

各类 AI 公司如今都在推出能够对你指定的主题进行深度研究,并生成详尽报告的 Agentic AI 系统,例如 OpenAI 的 Deep Research。
像 OpenAI Deep Research 这样的 Agentic AI 系统为多步搜索和综合等复杂任务提供了自动化流程。但多数现有方案都是闭源的,难以定制,并且限制了你对模型行为和数据处理的掌控。
比如,你可能想使用不同的 LLM、自定义搜索提供商,或者调整代理的规划和行为方式,以生成特定输出。
这就引出了一个有意思的问题:能否创建完全灵活的自有深度搜索代理,让你使用偏爱的 AI 模型、集成偏爱的搜索引擎,并自定义代理行为?答案是 可以。
在本文中,你将学习如何使用 Novita AI 、 LangChain 和 Tavily 来构建自己的深度研究代理。
什么是深度搜索代理工作流?
传统搜索通常很耗时,因为它需要筛选网上大量信息,最终却不一定能获得深入见解。深度搜索代理工作流 通过 AI 代理来解决这些问题,这些代理能够自主推理、做出决策,并在工作流中协调使用外部工具。
这个工作流通常包含以下几个步骤:
-
任务结构化:AI 代理将主题分解为较小的任务。
-
规划:代理制定策略来执行每个任务,帮助工作流确定任务的执行顺序。
-
工具集成:为了收集信息,代理使用不同的工具,例如数据库和网络搜索引擎。没有这些工具,代理就无法在工作流中执行关键操作。
-
综合:代理分析收集到的信息,并将其整合成连贯的数据。
-
报告生成:综合数据后,代理创建一份包含摘要和引文的结构化报告。
所需的工具
在进入本文的构建部分之前,我们先设置好必要的工具。
Novita AI
要构建代理工作流,我们需要一个 LLM。Novita AI 提供了价格合理、高性能的 API,让你能使用最新的 LLM、图像生成模型等。
登录 Novita AI 开始使用。登录后,导航至 Settings > Key Management,按照提示生成一个 API 密钥。
请注意,注册后 Novita AI 会提供免费额度,让你体验各种模型,因此在开始构建或实验前无需担心购买额度。

Tavily
Tavily 是一个为 AI 应用优化的高级网络搜索 API。使用 Tavily 的搜索引擎工具,我们可以让代理访问互联网,帮助收集准确和客观的信息。前往 Tavily 并生成一个 API 密钥。

LangChain
LangChain 是一个为构建基于 LLM 的应用而设计的开源框架。使用 LangChain,你可以创建能够逐步推理、使用工具并与 API 交互的代理工作流。对于我们的深度研究代理,我们会使用 LangChain 来结构化研究过程,使用网络搜索等工具,并将所有内容综合成一份结构化报告。
Google Colab
在本教程中,我们将使用 Google Colab 构建并测试深度搜索代理。Colab 让你无需任何设置,即可在浏览器中编写和运行 Python 代码,这使本教程易于跟随。
工作流概览
深度代理搜索是不同工作流阶段的组合,从规划搜索任务到交付最终搜索报告。我们来逐一了解每个步骤,理解应用的工作原理。
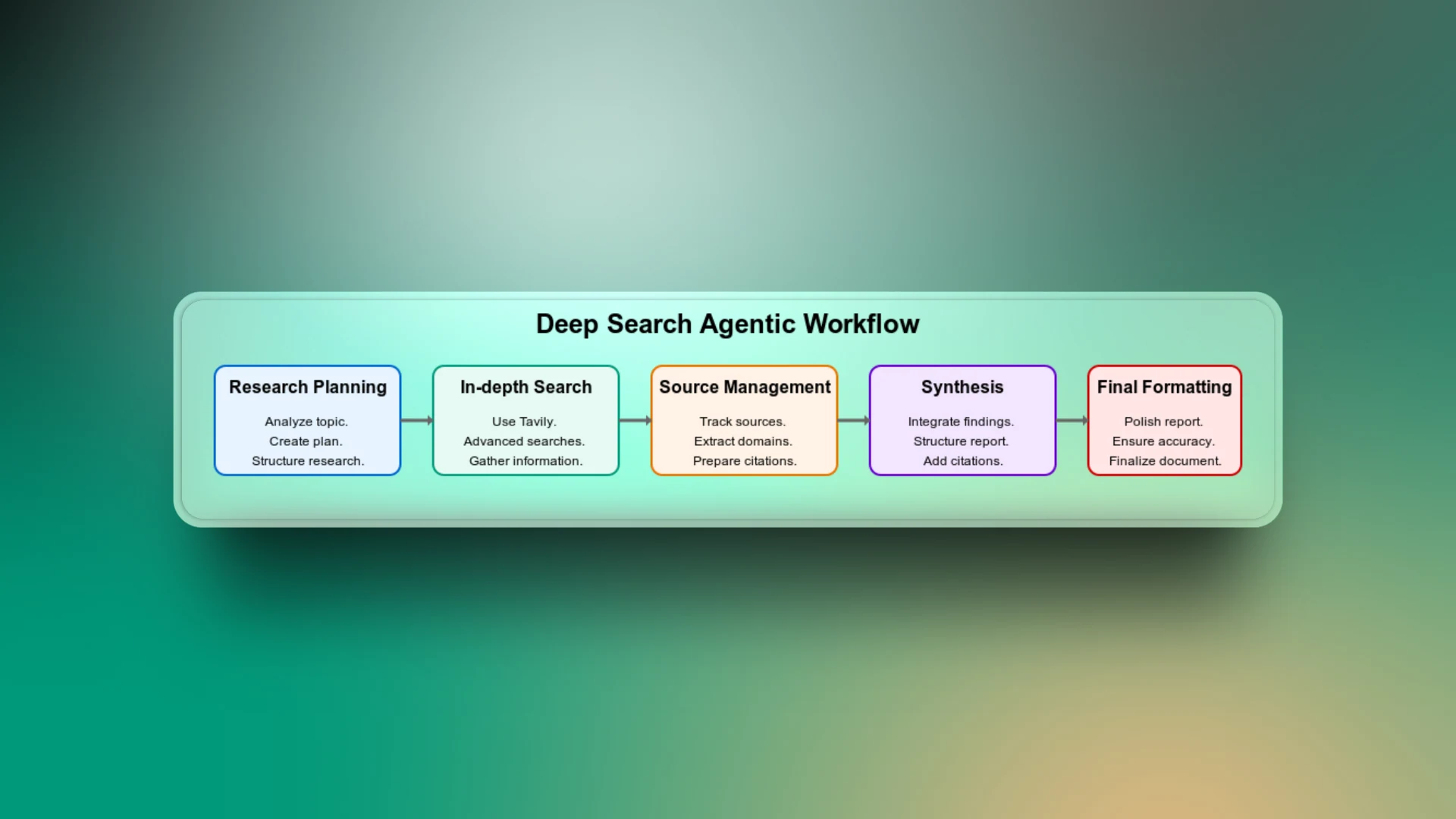
研究规划
这是工作流的第一步。代理会分析主题,并根据主题背景创建结构化的研究计划。它将宽泛的主题分解为有针对性的子主题,如历史、技术细节、优缺点、用例等。
你可以认为这是工作流中最重要的部分,因为如果没有它,代理可能会执行泛化搜索并返回不相关的结果。
深入搜索
LLM 受限于其训练数据,无法获取当前趋势。例如,如果你让一个没有搜索能力的代理列出当前足球队伍中的球员,它会基于训练数据返回结果。但由于这些结果不包含最新更新,它们可能不再准确。
使用 Tavily 执行高级网络搜索,让代理能够访问最新、最相关的网络来源。
来源管理
