

关键要点
我们研究了最新基准测试,评估了输入和输出 token 成本,分析了延迟和吞吐量,并针对您的需求给出了最佳模型选择建议。从分析中我们了解到:
常识理解: Llama 3.3 70b 在 MMLU 得分上表现更优。
编码: Llama 3.3 70b 在 HumanEval 得分上表现更优。
数学问题: Llama 3.3 70b 在 MATH 得分上表现更优。
多语言支持: Llama 3.3 70b 支持更多语言,表现更优。
价格与速度: Llama 3.1 70b 对 API 和硬件的要求更低。
如果您想在自己的使用场景中评估 Llama 3.3 70b 或 Llama 3.1 70b,Novita AI 可提供免费试用。
由 Meta 开发的 Llama 3.3 70b 和 Llama 3.1 70b 是存在显著差异的大型语言模型。我们来比较它们的性能、资源效率、应用场景以及如何选择和使用它们。
模型系列基础介绍
在开始对比之前,我们先了解每个模型的基本特征。
Llama 3.1 模型系列特点
- 发布日期:2024 年初
- 模型规模:
- 主要特性:
- 上下文窗口扩展至 128k token。
- 多语言能力增强
- 资源效率高
Llama 3.3 模型系列特点
- 发布日期:2024 年中
- 模型规模:
- 主要创新:
- 优化的 Transformer 架构
- 使用监督微调(SFT)和基于人类反馈的强化学习(RLHF)进行训练
- 训练中整合了 15 万亿 token 的公开数据
- 建议采用分组查询注意力(GMA)来提升推理可扩展性
- 支持八种核心语言,注重质量而非数量
性能对比
我们已经了解了每个模型的基本特征,现在深入研究它们在各项基准测试中的表现。此对比将有助于说明它们在不同领域的优势。
| 基准测试 | 含义 | Llama 3.1 70b | Llama 3.3 70b |
|---|---|---|---|
| MMLU(5-shot) | MMLU(大规模多任务语言理解)评估跨多种任务的通用语言理解能力。 | 66.4 | 68.9 |
| HumanEval | HumanEval 测试模型根据给定问题描述编写正确 Python 代码的能力。 | 80.5 | 88.4 |
| MATH | MATH 评估模型的数学问题解决能力。 | 68 | 77.0 |
| MBPP | MBPP(现代生物学问题解决)衡量 AI 在生物科学领域解决问题的能力。 | 86 | 87.6 |
从表中可以看出,Llama 3.3 70b 在各方面均表现出明显优势。
如果您想了解更多关于 llama3.3 基准测试的知识,可以查阅以下文章:Llama 3.3 基准测试:关键优势与应用见解。
资源效率
评估大型语言模型(LLM)的效率时,必须考虑三个关键类别:模型自身的处理能力、API 性能和硬件要求。
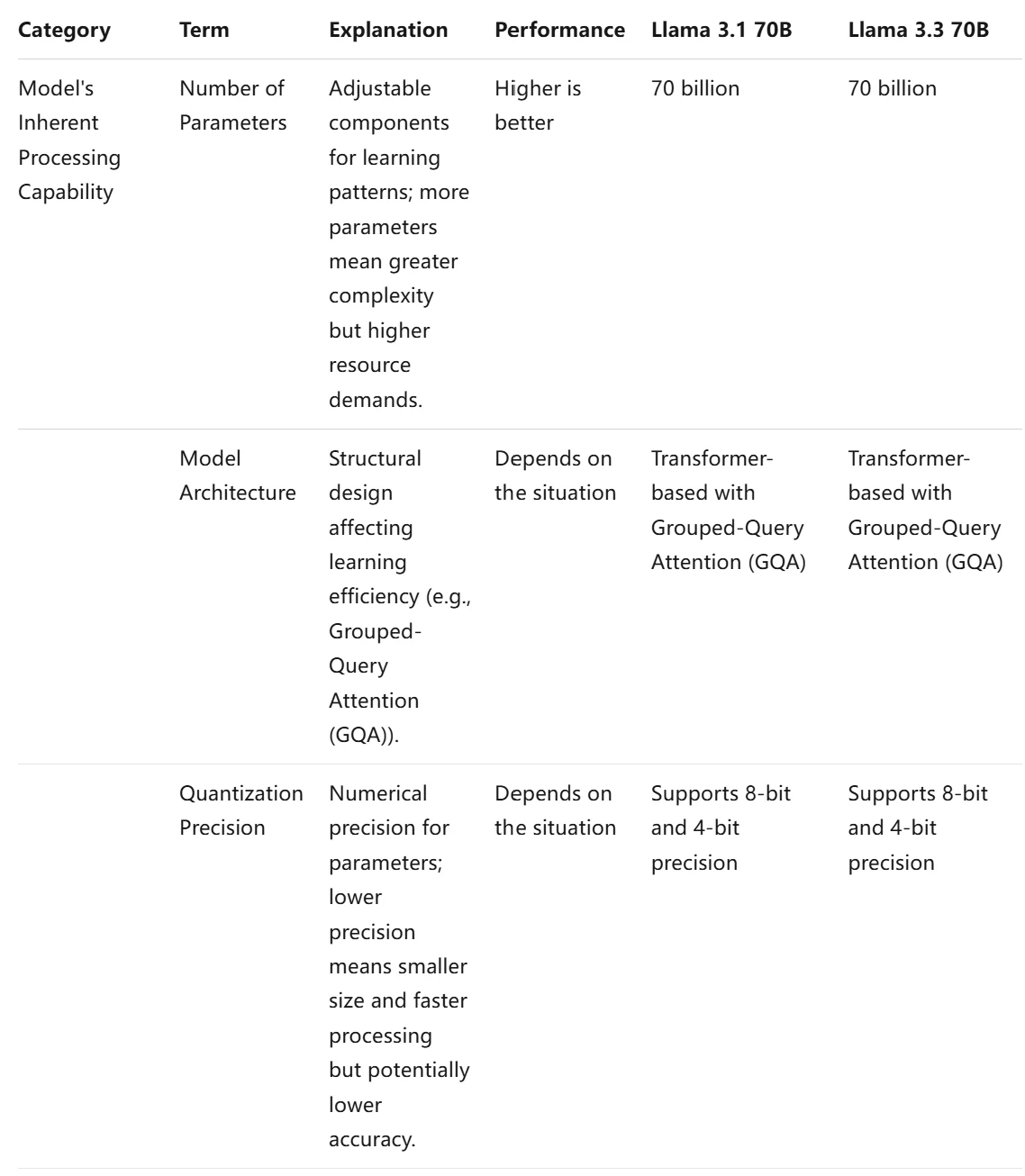

