

重點摘要
GPU 優勢:GPU 憑藉其平行架構,處理機器學習任務的速度比 CPU 快上 100 倍,是機器學習任務不可或缺的核心硬體。
關鍵規格:選擇 GPU 時應著重 CUDA 核心數、記憶體容量、頻寬及 TFLOPS。
軟體相容性:確認支援主流機器學習框架與 CUDA。
GPU 類型:根據需求選擇消費級、專業級、資料中心或雲端 GPU。
頂尖效能:NVIDIA A100、RTX 3090、RTX 4090 與 AMD Instinct MI250X 是 2025 年的領導者。
雲端選項:提供彈性,無需前期硬體投資。
2025 年,機器學習領域持續快速演進,需要越來越強大的硬體來支援複雜的演算法與海量資料集。這場技術革命的核心是圖形處理器(GPU),這項關鍵元件徹底改變了 AI 與機器學習的樣貌。本指南將考量最新進展與市場趨勢,提供全面的 GPU 選購建議。
為何 GPU 對機器學習至關重要:效能、速度與效率

平行處理如何以 GPU 加速機器學習
GPU 透過其平行處理架構徹底改變了機器學習。CPU 憑藉少數強大核心擅長序列任務,而 GPU 則利用數千個較小的核心同時進行無數計算。這種架構差異對機器學習工作負載至關重要:
主要優勢:
- 矩陣運算:GPU 高效處理大型矩陣與張量,對神經網路計算至關重要
- 批次處理:可同時處理多個資料樣本,加速訓練速度
- 向量計算:平行核心處理機器學習演算法所必需的向量運算
受益於 GPU 的常見機器學習任務
GPU 已成為現代機器學習不可或缺的工具,能大幅加速多項關鍵計算任務。以下詳細說明 GPU 展現卓越效能的主要機器學習應用:
- 深度學習模型訓練
- 加速複雜神經架構的訓練
- 實現跨多層的高效反向傳播
- 促進模型架構的快速實驗
- 將訓練時間從數週縮短至數小時或數天
- 神經網路推論
- 在生產環境中實現即時預測
- 支援高吞吐量的批次處理
- 對延遲敏感的應用至關重要
- 尤其適用於大規模部署
- 影像與影片處理
- 為電腦視覺提供快速的卷積運算
- 實現即時影片分析與處理
- 加速影像分類與物體偵測
- 支援語意分割等進階任務
- 自然語言處理
- 加速 Transformer 模型計算
- 實現注意力機制的高效處理
- 加快文字生成與翻譯任務
- 對訓練大型語言模型至關重要
- 強化學習
- 促進平行環境模擬
- 加速策略最佳化計算
- 支援複雜遊戲模擬
- 透過平行化實現快速智能體訓練
這些任務因 GPU 的專用架構而受益良多,其最佳化方向包括:
- 高效矩陣乘法
- 快速卷積運算
- 平行張量計算
- 高記憶體頻寬的資料移動能力
透過善用這些能力,GPU 處理機器學習演算法基本數學運算的速度比傳統 CPU 快上數個數量級,使過去不可行的應用變得可行且符合成本效益。
CPU 與 GPU:機器學習任務誰更適合?