为了确保代理生成的每一条信息都能链接到可靠来源,跟踪所有来源非常重要。工作流的这一部分建立与用户的信任,用户可能希望验证最终报告中的主张或数据。
综合
为了将收集到的所有信息联系起来,代理将来自所有研究方面的见解汇集在一起,形成连贯的报告。如果没有这个阶段,搜索结果可能只是一份零散的报告。
最终格式化
即使报告事实准确、研究充分,糟糕的格式化也会使其难以阅读。需要额外的步骤来确保结构清晰、标题一致、项目符号列表、间距等。
实现深度搜索代理
到目前为止,你已经了解了深度搜索代理工作流的概念。现在,我们将在 Google Colab 中实现它。
首先,我们执行几个关键步骤:
步骤 1:安装依赖项
-q langchain langchain-openai tavily-python
步骤 2:导入必要的库
# 导入标准 Python 库
import os # 用于与环境变量交互
import re # 用于正则表达式
import ast # 用于安全解析字符串中的 Python 表达式
# LangChain 模型和工具
from langchain_openai import ChatOpenAI # 与 OpenAI 聊天模型交互的接口
from langchain_community.utilities.tavily_search import TavilySearchAPIWrapper # 通过 Tavily API 启用搜索
# LangChain 消息模式
from langchain.schema import SystemMessage, HumanMessage # 定义对话中使用的消息类型
# LangChain 代理组件
from langchain.agents import Tool, AgentExecutor, create_react_agent # 用于构建和运行带工具的代理工作流
# LangChain 提示模板
from langchain.prompts import PromptTemplate # 允许创建可复用的提示模板
# LangChain 记忆
from langchain.memory import ConversationBufferMemory # 帮助在多个轮次中维持对话状态
步骤 3:设置环境变量
# 设置和检索环境变量
os.environ["NOVITA_API_KEY"] = "" # 替换为你的实际 Novita API 密钥
os.environ["TAVILY_API_KEY"] = "" # 替换为你的实际 Tavily API 密钥
# 将 API 密钥加载到变量中
novita_api_key = os.getenv("NOVITA_API_KEY")
tavily_api_key = os.getenv("TAVILY_API_KEY")
步骤 4:定义 LLM 辅助函数
Novita AI 兼容 OpenAI,因此我们将使用 LangChain 的 ChatOpenAI 模块将 Novita AI 与 LangChain 集成。这意味着我们可以以与 OpenAI 模型相同的方式与 Novita 通信。
但需要注意的一点是,我们需要将 base_url 设置为指向 Novita 的 API 端点:https://api.novita.ai/v3/openai。
在这个工作流中,我们将使用模型 llama-4-maverick-17b-128e-instruct-fp8,这是一个针对指令遵循任务微调过的强大 LLaMA 4 变体。
# LLM 辅助函数
def llm(api_key,
model="meta-llama/llama-4-maverick-17b-128e-instruct-fp8",
temperature=0.7):
"""使用指定参数创建 ChatOpenAI LLM 实例。"""
