

GPT-OSS-120B — это новая волна языковых моделей с открытыми весами, зародившаяся благодаря OpenAI и сейчас быстро развивающаяся сообществом открытого исходного кода. Разработчики и компании ищут способы использовать её потенциал, но поскольку доступ предоставляют множество API-провайдеров, не всегда понятно, какой из них лучше подходит для ваших задач ИИ. В этой статье мы разберем лучших провайдеров с разных сторон: стоимость, скорость и другие параметры, чтобы помочь вам выбрать оптимальный вариант для ваших нужд.
Подробнее о GPT-OSS-120
| Параметр | GPT-OSS-120B |
| Параметры | 117B всего, 5.1B активированных |
| Архитектура | MoE на основе трансформера |
| Контекстное окно | 128K токенов |
| Мультимодальность | Текст, изображения, аудио |
| Открытый исходный код | Да |
| Минимальные требования к оборудованию | 1× NVIDIA H100 80GB (квантизация MXFP4) |
Хотя технические характеристики GPT-OSS-120B демонстрируют его впечатляющий масштаб и универсальность, для запуска такой модели напрямую требуются продвинутая инфраструктура и высокие затраты. Для большинства разработчиков и компаний практический способ раскрыть её потенциал — использование API, которое делает доступ простым, масштабируемым и экономически эффективным.
Зачем получать доступ к GPT-OSS через API?
- Снимите нагрузку на оборудование при локальном развертывании
Для запуска GPT-OSS-120B на собственных мощностях требуются производительные GPU, оптимизированные конвейеры и постоянное обслуживание — ресурсы, которые могут позволить себе лишь немногие. API устраняет этот барьер, предоставляя мгновенный доступ к возможностям модели без необходимости в специализированной инфраструктуре.- Избавьтесь от затрат и временных затрат на самостоятельный хостинг
Настройка крупномасштабных моделей обычно требует больших первоначальных инвестиций и недель инженерных работ. В отличие от этого, API работает по модели оплаты по факту использования и позволяет начать работу за несколько минут. Это сочетание низкой стоимости и быстрой интеграции делает API наиболее практичным способом внедрения GPT-OSS в реальные приложения.- Решите проблемы с надежностью и масштабируемостью
Даже если вам удастся развернуть крупную модель, обеспечение стабильной производительности при большой нагрузке — еще одна сложность. API-провайдеры решают это с помощью мониторинга, четких SLA и оптимизированных систем, которые гарантируют стабильные ответы. Для команд это означает возможность сосредоточиться на создании ценности, доверив провайдерам обеспечение uptime и масштабирование.
Как выбрать API-провайдера?
| Метрика | Почему это важно |
| Длина контекста (Чем выше, тем лучше) |
Определяет, сколько текста модель может обработать за один раз: более длинные окна позволяют выполнять суммаризацию документов, многоходовый диалог и более сложное рассуждение. |
| Стоимость токенов (Чем ниже, тем лучше) |
Влияет на масштабируемость и бюджет: более низкая стоимость за токен означает больше запросов и более крупные рабочие нагрузки без перерасхода средств. |
| Задержка (Чем ниже, тем лучше) |
Непосредственно влияет на пользовательский опыт: быстрые ответы необходимы для чат-ботов, ассистентов и приложений в реальном времени. |
| Пропускная способность (Чем выше, тем лучше) |
Показывает, сколько запросов может обрабатываться параллельно: более высокая пропускная способность обеспечивает стабильную производительность при высокой нагрузке или корпоративном трафике. |
| Возможности интеграции | Надежные SDK, понятная документация и поддержка нескольких моделей упрощают интеграцию GPT-OSS в продукты и рабочие процессы, снижая сложность для разработчиков. |
Оценивая эти пять метрик, вы получаете более четкое представление о том, как разные провайдеры соотносятся друг с другом — не только на бумаге, но и в реальном использовании. Исходя из этой системы, давайте рассмотрим ведущих API-провайдеров для GPT-OSS на сегодняшний день.
