

Бесчисленные AI-компании сейчас внедряют агентные системы бизнес-аналитики, которые могут мгновенно анализировать ваши данные и предоставлять исчерпывающие инсайты без необходимости в сложных SQL-запросах или ручном разборе электронных таблиц. Например, система аналитики продаж на основе RAG может ответить на вопросы вроде «Какой товар был самым продаваемым в прошлом квартале?» за секунды, а не часы.
Система аналитики продаж на базе RAG решает эти проблемы, используя AI-агентов, которые способны автономно рассуждать, принимать решения и координировать внешние инструменты, обеспечивая запросы на естественном языке по всей вашей экосистеме данных. Вместо изучения схем баз данных или формул электронных таблиц, агент разбивает ваш запрос, определяет наилучший источник данных, выполняет целенаправленный анализ и предоставляет полные, основанные на данных ответы с корректными ссылками.
Например, вы можете использовать другую LLM, собственный формат документов или настроить анализ и поведение агентов для получения конкретных бизнес-результатов. В этом руководстве вы узнаете, как создать собственную систему аналитики продаж на основе RAG, используя единый LLM API Novita AI, агентный фреймворк LangChain и расширенные возможности обработки документов. Вы создадите систему, которая автоматически направляет запросы к оптимальным источникам данных и предоставляет практичные бизнес-инсайты.
Что такое система аналитики продаж на основе RAG?
Система аналитики продаж на основе RAG использует Retrieval-Augmented Generation для предоставления точных, обоснованных ответов на вопросы о розничных продажах, объединяя возможности больших языковых моделей со слоем поиска, который может получать доступ к вашим реальным бизнес-данным.
Такая система обычно включает:
- AI-агент анализирует запрос и определяет, требует ли он анализа структурированных данных (SQL), анализа документов или и того, и другого.
- Агент интеллектуально направляет запросы к наиболее подходящему источнику данных — базам данных SQL для количественного анализа или хранилищам документов для качественных инсайтов.
- Агент использует различные инструменты для сбора информации, включая Pandas для анализа CSV-файлов, SQL-агенты для запросов к базам данных и векторные хранилища для поиска по документам. Без этих инструментов агент не может выполнять ключевые действия в рабочем процессе.
- Агент обрабатывает собранную информацию с помощью специализированных методов: статистического анализа для числовых данных и семантического поиска для текстовых документов.
- После анализа данных агент создает структурированный ответ, который включает сводки, вычисления и корректные ссылки.
Необходимые инструменты
Прежде чем перейти к практической части статьи, давайте настроим необходимые инструменты.
Novita AI
Для создания нашей аналитической системы на основе RAG нам понадобится доступ к мощным большим языковым моделям (LLM) и моделям эмбеддингов. Novita AI предлагает доступные высокопроизводительные API, обеспечивающие доступ к последним большим языковым моделям (LLM), моделям эмбеддингов и многому другому через единый интерфейс.
LangChain
LangChain — это фреймворк с открытым исходным кодом, предназначенный для создания приложений с LLM. С помощью LangChain вы можете создать агентный рабочий процесс, который пошагово рассуждает, использует инструменты и взаимодействует с API. Для нашей системы аналитики продаж мы будем использовать LangChain для структурирования процесса анализа, применения таких инструментов, как SQL-агенты и обработчики документов, и синтеза всех данных в структурированные инсайты.

Streamlit
Для создания интерактивного веб-интерфейса мы будем использовать Streamlit. Он отлично подходит для быстрого прототипирования и позволяет создавать профессионально выглядящие интерфейсы с минимальным кодом, что упрощает выполнение этого руководства.
FAISS
Для векторного поиска по документам FAISS обеспечивает быстрый поиск по сходству, позволяя нам быстро находить релевантные фрагменты документов на основе пользовательских запросов.
SQLAlchemy и PyMySQL
Эти библиотеки обеспечивают работу с SQL-базами данных и подключение к MySQL, позволяя нашей системе напрямую запрашивать структурированные бизнес-данные.
pandas
Необходим для обработки и анализа CSV-данных. Наша система использует pandas-агенты для выполнения сложных вычислений над табличными данными.
