
GLM 4.5 vs Qwen3 235B 2507: Architekturvergleich
| Merkmal | Qwen3 235B A22B Instruct 2507 | GLM 4.5 |
|---|---|---|
| Modellgröße | 235B Gesamtparameter 22B aktive Parameter |
355B Gesamtparameter, 32B aktive Parameter |
| Open Source | Ja | Ja |
| Architektur | MoE (Mixture of Experts) | MoE (Mixture of Experts) |
| Kontextlänge | 262.144 Token | 128.000 Token |
| Sprachunterstützung | Mehrsprachig | Chinesisch und Englisch |
| Multimodal | Text zu Text | Text zu Text |
| Denkmodi | Kein “Thinking Mode” (keine interne Chain-of-Thought oder thinking-Blöcke) |
Unterstützt sowohl “Thinking Mode” als auch “Non-Thinking Mode” |
| Verbesserung | Instruction-Tuning für bessere Befolgungsfähigkeit Optimiert für allgemeine Textgenerierung, Denken, Mathematik, Naturwissenschaften, Programmierung und Tool-Nutzung Verbesserte Ausrichtung an menschlichen Präferenzen bei offenen und subjektiven Aufgaben |
MuonClip-Optimierer in beispiellosem Maßstab Neuartige Optimierungstechniken für Skalierbarkeit Hybrides Denken: Thinking Mode für komplexe Überlegungen und Tool-Nutzung Non-Thinking Mode für sofortige Antworten |
Wie wirkt sich die Parameterzahl (235B) auf die Leistung von Qwen-3 aus?
Die enorme Anzahl von 235 Milliarden Parametern verleiht Qwen 3 eine riesige Wissensbasis und eine hohe Kapazität für nuanciertes Verständnis. Die MoE-Architektur ist der Schlüssel, um diesen Umfang praktikabel zu machen. Da jeweils nur etwa 22 Milliarden Parameter aktiviert werden, erreicht das Modell die Wissens- und Denkfähigkeiten, die mit seiner großen Gesamtgröße verbunden sind, während die Inferenzkosten denen eines viel kleineren