

- Pourquoi les GPU sont essentiels pour le machine learning : performances, rapidité et efficacité
- Facteurs clés à considérer lors de la sélection du meilleur GPU pour le deep learning
- Types de GPU : trouver le choix idéal pour vos projets de machine learning
- Meilleurs GPU pour le deep learning : une comparaison complète
- Comment louer une instance GPU sur Novita AI
- Conclusions
Points clés
Avantage des GPU : les GPU traitent les tâches de ML jusqu’à 100 fois plus vite que les CPU grâce à leur architecture parallèle, ce qui les rend essentiels pour les tâches de machine learning.
Spécifications critiques : concentrez-vous sur les cœurs CUDA, la mémoire, la bande passante et les TFLOPS lors de la sélection d’un GPU.
Compatibilité logicielle : assurez la prise en charge des principaux frameworks ML et de CUDA.
Types de GPU : choisissez entre les GPU grand public, professionnels, pour centre de données ou cloud en fonction de vos besoins.
Meilleurs performeurs : NVIDIA A100, RTX 3090, RTX 4090 et AMD Instinct MI250X sont en tête en 2025.
Options cloud : offrent de la flexibilité sans investissement matériel initial.
En 2025, le domaine du machine learning continue d’évoluer rapidement, exigeant du matériel toujours plus puissant pour prendre en charge des algorithmes complexes et des ensembles de données massifs. Au cœur de cette révolution technologique se trouve l’unité de traitement graphique (GPU), un composant essentiel qui a transformé le paysage de l’IA et du machine learning. Ce guide propose un aperçu complet de la sélection d’un GPU, en tenant compte des dernières avancées et des tendances du marché.
Pourquoi les GPU sont essentiels pour le machine learning : performances, rapidité et efficacité

Comment le traitement parallèle accélère le machine learning avec les GPU
Les GPU révolutionnent le machine learning grâce à leur architecture de traitement parallèle. Alors que les CPU excellent dans les tâches séquentielles avec leurs quelques cœurs puissants, les GPU exploitent des milliers de cœurs plus petits pour effectuer d’innombrables calculs simultanément. Cette différence architecturale s’avère cruciale pour les charges de travail de machine learning :
Avantages clés :
- Opérations matricielles : les GPU traitent efficacement de grandes matrices et tenseurs, essentiels pour les calculs des réseaux de neurones
- Traitement par lots : plusieurs échantillons de données peuvent être traités simultanément, ce qui accélère les vitesses d’entraînement
- Calculs vectoriels : les cœurs parallèles gèrent les opérations vectorielles fondamentales des algorithmes de ML
Tâches courantes de machine learning qui bénéficient des GPU
Les GPU sont devenus indispensables dans le machine learning moderne, accélérant considérablement plusieurs tâches computationnelles clés. Voici une répartition détaillée des principales applications de ML où les GPU démontrent des performances exceptionnelles :
- Entraînement de modèles de deep learning
- Accélère l’entraînement d’architectures neuronales complexes
- Permet une rétropropagation efficace à travers plusieurs couches
- Facilite l’expérimentation rapide avec les architectures de modèles
- Réduit le temps d’entraînement de semaines à heures ou jours
- Inférence des réseaux de neurones
- Permet des prédictions en temps réel dans des environnements de production
- Prend en charge le traitement par lots à haut débit
- Essentiel pour les applications sensibles à la latence
- Particulièrement efficace pour le déploiement à grande échelle
- Traitement d’images et de vidéos
- Alimente des opérations de convolution rapides pour la vision par ordinateur
- Permet l’analyse et le traitement vidéo en temps réel
- Accélère la classification d’images et la détection d’objets
- Prend en charge des tâches avancées comme la segmentation sémantique
- Traitement du langage naturel
- Accélère les calculs des modèles de transformeurs
- Permet un traitement efficace des mécanismes d’attention
- Accélère les tâches de génération de texte et de traduction
- Essentiel pour l’entraînement de grands modèles de langage
- Apprentissage par renforcement
- Facilite la simulation parallèle d’environnements
- Accélère les calculs d’optimisation de politiques
- Permet des simulations de jeux complexes
- Soutient l’entraînement rapide d’agents grâce à la parallélisation
Ces tâches bénéficient énormément des GPU en raison de leur architecture spécialisée optimisée pour :
- Les multiplications matricielles efficaces
- Les opérations de convolution rapides
- Les calculs de tenseurs parallèles
- La bande passante mémoire élevée pour le mouvement des données
En exploitant ces capacités, les GPU peuvent traiter les opérations mathématiques fondamentales des algorithmes de ML des ordres de grandeur plus rapidement que les CPU traditionnels, rendant ainsi possibles des applications auparavant irréalisables et rentables.