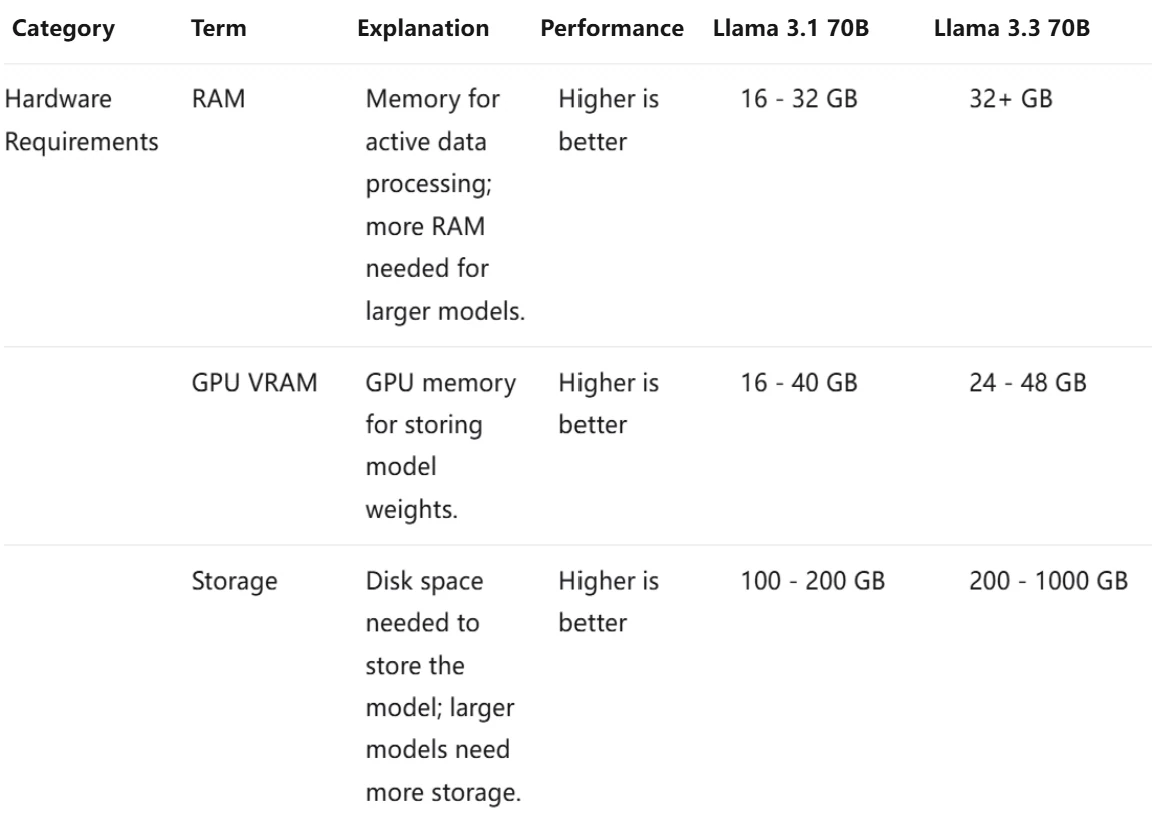
如果您想使用它们,Novita AI 提供 0.5 美元额度供您入门!
应用与使用场景
两个模型都适用于类似的应用场景,包括:
- 多语言聊天
- 编码辅助
- 合成数据生成
- 文本摘要
- 内容创作
- 本地化
- 知识型任务
- 工具使用
Llama 3.3 70b 在这些应用场景中可能表现更好,尤其是在多语言对话方面,得益于其优化。
通过 Novita AI 访问和部署
第 1 步:登录并访问模型库
登录您的账户,点击 模型库 按钮。