Обзор архитектуры системы
Наша RAG-система интеллектуально обрабатывает пользовательские запросы через многоэтапный рабочий процесс, который автоматически определяет наилучший источник данных и метод обработки для каждого вопроса. Вместо того чтобы заставлять пользователей знать, где находятся их данные, система сама определяет оптимальный подход.
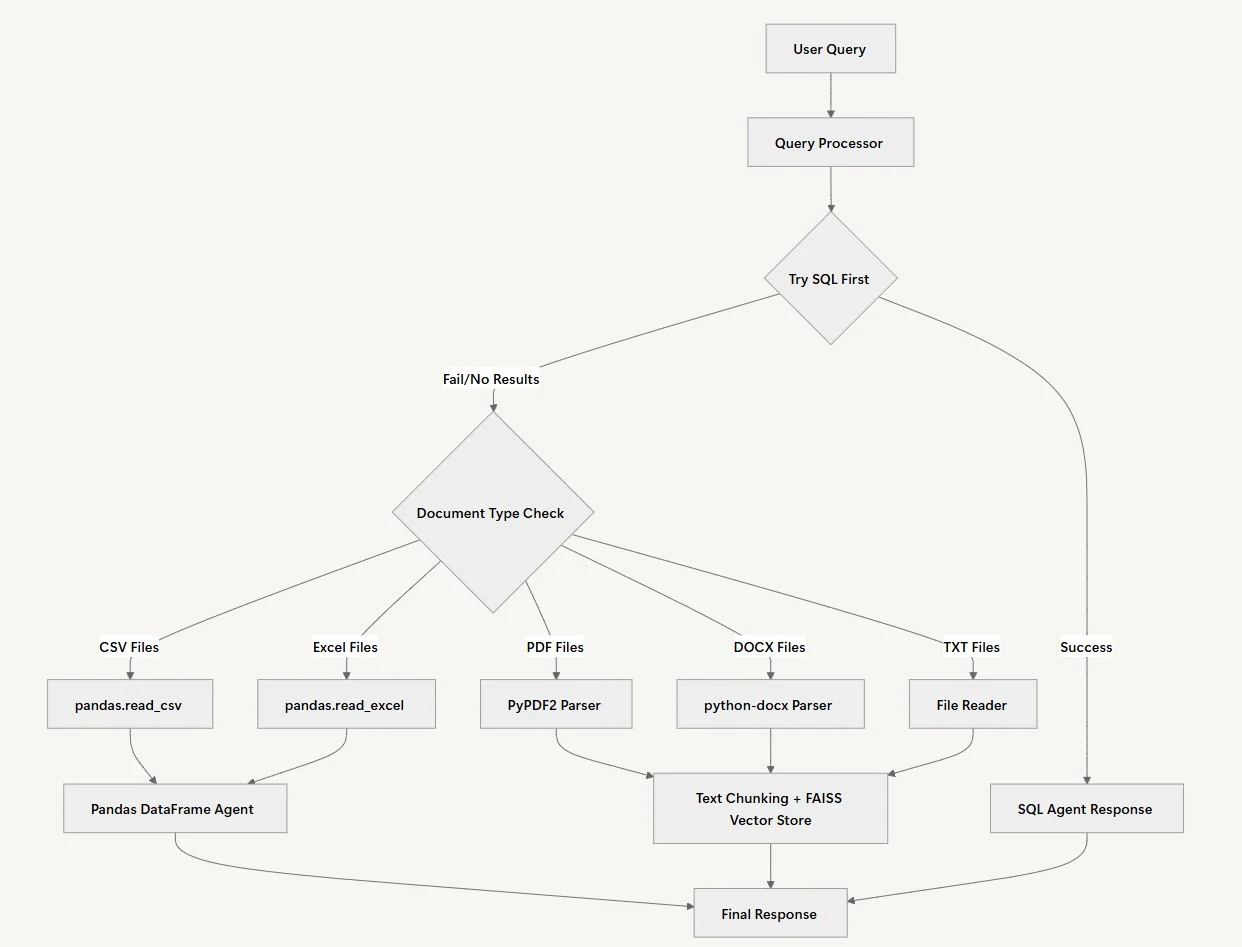
Обработка запроса
Первым шагом в нашем рабочем процессе с агентом является обработка запроса. В этом случае агент проверяет запрос, введенный пользователем, и разрабатывает персонализированный план обработки, соответствующий контексту запроса. Затем он определяет тип данных, по которым необходимо проанализировать вопрос: структурированные данные, анализ документов или оба варианта.