在機器學習任務中,CPU 與 GPU 都扮演關鍵角色,但各有擅長領域。下表比較 CPU 與 GPU 在機器學習工作流程中的角色與優勢,幫助您了解如何選擇與結合兩者以獲得最佳效能。
| 面向 | CPU | GPU |
| 主要角色 | 通用計算 | 專為機器學習任務中的平行處理而設計 |
| 機器學習任務速度 | 計算密集型任務較慢 | 針對特定機器學習任務(如訓練神經網路),資料處理速度可快達 100 倍 |
| 優勢 | 擅長序列任務、資料前處理與任務協調 | 擅長大規模平行任務,如模型訓練與推論 |
| 資料前處理 | 處理資料清理、特徵萃取與任務協調 | 不適合資料前處理任務 |
| 任務管理 | 管理整體機器學習管線,包括任務排程 | 加速管線中的特定任務,如神經網路中的矩陣乘法 |
| 平行化 | 平行處理能力有限;較擅長序列任務 | 專為平行化設計;擅長高吞吐量任務,如訓練深度學習模型 |
| 理想配置 | 最佳做法是與 GPU 搭配使用,負責系統管理與協調 | 最佳做法是負責計算密集型任務,如模型訓練與推論 |
| 工作流程角色 | 監督機器學習工作流程,管理資料載入與準備等任務 | 透過執行複雜數學計算來加速核心機器學習任務 |
選擇深度學習最佳 GPU 的關鍵考量因素

CUDA 與 Tensor 核心
NVIDIA 的 CUDA(統一計算裝置架構)核心與 Tensor 核心對深度學習效能至關重要。CUDA 核心處理通用平行計算,而 Tensor 核心專為深度學習常見的矩陣運算設計。選擇 GPU 時,應考慮這些核心的數量與世代,因為它們直接影響效能。
記憶體與頻寬
GPU 記憶體(VRAM)與頻寬對於高效處理大型資料集與複雜模型至關重要。選擇機器學習用 GPU 時,應優先考慮高記憶體容量(16GB 以上)與高記憶體頻寬,以確保大型任務順暢處理。充足的 VRAM 可讓 GPU 快速儲存與存取大量資料,而高頻寬則確保 GPU 與記憶體之間的快速資料傳輸,減少模型訓練與推論過程中的瓶頸。
效能與 TFLOPS
TFLOPS(每秒兆次浮點運算)是評估 GPU 在機器學習中效能的關鍵指標。較高的 TFLOPS 值通常代表更強大的運算能力,尤其在訓練大型模型或處理複雜任務時。TFLOPS 越高的 GPU 每秒可處理更多運算,這意味著模型訓練更快,以及在要求嚴苛的機器學習工作負載中獲得更好的整體效能。
相容性與可擴充性
確保 GPU 與您現有的硬體及軟體堆疊相容。此外,考慮其未來的可擴充性,例如支援多 GPU 平行運作的能力,這對於因應日後更嚴苛的機器學習專案至關重要。
電源與散熱
高效能 GPU 需要大量電力並產生大量熱能。電源不足會導致不穩定,而散熱不佳可能導致熱節流,降低 GPU 效率,甚至長期損害硬體。請確保您的系統配備適當的電源與散熱解決方案,以滿足高效能 GPU 的需求。
成本與投資回報率
權衡您的特定需求與預算。高階 GPU 效能卓越但價格高昂。對於密集型任務,高階 GPU 值得投資;但對於較輕的工作負載,更經濟的選項可能就足夠了。同時考慮前期成本與長期價值。