第 2 步:选择模型
浏览可用选项,选择符合您需求的模型。

第 3 步:开始免费试用
开始免费试用,探索所选模型的功能。

第 4 步:获取 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入 “设置” 页面,您可以复制 API 密钥,如下图所示。

第 5 步:安装 API
使用您编程语言对应的包管理器安装 API。

安装后,将所需的库导入您的开发环境。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是供 Python 用户使用的聊天补全 API 示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
注册后,Novita AI 会提供 0.5 美元额度供您入门!
如果免费额度用完,您可以付费继续使用。
结论
总之,选择 Llama 3.1 70B 还是 Llama 3.3 70B 取决于应用的具体要求和可用的硬件资源。Llama 3.1 70B 在成本和延迟方面表现出色,非常适合需要快速响应和成本效益的应用。另一方面,Llama 3.3 70B 在最大输出和吞吐量方面表现优异,适合需要生成长文本和高吞吐量的应用,尽管其硬件要求更高。因此,仔细权衡这些因素,选择最适合您需求的模型至关重要。
常见问题解答
llama 3.1 是否受限制?
对于 Llama 3.1、Llama 3.2 和 Llama 3.3,只要包含正确的 Llama 归属声明,就允许使用。详情请参阅许可协议。
llama 3.1 比 GPT-4 更好吗?
聊天机器人:由于 Llama 3 具有深层的语言理解能力,您可以用它来自动化客户服务。即使在问题解决任务中,其响应和修正输出相比 GPT-4 也更准确。Llama 3 和 GPT-4 都是编码和问题解决方面的强大工具,但它们满足不同的需求。如果您在编码任务中优先考虑准确性和效率,Llama 3 可能是更好的选择。
llama 3.1 与 llama 3 有何不同?
模型推荐:Llama 3.1 70B 适合长文本内容和复杂文档分析,而 Llama 3 70B 更适合实时交互。LLM API 灵活性:LLM API 允许开发人员无缝切换模型,便于直接比较并最大化各模型的优势。
Novita AI 是一个全能云平台,助力实现您的 AI 雄心。集成 API、无服务器、GPU 实例——您需要的经济高效的工具。消除基础设施负担,免费开始,让您的 AI 愿景成为现实。



