

关键亮点
GPU 优势:GPU 凭借并行架构,处理机器学习任务的速度比 CPU 快 100 倍,使其成为机器学习任务中不可或缺的组件。
关键规格:选择 GPU 时,重点关注 CUDA 核心数、内存容量、带宽和 TFLOPS。
软件兼容性:确保支持主流机器学习框架和 CUDA。
GPU 类型:根据需求选择消费级、专业级、数据中心或云端 GPU。
性能领先者:2025 年,NVIDIA A100、RTX 3090、RTX 4090 和 AMD Instinct MI250X 处于领先地位。
云端选项:提供灵活性,无需前期硬件投资。
2025 年,机器学习领域持续快速发展,对更强大的硬件需求日益增长,以支持复杂算法和海量数据集。这场技术革命的核心是图形处理器(GPU),这一关键组件已彻底改变了 AI 和机器学习的面貌。本指南综合考虑最新进展和市场趋势,为您提供全面的 GPU 选择指南。
为何 GPU 对机器学习至关重要:性能、速度和效率

并行处理如何通过 GPU 加速机器学习
GPU 通过其并行处理架构革新了机器学习。CPU 凭借少量强大核心擅长顺序任务,而 GPU 则利用数千个较小的核心同时执行无数计算。这种架构差异对机器学习工作负载至关重要:
关键优势:
- 矩阵运算:GPU 高效处理大型矩阵和张量,这对神经网络计算至关重要。
- 批处理:可同时处理多个数据样本,从而加速训练速度。
- 向量计算:并行核心处理机器学习算法中基础的向量运算。
受益于 GPU 的常见机器学习任务
GPU 在现代机器学习中已不可或缺,显著加速了多项关键计算任务。以下详细列出了 GPU 表现出色的主要机器学习应用:
-
深度学习模型训练
- 加速复杂神经架构的训练。
- 实现跨多层的有效反向传播。
- 促进模型架构的快速实验。
- 将训练时间从数周缩短为数小时或数天。
-
神经网络推理
- 在生产环境中实现实时预测。
- 支持高吞吐量批处理。
- 对于延迟敏感型应用中的模型服务至关重要。
- 在大规模部署中尤为有效。
-
图像和视频处理
- 为计算机视觉提供强大的快速卷积运算。
- 实现实时视频分析和处理。
- 加速图像分类和目标检测。
- 支持语义分割等高级任务。
-
自然语言处理
- 加速 Transformer 模型计算。
- 高效处理注意力机制。
- 加速文本生成和翻译任务。
- 对训练大型语言模型至关重要。
-
强化学习
- 促进并行环境模拟。
- 加速策略优化计算。
- 实现复杂游戏模拟。
- 通过并行化支持快速智能体训练。
这些任务之所以极大受益于 GPU,是因为其专门优化的架构:
- 高效的矩阵乘法
- 快速的卷积运算
- 并行张量计算
- 用于数据传输的高内存带宽
通过利用这些能力,GPU 处理机器学习算法基础数学运算的速度可以比传统 CPU 快数个数量级,使得以前不切实际的应用变得可行且经济高效。
CPU vs GPU:机器学习任务哪个更好?
