

主なハイライト
GPUの利点 :GPUは並列アーキテクチャにより、MLタスクをCPUの最大100倍の速度で処理するため、機械学習タスクに不可欠です。
重要なスペック :GPUを選ぶ際は、CUDAコア、メモリ、帯域幅、TFLOPSに注目してください。
ソフトウェア互換性 :主要なMLフレームワークとCUDAのサポートを確認してください。
GPUの種類 :ニーズに応じて、コンシューマー向け、プロフェッショナル向け、データセンター向け、またはクラウドGPUを選択します。
トップパフォーマー :2025年は、NVIDIA A100、RTX 3090、RTX 4090、AMD Instinct MI250Xがリードしています。
クラウドオプション :ハードウェアへの先行投資なしで柔軟性を提供します。
2025年、機械学習の分野はますます複雑化するアルゴリズムと巨大なデータセットを支えるため、より強力なハードウェアを必要としながら急速に進化し続けています。この技術革命の中心にあるのが、AIと機械学習の状況を一変させた重要なコンポーネントであるGPU(Graphics Processing Unit)です。本ガイドでは、最新の進歩と市場動向を考慮した、GPU選択の包括的な概要を提供します。
なぜGPUが機械学習に不可欠なのか:パフォーマンス、スピード、効率

並列処理がGPUによる機械学習を加速する方法
GPUは、並列処理アーキテクチャによって機械学習に革命をもたらします。CPUは少数の強力なコアで逐次処理を得意とする一方、GPUは数千もの小さなコアを活用して無数の計算を同時に実行します。このアーキテクチャの違いは、機械学習のワークロードにおいて決定的に重要です。
主な利点:
- 行列演算:ニューラルネットワーク計算に不可欠な大規模行列とテンソルをGPUが効率的に処理。
- バッチ処理:複数のデータサンプルを同時に処理でき、学習速度を加速。
- ベクトル計算:並列コアがMLアルゴリズムの基本となるベクトル演算を処理。
GPUの恩恵を受ける一般的な機械学習タスク
GPUは現代の機械学習において不可欠な存在となり、いくつかの主要な計算タスクを劇的に加速しています。以下に、GPUが卓越したパフォーマンスを発揮する主なMLアプリケーションを詳しく説明します。
-
ディープラーニングモデルの訓練
- 複雑なニューラルアーキテクチャの訓練を加速
- 多層にわたる効率的なバックプロパゲーションを実現
- モデルアーキテクチャの迅速な実験を促進
- 訓練時間を数週間から数時間または数日に短縮
-
ニューラルネットワーク推論
- 本番環境でのリアルタイム予測を可能に
- 高スループットのバッチ処理をサポート
- レイテンシが重要なアプリケーションでのモデル提供に不可欠
- 大規模なデプロイメントに特に効果的
-
画像・動画処理
- コンピュータビジョンのための高速な畳み込み演算を実現
- リアルタイムの動画解析・処理を可能に
- 画像分類や物体検出を加速
- セマンティックセグメンテーションなどの高度なタスクをサポート
-
自然言語処理
- トランスフォーマーモデルの計算を加速
- アテンションメカニズムの効率的な処理を実現
- テキスト生成・翻訳タスクを高速化
- 大規模言語モデルの訓練に不可欠
-
強化学習
- 並列環境シミュレーションを促進
- 方策最適化の計算を加速
- 複雑なゲームシミュレーションを実現
- 並列化による迅速なエージェント訓練をサポート
これらのタスクは、以下のために最適化されたGPUの特殊なアーキテクチャから大きな恩恵を受けます。
- 効率的な行列乗算
- 高速な畳み込み演算
- 並列テンソル計算
- データ移動のための高メモリ帯域幅
これらの機能を活用することで、GPUはMLアルゴリズムの基礎となる数学演算を従来のCPUより桁違いに高速に処理でき、以前は実現不可能だったアプリケーションを実用的かつ費用対効果の高いものにします。
CPU vs GPU:機械学習タスクにはどちらが優れているか?