Сравнение API-провайдеров GPT-OSS-120B
| Провайдер | Контекстное окно | Цена на вход ($/M токенов) | Цена на выход ($/M токенов) |
| Novita AI | 131K | 0.1 | 0.5 |
| Nebius | 128K | 0.15 | 0.6 |
| Fireworks | 131K | 0.15 | 0.6 |
| Провайдер | Скорость вывода (токенов/сек) | Задержка (при 10k входных токенов) | Задержка (при 100k входных токенов) |
| Novita AI | 273 | 1.2 | 5.9 |
| Nebius | 181 | 1.1 | 5.4 |
| Fireworks | 439 | 1.8 | 6.6 |
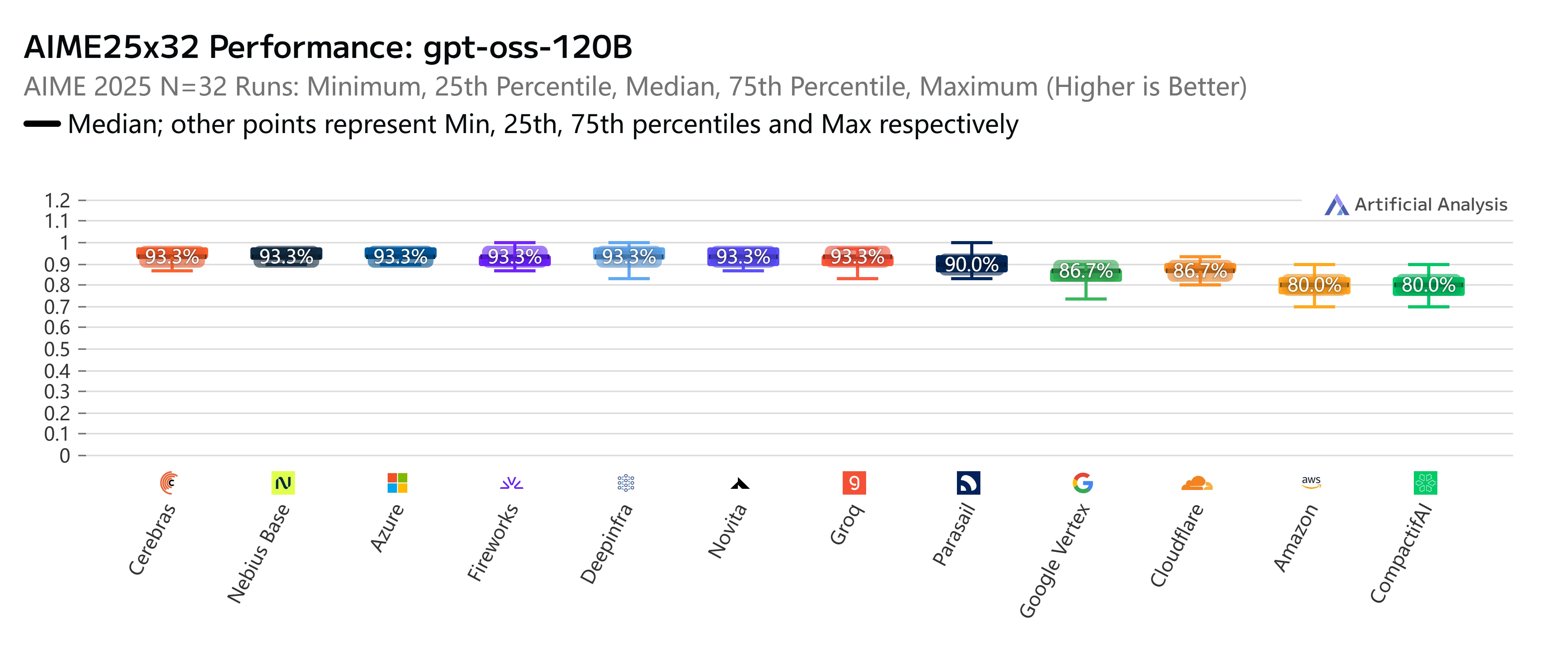
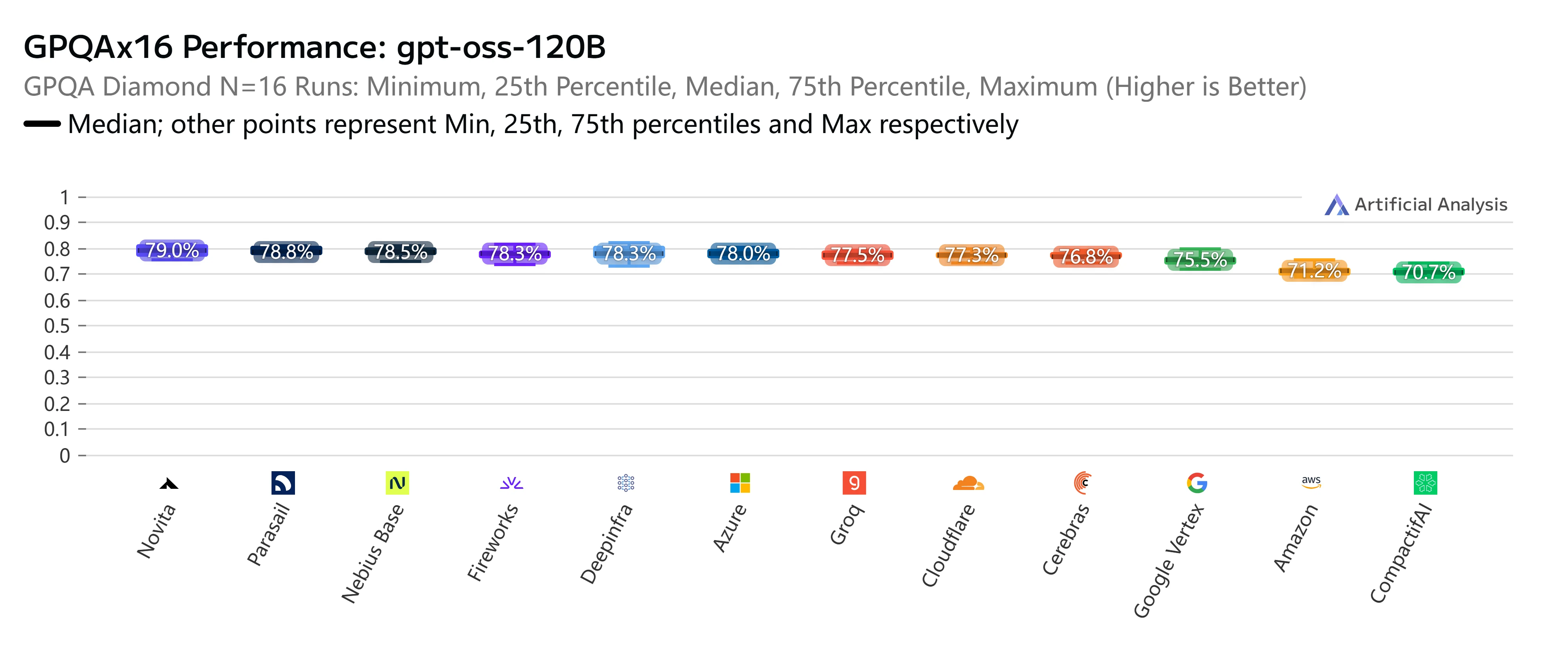
Novita AI
Ключевое преимущество Novita AI — сочетание конкурентной стоимости, щедрого контекстного окна на 131K токенов и выше среднего скорости вывода в 273 токена/сек. Это редкое сочетание доступности и возможностей делает его отличным выбором для команд, которые хотят масштабироваться экономически эффективно, не жертвуя производительностью. Он особенно подходит для таких рабочих нагрузок, как крупномасштабная генерация контента, корпоративный поиск или многоязычные приложения, где важны как обработка длинных входных данных, так и экономическая эффективность.
Помимо цены и скорости, Novita AI также выделяется на строгих независимых бенчмарках. В тесте AIME25x32 (продвинутое математическое рассуждение) наш эндпоинт GPT-OSS-120B стабильно показывает высочайшую точность в 93,3%, достигая или превосходя показатели почти всех крупных провайдеров. Аналогично, в оценке GPQAx16 (вопросы и ответы по науке уровня выпускников вузов) Novita снова вошел в число лучших с результатом 79%, что подчеркивает его сильные стороны в задачах со сложным рассуждением.
Nebius
Nebius выделяется самой низкой задержкой среди трех провайдеров, сохраняя стабильное время ответа даже при высокой нагрузке. Хотя его контекстное окно немного меньше — 128K, а скорость ниже (181 токен/сек), этот компромисс хорошо подходит для предприятий, которые ценят предсказуемость и стабильность системы больше, чем сырую скорость. Nebius — отличный вариант для управления знаниями, автоматизации внутренних бизнес-процессов или случаев, когда критически важны стабильные ответы с низкой задержкой.