在机器学习任务中,CPU 和 GPU 都扮演着关键角色,但它们各有擅长领域。下表比较了 CPU 和 GPU 在机器学习工作流程中的角色和优势,帮助您了解如何有效地选择和组合它们以获得最佳性能。
| 方面 | CPU | GPU |
| 主要角色 | 通用计算。 | 专门用于机器学习任务的并行处理。 |
| 机器学习任务速度 | 计算密集型任务较慢。 | 对于特定机器学习任务(如训练神经网络),数据处理速度可提升 100 倍。 |
| 优势 | 擅长顺序任务、数据预处理和任务编排。 | 擅长大规模并行任务,如模型训练和推理。 |
| 数据预处理 | 处理数据清洗、特征提取和任务编排。 | 不适合数据预处理任务。 |
| 任务管理 | 管理整体机器学习流水线,包括任务调度。 | 加速流水线中的特定任务,如神经网络中的矩阵乘法。 |
| 并行化 | 并行处理能力有限;更擅长顺序任务。 | 专为并行性而设计;擅长需要高吞吐量的任务,如训练深度学习模型。 |
| 理想配置 | 最好与 GPU 结合使用,用于系统管理和编排。 | 最适合计算密集型任务,如模型训练和推理。 |
| 工作流程角色 | 监督机器学习工作流程,管理数据加载和准备等任务。 | 通过执行复杂的数学计算加速核心机器学习任务。 |
选择最佳深度学习 GPU 时的关键考虑因素

CUDA 和张量核心
NVIDIA 的 CUDA(统一计算设备架构)核心和张量核心对深度学习性能至关重要。CUDA 核心处理通用并行计算,而张量核心专门用于深度学习中常见的矩阵运算。选择 GPU 时,要考虑这些核心的数量和代际,因为它们直接影响性能。
内存和带宽
GPU 内存(VRAM)和带宽对于高效处理大型数据集和复杂模型至关重要。为机器学习选择 GPU 时,优先考虑那些具有高内存容量(16GB 或更多)和高内存带宽的型号,以确保大规模任务的流畅处理。充足的 VRAM 允许 GPU 快速存储和访问大量数据,而高带宽确保 GPU 与内存之间的快速数据传输,从而在模型训练和推理期间最大限度地减少瓶颈。
性能和 TFLOPS
TFLOPS(每秒万亿次浮点运算)是评估 GPU 在机器学习中性能的关键指标。更高的 TFLOPS 值通常表示更强的计算能力,尤其是在训练大型模型或处理复杂任务时。具有更高 TFLOPS 的 GPU 每秒可以处理更多操作,这意味着更快的模型训练速度和更好的整体性能。
兼容性和可扩展性
确保 GPU 与您现有的硬件和软件栈兼容。此外,还要考虑其未来的可扩展性,例如支持多个 GPU 并行工作的能力,这对于随着需求增长处理更苛刻的机器学习项目至关重要。
功耗和散热
高性能 GPU 需要大量功耗并产生大量热量。供电不足会导致系统不稳定,而散热不佳可能导致热节流,降低 GPU 效率并长期损坏硬件。确保您的系统配备适当的供电和散热解决方案,以满足高性能 GPU 的需求。
成本和投资回报率
权衡您的具体需求和预算。高端 GPU 性能出色,但成本高昂。对于密集型任务,高端 GPU 值得投资,但对于较轻量级的工作负载,更实惠的选择可能就足够了。同时考虑前期成本和长期价值。
软件生态系统和框架支持
确保与主流机器学习框架(如 TensorFlow、PyTorch 和 CUDA)兼容。强大的软件生态系统可以极大地提高生产力和性能。
多 GPU 设置