機械学習タスクにおいて、CPUとGPUはどちらも重要な役割を果たしますが、それぞれ異なる分野で優れています。以下の表は、機械学習ワークフローにおけるCPUとGPUの役割と強みを比較したもので、最適なパフォーマンスを得るための選択と組み合わせ方を理解するのに役立ちます。
| 観点 | CPU | GPU |
| 主な役割 | 汎用コンピューティング | 機械学習タスクにおける並列処理に特化 |
| MLタスクの速度 | 計算負荷の高いタスクでは低速 | ニューラルネットワークの訓練など特定のMLタスクで最大100倍高速 |
| 強み | 逐次タスク、データ前処理、タスク調整に効率的 | モデル訓練や推論などの大規模並列タスクに効率的 |
| データ前処理 | データクリーニング、特徴抽出、タスク調整を処理 | データ前処理タスクには不向き |
| タスク管理 | タスクスケジューリングを含むMLパイプライン全体を管理 | ニューラルネットワークの行列乗算など、パイプライン内の特定タスクを加速 |
| 並列化 | 並列処理は限定的。逐次タスクを得意とする | 並列性を備え、ディープラーニングモデルの訓練など高スループットを要するタスクに優れる |
| 理想的な設定 | システム管理と調整のためにGPUと組み合わせて使用するのが最適 | モデル訓練や推論など計算負荷の高いタスクに最適 |
| ワークフローでの役割 | データ読み込みや準備などのタスクを管理し、MLワークフローを統括 | 複雑な数学計算を実行してコアMLタスクを高速化 |
ディープラーニングに最適なGPUを選ぶ際の重要な要素

CUDA & Tensor Cores
NVIDIAのCUDA(Compute Unified Device Architecture)コアとTensorコアは、ディープラーニングのパフォーマンスにとって極めて重要です。CUDAコアは汎用並列計算を処理し、Tensorコアはディープラーニングで一般的な行列演算に特化して設計されています。GPUを選択する際は、これらのコアの数と世代を考慮してください。パフォーマンスに直接影響します。
メモリと帯域幅
GPUメモリ(VRAM)と帯域幅は、大規模なデータセットや複雑なモデルを効率的に処理するために極めて重要です。機械学習用のGPUを選ぶ際は、大規模タスクのスムーズな処理を確保するために、大容量メモリ(16GB以上)と高いメモリ帯域幅を備えたものを優先しましょう。十分なVRAMがあれば、GPUは大量のデータを迅速に保存・アクセスでき、高い帯域幅はGPUとメモリ間の高速データ転送を保証し、モデル訓練や推論時のボトルネックを最小限に抑えます。
パフォーマンスとTFLOPS
TFLOPS(1秒あたりの浮動小数点演算数、Trillion Floating Point Operations Per Second)は、機械学習におけるGPUのパフォーマンスを評価するための重要な指標です。TFLOPS値が高いほど、特に大規模モデルの訓練や複雑なタスクを扱う際に、優れた計算能力を示します。TFLOPSの高いGPUは、1秒あたりより多くの演算を処理できるため、モデル訓練の高速化と、要求の厳しい機械学習ワークロードにおける全体的なパフォーマンスの向上につながります。
互換性とスケーラビリティ
GPUが既存のハードウェアおよびソフトウェアスタックと互換性があることを確認してください。また、将来的なスケーラビリティ、例えば複数のGPUを並列でサポートできるかどうかも検討しましょう。これは、ニーズの拡大に伴い、より要求の厳しい機械学習プロジェクトを処理するために不可欠です。