return ChatOpenAI(
model=model,
openai_api_key=api_key,
base_url="https://api.novita.ai/v3/openai",
temperature=temperature,
)
构建 Agentic 研究者
整个深度研究工作流被封装在一个名为 AgenticResearcher 的模块化类中。该类将管理生成研究计划、执行网络搜索、综合结果、格式化最终报告以及运行完整研究循环的过程。
我们将使用通过 Novita API 访问 LLM 和通过 Tavily API 访问网络搜索工具的方法来初始化研究代理。然后,我们定义一个方法,使用 Tavily 对给定查询执行高级网络搜索。结果会格式化为可读形式,原始数据会存储起来供后续使用。
class AgenticResearcher:
def __init__(self, novita_api_key, tavily_api_key, num_researchers=3, temperature=0.3):
"""使用必要的 API 密钥和参数初始化研究代理。"""
self.llm = llm(api_key=novita_api_key, temperature=temperature)
self.tavily_search =
TavilySearchAPIWrapper(tavily_api_key=tavily_api_key)
self.num_researchers = num_researchers
self.raw_search_results = []
def search(self, query):
"""搜索网络以获取有关查询的信息。"""
try:
results = self.tavily_search.results(
query, max_results=7,
search_depth="advanced"
)
# 存储原始结果以供后续引用处理
self.raw_search_results.extend(results)
formatted = []
for r in results:
formatted += [
f"TITLE: {r.get('title','')}",
f"URL: {r.get('url','')}",
f"CONTENT:\
{r.get('content','')}",
"---"
]
return "\
".join(formatted) if formatted else "No results found"
except Exception as e:
return f"Search error: {str(e)}"
创建多维度研究计划
仍然属于 AgenticResearcher 类,让我们创建一个方法,通过 LLM 将主题分解为几个不同的方面,从而生成结构化的研究计划。每个方面包含一个标题和一个具体的搜索查询。目标是从多个角度探索主题,以确保深度和广度。
def create_research_plan(self, topic):
"""创建一个结构化的研究计划,包含多个要调查的方面。"""
sys = "You are a planner that outputs Python lists of dicts."
hum = f"""
Create a comprehensive research plan for: {topic}
Identify {self.num_researchers} distinct aspects to investigate thoroughly.
Analyze the topic and determine the most relevant aspects to research based on its nature and domain.