Выбор источника данных
Когда пользователь отправляет вопрос, система использует простой подход: сначала она пытается решить задачу с помощью SQL-базы данных. Выбор источника данных имеет смысл, поскольку структурированные данные часто дают наиболее точные ответы на количественные вопросы. SQL-агент может быстро выполнить запросы и вернуть точные числа с правильными вычислениями.
Анализ документов
Когда SQL-агент возвращает пустые результаты или не может найти нужную информацию, система автоматически переключается на анализ документов. Путь обработки документов зависит от типа файла. CSV- и Excel-файлы загружаются в Pandas DataFrames для сложного анализа данных, в то время как PDF, Word-файлы и текстовые документы разбиваются на фрагменты и индексируются с помощью FAISS для семантического поиска.
Управление источниками
Важно правильно указывать все источники, чтобы гарантировать, что предоставленная информация может быть отслежена до авторитетного источника. Этот шаг в рабочем процессе помогает укрепить доверие аудитории, позволяя ей проверить любые утверждения или данные, представленные в итоговом отчете.
Синтез ответа
Чтобы связать воедино всю собранную информацию, агент объединяет инсайты из всех проанализированных источников данных для формирования связного ответа. Без этого этапа рабочего процесса вывод может оказаться разрозненным отчетом.
Реализация рабочего процесса аналитики на основе RAG
До сих пор вы получили представление о том, что такое система аналитики продаж на основе RAG. Теперь пришло время её реализовать. Для начала выполним несколько ключевых шагов:
Установка и настройка
Прежде чем продолжить, создадим полную структуру файлов для нашей RAG-аналитической системы. Вам нужно создать следующие файлы в директории проекта:
| rag-analytics-system/ ├── .env # Переменные окружения ├── requirements.txt # Python-зависимости ├── query_processor.py # Главный класс QueryProcessor ├── main.py # Интерфейс Streamlit |
Установка зависимостей
Сначала обновите файл requirements.txt со всеми необходимыми зависимостями:
| langchain==0.3.26 langchain-openai==0.3.25 python-dotenv==1.1.1 SQLAlchemy==2.0.41 pandas==2.3.0 PyPDF2==3.0.1 faiss-cpu==1.11.0 PyMySQL==1.1.1 cryptography==45.0.4 langchain-experimental==0.3.4 streamlit==1.46.0 openpyxl==3.1.5 python-docx==1.2.0 |
Затем войдите в Novita AI. После входа перейдите на страницу Manage API Keys, нажмите кнопку Add New Key и введите Key Name.
Novita AI предоставит вам бесплатные кредиты для тестирования различных моделей после регистрации, так что вам не нужно беспокоиться о покупке кредитов до начала создания или экспериментов. Добавьте свои учетные данные в файл .env, например созданный ранее Novita API Key:
| NOVITA_API_KEY=”your_novita_api_key_here” |
Теперь установите все необходимые зависимости для проекта:
| # Создайте виртуальное окружение python -m venv rag_analytics_env source rag_analytics_env/bin/activate # В Windows: rag_analytics_env\\Scripts\\activate # Установите зависимости pip install -r requirements.txt |
Создание обработчика запросов (QueryProcessor)
Весь рабочий процесс RAG-аналитики инкапсулирован в модульный класс под названием QueryProcessor. Этот класс будет управлять процессом маршрутизации запросов, выполнения SQL-анализа, обработки документов, синтеза результатов и запуска полного цикла анализа.
QueryProcessor служит центральным оркестратором нашей аналитической системы. Вместо создания отдельных инструментов для разных типов данных, этот унифицированный подход позволяет интеллектуально направлять запросы к наиболее подходящему методу анализа — будь то базы данных SQL, CSV-файлы или неструктурированные документы.