Fireworks
Fireworks лидирует по сырой производительности, обеспечивая самую высокую скорость вывода в 439 токенов/сек. Это делает его крайне привлекательным для сценариев использования в реальном времени и интерактивных задач, таких как чат-боты, ИИ-ассистенты и инструменты для совместной работы, где отзывчивость определяет пользовательский опыт. Хотя его стоимость токенов выше, а задержка немного больше, разработчики, которые ценят плавное, мгновенное взаимодействие больше, чем стоимость, найдут Fireworks наиболее убедительным выбором.
Топ-3 API-провайдера GPT-OSS-120B: Novita AI
Novita AI предоставляет удобный API, который делает развертывание ИИ-моделей простым и эффективным, а также предлагает доступное и надежное облако GPU, которое позволяет разработчикам создавать и масштабировать решения без больших затрат на инфраструктуру.
Почему стоит выбрать Novita AI?
Ключевые преимущества
- Ускорение разработки: Популярные мультимодальные модели, такие как DeepSeek V3.1, GPT-OSS и GLM-4.5, уже предварительно интегрированы, что сокращает время настройки.
- Экономическая эффективность: Собственные методы оптимизации позволяют снизить расходы на инференс на 30–50% по сравнению с mainstream-провайдерами.
- Масштабируемый доступ: Модель оплаты по факту использования и опции автоматического масштабирования делают платформу одинаково удобной как для стартапов, так и для корпоративных пользователей.
Основные возможности
- Хостинг моделей: Надежная поддержка широкого спектра моделей с открытым исходным кодом.
- Среда Playground: Браузерное пространство для мгновенного тестирования моделей и автоматической генерации фрагментов API-кода.
- Ресурсы для разработчиков: Утилиты, которые упрощают интеграцию и эксперименты.
- Контроль API: Мониторинг в реальном времени с детальными журналами использования.
