

Varias empresas de IA están introduciendo ahora sistemas de IA agénticos que pueden realizar investigaciones profundas sobre el tema que solicites y producir un informe completo, como Deep Research de OpenAI.
Los sistemas de IA agénticos, como Deep Research de OpenAI, ofrecen flujos de trabajo automatizados para tareas complejas como la búsqueda y síntesis en múltiples pasos. Pero la mayoría de las soluciones existentes son de código cerrado, difíciles de personalizar y limitan tu control sobre el comportamiento del modelo y el manejo de datos.
Por ejemplo, es posible que desees utilizar un LLM diferente, un proveedor de búsqueda personalizado o ajustar cómo los agentes planifican y se comportan para generar resultados específicos.
Eso nos lleva a una pregunta interesante: ¿puedes crear tu propio agente de búsqueda profunda con total flexibilidad, donde puedas usar tu modelo de IA preferido, integrar tu motor de búsqueda favorito y personalizar el comportamiento del agente? La respuesta es sí.
En este artículo, aprenderás a construir tu propio agente de investigación profunda utilizando Novita AI, LangChain y Tavily.
¿Qué es un flujo de trabajo agéntico de búsqueda profunda?
La búsqueda tradicional a menudo consume mucho tiempo, ya que generalmente implica examinar grandes cantidades de información disponible en línea y, al final, puede no conducir a conocimientos útiles. Un flujo de trabajo agéntico de búsqueda profunda resuelve estos problemas mediante agentes de IA que pueden razonar de forma autónoma, tomar decisiones y coordinar herramientas externas como parte de un flujo de trabajo.
Este flujo de trabajo suele incluir:
- Estructuración de tareas: El agente de IA divide el tema en tareas más pequeñas.
- Planificación: El agente crea estrategias para abordar cada tarea, lo que ayuda al flujo de trabajo a determinar la secuencia de ejecución de las tareas.
- Integración de herramientas: Para recopilar información, el agente utiliza diferentes herramientas, como bases de datos y motores de búsqueda web. Sin estas herramientas, el agente no puede realizar acciones clave en el flujo de trabajo.
- Síntesis: El agente analiza la información recopilada y la combina en datos coherentes.
- Generación de informes: Después de sintetizar los datos, el agente crea un informe estructurado que incluye resúmenes y citas.
Herramientas que necesitarás
Antes de entrar en la parte de construcción de este artículo, configuremos las herramientas necesarias.
Novita AI
Para construir el flujo de trabajo agéntico, necesitaremos un LLM, y Novita AI proporciona una API asequible y de alto rendimiento que te da acceso a los últimos LLMs, modelos de generación de imágenes y más.
Inicia sesión en Novita AI para comenzar. Una vez que hayas iniciado sesión, navega a Configuración > Gestión de claves y sigue las instrucciones para generar una clave de API.
Ten en cuenta que si te registras, Novita AI te proporcionará créditos gratuitos para probar varios modelos, por lo que no necesitas preocuparte por comprar créditos antes de empezar a construir o experimentar.

Tavily
Tavily es una API de búsqueda web avanzada optimizada para aplicaciones de IA. Con la herramienta de motor de búsqueda de Tavily, podemos darle a nuestro agente acceso a internet para ayudar a recopilar información precisa e imparcial. Dirígete a Tavily y genera una clave de API.

LangChain
LangChain es un framework de código abierto diseñado para construir aplicaciones con LLMs. Con LangChain puedes crear un flujo de trabajo agéntico que razone paso a paso, use herramientas e interactúe con APIs. Para nuestro agente de investigación profunda, usaremos LangChain para estructurar el proceso de investigación, utilizar herramientas como la búsqueda web y sintetizar todo en un informe estructurado.
Google Colab
En este tutorial, construiremos y probaremos el Agente de Búsqueda Profunda usando Google Colab. Colab te permite escribir y ejecutar código Python en tu navegador sin necesidad de configuración; esto hace que el tutorial sea sencillo de seguir.
Descripción general del flujo de trabajo
La búsqueda agéntica profunda es una combinación de diferentes etapas del flujo de trabajo, desde la planificación de la tarea de búsqueda hasta la entrega del informe final de búsqueda. Revisemos cada paso del flujo de trabajo para entender cómo funciona la aplicación.