Сначала импортируем необходимые библиотеки для проекта в файл query_processor.py. Эти импорты предоставляют все необходимое для интеграции с языковыми моделями, подключения к базам данных, обработки документов и векторного хранения:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.agent_toolkits.sql.base import create_sql_agent
from langchain_experimental.agents.agent_toolkits import create_csv_agent, create_pandas_dataframe_agent
from langchain_community.agent_toolkits.sql.toolkit import SQLDatabaseToolkit
from langchain.agents import AgentType
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.utilities import SQLDatabase
from langchain.prompts import PromptTemplate
from langchain_community.tools import ReadFileTool
from langchain.schema import Document
import os
from dotenv import load_dotenv
from sqlalchemy.engine import Engine
import glob
import pandas as pd
load_dotenv()
Далее инициализируем аналитического агента с доступом к LLM через API Novita и различными инструментами обработки данных. Метод инициализации настраивает все основные компоненты, которые нам понадобятся: языковую модель для понимания запросов, эмбеддинги для поиска по сходству документов и разделитель текста для эффективной обработки больших документов.
class QueryProcessor:
def __init__(self, documents_folder: str, sql_engine: Engine):
self.documents_folder = documents_folder
self.sql_engine = sql_engine
self.llm = ChatOpenAI(
model="google/gemma-3-27b-it",
temperature=0,
openai_api_key=os.getenv("NOVITA_API_KEY"),
openai_api_base="<https://api.novita.ai/v3/openai>",
default_headers={
"X-Model-Provider": "google"
}
)
self.embeddings = OpenAIEmbeddings(
model="baai/bge-m3",
openai_api_key=os.getenv("NOVITA_API_KEY"),
openai_api_base="<https://api.novita.ai/v3/openai>",
default_headers={
"X-Model-Provider": "baai"
}
)
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
self.sql_agent = None
self._prepare_data_sources()
Конструктор инициализирует несколько ключевых компонентов. Мы используем температуру 0 для LLM, чтобы обеспечить согласованные, фактические ответы, а не творческие вариации. Разделитель текста настроен с перекрывающимися фрагментами для сохранения непрерывности контекста при обработке больших документов. В конце вызывается метод _prepare_data_sources() для настройки наших специализированных агентов.
Создание многопрофильной интеграции данных
Следующий шаг включает создание методов, которые инициализируют различные агенты обработки данных. Каждый агент специализируется на обработке определенных типов данных и задач анализа, подобно тому как разные эксперты занимаются различными вопросами.
def _prepare_data_sources(self):
"""Prepare both SQL and document data sources"""
# Prepare SQL agent
self._prepare_sql_agent()
# Prepare document agent
self._prepare_document_agent()
def _prepare_sql_agent(self):
"""Initialize SQL agent"""
# Convert SQLAlchemy Engine to LangChain SQLDatabase
db = SQLDatabase(self.sql_engine)
toolkit = SQLDatabaseToolkit(db=db, llm=self.llm)
self.sql_agent = create_sql_agent(
llm=self.llm,
toolkit=toolkit,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
def _prepare_document_agent(self):
"""Initialize document agent using ReadFileTool and vector store"""
# Get all supported files
supported_files = []
for ext in ['*.txt', '*.pdf', '*.docx', '*.xlsx', '*.xls', '*.csv']:
supported_files.extend(glob.glob(os.path.join(self.documents_folder, ext)))
print(f"\
Found {len(supported_files)} supported files in {self.documents_folder}")
if supported_files:
# Create ReadFileTool
read_file_tool = ReadFileTool()
# Create tools list
tools = [read_file_tool]
# Create the prompt template for the react agent
prompt = PromptTemplate.from_template("""
You are a helpful assistant that can answer questions about business documents.
You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought: I should read the relevant documents to find the answer
{agent_scratchpad}
""")
agent = create_react_agent(self.llm, tools, prompt)
self.document_agent = AgentExecutor.from_agent_and_tools(
agent=agent,
tools=tools,
verbose=True
)
print("\
Document agent initialized successfully")
else:
print("\
No documents found in the specified folder.")