軟體生態系與框架支援
確保與主流機器學習框架(如 TensorFlow、PyTorch 及 CUDA)相容。強大的軟體生態系能大幅提升生產力與效能。
多 GPU 配置
對於大型專案,請考慮支援高效多 GPU 配置的 GPU,這能實現分散式訓練、更快的處理時間,以及在無損效能的情況下擴展工作負載的能力。
GPU 類型:為您的機器學習專案找到理想搭配
消費級 GPU
消費級 GPU(如 NVIDIA GeForce RTX 系列)為個人研究人員與小型專案提供了效能與成本的絕佳平衡。它們以更親民的價格提供可觀的運算能力。
專業級 GPU
專業級 GPU(如 NVIDIA Quadro 系列)專為工作站設計,提供 ECC 記憶體等功能以增強可靠性。適合需要機器學習能力與傳統圖形處理的專業環境。
資料中心 GPU
資料中心 GPU(如 NVIDIA A100)專為伺服器環境中的大規模機器學習操作而設計。它們提供最高效能,並針對資料中心全天候運作進行最佳化。
雲端 GPU
雲端 GPU 服務(如 Novita AI 提供的服務)提供靈活、可擴展的 GPU 資源存取,無需前期硬體投資。它們非常適合運算需求波動的專案,或是在投入長期硬體採購前進行測試,提供成本效益與適應性。
深度學習頂尖 GPU 全面比較
NVIDIA A100
NVIDIA A100 是 AI 與深度學習的強大引擎,憑藉其第三代 Tensor 核心提供卓越效能。它提供高達 624 TFLOPS 的 FP16 效能,並配備 80GB 高頻寬記憶體,非常適合最嚴苛的機器學習工作負載。
NVIDIA RTX 3090
RTX 3090 在深度學習任務中提供了效能與成本的絕佳平衡。配備 24GB GDDR6X 記憶體與第二代 RT 核心,是研究人員與小型團隊的熱門選擇。
NVIDIA RTX 4090
RTX 4090 代表消費級 GPU 的最新技術,相較前代產品有顯著改進。它配備第四代 Tensor 核心與 24GB GDDR6X 記憶體,是深度學習應用的強大選項。
NVIDIA RTX 6000
RTX 6000 是專業級 GPU,結合 NVIDIA Ampere 架構的強大效能與 48GB 記憶體,適合複雜的機器學習模型與大型資料集。
AMD Instinct MI250X
AMD 在高性能運算領域的產品 Instinct MI250X,為深度學習任務提供具競爭力的效能。它配備 128GB HBM2e 記憶體,並提供高達 383 TFLOPS 的 FP16 效能。
如何在 Novita AI 租用 GPU 實例
Novita AI 一直致力於提供先進的雲端 GPU 服務,讓企業與研究人員能夠利用高性能運算進行機器學習。透過提供可擴展且靈活的尖端硬體存取,Novita AI 使處理複雜的機器學習任務成為可能,無需大量前期硬體投資。這項能力對於加速創新與最佳化模型訓練流程至關重要。