CPU vs GPU : quel est le meilleur pour les tâches de machine learning ?
Dans les tâches de machine learning, les CPU et les GPU jouent des rôles cruciaux, mais excellent dans des domaines différents. Le tableau ci-dessous compare les rôles et les forces des CPU et des GPU dans les workflows de machine learning, vous aidant à comprendre comment les choisir et les combiner efficacement pour des performances optimales.
| Aspect | CPU | GPU |
| Rôle principal | Calcul généraliste. | Spécialisé dans le traitement parallèle pour les tâches de machine learning. |
| Vitesse pour les tâches de ML | Plus lent pour les tâches informatiquement intensives. | Peut traiter les données jusqu’à 100 fois plus vite pour certaines tâches de ML comme l’entraînement de réseaux de neurones. |
| Points forts | Efficace pour les tâches séquentielles, le prétraitement des données et l’orchestration. | Efficace pour les tâches parallèles à grande échelle comme l’entraînement et l’inférence de modèles. |
| Prétraitement des données | Gère le nettoyage des données, l’extraction de caractéristiques et l’orchestration des tâches. | Pas idéal pour les tâches de prétraitement des données. |
| Gestion des tâches | Gère l’ensemble du pipeline de ML, y compris l’ordonnancement des tâches. | Accélère des tâches spécifiques du pipeline comme les multiplications matricielles dans les réseaux de neurones. |
| Parallélisation | Traitement parallèle limité ; gère mieux les tâches séquentielles. | Conçu pour le parallélisme ; excelle dans les tâches nécessitant un haut débit, comme l’entraînement de modèles de deep learning. |
| Configuration idéale | Idéal en combinaison avec des GPU pour la gestion et l’orchestration du système. | Idéal pour les tâches informatiquement intensives comme l’entraînement et l’inférence de modèles. |
| Rôle dans le workflow | Supervise le workflow de ML, gérant des tâches telles que le chargement et la préparation des données. | Accélère les tâches centrales de ML en effectuant des calculs mathématiques complexes. |
Facteurs clés à considérer lors de la sélection du meilleur GPU pour le deep learning

Cœurs CUDA et Tenseurs
Les cœurs CUDA (Compute Unified Device Architecture) de NVIDIA et les cœurs Tensor sont cruciaux pour les performances en deep learning. Les cœurs CUDA gèrent le calcul parallèle à usage général, tandis que les cœurs Tensor sont spécifiquement conçus pour les opérations matricielles courantes en deep learning. Lors de la sélection d’un GPU, tenez compte du nombre et de la génération de ces cœurs, car ils ont un impact direct sur les performances.
Mémoire et bande passante
La mémoire GPU (VRAM) et la bande passante sont cruciales pour gérer efficacement de grands ensembles de données et des modèles complexes. Lors de la sélection d’un GPU pour le machine learning, privilégiez ceux ayant une capacité mémoire élevée (16 Go ou plus) et une bande passante mémoire élevée pour garantir un traitement fluide des tâches à grande échelle. Une VRAM suffisante permet au GPU de stocker et d’accéder rapidement à de grandes quantités de données, tandis qu’une bande passante élevée assure un transfert rapide des données entre le GPU et la mémoire, minimisant les goulots d’étranglement lors de l’entraînement et de l’inférence des modèles.
Performances et TFLOPS
Les TFLOPS (Trillion Floating Point Operations Per Second) sont une métrique essentielle pour évaluer les performances des GPU en machine learning. Une valeur TFLOPS plus élevée indique généralement une puissance de calcul supérieure, en particulier lors de l’entraînement de grands modèles ou du traitement de tâches complexes. Les GPU avec des TFLOPS plus élevés peuvent traiter plus d’opérations par seconde, ce qui se traduit par un entraînement plus rapide des modèles et une amélioration globale des performances dans les charges de travail exigeantes de machine learning.