電力と冷却
高性能GPUはかなりの電力を必要とし、大きな熱を発生します。電力が不十分だと不安定性を引き起こし、冷却が不十分だとサーマルスロットリングが発生してGPUの効率が低下し、長期的にはハードウェアを損傷する可能性があります。高性能GPUの要求に対応できる適切な電源と冷却ソリューションがシステムに搭載されていることを確認してください。
コストとROI
特定のニーズと予算を比較検討してください。ハイエンドGPUは優れたパフォーマンスを提供しますが、コストも高くなります。集中的なタスクにはプレミアムGPUへの投資価値がありますが、軽いワークロードにはより手頃なオプションで十分かもしれません。初期コストと長期的な価値の両方を考慮してください。
ソフトウェアエコシステムとフレームワークのサポート
TensorFlow、PyTorch、CUDAなどの一般的な機械学習フレームワークとの互換性を確保してください。強力なソフトウェアエコシステムは、生産性とパフォーマンスを大幅に向上させることができます。
マルチGPUセットアップ
大規模プロジェクトの場合は、効率的なマルチGPU構成をサポートするGPUを検討してください。これにより、分散訓練、処理時間の短縮、パフォーマンスを損なうことなくワークロードを拡張する能力が可能になります。
GPUの種類:機械学習プロジェクトに最適なマッチング
コンシューマーGPU
NVIDIAのGeForce RTXシリーズなどのコンシューマーGPUは、個人研究者や小規模プロジェクト向けに、パフォーマンスとコストの適切なバランスを提供します。これらは、より手頃な価格でかなりの計算能力を提供します。
プロフェッショナルGPU
NVIDIAのQuadroシリーズなどのプロフェッショナルGPUは、ワークステーション向けに設計されており、ECCメモリなどの信頼性を高める機能を備えています。ML機能と従来のグラフィックス処理の両方を必要とするプロフェッショナル環境に適しています。
データセンターGPU
NVIDIAのA100などのデータセンターGPUは、サーバー環境での大規模ML運用向けに構築されています。これらは最高のパフォーマンスを提供し、データセンターでの24時間365日の運用向けに設計されています。
クラウドGPU
Novita AIが提供するようなクラウドGPUサービスは、柔軟でスケーラブルなGPUリソースへのアクセスを提供し、ハードウェアへの先行投資を不要にします。変動する計算需要のあるプロジェクトや、長期のハードウェア購入前にテストしたい場合に最適で、コスト効率と適応性を提供します。
ディープラーニングに最適なGPU:包括的な比較
NVIDIA A100
NVIDIA A100は、第3世代Tensorコアを搭載し、AIおよびディープラーニング向けのパワーハウスです。FP16パフォーマンスで最大624 TFLOPSを提供し、80GBの高帯域幅メモリを搭載しており、最も要求の厳しいMLワークロードに最適です。
NVIDIA RTX 3090
RTX 3090は、ディープラーニングタスクにおいてパフォーマンスとコストの優れたバランスを提供します。24GBのGDDR6Xメモリと第2世代RTコアを搭載しており、研究者や小規模チームに人気の選択肢です。
NVIDIA RTX 4090
