

GPT-OSS-120B marca una nueva ola de modelos de lenguaje de pesos abiertos, que fue iniciada en su momento por OpenAI y ahora avanzada rápidamente por la comunidad de código abierto, con desarrolladores y empresas que buscan formas de aprovechar su potencial. Sin embargo, al haber múltiples proveedores de API que ofrecen acceso, no siempre está claro cuál se adapta mejor a tus cargas de trabajo de IA. Este artículo analiza los principales proveedores desde diferentes ángulos como costo, velocidad y más para ayudarte a elegir el que mejor se ajuste a tus necesidades.
Un vistazo más detallado a GPT-OSS-120
| Característica | GPT-OSS-120B |
| Parámetro | 117B en total, 5.1B activados |
| Arquitectura | MoE basado en Transformer |
| Ventana de contexto | 128K tokens |
| Multimodal | Texto, Imagen, Audio |
| Código abierto | Sí |
| Requisito mínimo de hardware | 1×NVIDIA H100 80GB (cuantización MXFP4) |
Si bien el perfil técnico de GPT-OSS-120B muestra su escala impresionante y versatilidad, ejecutar este modelo directamente requiere infraestructura avanzada y costos elevados. Para la mayoría de desarrolladores y empresas, la forma práctica de liberar su potencial es a través de una API, que hace que el acceso sea sencillo, escalable y rentable.
¿Por qué acceder a GPT-OSS mediante una API?
- Soluciona la carga de hardware de la implementación local
Ejecutar GPT-OSS-120B por tu cuenta requiere GPUs potentes, canalizaciones optimizadas y mantenimiento constante: recursos que solo unos pocos pueden permitirse. Las API eliminan esta barrera al ofrecer acceso instantáneo a las capacidades del modelo sin necesidad de infraestructura especializada.- Elimina el costo y el consumo de tiempo del alojamiento propio
Configurar modelos a gran escala generalmente significa una fuerte inversión inicial y semanas de trabajo de ingeniería. Por el contrario, las API siguen un modelo de pago por uso y te permiten empezar en minutos. Esta combinación de menor costo e integración más rápida hace que las API sean la forma más práctica de incorporar GPT-OSS en aplicaciones reales.- Resuelve los desafíos de fiabilidad y escalabilidad
Incluso si logras implementar un modelo masivo, garantizar un rendimiento estable a escala es otro obstáculo. Los proveedores de API solucionan esto con monitorización, SLAs claros y sistemas optimizados que garantizan respuestas consistentes. Para los equipos, esto significa centrarse en crear valor mientras confían en los proveedores para gestionar el tiempo de actividad y la escalabilidad.
¿Cómo elegir un proveedor de API?
| Métrica | Por qué es importante |
| Longitud de contexto (Mayor es mejor) |
Determina cuánto texto puede procesar el modelo de una sola vez: ventanas más largas permiten resumir documentos, diálogos multipaso y razonamientos más complejos. |
| Costo por token (Menor es mejor) |
Afecta a la escalabilidad y el presupuesto; un costo por token menor significa más consultas y cargas de trabajo más grandes sin gastar de más. |
| Latencia (Menor es mejor) |
Impacta directamente la experiencia de usuario; las respuestas más rápidas son esenciales para chatbots, asistentes y aplicaciones en tiempo real. |
| Rendimiento (Mayor es mejor) |
Mide cuántas solicitudes se pueden ejecutar en paralelo; un mayor rendimiento garantiza un funcionamiento estable bajo tráfico intenso o de nivel empresarial. |
| Capacidad de integración | SDKs potentes, documentación clara y soporte para múltiples modelos facilitan la integración de GPT-OSS en productos y flujos de trabajo, reduciendo la fricción para los desarrolladores. |
Al ponderar estas cinco métricas, obtienes una imagen más clara de cómo se comparan los diferentes proveedores, no solo sobre el papel, sino en el uso del mundo real. Con ese marco en mente, veamos los principales proveedores de API para GPT-OSS en la actualidad.