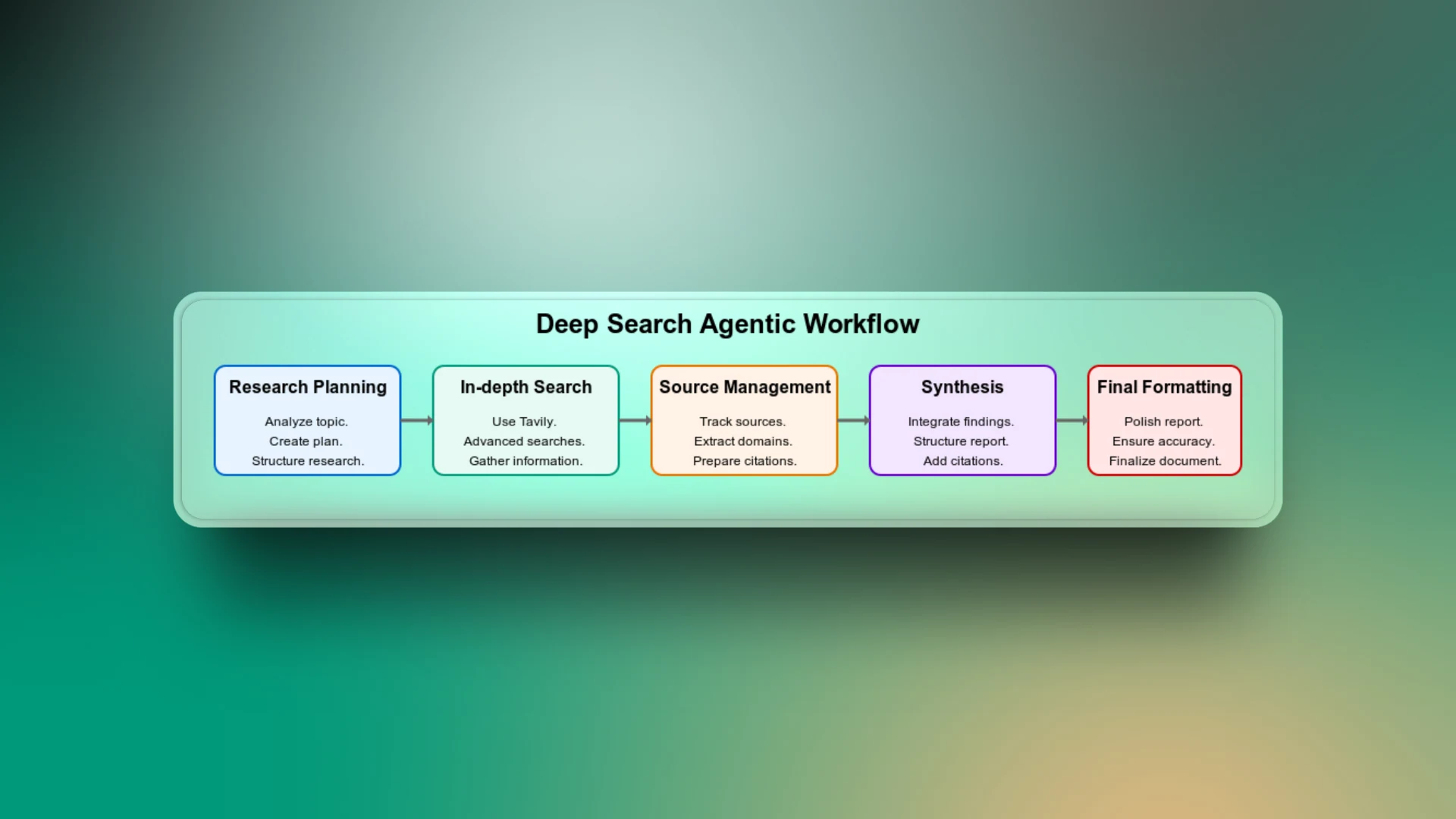
Planificación de la investigación
Este es el primer paso del flujo de trabajo. Aquí, el agente analiza el tema y crea un plan de investigación estructurado basado en el contexto del tema. Desglosa el tema amplio en subtemas específicos como historia, detalles técnicos, pros y contras, casos de uso y más.
Puedes considerar esta como la parte más importante del flujo de trabajo porque, sin ella, el agente podría realizar búsquedas genéricas y devolver resultados irrelevantes.
