

GPT-OSS-120B 代表了開源權重語言模型的新浪潮,最初由 OpenAI 發起,如今已由開源社群快速推進,開發者與企業都在尋找挖掘其潛力的方式。然而由於有多家 API 供應商提供存取服務,要判斷哪一家最適合您的 AI 工作負載並不容易。本文將從成本、速度等多個角度分析頂級供應商,幫助您挑選最符合需求的選項。
深入了解 GPT-OSS-120
| 功能 | GPT-OSS-120B |
| 參數量 | 總計 117B,其中 5.1B 被激活 |
| 架構 | 基於 Transformer 的混合專家(MoE)架構 |
| 上下文視窗 | 128K Tokens |
| 多模態 | 文字、圖片、音訊 |
| 開源 | 是 |
| 最低硬體需求 | 1×NVIDIA H100 80GB(MXFP4 量化) |
雖然 GPT-OSS-120B 的技術規格展現了其驚人的規模與多功能性,但直接運行此模型需要先進的基礎設施與高額成本。對大多數開發者與企業而言,釋放其潛力的務實方式是透過 API——這能讓存取變得簡單、可擴展且成本高效。
為什麼要透過 API 存取 GPT-OSS?
- 解決本地部署的硬體負擔
自行運行 GPT-OSS-120B 需要強大的 GPU、優化的流程以及持續的維護,這些資源只有少數單位負擔得起。API 透過提供模型能力的即時存取,且無需專門的基礎設施,消除了這道門檻。- 消除自託管的成本與時間消耗
搭建大型模型通常意味著高昂的前期投入與數週的工程工作量。相比之下,API 採用隨用隨付模式,讓您能在幾分鐘內開始使用。這種低成本與快速整合的組合,使得 API 成為將 GPT-OSS 導入實際應用的最務實方式。- 解決可靠性與可擴展性挑戰
即使您成功部署了大型模型,確保大規模下的穩定性能仍是另一道難關。API 供應商透過監控、明確的服務等級協議(SLA)與優化系統來解決這個問題,保證回應的一致性。對團隊而言,這意味著可以專注於創造價值,同時依賴供應商處理正常運行時間與擴展需求。