dichten Modells ähneln. Dies bietet ein hervorragendes Gleichgewicht zwischen Leistungsqualität und Recheneffizienz und ermöglicht es, komplexe Probleme ohne die prohibitiven Kosten eines 235B dichten Modells zu bewältigen.
GLM 4.5 vs Qwen3 235B 2507: Benchmark-Vergleich
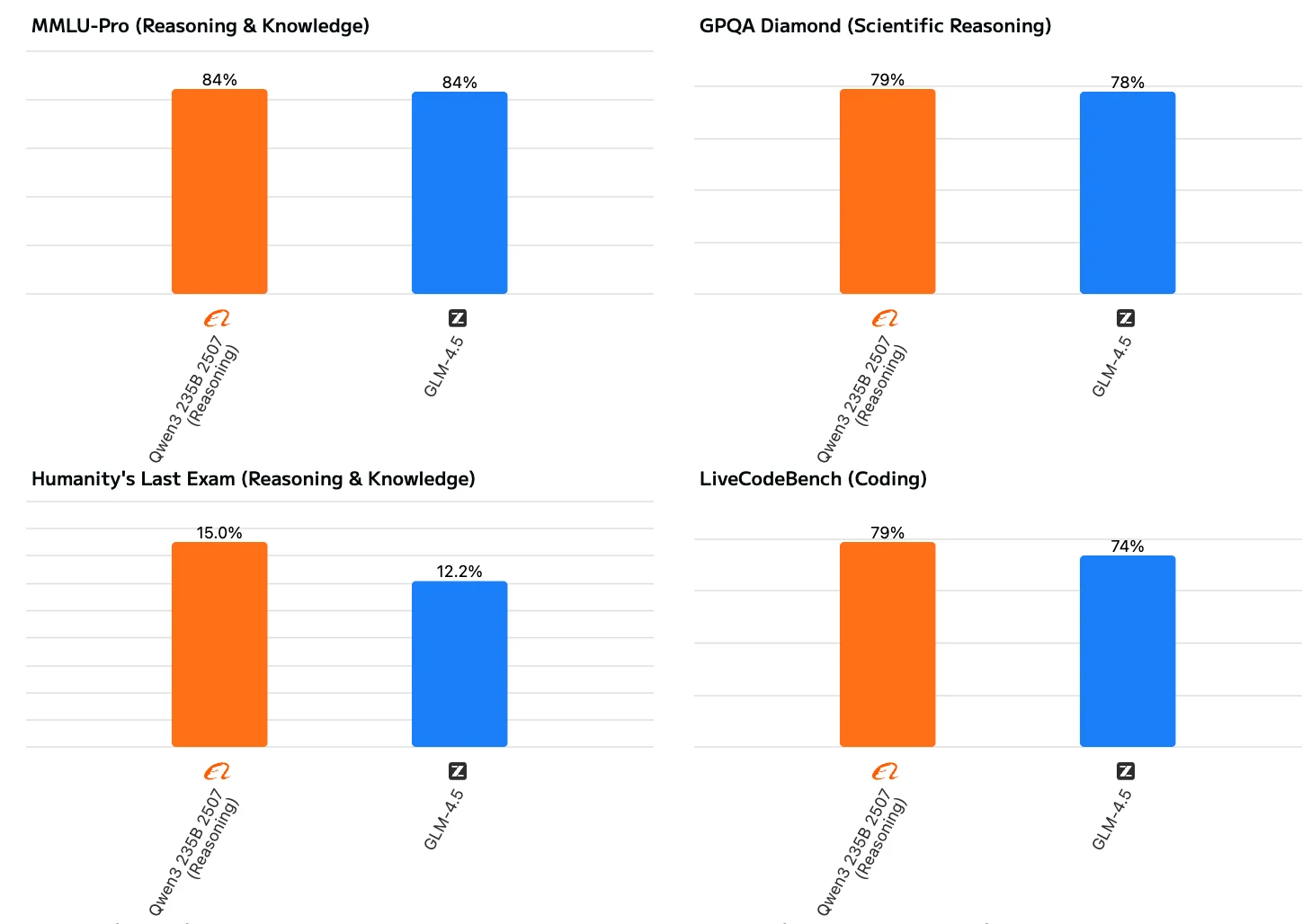
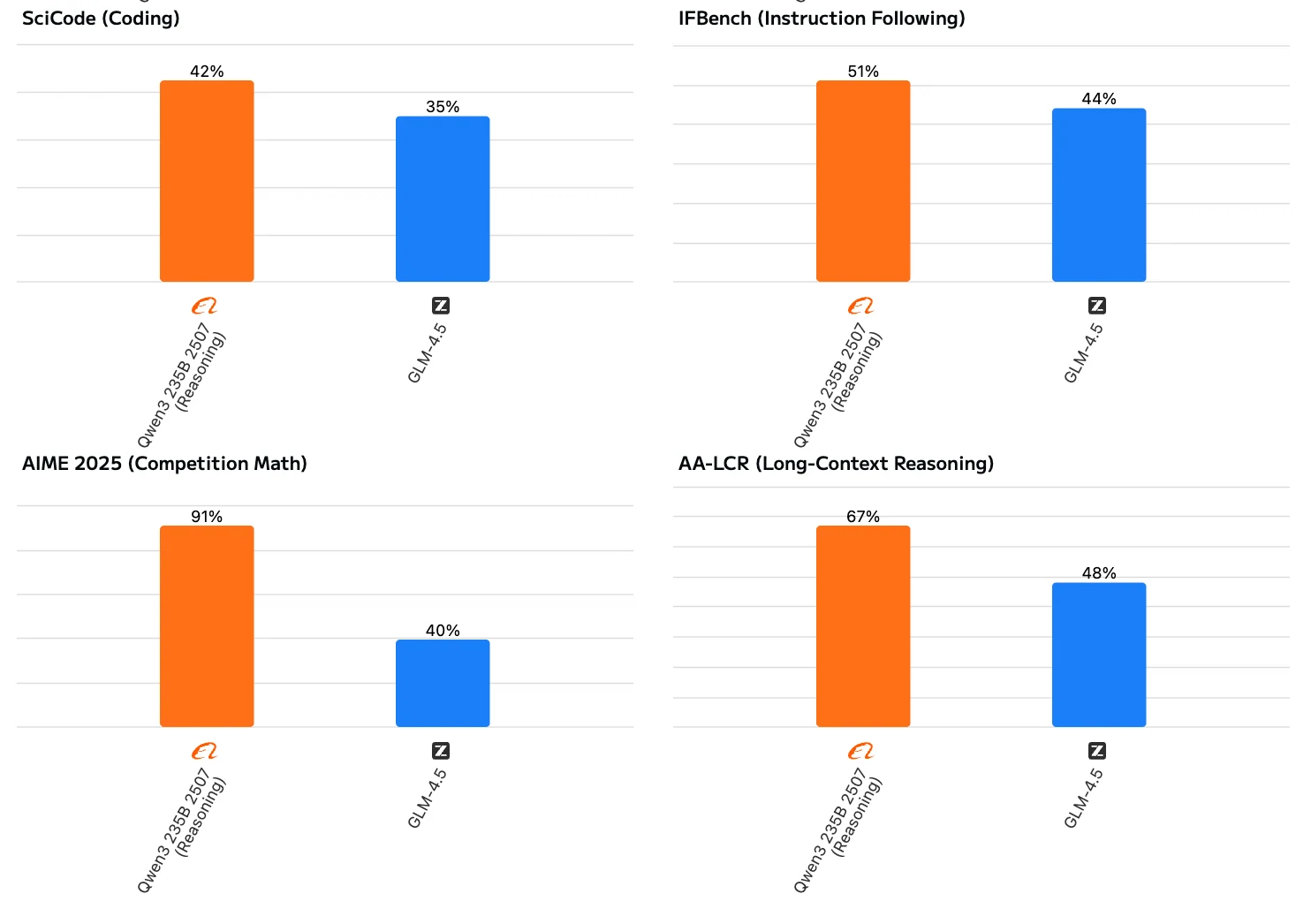
Qwen3 235B A22B Instruct 2507 zeigt eine ausgewogenere und umfassendere Leistung. Es glänzt nicht nur in traditionellen Bereichen wie Wissen, Denken, Programmierung und Mathematik, sondern zeigt auch starke Fähigkeiten im Verständnis langer Kontexte und bei der Bearbeitung komplexer Aufgaben. Obwohl GLM 4.5 insgesamt gut abschneidet, liegt es bei anspruchsvolleren Aufgaben wie Mathematik, Instruktionsbefolgung und langem Kontextdenken merklich hinter Qwen3 zurück.