Novita AI 透過提供高階 GPU(如 RTX 4090 與 A100)的存取,最佳化機器學習模型效能,這些 GPU 非常適合訓練大規模模型。雲端服務允許使用者根據專案的運算需求無縫擴展或縮減資源。這種靈活性確保資源有效配置,提升處理速度並降低成本。
開始使用 Novita AI
要開始將 Novita AI 用於您的機器學習專案:
步驟 1:註冊帳號
如果您是 Novita AI 的新用戶,請先在我們的網站上建立帳號。成功註冊後,前往「GPU」分頁探索可用資源,展開您的旅程。
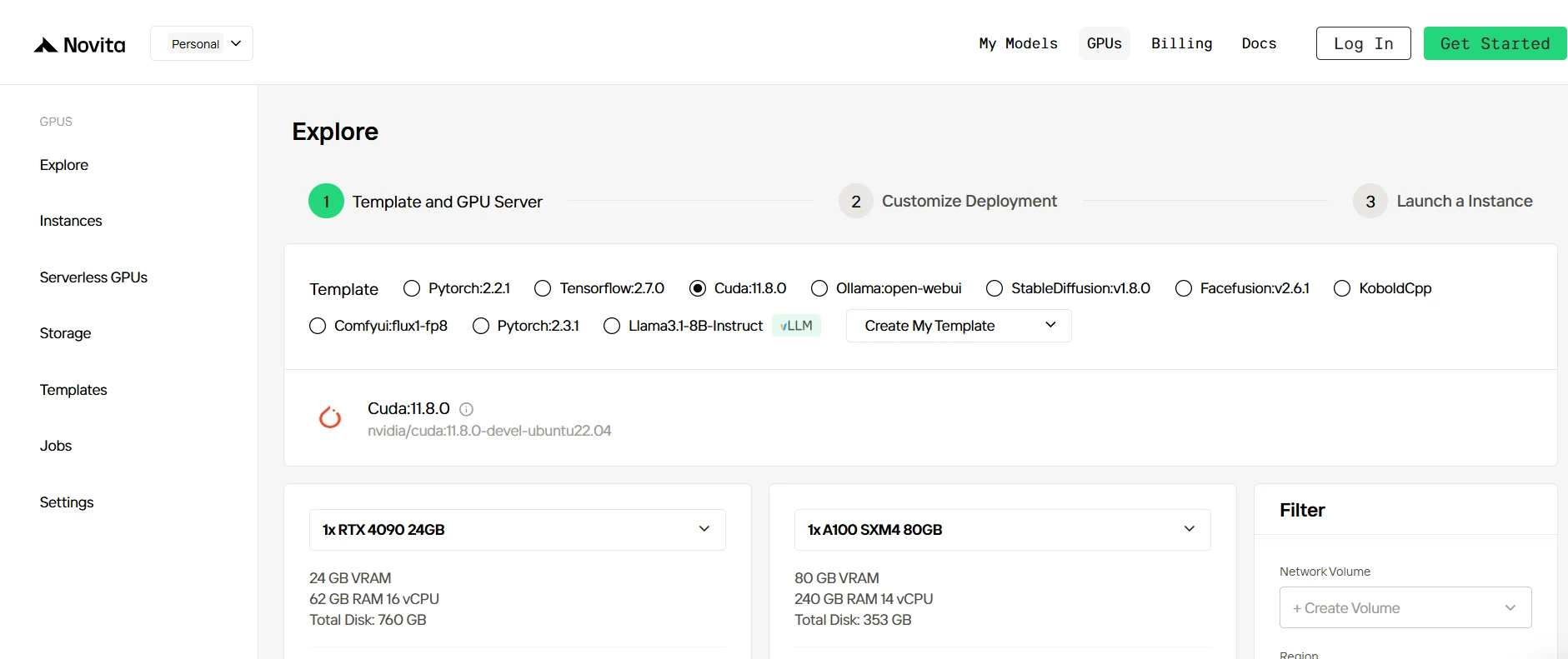
步驟 2:探索範本與 GPU 伺服器
首先選擇符合您專案需求的範本,例如 PyTorch、TensorFlow 或 CUDA。您可以挑選最適合的版本,例如 PyTorch 2.2.1 或 CUDA 11.8.0。接著,選擇 GPU 伺服器配置,例如 RTX 4090 或 A100 SXM4,並根據工作負載需求調整 VRAM、RAM 與磁碟容量。
步驟 3:自訂部署設定
選定範本與 GPU 後,您可以自訂部署設定。調整參數,如作業系統版本(例如 CUDA 11.8),以及其他設定,以根據專案需求微調環境。

步驟 4:啟動實例
完成範本與部署設定後,點擊「啟動實例」以設定您的 GPU 實例。這將準備好環境,讓您開始將 GPU 資源用於機器學習任務。

結論
在 2025 年為機器學習選擇合適的 GPU,需要仔細考量多種因素,包括效能、記憶體、成本及特定專案需求。雖然 NVIDIA 憑藉其 CUDA 生態系與高效能產品持續主導市場,但 AMD 等競爭對手也正大步邁進。雲端 GPU 服務與平台(如 Novita AI)為傳統硬體投資提供了彈性替代方案。隨著機器學習領域持續進步,了解最新的 GPU 技術及其應用,對於想要站在 AI 創新最前線的研究人員與組織來說將至關重要。
常見問題
雲端 GPU 平台對深度學習有益嗎?
是的,雲端 GPU 平台提供靈活性與可擴展性,讓使用者可以按需租用強大的 GPU,這對新創公司、研究人員及企業非常有幫助。
使用舊款 GPU 進行深度學習值得嗎?
雖然舊款 GPU 仍可用於深度學習,但新款 GPU 在大型與複雜模型上效能更佳。舊款 GPU 可能在記憶體、速度及新技術支援上有所限制。不過對於較小的模型或剛入門的使用者,舊款 GPU(如 GeForce GTX 1070 或 RTX 2080 Ti)可能已足夠,且價格更實惠。
如何在執行機器學習任務時為 GPU 散熱?
有效的散熱至關重要,尤其在使用多張 GPU 時。若 GPU 之間有足夠空間,氣冷散熱即可滿足需求。鼓風扇式 GPU 無需水冷也能運作。當空間有限或使用多張高功率 GPU 時,可能需要水冷散熱,但水冷可能較不可靠,應謹慎執行。
Novita AI 是一個 AI 雲端平台,提供開發者透過簡單 API 輕鬆部署 AI 模型,同時提供價格實惠且可靠的 GPU 雲端服務,用於建置與擴展應用。
推薦閱讀