如何選擇 API 供應商?
| 指標 | 重要性 |
| 上下文長度 (越高越好) |
決定模型一次能處理多少文本——更長的上下文視窗能支持文件摘要、多輪對話與更複雜的推理。 |
| Token 成本 (越低越好) |
影響可擴展性與預算;更低的單一 Token 成本意味著可以在不超支的情況下進行更多查詢與處理更大工作負載。 |
| 延遲 (越低越好) |
直接影響使用者體驗;快速回應對於聊天機器人、助理與即時應用程式至關重要。 |
| 吞吐量 (越高越好) |
衡量可並行運行的請求數量;更高的吞吐量能確保在大量或企業級流量下的穩定性能。 |
| 整合能力 | 強大的 SDK、清晰的說明文件與多模型支持能讓 GPT-OSS 更易於整合到產品與工作流程中,降低開發者的使用門檻。 |
透過權衡這五項指標,您能更清楚地了解不同供應商的實際表現——不僅是紙上數據,更是實際使用中的情況。基於這個框架,我們來看看目前 GPT-OSS 的頂級 API 供應商。
GPT-OSS-120B 的 API 供應商:比較
| 供應商 | 上下文視窗 | 輸入價格(美元/百萬 Token) | 輸出價格(美元/百萬 Token) |
| Novita AI | 131K | 0.1 | 0.5 |
| Nebius | 128K | 0.15 | 0.6 |
| Fireworks | 131K | 0.15 | 0.6 |
| 供應商 | 輸出速度(Token/秒) | 延遲(處理 1 萬輸入 Token) | 延遲(處理 10 萬輸入 Token) |
| Novita AI | 273 | 1.2 | 5.9 |
| Nebius | 181 | 1.1 | 5.4 |
| Fireworks | 439 | 1.8 | 6.6 |
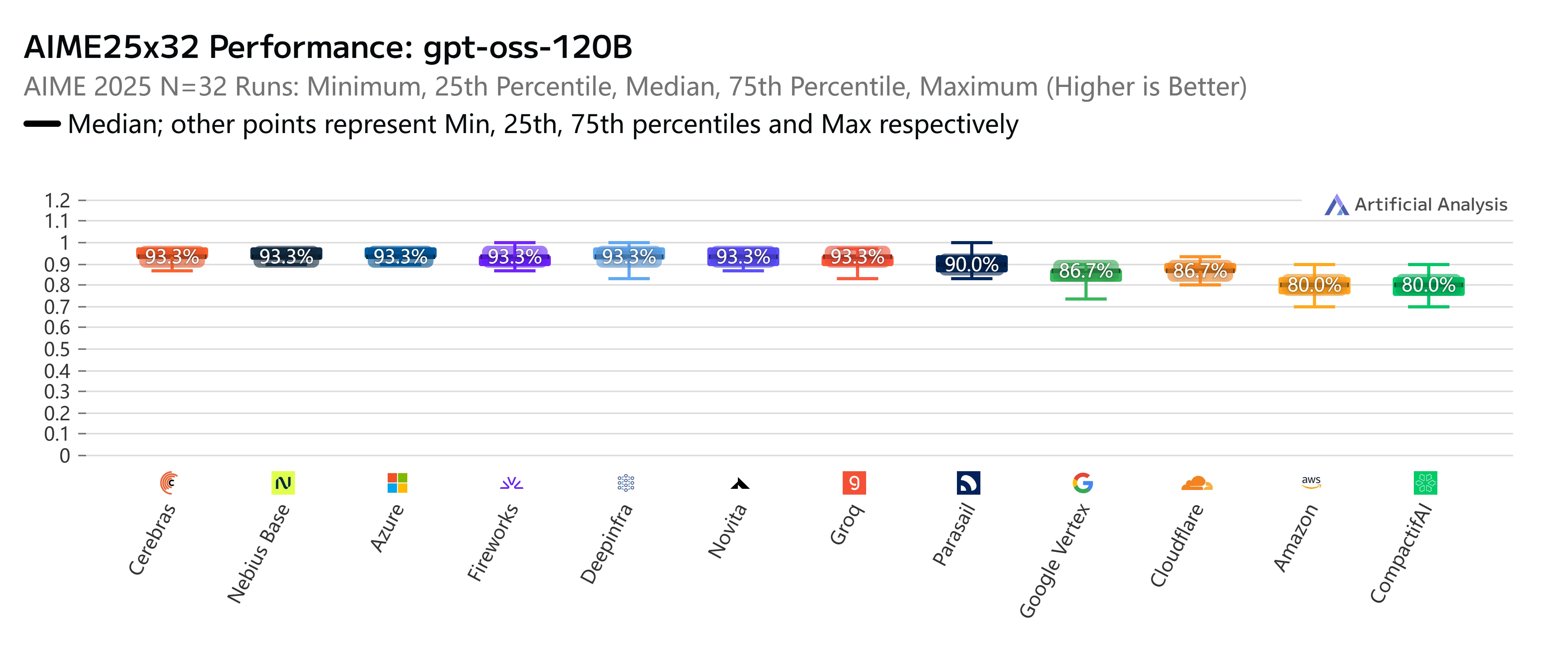