对于大型项目,考虑支持高效多 GPU 配置的 GPU,这些配置允许分布式训练、更快的处理时间以及在不影响性能的情况下扩展工作负载的能力。
GPU 类型:为您的机器学习项目找到理想搭配
消费级 GPU
消费级 GPU,如 NVIDIA 的 GeForce RTX 系列,为个人研究人员和小型项目提供了性能与成本的良好平衡。它们以更可接受的价格提供强大的计算能力。
专业级 GPU
专业级 GPU,如 NVIDIA 的 Quadro 系列,专为工作站设计,并提供 ECC 内存等特性以增强可靠性。它们适用于需要同时具备机器学习能力和传统图形处理的专业环境。
数据中心 GPU
数据中心 GPU,如 NVIDIA 的 A100,专为服务器环境中的大规模机器学习操作而构建。它们提供最高的性能,并设计用于数据中心的 7x24 小时运行。
云端 GPU
云端 GPU 服务,例如 Novita AI 提供的服务,提供灵活、可扩展的 GPU 资源访问,无需前期硬件投资。它们非常适合计算需求波动的项目,或在承诺长期硬件采购之前进行测试,具有成本效益和适应性。
深度学习顶级 GPU:全面比较
NVIDIA A100
NVIDIA A100 是 AI 和深度学习的强劲引擎,凭借其第三代张量核心提供卓越性能。它提供高达 624 TFLOPS 的 FP16 性能,并配备 80GB 高带宽内存,非常适合最苛刻的机器学习工作负载。
NVIDIA RTX 3090
RTX 3090 在深度学习任务中提供了出色的性能和成本平衡。凭借 24GB GDDR6X 内存和第二代 RT 核心,它是研究人员和小型团队的热门选择。
NVIDIA RTX 4090
RTX 4090 代表了最新的消费级 GPU 技术,相比前代产品有显著改进。它拥有第四代张量核心和 24GB GDDR6X 内存,是深度学习应用的强大选择。
NVIDIA RTX 6000
RTX 6000 是一款专业级 GPU,结合了 NVIDIA Ampere 架构的强大性能和 48GB 内存,适用于复杂的机器学习模型和大型数据集。
AMD Instinct MI250X
AMD 在高性能计算领域的产品 Instinct MI250X,为深度学习任务提供了具有竞争力的性能。它配备 128GB HBM2e 内存,并提供高达 383 TFLOPS 的 FP16 性能。
如何在 Novita AI 上租用 GPU 实例
Novita AI 一直处于提供先进云端 GPU 服务的前沿,赋能企业和研究人员利用高性能计算进行机器学习。通过提供对尖端硬件的可扩展、灵活访问,Novita AI 能够高效处理复杂的机器学习任务,而无需大量前期硬件投资。这一能力对于加速创新和优化模型训练过程至关重要。
Novita AI 通过提供对高端 GPU(如 RTX 4090 和 A100)的访问来优化机器学习模型性能,这些 GPU 非常适合训练大规模模型。云端服务允许用户根据项目计算需求无缝扩展或缩减资源。这种灵活性确保了资源的有效分配,提高了处理速度并降低了成本。
Novita AI 入门指南
要开始将 Novita AI 用于您的机器学习项目:
步骤 1:注册账户
如果您是 Novita AI 的新用户,请先在官网创建账户。注册成功后,前往 “GPU” 标签页探索可用资源,开启您的旅程。
[立即尝试 Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Choosing the Best GPU for Machine Learning in 2025: A Complete Guide)