GLM 4.5 vs Qwen3 235B thinking 2507: Fähigkeitenvergleich
Denkfähigkeiten
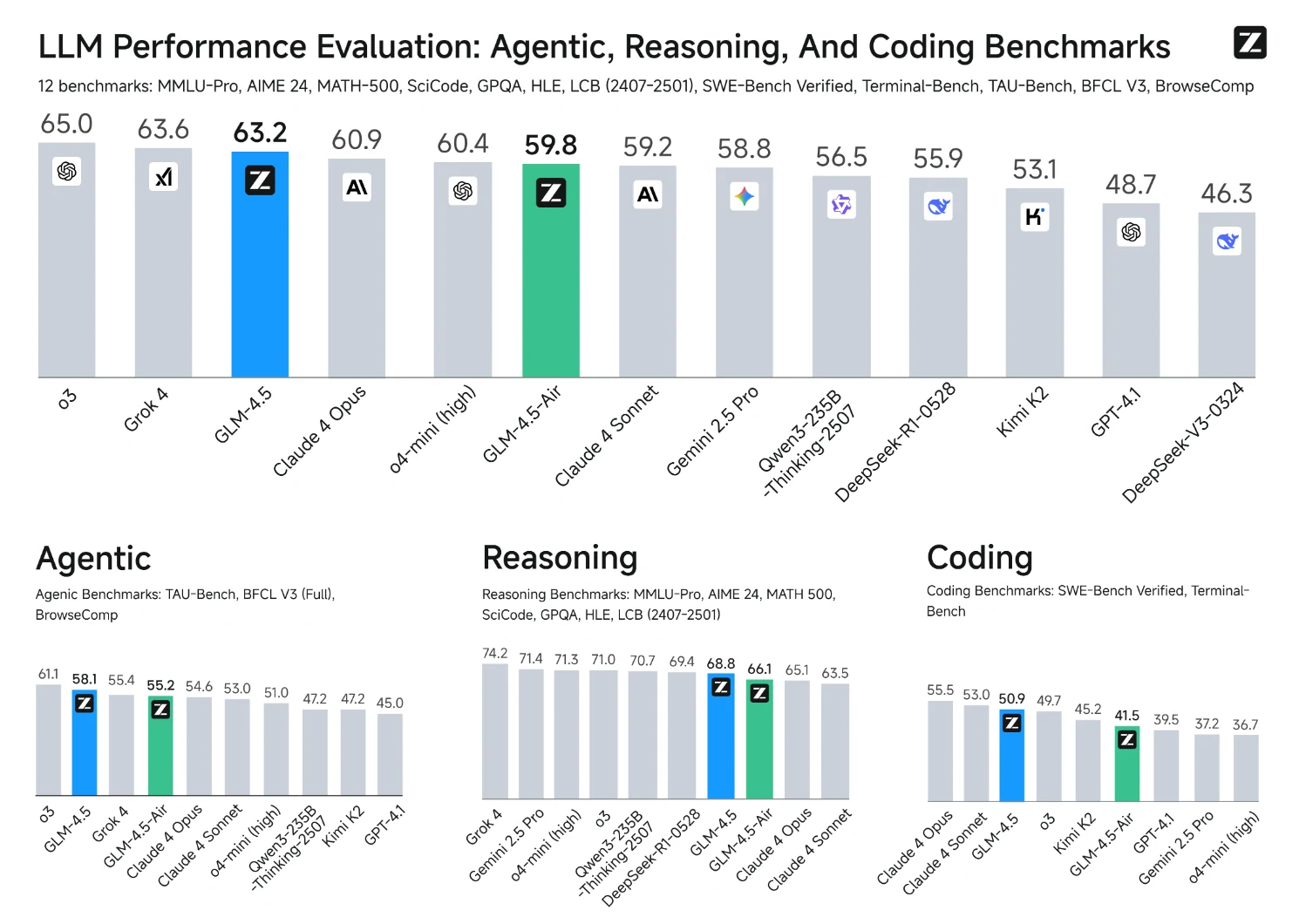
Qwen3 235B Thinking 2507 zeigt etwas stärkere Denkfähigkeiten als GLM 4.5, wie in den Denk-Benchmarks (71,0 vs. 68,8) zu sehen ist. Das bedeutet, dass Qwen3 besonders gut für Aufgaben geeignet ist, die komplexe logische Schlussfolgerungen und Problemlösungen erfordern. GLM 4.5 bietet jedoch eine ausgewogenere Leistung bei agentischen und Programmieraufgaben, was es zu einer vielseitigeren Wahl für breitere Anwendungsfälle macht.
Generalisierung
-
GLM 4.5 wurde entwickelt, um verschiedene Fähigkeiten zu vereinen, ohne bei einem einzelnen Bereich an Leistung einzubüßen – das spiegelt eine starke Betonung der Generalisierung wider. Es wurde mit 15 Billionen Token allgemeinem Text plus 8 Billionen Token spezialisierter Daten trainiert, was ihm eine breite und tiefe Wissensbasis verleiht.