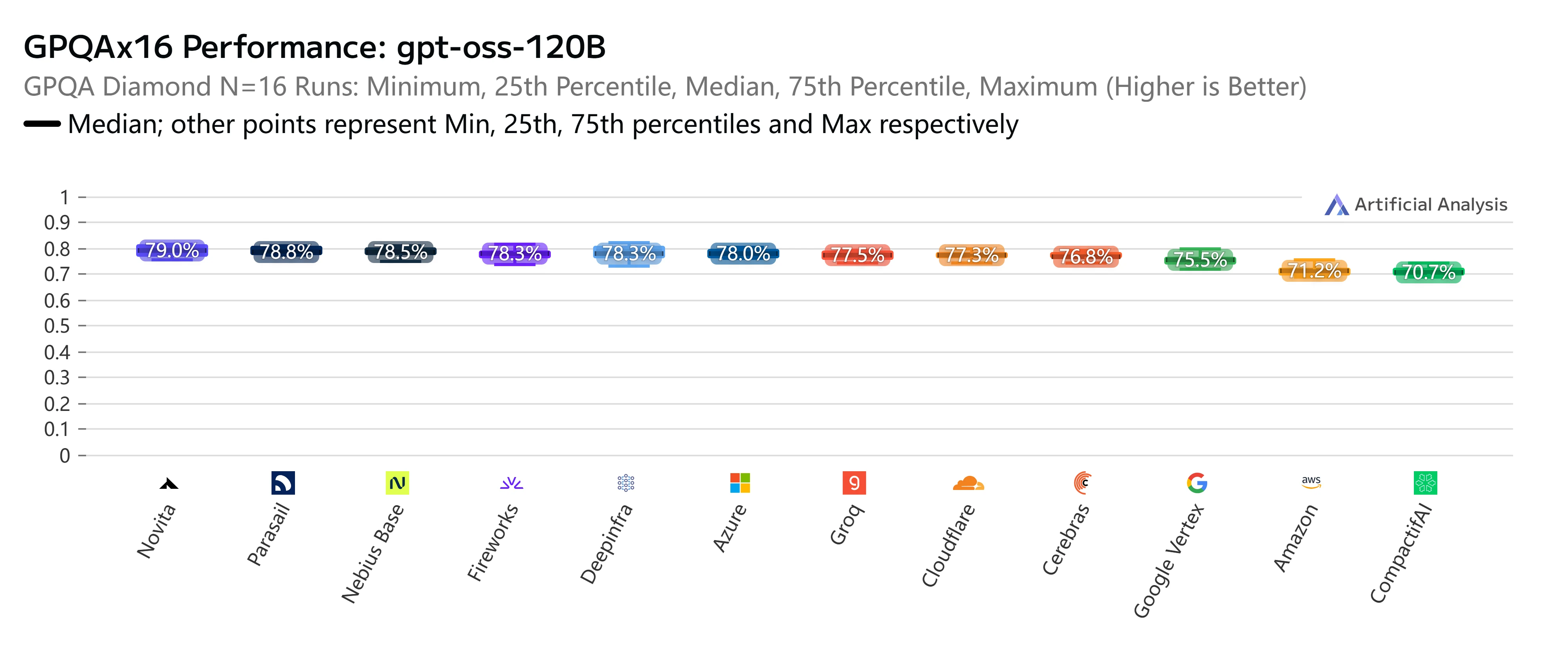
Novita AI
Novita AI 最大的優勢在於將具競爭力的價格、寬容的131K 上下文視窗與高於平均的273 Token/秒輸出速度相結合。這種實惠與能力的稀有平衡,使其非常適合想要在不犧牲性能的前提下進行成本效益擴展的團隊。它尤其適用於大規模內容生成、企業搜索或多語言應用等需要長輸入處理與成本效率兼備的工作負載。
除了價格與速度,Novita AI 在嚴格的獨立基準測試中也表現突出。在 AIME25x32(高級數學推理)測試中,我們的 GPT-OSS-120B 端點始終保持 93.3% 的頂級準確率,表現與幾乎所有主流供應商持平甚至更優。同樣地,在 GPQAx16(研究生級科學問答)評估中,Novita 再次以 79% 的分數躋身最佳行列,凸顯了其在複雜推理任務上的強大實力。
Nebius
Nebius 在這三家供應商中以最低延遲脫穎而出,即使面對沉重的工作負載也能保持穩定的回應時間。雖然其上下文視窗略小,為 128K,速度也較慢,為 181 Token/秒,但這種取捨非常適合將可預測性與系統穩定置於原始速度之上的企業。Nebius 是知識管理、後台自動化,或需要一致、低延遲回應的場景的強力選擇。
Fireworks
Fireworks 在原始性能方面領先,提供最快的輸出速度,達 439 Token/秒。這使其對即時與互動型使用場景极具吸引力,例如聊天機器人、AI 助理與協作工具,在這些場景中,回應速度決定了使用者體驗。雖然其 Token 定價較高,延遲也略高,但將流暢、即時的互動置於成本之上的開發者會發現 Fireworks 是最具吸引力的選擇。
GPT-OSS-120B 三大 API 供應商:Novita AI
Novita AI 提供流暢的 API,讓 AI 模型部署簡單高效,同時提供實惠且可靠的 GPU 雲端服務,讓開發者無需承擔沉重的基礎設施成本即可構建與擴展應用。
為什麼要選擇 Novita AI?