Метод _prepare_sql_agent() создает специализированного агента для запросов к базе данных. Мы используем тип агента ZERO_SHOT_REACT_DESCRIPTION, что означает, что агент может рассуждать о SQL-запросах без необходимости в конкретных примерах, что делает его адаптируемым к различным схемам баз данных. Метод _prepare_document_agent() сканирует поддерживаемые типы файлов и создает гибкого агента, способного читать различные форматы документов. Шаблон подсказки ReAct (Reasoning and Acting) направляет агента через структурированный процесс мышления, аналогично тому, как человек-аналитик подошел бы к анализу документов.
Обработка документов и векторное хранение
Затем нам нужно обработать, как рабочий процесс обрабатывает различные типы документов. Этот раздел создает методы, которые обрабатывают CSV/Excel-файлы с помощью pandas-агентов и неструктурированные документы с помощью векторного хранилища. Ключевой момент здесь заключается в том, что разные типы данных требуют разных стратегий обработки.
CSV_PROMPT_PREFIX = """
IMPORTANT: You are working with a pandas DataFrame called 'df' that has been loaded with the actual data.
DO NOT create sample data or make up data. Use ONLY the actual DataFrame 'df' that is available to you.
First, explore the DataFrame by:
1. Setting pandas display options to show all columns: pd.set_option('display.max_columns', None)
2. Check the shape of the DataFrame: print(df.shape)
3. Get the column names: print(df.columns.tolist())
4. Check the data types: print(df.dtypes)
5. Look at the first few rows: print(df.head())
6. Then answer the question using the actual data in the DataFrame.
"""
CSV_PROMPT_SUFFIX = """
- **CRITICAL**: Use ONLY the actual data in the DataFrame. Do NOT create sample data or use fictional data.
- **ALWAYS** before giving the Final Answer, try another method to verify your results.
- Then reflect on the answers of the two methods you did and ask yourself if it answers correctly the original question.
- If you are not sure, try another method.
- FORMAT 4 FIGURES OR MORE WITH COMMAS.
- If the methods tried do not give the same result, reflect and try again until you have two methods that have the same result.
- If you still cannot arrive to a consistent result, say that you are not sure of the answer.
- If you are sure of the correct answer, create a beautiful and thorough response using Markdown.
- **DO NOT MAKE UP AN ANSWER OR USE PRIOR KNOWLEDGE, ONLY USE THE RESULTS OF THE CALCULATIONS YOU HAVE DONE**.
- **ALWAYS**, as part of your "Final Answer", explain how you got to the answer on a section that starts with: "\\
\\
Explanation:\\
".
- In the explanation, mention the column names that you used to get to the final answer.
- Show your work by displaying relevant DataFrame operations and their results.
"""
def _process_document_query(self, query: str) -> str:
"""Process document query using CSV/Excel agents for tabular data, and LLM for unstructured data."""
try:
print(f"\\
Processing query: {query}")
# Get all supported files
supported_files = []
for ext in ['*.txt', '*.pdf', '*.docx', '*.xlsx', '*.xls', '*.csv']:
supported_files.extend(glob.glob(os.path.join(self.documents_folder, ext)))
print(f"Found {len(supported_files)} supported files in {self.documents_folder}")
if not supported_files:
return "No documents found to search through."
# Check for CSV/Excel files first
csv_files = [f for f in supported_files if f.endswith('.csv')]
excel_files = [f for f in supported_files if f.endswith(('.xlsx', '.xls'))]
if csv_files:
csv_file = csv_files[0]
print(f"\
Processing CSV file: {csv_file}")
try:
# First try with pandas DataFrame agent
df = pd.read_csv(csv_file)
print(f"CSV loaded successfully with {len(df)} rows and columns: {df.columns.tolist()}")
# Create the agent with improved configuration
print("Creating pandas DataFrame agent...")
agent = create_pandas_dataframe_agent(
self.llm,
df,
verbose=True,
include_df_in_prompt=False, # Avoid token limits with large DataFrames
allow_dangerous_code=True,
max_iterations=10,
handle_parsing_errors=True
)
# Process the query with our custom prompt
print(f"Processing query with agent: {query}")
# Improved prompt that ensures agent uses the actual DataFrame
prompt = f"""
You have access to a pandas DataFrame called 'df' with {len(df)} rows and the following columns: {df.columns.tolist()}.