-
Qwen3 235B Thinking 2507 zeigt ebenfalls eine starke Generalisierung, mit Trainingsdaten, die 36 Billionen Token in 119 Sprachen umfassen. Die Entwicklung spezialisierter Varianten wie “Thinking” und “Coder” deutet jedoch auf eine Strategie der Optimierung für bestimmte Aufgaben hin, die manchmal zu Lasten der Allgemeinheit gehen kann.
GLM 4.5 vs Qwen 3 235B 2507: Effizienzvergleich
Geschwindigkeitsvergleich
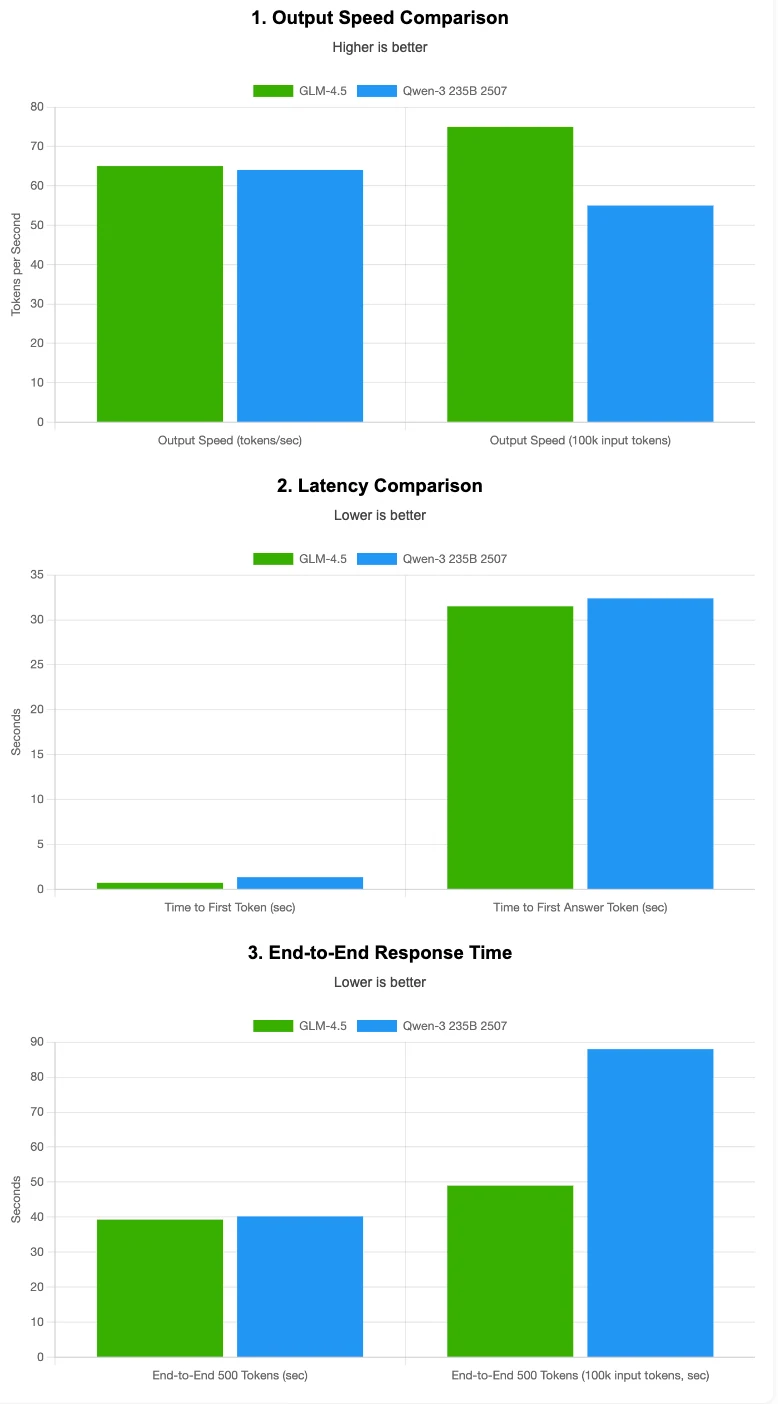
GLM 4.5 ist etwas schneller in der Ausgabegeschwindigkeit und hat eine geringere Latenz, insbesondere bei langen Eingabekontexten. Qwen 3 235B 2507 liegt bei kurzen Kontexten nahe, wird aber langsamer, je größer die Eingabe wird.
