

Vision Language Models (VLMs) are advanced multimodal AI systems that integrate visual and textual understanding, enabling them to interpret images and text simultaneously. The current landscape of VLMs includes both closed-source options like GPT-4o, Gemini 2.5 Pro, and Claude 3.7 Vision, and open-source models like Qwen 2.5-VL-72B and Llama 4 Scout. Closed-source models often excel at specific tasks but are limited to official platforms, while open-source models provide flexibility, portability, and cost-effectiveness through APIs like Novita AI.
Refer your friends to Novita AI and both of you will earn $10 in LLM API credits—up to $500 in total rewards.
To support the developer community, Qwen2.5 7B, Qwen 3 4B is currently available for free on Novita AI.

What are Vision Language Models (VLMs)?
A Vision Language Model (VLM) is a powerful multimodal AI model that understands both images and text—and generates natural language output. It’s like giving sight to language models.
What Can VLMs Do?
VLMs are incredibly flexible and power a wide range of tasks, such as:
- Visual Document QA – Answering questions based on images of documents
- Image Captioning – Writing descriptive captions for images
- Image Classification – Recognizing and labeling objects in pictures
- Object Detection – Finding where objects are located in an image
How Do VLMs Work?
A typical VLM combines two major components:
- Image Feature Extractor
Usually a pre-trained vision model (like ViT or CLIP) that pulls meaningful features from an image. - Text Decoder
A large language model (LLM) such as LLaMA or Qwen that turns those visual features into human-like text.
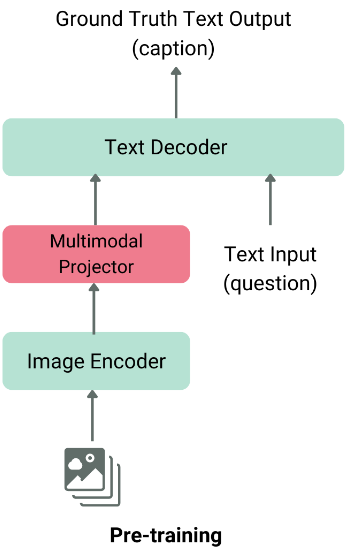
From Clarifai
Comparing Top 5 Large Vision Models in Architecture
| Model | Release date | Avantages | Text context window | Openness / licence |
|---|---|---|---|---|
| GPT 4o | March 2025 | More Efficient Cross-Modal Fusion | 128 k tokens | Closed-source |
| Gemini 2.5 Pro | 6 May 2025 | General-purpose visual tasks | 1 M tokens today; 2 M announced | Served via Google AI Studio |
| Claude 3.7 Vision | 27 Feb 2025 | OCR and chart-focused | 200 k tokens | Closed-source |
| Qwen 2.5-VL-72B | 22 Apr 2025 | Arbitrary resolution, long-video tasks | 128 k tokens | Open-source |
| Llama 4 (Scout / Maverick) | 5 Apr 2025 | Broad multimodal tasks | 1 M – 10 M tokens (Scout advertises 10 M) | Open-source |
Open AI GPT 4o
GPT-4 adopts a fully unified multimodal Transformer architecture, where image patches, audio frames, and text are tokenized and processed in the same sequence, eliminating the need for a separate vision tower.
Advantages
- Simplified Architecture: Without a separate vision tower, the model is more streamlined and unified, reducing complexity.
- More Efficient Cross-Modal Fusion: Processing images and text in the same sequence allows for more natural information integration, improving understanding and generation.
- Stronger Image Generation Capability: This unified design enables the model to convert textual descriptions into high-quality, diverse images with greater accuracy and stylistic richness.
Gemini 2.5 Pro
Gemini 2.5 Pro‘s architecture uses a Frozen SigLIP-ViT tower as the vision encoder. Visual input is pre-encoded independently, linearly projected into the shared Transformer, and integrated with text and other modalities through cross-attention.
Advantages
- Flexibility of Modular Design:
By separating the image pre-encoding process (Frozen SigLIP-ViT), the vision model can be independently optimized or replaced. This allows the Transformer to focus solely on modality fusion, making the modular architecture ideal for flexible iteration or expansion. - Higher Computational Efficiency:
Freezing the weights of the vision encoder eliminates the need to re-optimize the vision component during multimodal training, significantly reducing computational costs, especially when dealing with large-scale visual data. - Optimized for Vision-Centric Tasks:
The vision component can be pre-trained on large-scale image datasets and then integrated with other modalities via lightweight cross-attention, ensuring powerful visual understanding capabilities.
Claude 3.7 Vision
Although the detailed architecture of the visual module has not been officially disclosed, based on the design philosophy of the Claude 3 series and available information, we can infer that its visual processing likely adopts an architecture similar to the following: Claude 3 Vision’s architecture uses a Resampler ViT combined with a lightweight adapter to process visual inputs. Vision tokens are gate-fused directly into the Claude language model backbone, making it optimized for tasks like high-accuracy OCR and chart interpretation.