Here are the first few rows of the data:
{df.head().to_string()}
Data types:
{df.dtypes.to_string()}
{self.CSV_PROMPT_PREFIX}
Question: {query}
{self.CSV_PROMPT_SUFFIX}
"""
response = agent.invoke({"input": prompt})
print(f"Agent response: {response}")
return response['output']
except Exception as e:
print(f"Error with pandas DataFrame agent: {str(e)}")
print("Trying alternative CSV agent...")
# Fallback to CSV agent
try:
agent = create_csv_agent(
self.llm,
csv_file,
verbose=True,
allow_dangerous_code=True
)
enhanced_query = f"""
{self.CSV_PROMPT_PREFIX}
Question: {query}
{self.CSV_PROMPT_SUFFIX}
"""
response = agent.invoke({"input": enhanced_query})
return response['output']
except Exception as e2:
print(f"Error processing CSV file: {str(e2)}")
import traceback
print(f"Full traceback: {traceback.format_exc()}")
return f"Error processing CSV file: {str(e2)}"
elif excel_files:
excel_file = excel_files[0]
print(f"\
Processing Excel file: {excel_file}")
try:
df = pd.read_excel(excel_file)
print(f"Excel loaded successfully with {len(df)} rows and columns: {df.columns.tolist()}")
# Create the agent with improved configuration
print("Creating pandas DataFrame agent...")
agent = create_pandas_dataframe_agent(
self.llm,
df,
verbose=True,
include_df_in_prompt=False, # Avoid token limits with large DataFrames
allow_dangerous_code=True,
max_iterations=10,
handle_parsing_errors=True
)
# Process the query with our custom prompt
print(f"Processing query with agent: {query}")
# Improved prompt that ensures agent uses the actual DataFrame
prompt = f"""
You have access to a pandas DataFrame called 'df' with {len(df)} rows and the following columns: {df.columns.tolist()}.
Here are the first few rows of the data:
{df.head().to_string()}
Data types:
{df.dtypes.to_string()}
{self.CSV_PROMPT_PREFIX}
Question: {query}
{self.CSV_PROMPT_SUFFIX}
"""
response = agent.invoke({"input": prompt})
print(f"Agent response: {response}")
return response['output']
except Exception as e:
print(f"Error processing Excel file: {str(e)}")
import traceback
print(f"Full traceback: {traceback.format_exc()}")
return f"Error processing Excel file: {str(e)}"
# For unstructured text files
print("\
Processing unstructured text files...")
all_content = []
for file_path in supported_files:
try:
if file_path.endswith('.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
all_content.append(Document(page_content=content, metadata={"source": file_path}))
except Exception as e:
print(f"Error reading file {file_path}: {str(e)}")
continue
if not all_content:
return "Could not read any documents."
# Process unstructured text using vector store
print("Processing text with vector store...")
chunks = self.text_splitter.split_documents(all_content)
vector_store = FAISS.from_documents(chunks, self.embeddings)
relevant_docs = vector_store.similarity_search(query, k=3)
context = "\\
\\
".join([doc.page_content for doc in relevant_docs])
print(f"Generated context length: {len(context)}")
response = self.llm.invoke(
f"""Based on the following context, answer the question: {query}
\\
Context:\\
{context}\\
\\
Answer:"""
)
return response.content
except Exception as e:
print(f"Error processing document query: {str(e)}")
import traceback
print(f"Full traceback: {traceback.format_exc()}")
return f"Error processing document query: {str(e)}"
Раздел обработки CSV включает детальный промпт-инжиниринг для обеспечения точного анализа. Префиксные и суффиксные подсказки имеют решающее значение, поскольку они предотвращают галлюцинирование данных агентом или предоставление неверных результатов. Шаг верификации, когда агент пробует несколько методов, помогает обеспечить точность, подобно тому как внимательный аналитик перепроверяет свои расчеты. Мы отдаем приоритет агентам pandas DataFrame перед CSV-агентами, потому что они обеспечивают более надежную обработку данных и лучшую производительность с большими наборами данных. Механизм fallback гарантирует, что если один подход не сработает, у нас есть альтернативные методы для обработки данных. Теперь завершим метод _process_document_query для обработки Excel-файлов и неструктурированных документов:
elif excel_files:
excel_file = excel_files[0]
print(f"\
Processing Excel file: {excel_file}")
try:
df = pd.read_excel(excel_file)
print(f"Excel loaded successfully with {len(df)} rows and columns: {df.columns.tolist()}")
# Create the agent with improved configuration
print("Creating pandas DataFrame agent...")