RTX 4090は、コンシューマーGPU技術の最新を代表し、前世代から大幅な改良を加えています。第4世代Tensorコアと24GBのGDDR6Xメモリを搭載し、ディープラーニングアプリケーションに強力なオプションです。
NVIDIA RTX 6000
RTX 6000はプロフェッショナルグレードのGPUで、NVIDIAのAmpereアーキテクチャのパワーと48GBのメモリを組み合わせ、複雑なMLモデルや大規模データセットに適しています。
AMD Instinct MI250X
ハイパフォーマンスコンピューティング分野におけるAMDの製品であるInstinct MI250Xは、ディープラーニングタスクで競争力のあるパフォーマンスを提供します。128GBのHBM2eメモリを搭載し、FP16パフォーマンスで最大383 TFLOPSを提供します。
Novita AIでGPUインスタンスをレンタルする方法
Novita AIは、先進的なクラウドベースのGPUサービスの最前線に立ち、企業や研究者がMLのためにハイパフォーマンスコンピューティングを活用できるようにしています。スケーラブルで柔軟な最先端ハードウェアへのアクセスを提供することで、Novita AIは多額のハードウェア先行投資を必要とせずに、複雑なMLタスクの効率的な処理を可能にします。この機能は、イノベーションを加速し、モデル訓練プロセスを最適化するために不可欠です。
Novita AIは、RTX 4090やA100などのハイエンドGPUへのアクセスを提供することで、MLモデルのパフォーマンスを最適化します。これらのGPUは、大規模モデルの訓練に最適です。クラウドサービスにより、ユーザーはプロジェクトの計算要件に応じてシームレスにスケールアップまたはスケールダウンできます。この柔軟性により、リソースが効率的に割り当てられ、処理速度が向上し、コストが削減されます。
Novita AIの始め方
機械学習プロジェクトでNovita AIを使用するには、以下の手順に従ってください。
ステップ1:アカウント登録
Novita AIが初めての方は、ウェブサイトでアカウントを作成してください。正常に登録できたら、「[GPUs](https://novita.ai/gpus/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Choosing the Best GPU for Machine Learning in 2025: A Complete Guide)」タブに移動して、利用可能なリソースを確認し、旅を始めましょう。
[今すぐNovita AIを試す](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Choosing the Best GPU for Machine Learning in 2025: A Complete Guide)
ステップ2:テンプレートとGPUサーバーの探索
まず、プロジェクトのニーズに合ったテンプレート(PyTorch、TensorFlow、CUDAなど)を選択します。要件に最適なバージョン(PyTorch 2.2.1やCuda 11.8.0など)を選べます。次に、GPUサーバーの構成を選択します。例えば、RTX 4090やA100 SXM4など、VRAM、RAM、ディスク容量が異なるものをワークロードの需要に合わせて選びます。
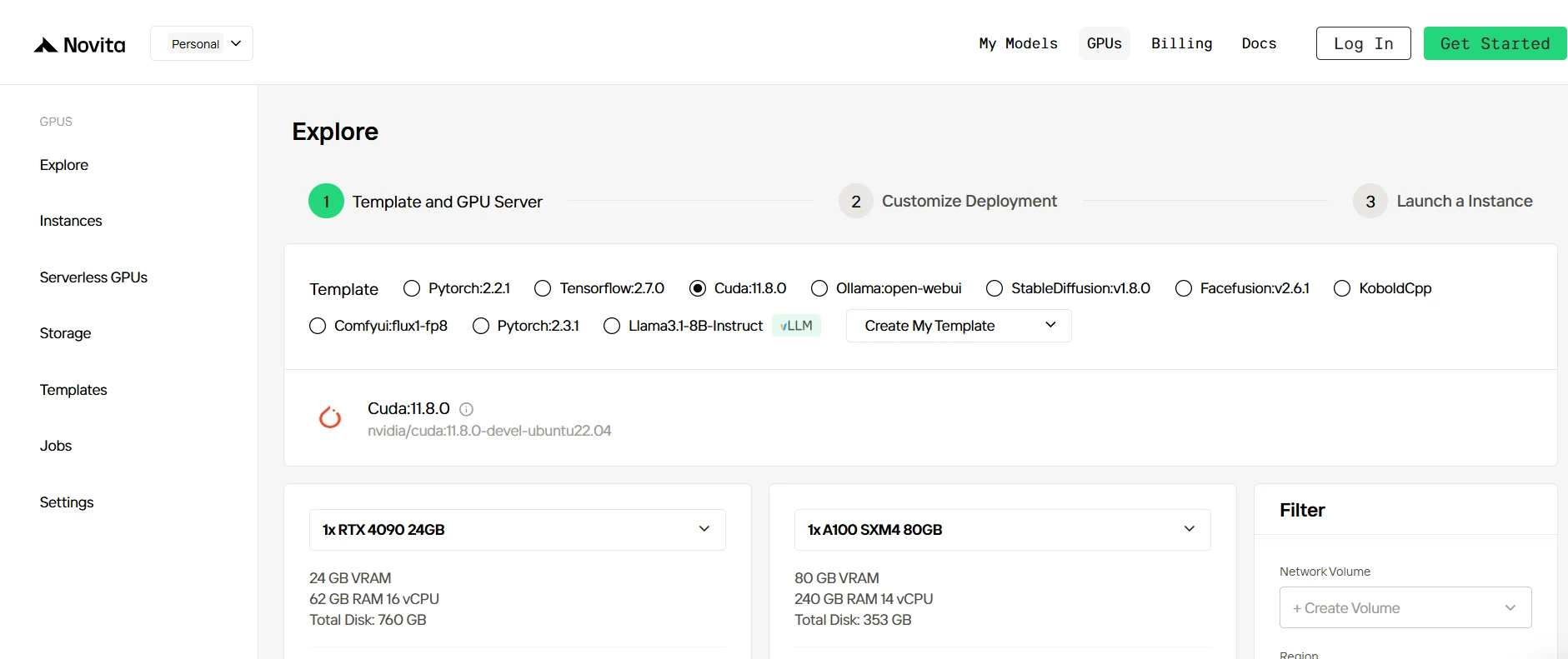