- Контроль бюджета: Биллинг на основе токенов в паре с оповещениями о превышении бюджета.
- Корпоративные решения: 1) Частное локальное развертывание для отраслей с высокими требованиями к соответствию нормам. 2) Кастомная оптимизация: от индивидуального обучения моделей до аппаратного ускорения для крупных клиентов.
Как получить доступ к GPT-OSS на Novita AI?
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в существующий аккаунт или зарегистрируйте новый, затем нажмите кнопку Библиотека моделей.
Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.
Раздел библиотеки моделей Novita AI
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
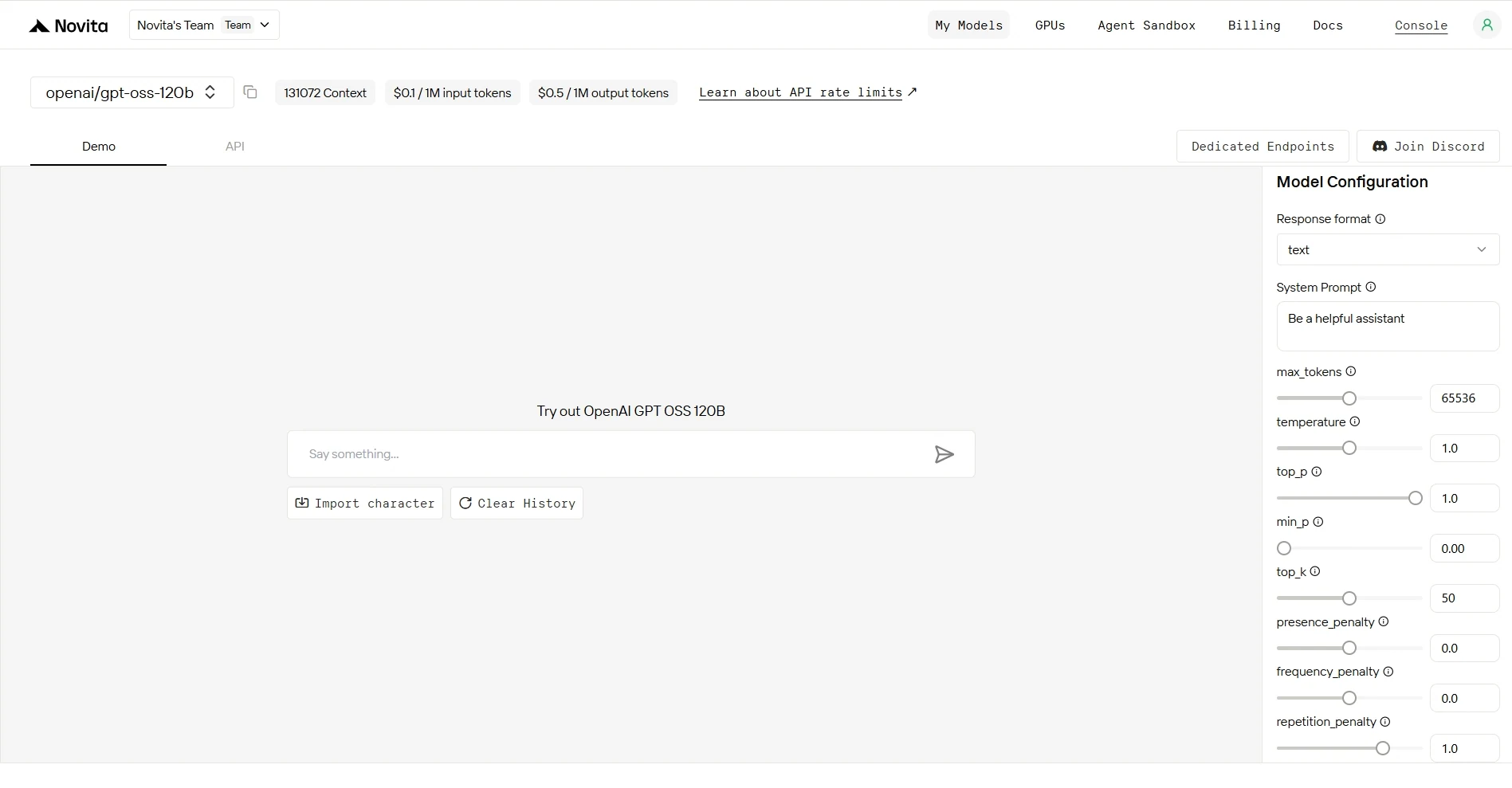
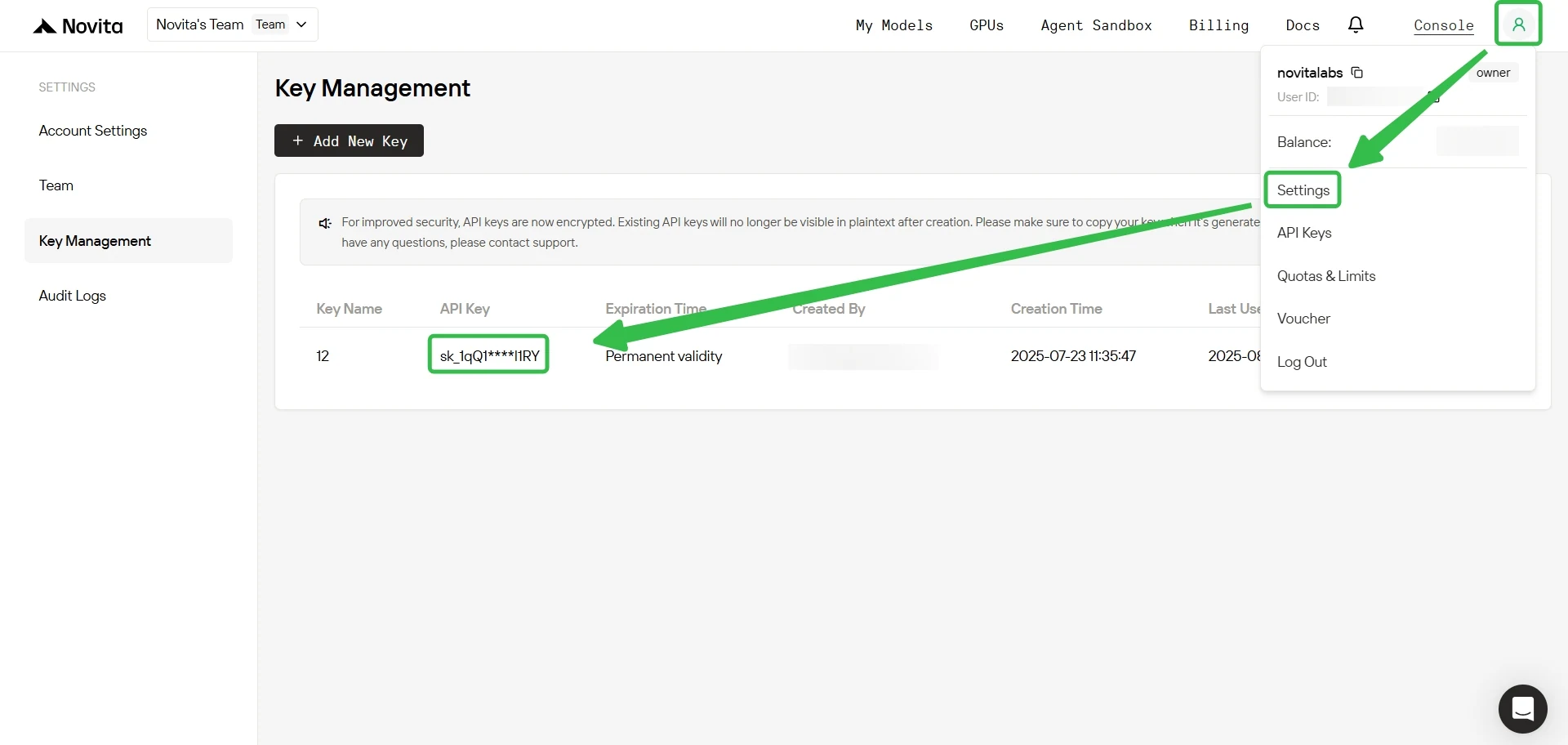
Шаг 4: Получите API-ключ
Для аутентификации через API Novita AI предоставляет вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.
Шаг 5: Установите API (пример для Python)
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с LLM Novita AI. Это пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Топ-3 API-провайдера GPT-OSS-120B: Nebius
Nebius предлагает сбалансированное соотношение цены и производительности как API-провайдер GPT-OSS-120B. Хотя он не самый дешевый, он обеспечивает самую низкую задержку для больших входных данных (5,4 с для 100k токенов), что делает его эффективным для задач с длинным контекстом.
Как получить доступ к GPT-OSS на этой платформе?
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "system",
"content": """SYSTEM_PROMPT"""
},
{
"role": "user",
"content": [
{
"type": "text",
"text": """USER_MESSAGE"""
}
]
}
]
)
print(response.to_json())
Топ-3 API-провайдера GPT-OSS-120B: Fireworks