Proveedores de API de GPT-OSS-120B: Comparativa
| Proveedor | Ventana de contexto | Precio de entrada ($/M tokens) | Precio de salida ($/M tokens) |
| Novita AI | 131K | 0.1 | 0.5 |
| Nebius | 128K | 0.15 | 0.6 |
| Fireworks | 131K | 0.15 | 0.6 |
| Proveedor | Velocidad de salida (tokens /seg) | Latencia (por 10k tokens de entrada) | Latencia (por 100k tokens de entrada) |
| Novita AI | 273 | 1.2 | 5.9 |
| Nebius | 181 | 1.1 | 5.4 |
| Fireworks | 439 | 1.8 | 6.6 |
Novita AI
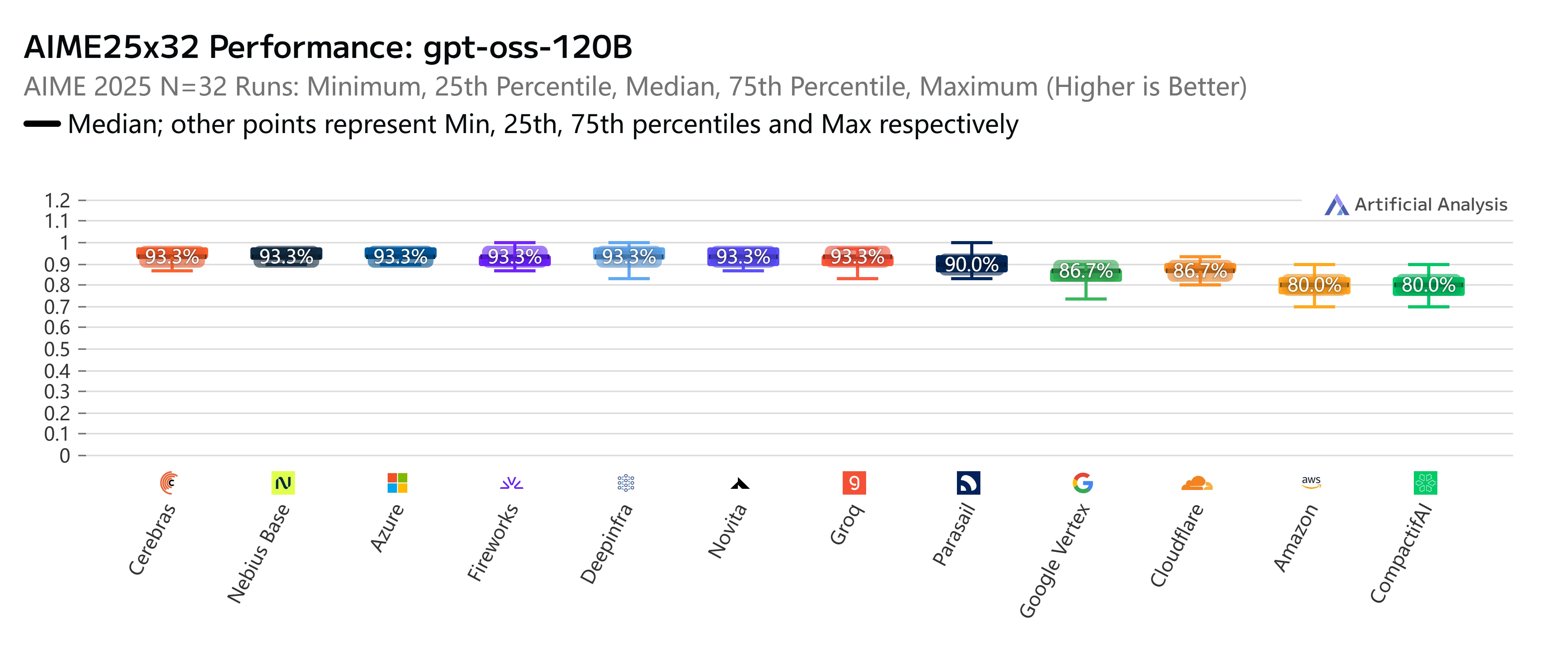
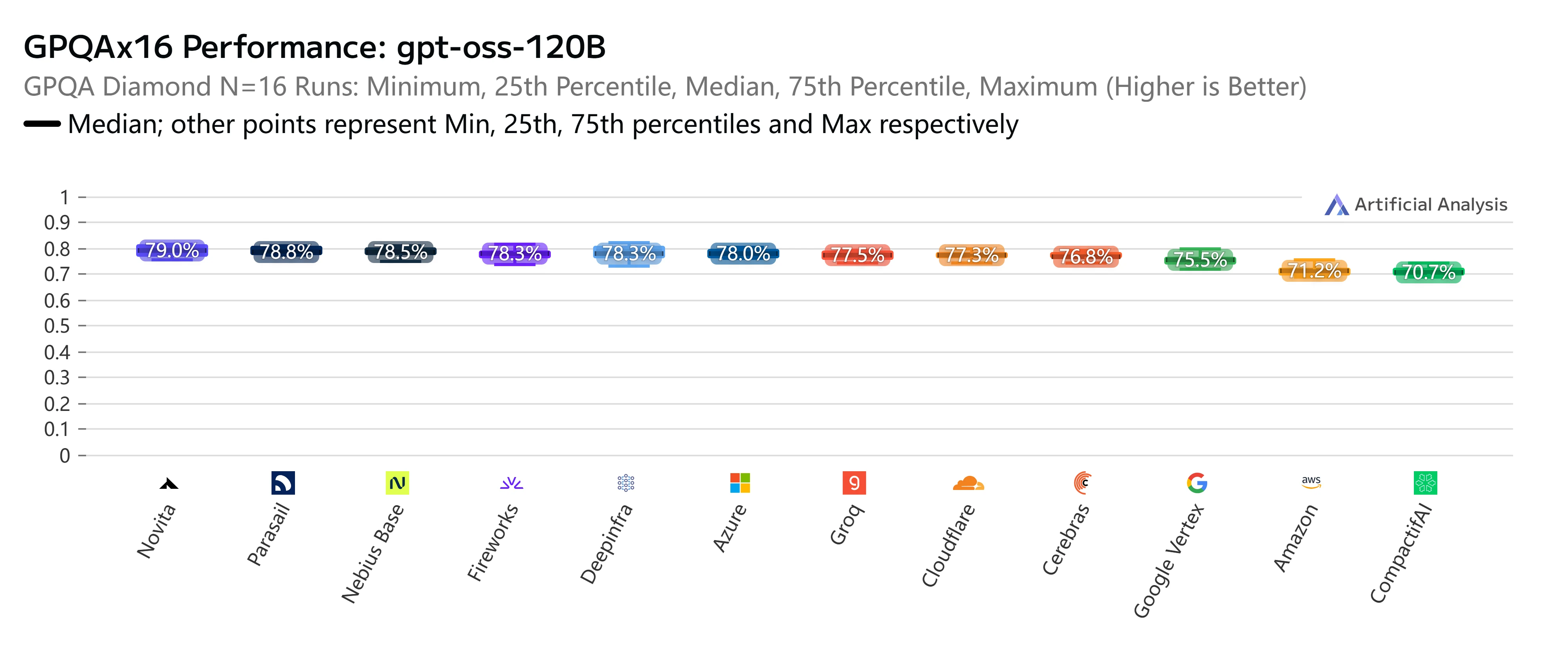
La mayor fortaleza de Novita AI radica en combinar precios competitivos con una generosa ventana de contexto de 131K y una velocidad de salida superior a la media de 273 tokens/seg. Este equilibrio poco habitual entre asequibilidad y capacidad lo convierte en una opción excelente para equipos que quieren escalar de forma rentable sin sacrificar rendimiento. Es especialmente adecuado para cargas de trabajo como generación de contenido a gran escala, búsqueda empresarial o aplicaciones multilingües, donde tanto el manejo de entradas largas como la eficiencia de costos son importantes.
Más allá de los precios y la velocidad, Novita AI también destaca en rigurosos benchmarks independientes. En AIME25x32 (razonamiento matemático avanzado), nuestro endpoint de GPT-OSS-120B ofreció constantemente una precisión de primer nivel del 93,3%, igualando o