Advantages
- Modular and Flexible Design:
Frozen SigLIP-ViT functions as an independent vision module, allowing for separate optimization or replacement. This flexibility makes it ideal for adapting to new tasks. In contrast, Resampler ViT is tightly integrated, limiting its adaptability. - Efficient for Large-Scale Vision Tasks:
Freezing the vision encoder eliminates the need for re-training during multimodal learning, reducing computational costs, especially for large-scale visual data. Resampler ViT, while lightweight, processes vision tokens dynamically, which can increase overhead for vision-heavy tasks. - Optimized for General Vision Tasks:
Pre-trained on large datasets, Frozen SigLIP-ViT excels in broad vision tasks (e.g., classification, detection). Its cross-attention integration ensures high-quality outputs. Conversely, Resampler ViT is more specialized for lightweight tasks like OCR and chart parsing.
Qwen 2.5-VL-72B
Window-Attention ViT with MRoPE enables efficient processing of arbitrary resolution images and long videos, seamlessly fused token-by-token with a 72B MoE language core for complex multimodal tasks.
Advantages
- Frozen SigLIP-ViT:
Modular and flexible design allows independent optimization or replacement of the vision encoder, ideal for general-purpose vision tasks. - Resampler ViT:
Lightweight and efficient, specialized for high-accuracy OCR and chart interpretation, with minimal computational overhead. - Window-Attention ViT + MRoPE:
Optimized for arbitrary resolution and long-video processing, with fine-grained token-by-token fusion for complex multimodal tasks.
Llama 4 (Scout / Maverick)
ViT patch-embedding feeds into a Mixture-of-Experts multimodal Transformer, dynamically activating 16–128 experts per forward pass for scalable and efficient multimodal processing.
Advantages
- Scalability:
The Mixture-of-Experts design allows the model to scale efficiently to large datasets and tasks, activating only the necessary experts, reducing unnecessary computation. This makes it highly efficient for large-scale multimodal systems. - Task Adaptability:
By dynamically selecting between 16–128 experts, this architecture adapts to tasks of varying complexity, ensuring optimal performance without overloading computation. - Efficiency for Diverse Data:
Unlike Window-Attention ViT, which specializes in high-resolution or video data, the MoE architecture excels in general multimodal workloads, efficiently balancing resources across different types of data (e.g., text, images, and their combinations).
Comparing Top 5 Large Vision Models in Performance
| Model | MMBench | MMMU | OCRBench | MATHVista | HallusionBench | ScienceQA-TEST |
|---|---|---|---|---|---|---|
| GPT 4o | 82.2 | 69.2 | 815 | 61.8 | 55 | 90.7 |
| Gemini 2.5 Pro | 88.3 | 74.7 | 862 | 80.9 | 64.1 | - |
| Claude 3.7 Sonnet | 79.7 | 71 | 701 | 66.8 | 55.4 | 90.9 |
| Qwen 2.5 VL 72B | 87.8 | 68.2 | 882 | 74.2 | 54.6 | 91.4 |
| Llama 4 Scout | 69.4 | 66.5 | - | 70.7 | - | - |
Gemini 2.5 Pro is the best choice for general multimodal tasks. Qwen 2.5-VL-72B excels in OCR and scientific reasoning. GPT-4o and Claude 3 Sonnet are strong for scientific tasks but weaker in math and hallucination resistance. Llama 4 Scout has limited capabilities and incomplete evaluations.
Comparing Top 5 Large Vision Models in Application
| If you care most about … | Short-list |
|---|---|
| Sub-second OCR & general visual chat | GPT 4o |
| College-level multimodal reasoning / video moment QA | Gemini 2.5 Pro |
| Massive PDFs + images with high legal accuracy | Claude 3.7 Vision |
| Full control & low TCO for grounding / video QA | Qwen 2.5-VL-72B |
| Chart or structured-doc analytics on single GPU | Llama 4 Scout |
Comparing Top 5 Large Vision Models in Deployment
Since GPT, Gemini, and Claude are closed-source models and can only be accessed via their official platforms, Qwen and Llama, being open-source models, offer the advantage of portability and cost-effectiveness through APIs such as Novita AI.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Try Qwen 2.5 VL 72B and Llama 4 Demo Now!
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Vision Language Models (VLMs) represent the cutting edge of multimodal AI, combining image and text understanding to power a wide range of tasks like visual QA, image captioning, and object detection. Among the leading models:
- Gemini 2.5 Pro is the top choice for general multimodal tasks, excelling in diverse use cases with high efficiency and scalability.
- Qwen 2.5-VL-72B stands out for OCR and scientific reasoning, offering flexibility and cost-effectiveness as an open-source solution.
- GPT-4o and Claude 3 Vision are strong in scientific reasoning and OCR but are closed-source with limited adaptability.
- Llama 4 Scout provides a scalable open-source option, though its capabilities are less refined compared to competitors.
Open-source models like Qwen and Llama offer the advantage of portability and cost-efficiency, accessible through APIs such as Novita AI.
Frequently Asked Questions
What are Vision Language Models (VLMs)?
VLMs are AI models designed to process both images and text, generating natural language outputs. They perform tasks such as visual QA, image captioning, and object detection.
How do VLMs work?
VLMs combine an image feature extractor (e.g., ViT or CLIP) with a text decoder (e.g., LLaMA or Qwen). This integration enables seamless multimodal understanding.
Why choose open-source VLMs like Qwen and Llama?
Open-source models allow full control, customization, and cost-effective deployment. They can be accessed via APIs like Novita AI, providing flexibility and ease of integration.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