核心優勢
- 加速開發:熱門多模態模型如 DeepSeek V3.1、GPT-OSS 與 GLM-4.5 已預先整合,大幅縮短設定時間。
- 成本效益:專有優化技術能讓推論費用比主流供應商低 30%–50%。
- 可擴展的存取:隨用隨付定價與自動擴展選項,讓平台對新創公司與企業用戶都同樣友好。
核心能力
- 模型託管:可靠支持多種開源模型。
- 測試環境:基於瀏覽器的空間,可即時測試模型並自動生成 API 程式碼片段。
- 開發者資源:簡化整合與實驗的工具。
- API 監控:即時監控與詳細的使用日誌。
- 預算控制:基於 Token 的計費,搭配預算提醒功能。
- 企業解決方案:1)針對合規導向行業的私有、本地部署。2)客製化優化,從量身打造的模型訓練到大型客戶的硬體加速。
如何在 Novita AI 上存取 GPT-OSS?
步驟 1:登入並存取模型庫
登入或註冊您的帳號,點擊 模型庫 按鈕。
步驟 2:選擇模型
瀏覽可用的選項,選擇符合您需求的模型。
Novita AI 的模型庫區域
步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
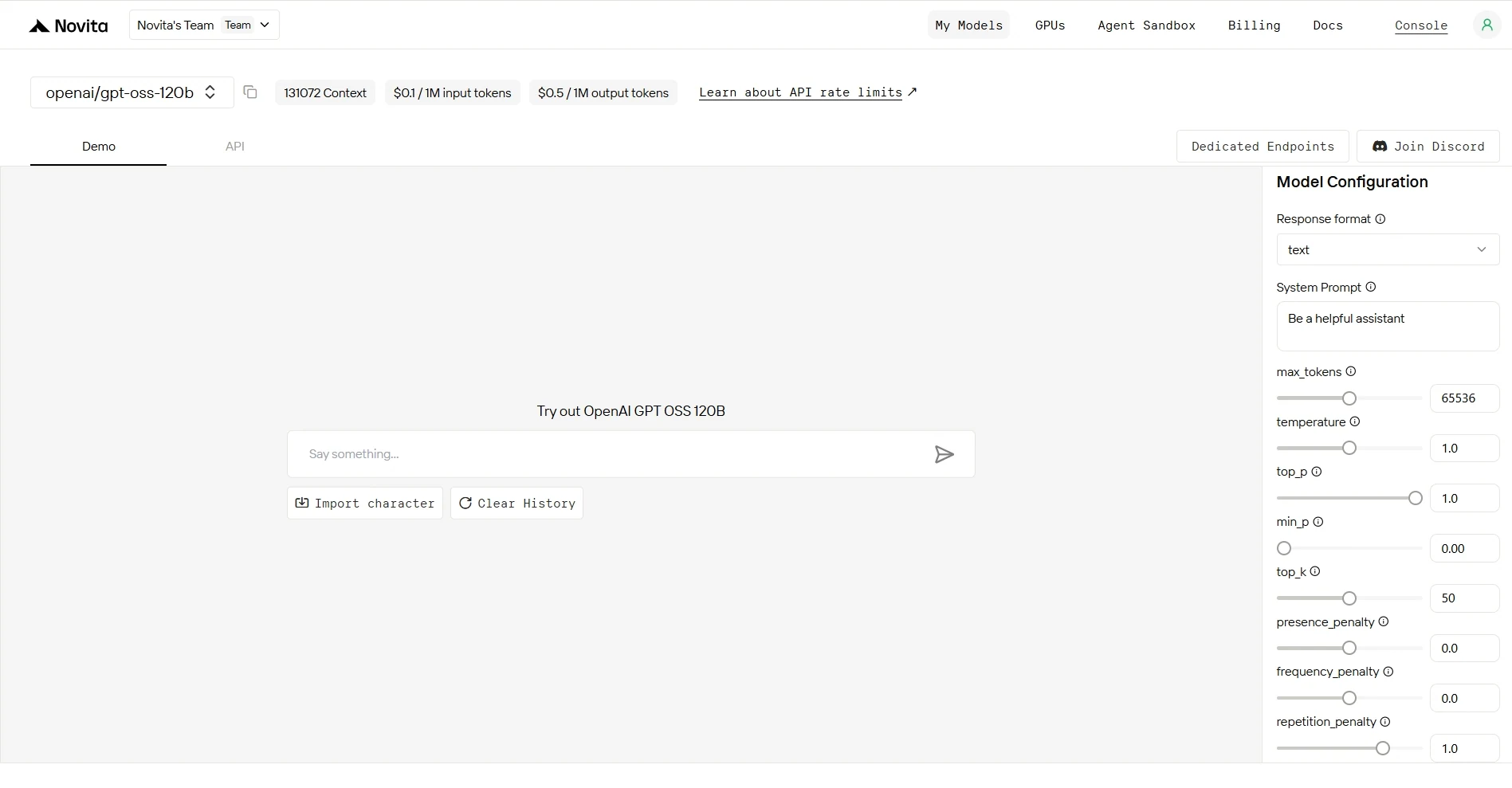
步驟 4:取得 API 金鑰
為了進行 API 驗證,Novita AI 會為您提供新的 API 金鑰。進入「設定」頁面,即可按照圖片指示複製 API 金鑰。
步驟 5:安裝 API(Python 範例)
使用對應程式語言的套件管理器安裝 API。
安裝完成後,將必要的程式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,即可開始與 Novita AI LLM 互動。以下是为 Python 使用者提供的聊天完成 API 呼叫範例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GPT-OSS-120B 三大 API 供應商:Nebius
Nebius 作為 GPT-OSS-120B 的 API 供應商,在成本與性能之間提供了具競爭力的平衡。雖然不是定價最低的選項,但它在處理大型輸入時延遲最低(處理 10 萬 Token 僅需 5.4 秒),非常適合長上下文任務。
如何在 Nebius 上存取 GPT-OSS?
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "system",
"content": """SYSTEM_PROMPT"""