superando a casi todos los proveedores principales. Del mismo modo, en la evaluación GPQAx16 (preguntas y respuestas científicas de nivel de posgrado), Novita volvió a situarse entre los mejores con una puntuación del 79%, lo que subraya su fortaleza en tareas de razonamiento complejo.
Nebius
Nebius destaca por su latencia más baja entre los tres proveedores, manteniendo los tiempos de respuesta estables incluso para cargas de trabajo intensas. Aunque su ventana de contexto es ligeramente menor, de 128K, y su velocidad más lenta, de 181 tokens/seg, esta compensación funciona bien para empresas que valoran la previsibilidad y la estabilidad del sistema por encima de la velocidad bruta. Nebius es una opción muy sólida para la gestión del conocimiento, la automatización de oficinas traseras o casos en los que las respuestas consistentes y de baja latencia son críticas.
Fireworks
Fireworks lidera en rendimiento bruto, ofreciendo la velocidad de salida más rápida de 439 tokens/seg. Esto lo hace muy atractivo para casos de uso en tiempo real e interactivos, como chatbots, asistentes de IA y herramientas colaborativas, donde la capacidad de respuesta define la experiencia de usuario. Aunque sus precios por token son más altos y la latencia ligeramente mayor, los desarrolladores que priorizan una interacción fluida e instantánea por encima del costo encontrarán que Fireworks es la opción más convincente.