Compatibilité et évolutivité
Assurez-vous que le GPU est compatible avec votre matériel et votre pile logicielle existants. De plus, considérez son évolutivité future, comme la capacité à prendre en charge plusieurs GPU en parallèle, ce qui est essentiel pour gérer des projets de machine learning plus exigeants à mesure que vos besoins augmentent.
Alimentation et refroidissement
Les GPU hautes performances nécessitent une alimentation substantielle et génèrent une chaleur importante. Une puissance insuffisante peut provoquer une instabilité, tandis qu’un refroidissement inadéquat peut entraîner un étranglement thermique, réduisant l’efficacité du GPU et potentiellement endommager le matériel à long terme. Assurez-vous que votre système est équipé des solutions d’alimentation et de refroidissement appropriées pour répondre aux exigences des GPU hautes performances.
Coût et retour sur investissement
Pesez vos besoins spécifiques et votre budget. Les GPU haut de gamme offrent d’excellentes performances mais ont un coût élevé. Pour les tâches intensives, les GPU premium valent l’investissement, mais pour des charges de travail plus légères, une option plus abordable peut suffire. Tenez compte à la fois des coûts initiaux et de la valeur à long terme.
Écosystème logiciel et prise en charge des frameworks
Assurez la compatibilité avec les frameworks de machine learning populaires tels que TensorFlow, PyTorch et CUDA. Un écosystème logiciel solide peut grandement améliorer à la fois la productivité et les performances.
Configurations multi-GPU
Pour les projets à grande échelle, envisagez des GPU qui prennent en charge des configurations multi-GPU efficaces, permettant un entraînement distribué, des temps de traitement plus rapides et la capacité de faire évoluer les charges de travail sans compromettre les performances.
Types de GPU : trouver le choix idéal pour vos projets de machine learning
GPU grand public
Les GPU grand public, comme la série NVIDIA GeForce RTX, offrent un bon équilibre entre performances et coût pour les chercheurs individuels et les projets à petite échelle. Ils fournissent une puissance de calcul substantielle à un prix plus accessible.
GPU professionnels
Les GPU professionnels, comme la série NVIDIA Quadro, sont conçus pour les stations de travail et offrent des fonctionnalités telles que la mémoire ECC pour une fiabilité accrue. Ils conviennent aux environnements professionnels nécessitant à la fois des capacités de ML et un traitement graphique traditionnel.
GPU pour centre de données
Les GPU pour centre de données, comme le NVIDIA A100, sont conçus pour les opérations de ML à grande échelle dans les environnements serveurs. Ils offrent les plus hautes performances et sont conçus pour fonctionner 24h/24 et 7j/7 dans les centres de données.
GPU cloud
Les services de GPU cloud, comme ceux proposés par Novita AI, offrent un accès flexible et évolutif aux ressources GPU, éliminant ainsi le besoin d’investissement matériel initial. Ils sont parfaits pour les projets avec des demandes de calcul fluctuantes ou pour tester avant de s’engager dans des achats matériels à long terme, offrant rentabilité et adaptabilité.
Meilleurs GPU pour le deep learning : une comparaison complète
NVIDIA A100
Le NVIDIA A100 est une centrale électrique pour l’IA et le deep learning, offrant des performances exceptionnelles avec ses cœurs Tensor de 3e génération. Il fournit jusqu’à 624 TFLOPS de performances FP16 et dispose de 80 Go de mémoire à large bande passante, ce qui le rend idéal pour les charges de travail de ML les plus exigeantes.
NVIDIA RTX 3090
Le RTX 3090 offre un excellent équilibre entre performances et coût pour les tâches de deep learning. Avec 24 Go de mémoire GDDR6X et des cœurs RT de 2e génération, c’est un choix populaire pour les chercheurs et les petites équipes.
NVIDIA RTX 4090
Le RTX 4090 représente la dernière technologie de GPU grand public, offrant des améliorations significatives par rapport à ses prédécesseurs. Il dispose de cœurs Tensor de 4e génération et de 24 Go de mémoire GDDR6X, ce qui en fait une option puissante pour les applications de deep learning.
NVIDIA RTX 6000
Le RTX 6000 est un GPU de qualité professionnelle qui combine la puissance de l’architecture Ampere de NVIDIA avec 48 Go de mémoire, ce qui le rend adapté aux modèles de ML complexes et aux grands ensembles de données.