Output exactly:
ASPECT {{'title': '...', 'search_query': '...'}}
"""
try:
resp = self.llm.invoke([SystemMessage(content=sys), HumanMessage(content=hum)])
aspects = []
for line in resp.content.splitlines():
if line.strip().startswith("ASPECT"):
m = re.search(r"\{.*\}", line)
if m:
try:
aspects.append(ast.literal_eval(m.group(0)))
except Exception as e:
print(f"Error parsing aspect: {e}")
if not aspects:
# 适用于不同领域的通用默认方面
default_aspects = [
{"title": "Overview and Key Information", "search_query": f"{topic} overview key facts"},
{"title": "Background and Context", "search_query": f"{topic} background history context"},
{"title": "Details and Specifications", "search_query": f"{topic} details specifics data"},
{"title": "Analysis and Significance", "search_query": f"{topic} analysis importance implications"}
]
aspects = default_aspects[:self.num_researchers]
return aspects
except Exception as e:
print(f"Error creating research plan: {e}")
return [{"title": f"{topic} research", "search_query": topic}]
来源管理与引用
下一步,我们需要处理工作流如何生成可信报告。我们将通过创建一个从原始搜索结果中提取唯一来源的方法来实现这一点,确保每个来源都被引用。
def extract_sources(self):
"""从原始搜索结果中提取唯一来源,用于引用。"""
unique_sources = {}
for result in self.raw_search_results:
url = result.get('url', '')
if url and 'http' in url:
domain = url.split('/')[2] if len(url.split('/')) > 2 else url
if domain not in unique_sources:
unique_sources[domain] = url
return unique_sources
报告综合
现在我们已经从多个来源收集了原始信息,下一步是将这些杂乱输入转换为详细的研究报告。我们将编写将原始文本综合成可读、组织良好的报告的方法,其中包含标题、子标题、关键发现和来源引用。
def synthesize(self, text):
"""将原始文本综合成详细、结构化的发现,并附引用。"""
sources = self.extract_sources()
sources_list = list(sources.keys())
sys = """You are an expert research synthesizer that creates detailed, structured reports.
For each claim or fact you include, add a citation to the source domain.
Use the exact domain names provided without modification.
Adapt your report structure to the topic's domain and nature."""
hum = f"""
INFORMATION TO SYNTHESIZE:
{text}
AVAILABLE SOURCE DOMAINS (use these exact names for citations):
{sources_list}
Create a comprehensive, detailed research report with:
1. Main findings with specific facts and figures
2. Structured information with clear headings and subheadings appropriate to the topic
3. Citations using the exact source domain names in square brackets [like.this]
4. Relevant data presented clearly and professionally
5. Format adapted to the specific nature of the topic (technical, historical, news event, etc.)
FORMAT THE REPORT PROFESSIONALLY AND THOROUGHLY WITHOUT ASSUMING ANY SPECIFIC DOMAIN.
"""
try:
return self.llm.invoke([SystemMessage(content=sys), HumanMessage(content=hum)]).content
except Exception as e:
return f"Synthesis error: {str(e)}"
为代理创建工具
为了使深度搜索代理工作流可用,我们需要定义工具。工具赋予代理执行特定操作的能力。
这个工作流需要的核心工具包括:“plan”帮助代理分解主题并创建结构化研究计划;“search”让代理执行深度网络搜索;“synthesize”让代理将所有原始发现转换为组织好的报告。
def get_tools(self):
"""创建并返回代理可用的工具列表。"""
return [
Tool(
name="plan",
func=lambda t: str(self.create_research_plan(t)),
description="Create a detailed research plan with multiple aspects to investigate."
),
Tool(
name="search",
func=self.search,
description="Search the web thoroughly for a query and return comprehensive results."
),
Tool(
name="synthesize",
func=self.synthesize,
description="Transform raw text into detailed, structured findings with citations."
),
]
构建代理执行器
现在工具已准备就绪,我们需要使用 ReAct 风格的提示将所有内容整合成一个 AI 代理。这有助于代理进行规划、使用定义的工具执行操作、观察结果并循环,直到拥有足够数据来生成最终研究报告。
def get_agent_executor(self):
"""创建并返回带工具和记忆的代理执行器。"""
tools = self.get_tools()
template = """You are an autonomous research agent specialized in producing comprehensive, detailed reports on any topic.