[Novita AIの高性能GPUを試す](https://novita.ai/gpus-console/?utm_source=blogs_GPU&utm_medium=article&utm_campaign= Choosing the Best GPU for Machine Learning in 2025: A Complete Guide)
ステップ3:デプロイのカスタマイズ
テンプレートとGPUを選択したら、デプロイメント設定をカスタマイズできます。オペレーティングシステムのバージョン(例:CUDA 11.8)などのパラメーターや、その他の設定を調整して、プロジェクトのニーズに応じて環境を微調整します。

ステップ4:インスタンスの起動
テンプレートとデプロイメント設定を確定したら、「Launch Instance(インスタンスを起動)」をクリックしてGPUインスタンスをセットアップします。これにより環境が準備され、機械学習タスクにGPUリソースの利用を開始できます。

結論
2025年に機械学習向けの適切なGPUを選択するには、パフォーマンス、メモリ、コスト、特定のプロジェクト要件など、さまざまな要素を慎重に考慮する必要があります。NVIDIAはCUDAエコシステムと高性能製品で市場を支配し続けていますが、AMDなどの競合も重要な進歩を遂げています。Novita AIのようなクラウドGPUサービスやプラットフォームは、従来のハードウェア投資に代わる柔軟な選択肢を提供します。機械学習の分野が進歩し続ける中、AIイノベーションの最前線に立ちたい研究者や組織にとって、最新のGPU技術とそのアプリケーションについて情報を得ることが極めて重要です。
よくある質問
クラウドGPUプラットフォームはディープラーニングに役立ちますか?
はい、クラウドGPUプラットフォームは柔軟性とスケーラビリティを提供し、ユーザーはオンデマンドで強力なGPUをレンタルできます。これはスタートアップ、研究者、企業にとって有益です。
古いGPUをディープラーニングに使用する価値はありますか?
古いGPUでもディープラーニングに使用できますが、特に大規模で複雑なモデルには、新しいモデルの方が優れたパフォーマンスを発揮します。古いGPUは、メモリ、速度、新しいテクノロジーのサポートに制限がある場合があります。ただし、小規模なモデルや初心者には、GeForce GTX 1070やRTX 2080 Tiのような古いGPUでも十分であり、より手頃な価格です。
機械学習タスク実行中にGPUを涼しく保つにはどうすればよいですか?
効果的な冷却は不可欠です。特に複数のGPUを実行する場合です。GPU間に十分なスペースがあれば、空冷で十分な場合があります。ブロワースタイルのGPUは、水冷なしでも機能します。スペースが限られている場合や、複数の高出力GPUを使用する場合は、水冷が必要になることがありますが、信頼性が低い可能性があるため、注意して行う必要があります。
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Choosing the Best GPU for Machine Learning in 2025: A Complete Guide)は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるようにするとともに、手頃な価格で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。
おすすめの記事