},
{
"role": "user",
"content": [
{
"type": "text",
"text": """USER_MESSAGE"""
}
]
}
]
)
print(response.to_json())
GPT-OSS-120B 三大 API 供應商:Fireworks
Fireworks 在 GPT-OSS-120B 的 API 供應商中脫穎而出,擁有最高的輸出速度——每秒 439 Token——非常適合需要快速生成的工作負載。它同時支持 131K 的大上下文視窗,能無縫處理長篇或複雜的提示詞。雖然其輸入與輸出定價(每百萬 Token 0.15 美元與 0.6 美元)與 Nebius 持平,但對於在大型應用中看重速度與回應性的使用者而言,Fireworks 是特別強勢的選擇。
如何在 Fireworks 上存取 GPT-OSS?
步驟 1:安裝 SDK
pip install --upgrade fireworks-ai
步驟 2:設定 API 金鑰(Windows 範例)
您可以透過 Windows 搜尋列搜尋「命令提示字元」,或按下 Win + R、輸入 cmd 後按 Enter 來開啟命令提示字元。
setx FIREWORKS_API_KEY "<API_KEY>"
步驟 3:發送第一個 API 請求(Python 範例)
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "system",
"content": """SYSTEM_PROMPT"""
},
{
"role": "user",
"content": [
{
"type": "text",
"text": """USER_MESSAGE"""
}
]
}
]
)
print(response.to_json())
結論
為 GPT-OSS 選擇合適的 API 供應商最終取決於您的優先考量。如果成本效率是主要因素,Novita AI 提供了最實惠的選項。如果需要最快的回應時間與最高的吞吐量,Fireworks 或 Nebius 是最佳選擇。所有主流供應商都提供核心能力,包括大上下文視窗與函數呼叫。請考慮您的專案最看重什麼,並利用這份比較來找出最符合需求的供應商。
常見問題
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 來輕鬆部署 AI 模型,同時也提供實惠且可靠的 GPU 雲端服務,用於構建與擴展應用。