{tool_names}
TOOLS:
{tools}
PREVIOUS CONVERSATIONS:
{chat_history}
When given a research topic (as {input}), follow this process:
1. Analyze the type of topic and create a research plan tailored to its domain
2. Search for comprehensive information on each aspect of the topic
3. Collect detailed, relevant information with sources
4. Synthesize everything into a professional, detailed report formatted appropriately for the topic
Follow exactly this format:
Question: {input}
Thought: (your reasoning here)
Action: the name of the tool to call, must be one of [{tool_names}]
Action Input: the input to the tool
Observation: (the tool's output)
... (repeat Thought/Action/Action Input/Observation as needed)
When you have gathered comprehensive information, output:
Final Answer: (your final, detailed research report with structured sections, appropriate formatting, specific details, and citations)
BEGIN WITH A THOROUGH PLAN!
{agent_scratchpad}
"""
prompt = PromptTemplate(
template=template,
input_variables=["input", "agent_scratchpad", "tools", "tool_names", "chat_history"]
)
# 创建底层代理
agent = create_react_agent(
llm=self.llm,
tools=tools,
prompt=prompt
)
# 将其包装在带记忆的执行器中
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent_executor = AgentExecutor.from_agent_and_tools(
agent=agent,
tools=tools,
verbose=True,
memory=memory,
max_iterations=18,
early_stopping_method="generate",
handle_parsing_errors=True
)
return agent_executor
最终报告格式化
在研究代理完成深度搜索后,输出可能信息量丰富但不够美观。这个额外步骤有助于使最终报告更精良。为此,我们将提示 LLM 作为专家编辑来改进最终报告。
def format_final_report(self, raw_report):
"""为报告添加最终格式化,使其更专业。"""
sys = """You are an expert editor that improves research reports.
Keep all the factual content, citations, and structure intact.
Just improve the formatting, organization, and readability."""
hum = f"""
Here is a research report that needs final formatting improvements:
{raw_report}
Please improve the formatting and presentation while preserving all:
1. Facts and figures
2. Citations
3. Content organization
4. Statistical data
Make it look professional with proper headings, spacing, and layout.
"""
try:
improved = self.llm.invoke([SystemMessage(content=sys), HumanMessage(content=hum)]).content
return improved
except Exception as e:
# 如果格式化失败,返回原始报告
return raw_report
整合在一起
让我们将整个工作流整合到一个管道中,该管道协调整个研究流程。这将作为入口点,使代理能够执行完整的研究过程,然后格式化最终报告。
def run(self, topic):
"""对给定主题执行研究过程。"""
try:
# 重置存储的搜索结果
self.raw_search_results = []
# 运行代理
executor = self.get_agent_executor()
raw_report = executor.invoke({"input": topic})["output"]
# 格式化最终报告
final_report = self.format_final_report(raw_report)
return final_report
except Exception as e:
return f"Research failed: {str(e)}"
运行研究代理
现在我们已经构建了深度搜索代理工作流,让我们测试一下它在真实研究任务中的表现。
我们将创建一个研究代理实例,并要求它生成一个关于当前主题的详细报告。
# 创建研究者对象
researcher = AgenticResearcher(novita_api_key, tavily_api_key, num_researchers=3)
# 运行一个测试研究
topic = "What are the most promising climate tech startups in 2025?"
report = researcher.run(topic)
# 显示研究报告
print("\
" + "="*60)
print(f"📝 DETAILED RESEARCH REPORT: {topic}")
print("="*60)
print(report)
print("="*60 + "\
")
结果:

深度代理工作流将主题分解并创建了研究计划,执行了互联网搜索以检索相关信息,综合了收集到的数据,并最终基于搜索查询返回了一份结构化的报告。
结论
恭喜你构建了自己的深度搜索代理工作流!现在你可以研究任何主题,并获取关于你查询的详细报告。
让我们快速回顾一下你完成的内容:
在本文中,你学习了如何构建一个深度搜索代理,该代理可以将复杂主题分解、生成研究计划、执行互联网搜索,并将所有发现综合成结构化报告。
整个工作流由以下技术驱动:
- Novita AI 作为 LLM 提供商
- LangChain 作为代理框架
- Tavily 作为实时搜索引擎
欢迎尝试不同主题来测试代理的能力!
这仅仅是用当今强大模型可以构建的众多令人兴奋的 AI 应用之一。访问 Novita LLM Playground 体验其他顶尖的最新 AI 模型;也许你的下一个伟大 AI 创意就从那里开始。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷途径,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。