Fireworks выделяется среди API-провайдеров GPT-OSS-120B самой высокой скоростью вывода — 439 токенов в секунду, что идеально подходит для рабочих нагрузок, требующих быстрой генерации. Он также поддерживает большое контекстное окно на 131K токенов, что позволяет беспрепятственно обрабатывать длинные или сложные запросы. Хотя его цены на вход и выход ($0,15 и $0,6 за миллион токенов) совпадают с Nebius, Fireworks особенно подходит для пользователей, которые ценят скорость и отзывчивость в крупномасштабных приложениях.
Как получить доступ к GPT-OSS на этой платформе?
Шаг 1: Установите SDK
pip install --upgrade fireworks-ai
Шаг 2: Настройте API-ключ (пример для Windows)
Вы можете открыть командную строку, найдя её в строке поиска Windows, или нажав Win + R, введя cmd и нажав Enter
setx FIREWORKS_API_KEY "<API_KEY>"
Шаг 3: Отправка первого API-запроса (пример для Python)
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "system",
"content": """SYSTEM_PROMPT"""
},
{
"role": "user",
"content": [
{
"type": "text",
"text": """USER_MESSAGE"""
}
]
}
]
)
print(response.to_json())
Заключение
Выбор правильного API-провайдера для GPT-OSS в конечном итоге зависит от ваших приоритетов. Если главным фактором является экономическая эффективность, Novita AI предлагает самый доступный вариант. Для тех, кому нужны самые быстрые время отклика и максимальная пропускная способность, лучший выбор — Fireworks или Nebius. Все крупные провайдеры предоставляют основные возможности, включая большие контекстные окна и вызов функций. Оцените, что наиболее важно для вашего проекта, и используйте это сравнение, чтобы найти провайдера, который лучше всего соответствует вашим потребностям.
Часто задаваемые вопросы
Novita AI — это облачная ИИ-платформа, которая предоставляет разработчикам простой способ развертывать ИИ-модели с помощью нашего простого API, а также предлагает доступное и надежное облако GPU для создания и масштабирования решений.