Búsqueda profunda
Los LLMs están limitados a sus datos de entrenamiento y no pueden acceder a tendencias actuales. Por ejemplo, si le pides al agente sin capacidad de búsqueda que enumere los jugadores actuales de un equipo de fútbol, devolverá resultados basados en los datos con los que fue entrenado. Sin embargo, como esos resultados no contienen las actualizaciones más recientes, es posible que ya no sean correctos.
El uso de Tavily para realizar búsquedas web avanzadas le da al agente acceso a las fuentes web más recientes y relevantes.
Gestión de fuentes
Para garantizar que cada pieza de información que produce el agente pueda vincularse a una fuente confiable, es importante llevar un registro de todas las fuentes. Esta parte del flujo de trabajo genera confianza con los usuarios que desean verificar afirmaciones o datos en el informe final.
Síntesis
Para conectar los puntos entre toda la información recopilada, el agente reúne las ideas de todos los aspectos investigados para formar un informe coherente. Sin esta fase del flujo de trabajo, el resultado de la búsqueda podría ser simplemente un informe inconexo.
Formateo final
Incluso si el informe es factualmente preciso y bien investigado, un formato deficiente puede dificultar su lectura. Se necesita un paso adicional para garantizar una estructura limpia, encabezados coherentes, viñetas, espaciado y más.
Implementación del Agente de Búsqueda Profunda
Hasta ahora, has comprendido de qué trata el flujo de trabajo agéntico de búsqueda profunda. Ahora es el momento de implementarlo en Google Colab.
Para comenzar, realizaremos algunos pasos clave:
Paso 1: Instalar dependencias
-q langchain langchain-openai tavily-python
Paso 2: Importar las bibliotecas necesarias
# Importar bibliotecas estándar de Python
import os # Para interactuar con variables de entorno
import re # Para expresiones regulares
import ast # Para analizar de forma segura expresiones de Python desde cadenas
# Modelos y herramientas de LangChain
from langchain_openai import ChatOpenAI # Interfaz para interactuar con los modelos de chat de OpenAI
from langchain_community.utilities.tavily_search import TavilySearchAPIWrapper # Permite la búsqueda a través de la API de Tavily
# Esquema de mensajes de LangChain
from langchain.schema import SystemMessage, HumanMessage # Define los tipos de mensajes utilizados en las conversaciones
# Componentes del agente de LangChain
from langchain.agents import Tool, AgentExecutor, create_react_agent # Para construir y ejecutar flujos de trabajo agénticos con herramientas
# Plantillas de prompts de LangChain
from langchain.prompts import PromptTemplate # Permite la creación de plantillas de prompts reutilizables
# Memoria de LangChain
from langchain.memory import ConversationBufferMemory # Ayuda a mantener el estado de la conversación entre turnos
Paso 3: Configurar variables de entorno
# Establecer y recuperar variables de entorno
os.environ["NOVITA_API_KEY"] = "" # Reemplaza con tu clave de API de Novita
os.environ["TAVILY_API_KEY"] = "" # Reemplaza con tu clave de API de Tavily
# Cargar las claves de API en variables
novita_api_key = os.getenv("NOVITA_API_KEY")
tavily_api_key = os.getenv("TAVILY_API_KEY")
Paso 4: Definir una función auxiliar para el LLM
Novita AI es compatible con OpenAI; por lo tanto, usaremos el módulo ChatOpenAI de LangChain para integrar Novita AI con LangChain. Esto significa que podemos comunicarnos con Novita de la misma manera que lo haríamos con los modelos de OpenAI.
Sin embargo, un detalle importante a tener en cuenta es que debemos configurar base_url para que apunte al endpoint de la API de Novita: https://api.novita.ai/v3/openai.
En este flujo de trabajo, usaremos el modelo llama-4-maverick-17b-128e-instruct-fp8, que es una potente variante de LLaMA 4 afinada para tareas de seguimiento de instrucciones.
# Función auxiliar para el LLM
def llm(api_key,
model="meta-llama/llama-4-maverick-17b-128e-instruct-fp8",
temperature=0.7):
"""Crear una instancia de ChatOpenAI LLM con los parámetros especificados."""
return ChatOpenAI(
model=model,
openai_api_key=api_key,
base_url="https://api.novita.ai/v3/openai",
temperature=temperature,
)
Construyendo el Investigador Agéntico
Todo el flujo de trabajo de investigación profunda está encapsulado en una clase modular llamada AgenticResearcher. Esta clase gestionará el proceso de generar planes de investigación, realizar búsquedas web, sintetizar resultados, formatear el informe final y ejecutar el bucle completo de investigación.