Preisvergleich auf Novita AI
| Modell | Kontextlänge | Eingabepreis (/M Token) | Ausgabepreis (/M Token) |
|---|---|---|---|
| Qwen3 235B A22B Thinking 2507 | 131.072 | $0,3 | $3,0 |
| GLM 4.5 | 131.072 | $0,6 | $2,2 |
GLM 4.5 bietet eine bessere Effizienz und ist besser geeignet für Aufgaben mit großen Ausgaben oder langen Kontextfenstern, insbesondere wenn die Antwortzeit kritisch ist.
Qwen3 235B A22B Thinking 2507 bietet niedrigere Eingabekosten, was attraktiv sein kann, wenn dein Arbeitspensum eher promptlastig als ausgabelastig ist.
Bestes LLM für komplexe Denkaufgaben: GLM 4.5 oder Qwen 3 235B 2507
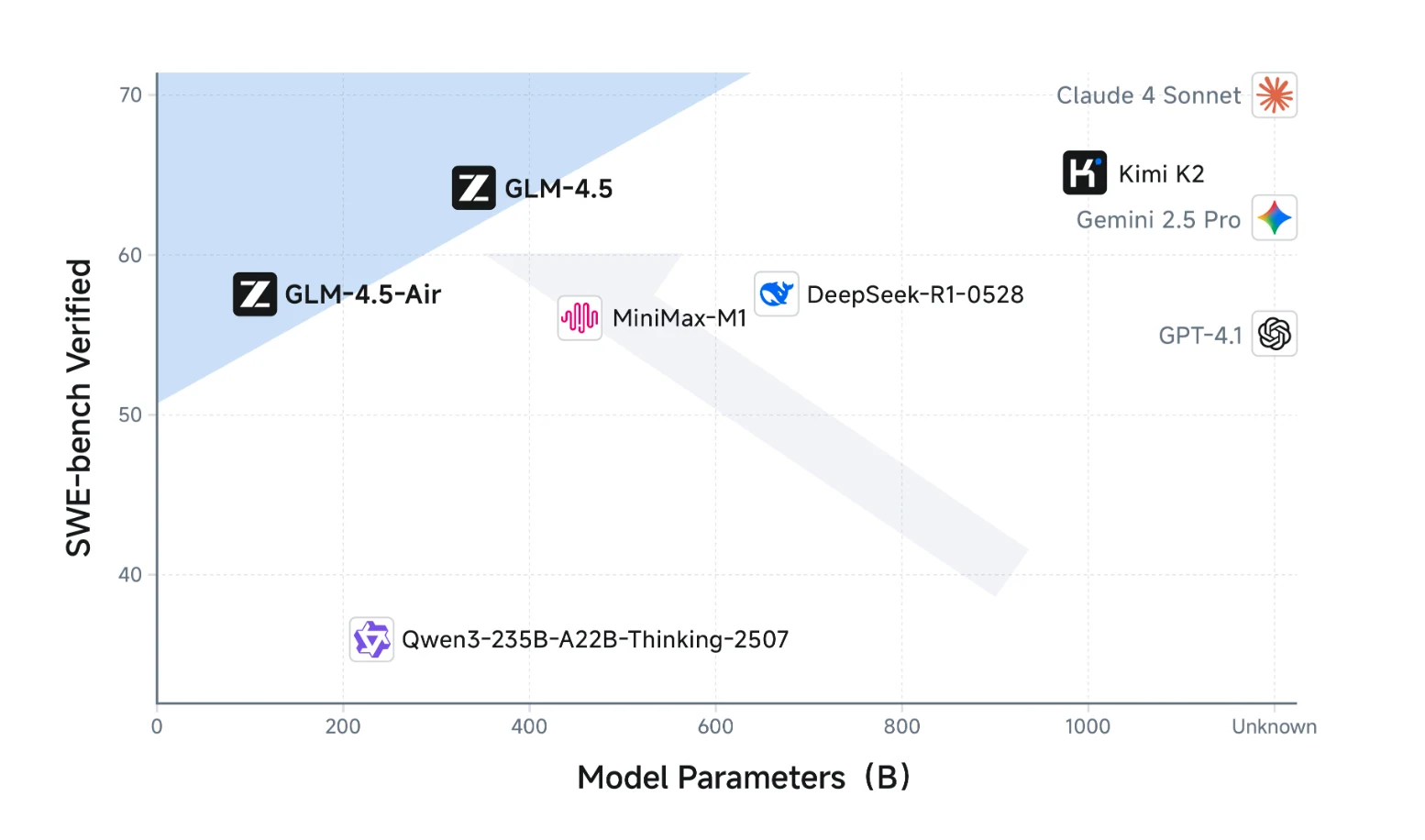
Diese Grafik zeigt, dass die GLM-4.5-Serie bei komplexem Denken (SWE-bench Verified) überlegene Leistungen erzielt und andere Modelle mit ähnlicher oder sogar deutlich größerer Parameterzahl übertrifft.
Prompt: Erstelle ein Flappy Bird Spiel
| Dimension | Qwen 3 235B | GLM-4.5 |
|---|---|---|
| Benutzerfreundlichkeit | Kopieren & einfügen, minimale Abhängigkeiten, ideal für schnelles Prototyping und Testen | Gut strukturiert, geeignet für weitere Erweiterungen oder Teamarbeit |
| Spieltreue | Sehr originalgetreu, Kernmechaniken sind einfach und klar | Sehr originalgetreu, besonderes Augenmerk auf visuelle und interaktive Details |
| Codestil | Moderner Frontend-Stil, prägnant und klar, großartig für Einzelentwicklung | Pädagogischer/technischer Stil, modular und klar, ideal für Teams/Lehre |