AMD Instinct MI250X
L’offre d’AMD dans le domaine du calcul haute performance, l’Instinct MI250X, fournit des performances compétitives pour les tâches de deep learning. Il dispose de 128 Go de mémoire HBM2e et offre jusqu’à 383 TFLOPS de performances FP16.
Comment louer une instance GPU sur Novita AI
Novita AI est à l’avant-garde de la fourniture de services GPU cloud avancés, permettant aux entreprises et aux chercheurs d’exploiter le calcul haute performance pour le ML. En offrant un accès évolutif et flexible à du matériel de pointe, Novita AI permet le traitement efficace de tâches de ML complexes sans nécessiter d’investissements matériels initiaux substantiels. Cette capacité est cruciale pour accélérer l’innovation et optimiser les processus d’entraînement des modèles.
Novita AI optimise les performances des modèles de ML en donnant accès à des GPU haut de gamme, tels que le RTX 4090 et l’A100, idéaux pour l’entraînement de modèles à grande échelle. Les services cloud permettent aux utilisateurs d’augmenter ou de réduire la capacité de manière transparente en fonction des exigences de calcul de leurs projets. Cette flexibilité garantit une allocation efficace des ressources, améliorant la vitesse de traitement et réduisant les coûts.
Pour commencer avec Novita AI
Pour commencer à utiliser Novita AI pour vos projets de machine learning :
Étape 1 : Créer un compte
Si vous êtes nouveau sur Novita AI, commencez par créer un compte sur notre site Web. Une fois inscrit avec succès, rendez-vous dans l’onglet « GPUs » pour explorer les ressources disponibles et commencer votre parcours.
Essayez Novita AI dès maintenant
Étape 2 : Explorer les modèles et les serveurs GPU
Commencez par sélectionner un modèle adapté aux besoins de votre projet, comme PyTorch, TensorFlow ou CUDA. Vous pouvez choisir la version qui correspond le mieux à vos exigences, par exemple PyTorch 2.2.1 ou Cuda 11.8.0. Ensuite, choisissez une configuration de serveur GPU, par exemple le RTX 4090 ou l’A100 SXM4, avec différentes capacités de VRAM, RAM et disque pour correspondre à la charge de travail de votre projet.
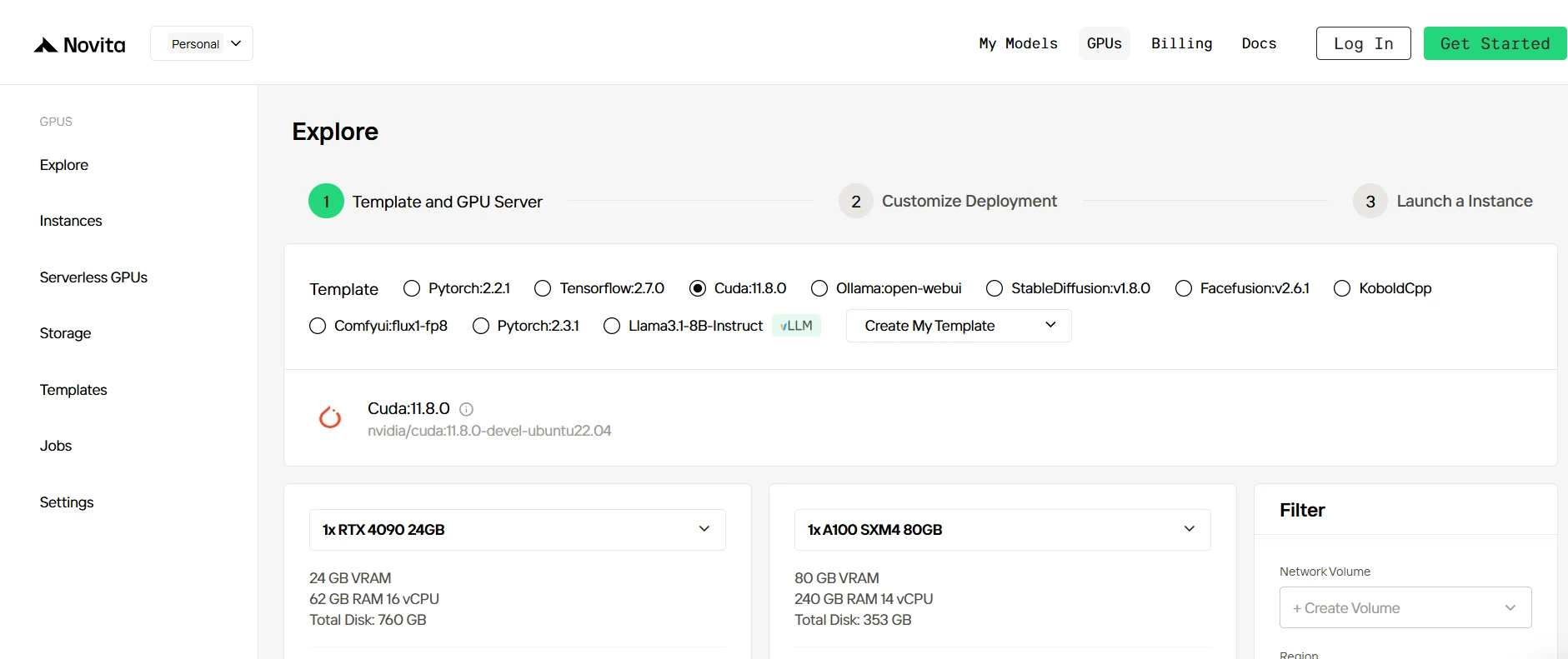
Essayez les GPU haute performance de Novita AI
Étape 3 : Personnaliser votre déploiement
Une fois que vous avez sélectionné un modèle et un GPU, vous pouvez personnaliser les paramètres de déploiement. Ajustez des paramètres comme la version du système d’exploitation (par exemple, CUDA 11.8), ainsi que d’autres paramètres pour affiner l’environnement en fonction des besoins de votre projet.

Étape 4 : Lancer une instance