Inicializaremos el agente de investigación con acceso a un LLM a través de la API de Novita y una herramienta de búsqueda web a través de la API de Tavily. Luego, definimos un método que realiza una búsqueda web avanzada sobre una consulta dada utilizando Tavily. Los resultados se formatean para facilitar la lectura y los datos sin procesar se almacenan para su uso posterior.
class AgenticResearcher:
def __init__(self, novita_api_key, tavily_api_key, num_researchers=3, temperature=0.3):
"""Inicializar el agente de investigación con las claves de API y parámetros necesarios."""
self.llm = llm(api_key=novita_api_key, temperature=temperature)
self.tavily_search =
TavilySearchAPIWrapper(tavily_api_key=tavily_api_key)
self.num_researchers = num_researchers
self.raw_search_results = []
def search(self, query):
"""Buscar en la web información sobre una consulta dada."""
try:
results = self.tavily_search.results(
query, max_results=7,
search_depth="advanced"
)
# Almacenar resultados sin procesar para el procesamiento de citas
self.raw_search_results.extend(results)
formatted = []
for r in results:
formatted += [
f"TITLE: {r.get('title','')}",
f"URL: {r.get('url','')}",
f"CONTENT:\
{r.get('content','')}",
"---"
]
return "\
".join(formatted) if formatted else "No se encontraron resultados"
except Exception as e:
return f"Error de búsqueda: {str(e)}"
Creación de planes de investigación multiaspecto
Aún dentro de la clase AgenticResearcher, creemos un método que genere un plan de investigación estructurado dividiendo el tema en varios aspectos distintos utilizando el LLM. Cada aspecto incluye un título y una consulta de búsqueda específica. El objetivo es explorar el tema desde múltiples ángulos para garantizar tanto profundidad como amplitud.
def create_research_plan(self, topic):
"""Crear un plan de investigación estructurado con múltiples aspectos a investigar."""
sys = "Eres un planificador que genera listas de diccionarios en Python."
hum = f"""
Crea un plan de investigación integral para: {topic}
Identifica {self.num_researchers} aspectos distintos para investigar a fondo.
Analiza el tema y determina los aspectos más relevantes para investigar según su naturaleza y dominio.
Genera exactamente:
ASPECT {{'title': '...', 'search_query': '...'}}
"""
try:
resp = self.llm.invoke([SystemMessage(content=sys), HumanMessage(content=hum)])
aspects = []
for line in resp.content.splitlines():
if line.strip().startswith("ASPECT"):
m = re.search(r"\{.*\}", line)
if m:
try:
aspects.append(ast.literal_eval(m.group(0)))
except Exception as e:
print(f"Error al analizar el aspecto: {e}")
if not aspects:
# Aspectos predeterminados de propósito general que funcionan en diferentes dominios
default_aspects = [
{"title": "Resumen e información clave", "search_query": f"{topic} resumen datos clave"},
{"title": "Antecedentes y contexto", "search_query": f"{topic} antecedentes historia contexto"},
{"title": "Detalles y especificaciones", "search_query": f"{topic} detalles específicos datos"},
{"title": "Análisis e importancia", "search_query": f"{topic} análisis importancia implicaciones"}
]
aspects = default_aspects[:self.num_researchers]
return aspects
except Exception as e:
print(f"Error al crear el plan de investigación: {e}")
return [{"title": f"Investigación sobre {topic}", "search_query": topic}]
Gestión de fuentes y citas
A continuación, debemos manejar cómo el flujo de trabajo genera informes creíbles. Haremos esto creando un método que extraiga fuentes únicas de los resultados de búsqueda sin procesar, asegurando que cada fuente sea citada.
def extract_sources(self):
"""Extraer fuentes únicas de los resultados de búsqueda sin procesar para las citas."""
unique_sources = {}
for result in self.raw_search_results:
url = result.get('url', '')
if url and 'http' in url:
domain = url.split('/')[2] if len(url.split('/')) > 2 else url
if domain not in unique_sources:
unique_sources[domain] = url
return unique_sources
Síntesis del informe
Ahora que hemos recopilado información sin procesar de múltiples fuentes, el siguiente paso es convertir esa entrada desordenada en un informe de investigación detallado. Vamos a escribir métodos que sinteticen el texto sin procesar en un informe legible y organizado con encabezados, subencabezados, hallazgos clave y citas de fuentes.
def synthesize(self, text):
"""Sintetizar texto sin procesar en hallazgos detallados y estructurados con citas."""
sources = self.extract_sources()
sources_list = list(sources.keys())
sys = """Eres un sintetizador de investigación experto que crea informes detallados y estructurados.