| Grafik | Einfach und praktisch, gut für technische Demos | Detailverliebt und poliert, geeignet für Präsentationen und Portfolios |
| Erweiterbarkeit | Stark, einfach in komplexere Webprojekte integrierbar | Stark, leicht für Geschäftslogik oder Funktionserweiterungen paketierbar |
| Benutzererfahrung | Benutzerfreundliche Interaktion, hohe Nutzbarkeit | Verfeinerte Interaktion, ausgefeiltere UI/UX |
Qwen 3 235B eignet sich besser für Szenarien, die Minimalismus, schnelle Integration und prägnanten Code erfordern – perfekt für Prototyping und Lernen. GLM 4.5 eignet sich besser für Szenarien, die Lehre, Wartbarkeit und visuelle Ästhetik verlangen – ideal für technische oder pädagogische Anwendungen.
Wie greife ich auf GLM 4.5 oder Qwen 3 235B 2507 zu?
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Melde dich in deinem Konto an und klicke auf die Schaltfläche Model Library.

Schritt 2: Wähle dein Modell
Durchstöbere die verfügbaren Optionen und wähle das Modell, das deinen Anforderungen entspricht.
Schritt 3: Starte deine kostenlose Testversion
Beginne deine kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: API-Schlüssel abrufen
Zur Authentifizierung mit der API erhältst du einen neuen API-Schlüssel. Rufe die Seite “Settings” auf und kopiere den API-Schlüssel, wie im Bild gezeigt.

Schritt 5: API installieren
Installiere die API mit dem Paketmanager deiner Programmiersprache.