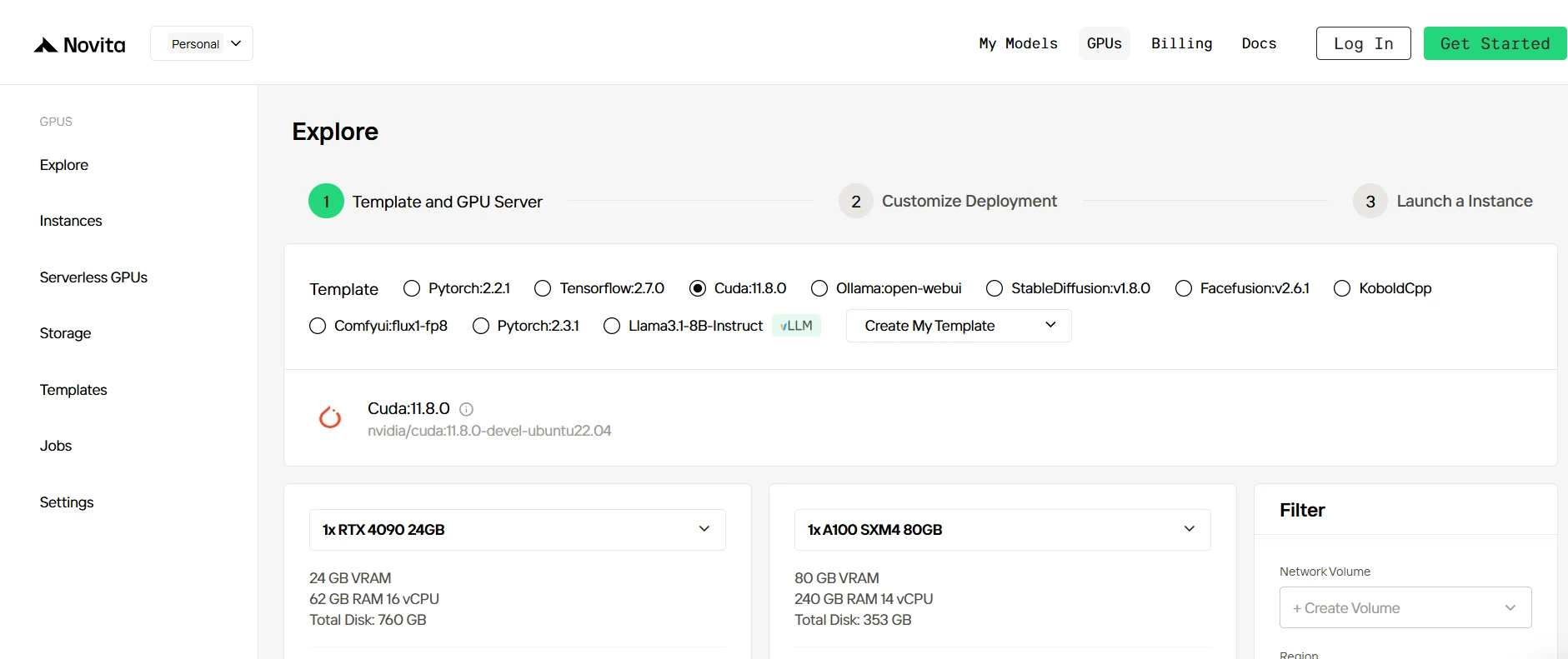
步骤 2:探索模板和 GPU 服务器
首先选择适合您项目需求的模板,例如 PyTorch、TensorFlow 或 CUDA。您可以选择最匹配需求的版本,比如 PyTorch 2.2.1 或 CUDA 11.8.0。然后,选择 GPU 服务器配置,例如 RTX 4090 或 A100 SXM4,并根据工作负载需求选择不同的 VRAM、RAM 和磁盘容量。
[尝试 Novita AI 的高性能 GPU](https://novita.ai/gpus-console/?utm_source=blogs_GPU&utm_medium=article&utm_campaign= Choosing the Best GPU for Machine Learning in 2025: A Complete Guide)
步骤 3:定制部署
选择模板和 GPU 后,您可以自定义部署设置。调整操作系统版本(例如 CUDA 11.8)等参数以及其他设置,根据项目需求微调环境。

步骤 4:启动实例
完成模板和部署设置后,点击 “启动实例” 来设置您的 GPU 实例。这将准备环境,并允许您开始为机器学习任务使用 GPU 资源。

结论
在 2025 年为机器学习选择正确的 GPU 需要仔细考虑多种因素,包括性能、内存、成本和具体项目需求。虽然 NVIDIA 凭借其 CUDA 生态系统和高性能产品继续主导市场,但 AMD 等竞争对手也在取得重大进展。云端 GPU 服务和 Novita AI 等平台为传统的硬件投资提供了灵活的替代方案。随着机器学习领域的不断进步,了解最新的 GPU 技术及其应用,对于希望保持在 AI 创新前沿的研究人员和组织来说至关重要。
常见问题解答
云端 GPU 平台对深度学习有益吗?
是的,云端 GPU 平台提供灵活性和可扩展性,允许用户按需租用强大的 GPU,这对初创公司、研究人员和企业都很有帮助。
使用较旧的 GPU 进行深度学习值得吗?
虽然较旧的 GPU 可以用于深度学习,但较新的型号在性能上更优,尤其对于大型和复杂模型。较旧的 GPU 可能在内存、速度和对新技术的支持方面存在限制。然而,对于较小的模型或初学者来说,较旧的 GPU(如 GeForce GTX 1070 或 RTX 2080 Ti)可能就足够且更经济实惠。
运行机器学习任务时,如何保持 GPU 冷却?
有效的散热至关重要,尤其是在运行多个 GPU 时。如果 GPU 之间有足够的空间,风冷就足够了。涡轮式 GPU 也可以在不使用水冷的情况下工作。当空间有限或使用多个高功率 GPU 时,可能需要水冷,尽管它可能不太可靠,应谨慎使用。
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Choosing the Best GPU for Machine Learning in 2025: A Complete Guide) 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的简便途径,同时还提供经济实惠且可靠的 GPU 云用于构建和扩展。
推荐阅读