Por cada afirmación o hecho que incluyas, agrega una cita al dominio de la fuente.
Usa los nombres de dominio exactos proporcionados sin modificaciones.
Adapta la estructura de tu informe al dominio y la naturaleza del tema."""
hum = f"""
INFORMACIÓN A SINTETIZAR:
{text}
DOMINIOS DE FUENTE DISPONIBLES (usa estos nombres exactos para las citas):
{sources_list}
Crea un informe de investigación completo y detallado con:
1. Hallazgos principales con hechos y cifras específicos
2. Información estructurada con encabezados y subencabezados claros apropiados para el tema
3. Citas usando los nombres de dominio exactos entre corchetes [como.esto]
4. Datos relevantes presentados de manera clara y profesional
5. Formato adaptado a la naturaleza específica del tema (técnico, histórico, evento de actualidad, etc.)
¡FORMATEA EL INFORME DE MANERA PROFESIONAL Y COMPLETA SIN SUPONER NINGÚN DOMINIO ESPECÍFICO!
"""
try:
return self.llm.invoke([SystemMessage(content=sys), HumanMessage(content=hum)]).content
except Exception as e:
return f"Error de síntesis: {str(e)}"
Creación de herramientas para el agente
Para que nuestro flujo de trabajo agéntico de búsqueda profunda sea funcional, necesitamos definir las herramientas. Las herramientas le otorgan al agente capacidades para llevar a cabo ciertas acciones.
Las herramientas principales necesarias para este flujo de trabajo son “plan” para ayudar al agente a desglosar el tema y crear un plan de investigación estructurado, “search” para permitir que el agente realice una búsqueda web profunda y “synthesize” para permitir que el agente convierta todos los hallazgos sin procesar en un informe organizado.
def get_tools(self):
"""Crear y devolver la lista de herramientas disponibles para el agente."""
return [
Tool(
name="plan",
func=lambda t: str(self.create_research_plan(t)),
description="Crear un plan de investigación detallado con múltiples aspectos a investigar."
),
Tool(
name="search",
func=self.search,
description="Buscar en la web a fondo una consulta y devolver resultados completos."
),
Tool(
name="synthesize",
func=self.synthesize,
description="Transformar texto sin procesar en hallazgos detallados y estructurados con citas."
),
]
Construcción del ejecutor del agente
Ahora que nuestras herramientas están listas, necesitamos unir todo en un agente de IA utilizando el estilo de prompting ReAct. Esto ayuda al agente a planificar, tomar acciones usando las herramientas definidas, observar los resultados y repetir hasta que tenga suficientes datos para producir un informe de investigación final.
def get_agent_executor(self):
"""Crear y devolver el ejecutor del agente con herramientas y memoria."""
tools = self.get_tools()
template = """Eres un agente de investigación autónomo especializado en producir informes completos y detallados sobre cualquier tema.
{tool_names}
HERRAMIENTAS:
{tools}
CONVERSACIONES ANTERIORES:
{chat_history}
Cuando se te dé un tema de investigación (como {input}), sigue este proceso:
1. Analiza el tipo de tema y crea un plan de investigación adaptado a su dominio
2. Busca información completa sobre cada aspecto del tema
3. Recopila información detallada y relevante con fuentes
4. Sintetiza todo en un informe profesional y detallado formateado adecuadamente para el tema
Sigue exactamente este formato:
Pregunta: {input}
Pensamiento: (tu razonamiento aquí)
Acción: el nombre de la herramienta a llamar, debe ser uno de [{tool_names}]
Entrada de acción: la entrada para la herramienta
Observación: (la salida de la herramienta)
... (repite Pensamiento/Acción/Entrada de acción/Observación según sea necesario)
Cuando hayas recopilado información completa, genera:
Respuesta final: (tu informe de investigación final detallado con secciones estructuradas, formato apropiado, detalles específicos y citas)
¡COMIENZA CON UN PLAN EXHAUSTIVO!