Principales 3 proveedores de API de GPT-OSS-120B: Novita AI
Novita AI ofrece una API fluida que hace que la implementación de modelos de IA sea sencilla y eficiente, además de proporcionar una nube de GPU asequible y fiable que permite a los desarrolladores construir y escalar sin costos elevados de infraestructura.
¿Por qué elegir Novita AI?
Beneficios clave
- Desarrollo acelerado: Los modelos multimodales populares como DeepSeek V3.1, GPT-OSS y GLM-4.5 vienen preintegrados, reduciendo el tiempo de configuración.
- Eficiencia de costos: Las técnicas de optimización propietarias ayudan a reducir los gastos de inferencia entre un 30% y un 50% en comparación con los proveedores mayoritarios.
- Acceso escalable: El modelo de precios de pago por uso y las opciones de escalado automático hacen que la plataforma sea igualmente apta para startups y usuarios empresariales.
Capacidades principales
- Alojamiento de modelos: Soporte fiable para una amplia gama de modelos de código abierto.
- Entorno de pruebas: Un espacio basado en navegador para probar modelos al instante y generar automáticamente fragmentos de API.
- Recursos para desarrolladores: Utilidades que facilitan la integración y la experimentación.
- Supervisión de API: Monitorización en tiempo real con registros de uso detallados.
- Control de presupuesto: Facturación basada en tokens combinada con alertas de presupuesto.
- Soluciones empresariales: 1) Implementación privada en local para industrias centradas en el cumplimiento normativo. 2) Optimización personalizada, desde entrenamiento de modelos adaptado hasta aceleración de hardware para clientes de gran escala.
¿Cómo acceder a GPT-OSS en Novita AI?
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión o regístrate en tu cuenta y haz clic en el botón de Biblioteca de modelos.
Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Sección de biblioteca de modelos de Novita AI
Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
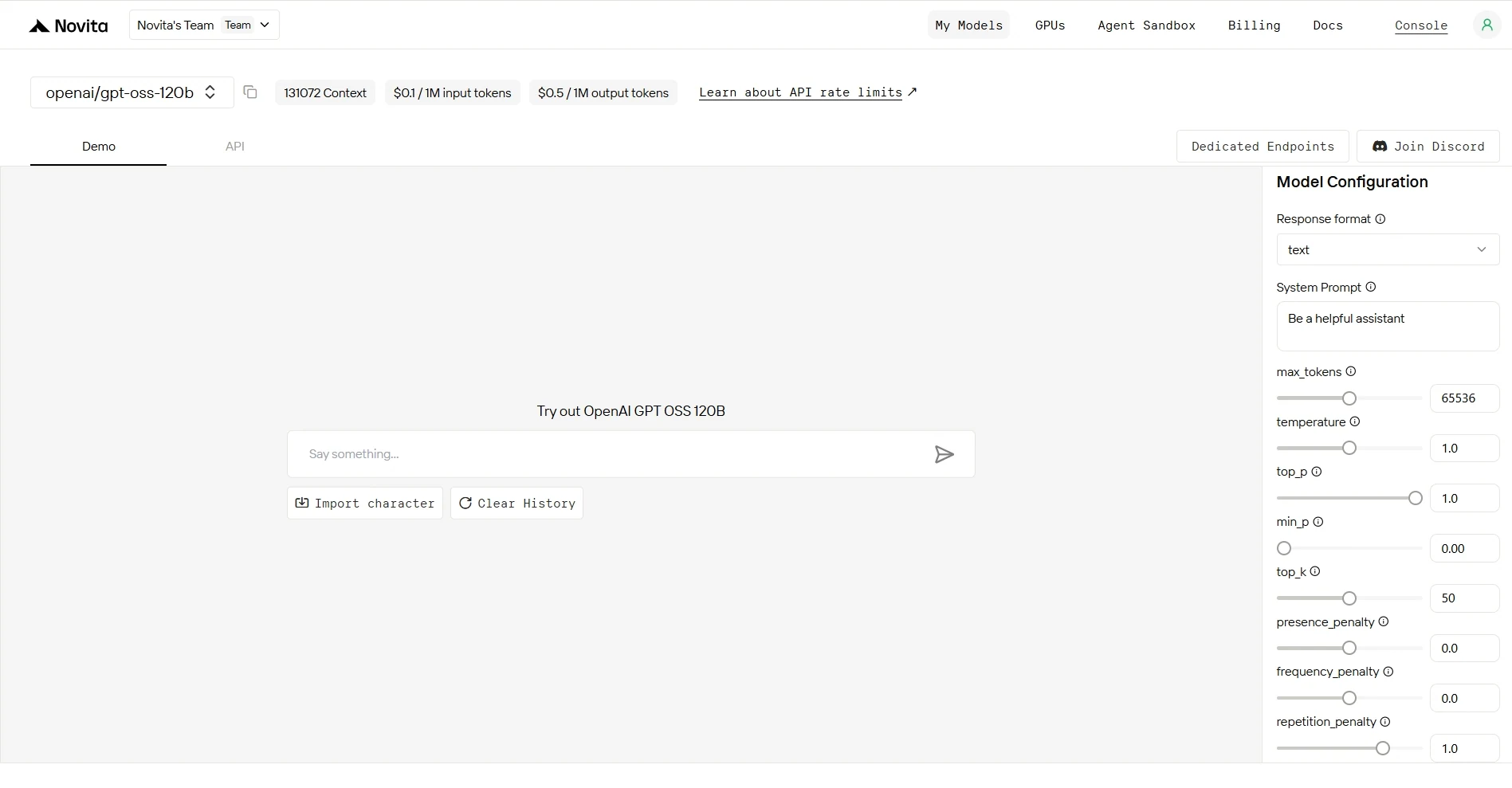
Paso 4: Obtén tu CLAVE DE API
Para autenticarte con la API, Novita AI te proporciona una nueva clave de API. Al entrar en la página de “Configuración”, puedes copiar la clave de API como se indica en la imagen.
Paso 5: Instala la API (ejemplo en Python)
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con el LLM de Novita AI. Este es un ejemplo de uso de la API de finalización de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Principales 3 proveedores de API de GPT-OSS-120B: Nebius