Après avoir finalisé le modèle et les paramètres de déploiement, cliquez sur « Launch Instance » pour configurer votre instance GPU. Cela préparera l’environnement et vous permettra de commencer à utiliser les ressources GPU pour vos tâches de machine learning.

Conclusions
Choisir le bon GPU pour le machine learning en 2025 nécessite un examen attentif de divers facteurs, notamment les performances, la mémoire, le coût et les exigences spécifiques du projet. Alors que NVIDIA continue de dominer le marché avec son écosystème CUDA et ses offres hautes performances, des concurrents comme AMD font des progrès significatifs. Les services GPU cloud et les plateformes comme Novita AI offrent des alternatives flexibles aux investissements matériels traditionnels. Alors que le domaine du machine learning continue de progresser, rester informé des dernières technologies GPU et de leurs applications sera crucial pour les chercheurs et les organisations qui souhaitent rester à la pointe de l’innovation en IA.
Questions fréquemment posées
Les plateformes GPU cloud sont-elles bénéfiques pour le deep learning ?
Oui, les plateformes GPU cloud offrent flexibilité et évolutivité, permettant aux utilisateurs de louer des GPU puissants à la demande, ce qui peut être utile pour les start-ups, les chercheurs et les entreprises.
Vaut-il la peine d’utiliser des GPU plus anciens pour le deep learning ?
Bien que les GPU plus anciens puissent être utilisés pour le deep learning, les modèles plus récents offrent de meilleures performances, en particulier pour les grands modèles complexes. Les GPU plus anciens peuvent avoir des limitations en termes de mémoire, de vitesse et de prise en charge des nouvelles technologies. Cependant, pour les modèles plus petits ou pour ceux qui débutent, des GPU plus anciens comme le GeForce GTX 1070 ou le RTX 2080 Ti peuvent être suffisants et plus abordables.
Comment puis-je garder mon GPU au frais lors de l’exécution de tâches de machine learning ?
Un refroidissement efficace est essentiel, surtout lors de l’exécution de plusieurs GPU. Le refroidissement par air peut être suffisant s’il y a suffisamment d’espace entre les GPU. Les GPU de type soufflante peuvent également fonctionner sans refroidissement par eau. Lorsque l’espace est limité ou que plusieurs GPU haute puissance sont utilisés, un refroidissement par eau peut être nécessaire, bien qu’il puisse être peu fiable et doit être effectué avec prudence.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA en utilisant notre API simple, tout en fournissant également un cloud GPU abordable et fiable pour construire et faire évoluer.
Lectures recommandées
What is GPU Cloud: A Comprehensive Guide
Decoding “What Does TI Mean in GPU”: Understanding GPU Terminology