Nach der Installation importiere die erforderlichen Bibliotheken in deine Entwicklungsumgebung. Initialisiere die API mit deinem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_UsudmdAIggvSInjIdO2HWaTCyXxTFOXDV8TH8UCPbA576Rs4AGqSA5ThNbelSDgdEGAWQcWXnAU2bHi5BueceA==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Leitfaden für Drittanbieterplattformen
Verwendung der CLI (z. B. Trae, Claude Code, Qwen Code)
Wenn du die Top-Modelle von Novita AI (wie Qwen3-Coder, Kimi K2, DeepSeek R1, GLM 4.5) für KI-gestützte Programmierhilfe in deiner lokalen Umgebung oder IDE nutzen möchtest, ist der Vorgang einfach: API-Schlüssel abrufen, das Tool installieren, Umgebungsvariablen konfigurieren und mit dem Programmieren beginnen.
Ausführliche Einrichtungsbefehle und Beispiele findest du in den offiziellen Tutorials:
- Trae : Schritt-für-Schritt-Anleitung für den Zugriff auf KI-Modelle in deiner IDE
- Claude Code:So verwendest du Kimi-K2 in Claude Code unter Windows, Mac und Linux
- Qwen Code:So verwendest du die OpenAI-kompatible API in Qwen Code (60 Sekunden Einrichtung!)
Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstelle fortschrittliche Multi-Agent-Systeme durch die Integration von Novita AI mit dem OpenAI Agents SDK:
- Plug-and-Play: Verwende die LLMs von Novita AI in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwerfe Agenten, die delegieren, priorisieren oder Funktionen ausführen können – alle betrieben von Novita AI-Modellen.
- Python-Integration: Setze einfach den SDK-Endpunkt auf
https://api.novita.ai/v3/openaiund verwende deinen API-Schlüssel.
API auf Drittanbieterplattformen verbinden
- OpenAI-kompatible API: Genieße eine problemlose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI-API-Standard entwickelt wurden.
- Hugging Face: Verwende Modelle in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
- Agent- und Orchestrierungs-Frameworks: Verbinde Novita AI ganz einfach mit Partnerplattformen wie Continue, AnythingLLM,LangChain, Dify und Langflow über offizielle Konnektoren und Schritt-für-Schritt-Integrationsleitfäden.
GLM-4.5 und Qwen3 235B 2507 repräsentieren beide den neuesten Stand der LLM-Technologie, aber jedes Modell zeichnet sich in unterschiedlichen Bereichen aus:
Zusammenfassung:
- Wähle Qwen3 235B 2507 für Aufgaben, die große Kontextfenster, mehrsprachige Interaktion und spezialisierte “Thinking”- oder “Coder”-Varianten erfordern.
- Wähle GLM-4.5 für Anwendungen, bei denen Effizienz, Ausgabekosten, Vielseitigkeit und fortschrittliche agentische oder technische Anwendungsfälle von größter Bedeutung sind.
Häufig gestellte Fragen
Was sind die wichtigsten architektonischen Unterschiede zwischen GLM-4.5 und Qwen3 235B 2507?
Beide verwenden Mixture-of-Experts (MoE)-Architekturen. Qwen3 235B hat 235B Parameter (22B aktiv pro Inferenz), während GLM-4.5 355B (32B aktiv) hat. Qwen3 235B bietet ein längeres Kontextfenster (262.144 vs. 128.000 Token).
Welches Modell eignet sich besser für komplexe Denkaufgaben?
GLM-4.5 erzielt bei SWE-bench Verified für komplexes Denken im Verhältnis zur Modellgröße überlegene Ergebnisse, aber Qwen3 235B 2507 liegt bei einigen Denk-Benchmarks leicht vorn (z. B. 71,0 vs. 68,8). GLM-4.5 unterstützt sowohl hybride “Thinking”- als auch sofortige Modi, was ihm mehr Flexibilität in agentischen Workflows verleiht.
Wie schneiden diese Modelle bei Programmierung und Instruktionsbefolgung ab?
Beide Modelle gehören zu den besten bei Codegenerierung und Instruktionsbefolgung. Qwen3 235B 2507 ist durch Instruction-Tuning für umfassende Leistung optimiert, während GLM-4.5 robuste Unterstützung für Tool-Nutzung, agentische Programmieraufgaben und ausgewogene Generalisierung bietet.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über eine einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.