Nebius ofrece un equilibrio competitivo entre costo y rendimiento como proveedor de API de GPT-OSS-120B. Aunque no es el más barato, cuenta con la latencia más baja para entradas grandes (5,4s para 100k tokens), lo que lo hace eficiente para tareas de contexto largo.
¿Cómo acceder a GPT-OSS en él?
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "system",
"content": """SYSTEM_PROMPT"""
},
{
"role": "user",
"content": [
{
"type": "text",
"text": """USER_MESSAGE"""
}
]
}
]
)
print(response.to_json())
Principales 3 proveedores de API de GPT-OSS-120B: Fireworks
Fireworks se distingue entre los proveedores de API de GPT-OSS-120B por su velocidad de salida más alta: 439 tokens por segundo, ideal para cargas de trabajo que requieren generación rápida. También admite una amplia ventana de contexto de 131K, lo que permite manejar sin problemas prompts largos o complejos. Aunque sus precios de entrada y salida ($0,15 y $0,6 por millón de tokens) se alinean con los de Nebius, Fireworks es especialmente fuerte para usuarios que valoran la velocidad y la capacidad de respuesta en aplicaciones a gran escala.
¿Cómo acceder a GPT-OSS en él?
Paso 1: Instala el SDK
pip install --upgrade fireworks-ai
Paso 2: Configura la clave de API (ejemplo en Windows)
Puedes abrir el Símbolo del sistema buscándolo en la barra de búsqueda de Windows o presionando Win + R, escribiendo cmd y presionando Enter
setx FIREWORKS_API_KEY "<API_KEY>"
Paso 3: Enviar la primera solicitud a la API (ejemplo en Python)
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "system",
"content": """SYSTEM_PROMPT"""
},
{
"role": "user",
"content": [
{
"type": "text",
"text": """USER_MESSAGE"""
}
]
}
]
)
print(response.to_json())
Conclusión
Elegir el proveedor de API adecuado para GPT-OSS depende en última instancia de tus prioridades. Si la eficiencia de costos es el factor principal, Novita AI ofrece la opción más asequible. Para quienes necesiten los tiempos de respuesta más rápidos y el mayor rendimiento, Fireworks o Nebius son la mejor opción. Todos los proveedores principales ofrecen capacidades esenciales, incluidas ventanas de contexto amplias y llamadas a funciones. Ten en cuenta lo que más importa para tu proyecto y usa esta comparativa para identificar el proveedor que mejor se adapte a tus necesidades.
Preguntas frecuentes
Novita AI es una plataforma de IA en la nube que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, además de proporcionar una nube de GPU asequible y fiable para construir y escalar.