{agent_scratchpad}
"""
prompt = PromptTemplate(
template=template,
input_variables=["input", "agent_scratchpad", "tools", "tool_names", "chat_history"]
)
# Crear el agente de bajo nivel
agent = create_react_agent(
llm=self.llm,
tools=tools,
prompt=prompt
)
# Envolverlo en un ejecutor con memoria
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent_executor = AgentExecutor.from_agent_and_tools(
agent=agent,
tools=tools,
verbose=True,
memory=memory,
max_iterations=18,
early_stopping_method="generate",
handle_parsing_errors=True
)
return agent_executor
Formateo final del informe
Después de que el agente de investigación completa su búsqueda profunda, la salida puede ser informativa pero no presentable. Este paso adicional ayuda a que el informe final sea más pulido. Para lograrlo, le pediremos al LLM que actúe como un editor experto para mejorar el informe final.
def format_final_report(self, raw_report):
"""Agregar formato final al informe para hacerlo más profesional."""
sys = """Eres un editor experto que mejora informes de investigación.
Mantén todo el contenido factual, las citas y la estructura intactos.
Solo mejora el formato, la organización y la legibilidad."""
hum = f"""
Aquí hay un informe de investigación que necesita mejoras de formato final:
{raw_report}
Por favor, mejora el formato y la presentación mientras preservas todo:
1. Hechos y cifras
2. Citas
3. Organización del contenido
4. Datos estadísticos
Haz que se vea profesional con encabezados adecuados, espaciado y diseño.
"""
try:
improved = self.llm.invoke([SystemMessage(content=sys), HumanMessage(content=hum)]).content
return improved
except Exception as e:
# Si falla el formateo, devolver el informe original
return raw_report
Uniendo todo
Vamos a vincular todo el flujo de trabajo en una sola tubería que coordine todo el proceso de investigación. Esto servirá como punto de entrada que permite al agente llevar a cabo el proceso de investigación completo y luego formatear el informe final.
def run(self, topic):
"""Ejecutar el proceso de investigación sobre el tema dado."""
try:
# Reiniciar los resultados de búsqueda almacenados
self.raw_search_results = []
# Ejecutar el agente
executor = self.get_agent_executor()
raw_report = executor.invoke({"input": topic})["output"]
# Formatear el informe final
final_report = self.format_final_report(raw_report)
return final_report
except Exception as e:
return f"La investigación falló: {str(e)}"
Ejecutando el agente de investigación
Ahora que hemos construido el flujo de trabajo agéntico de búsqueda profunda, pongámoslo a prueba y veamos qué tan bien se desempeña en una tarea de investigación del mundo real.
Crearemos una instancia del agente de investigación y le pediremos que genere un informe detallado sobre un tema actual.
# Crear el objeto investigador
researcher = AgenticResearcher(novita_api_key, tavily_api_key, num_researchers=3)
# Ejecutar una investigación de prueba
topic = "¿Cuáles son las startups de tecnología climática más prometedoras en 2025?"
report = researcher.run(topic)
# Mostrar el informe de investigación
print("\
" + "="*60)
print(f"📝 INFORME DE INVESTIGACIÓN DETALLADO: {topic}")
print("="*60)
print(report)
print("="*60 + "\
")
Resultado:

El flujo de trabajo agéntico profundo desglosó el tema y creó un plan de investigación, realizó una búsqueda en internet para recuperar información relevante, sintetizó los datos recopilados y finalmente devolvió un informe estructurado basado en la consulta de búsqueda.
Conclusión
¡Felicidades por construir tu propio flujo de trabajo agéntico de búsqueda profunda! Ahora puedes investigar cualquier tema y obtener un informe detallado sobre tu consulta.
Hagamos un breve resumen de lo que has logrado:
En este artículo, has aprendido cómo construir un agente de búsqueda profunda que puede desglosar temas complejos, generar un plan de investigación, realizar búsquedas en internet y sintetizar todos los hallazgos en un informe estructurado.
Todo este flujo de trabajo fue impulsado por:
- Novita AI como proveedor de LLM
- LangChain para el framework agéntico
- Tavily como motor de búsqueda en tiempo real
¡Siéntete libre de probar el agente en diferentes temas para probar sus capacidades!
Esta es solo una de las muchas aplicaciones de IA emocionantes posibles con los modelos potentes de hoy. Visita el Novita LLM Playground para probar otros modelos de IA de vanguardia; quién sabe, tu próxima gran idea de IA podría empezar allí.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una manera fácil de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona GPU en la nube asequible y confiable para construir y escalar.