agent = create_pandas_dataframe_agent(
self.llm,
df,
verbose=True,
include_df_in_prompt=False, # Avoid token limits with large DataFrames
allow_dangerous_code=True,
max_iterations=10,
handle_parsing_errors=True
)
# Process the query with our custom prompt
print(f"Processing query with agent: {query}")
# Improved prompt that ensures agent uses the actual DataFrame
prompt = f"""
You have access to a pandas DataFrame called 'df' with {len(df)} rows and the following columns: {df.columns.tolist()}.
Here are the first few rows of the data:
{df.head().to_string()}
Data types:
{df.dtypes.to_string()}
{self.CSV_PROMPT_PREFIX}
Question: {query}
{self.CSV_PROMPT_SUFFIX}
"""
response = agent.invoke({"input": prompt})
print(f"Agent response: {response}")
return response['output']
except Exception as e:
print(f"Error processing Excel file: {str(e)}")
import traceback
print(f"Full traceback: {traceback.format_exc()}")
return f"Error processing Excel file: {str(e)}"
# For unstructured text files
print("\
Processing unstructured text files...")
all_content = []
for file_path in supported_files:
try:
if file_path.endswith('.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
all_content.append(Document(page_content=content, metadata={"source": file_path}))
except Exception as e:
print(f"Error reading file {file_path}: {str(e)}")
continue
if not all_content:
return "Could not read any documents."
# Process unstructured text using vector store
print("Processing text with vector store...")
chunks = self.text_splitter.split_documents(all_content)
vector_store = FAISS.from_documents(chunks, self.embeddings)
relevant_docs = vector_store.similarity_search(query, k=3)
context = "\\
\\
".join([doc.page_content for doc in relevant_docs])
print(f"Generated context length: {len(context)}")
response = self.llm.invoke(
f"""Based on the following context, answer the question: {query}
\\
Context:\\
{context}\\
\\
Answer:"""
)
return response.content
except Exception as e:
print(f"Error processing document query: {str(e)}")
import traceback
print(f"Full traceback: {traceback.format_exc()}")
return f"Error processing document query: {str(e)}"
Интеграция с SQL-базой данных
Теперь, когда мы разобрались с обработкой документов, нам нужно создать интеллектуальную систему маршрутизации запросов, которая решает, какой анализ использовать — SQL или документный. Это ядро интеллекта нашей системы — определение того, какой источник данных с наибольшей вероятностью содержит ответ на заданный вопрос.
def process_query(self, query: str) -> str:
"""
Process query using agents to intelligently decide between SQL and documents
"""
# First try SQL agent
try:
print("\\
Trying SQL Agent...")
sql_result = self.sql_agent.run(query)
no_answer_phrases = [
"no results", "i don't know", "unknown", "not sure", "cannot answer", "don't have", "no data", "n/a"
]
if sql_result and not any(phrase in sql_result.lower() for phrase in no_answer_phrases) and sql_result.strip():
return f"From SQL Database: {sql_result}"
else:
print("SQL Agent could not answer, trying documents...")
except Exception as e:
print(f"SQL Agent Error: {str(e)}")
print("Falling back to documents...")
# If SQL agent fails or returns no results, try document processing
try:
print("\\
Processing documents...")
doc_result = self._process_document_query(query)
if doc_result:
return f"From Documents: {doc_result}"
else:
print("Document processing returned no results")
except Exception as e:
print(f"Document Processing Error: {str(e)}")
return "Could not find relevant information in either SQL database or documents."
Логика маршрутизации запросов следует системе приоритетов: сначала пробуются базы данных SQL, потому что они обычно содержат структурированные количественные данные, которые могут быстро и точно ответить на бизнес-вопросы. Если SQL-агент возвращает неясные или отрицательные ответы (определяемые через наш список no_answer_phrases), система автоматически переключается на обработку документов. Этот подход имитирует работу человека-аналитика: сначала проверить структурированные источники данных, затем обратиться к документам и отчетам, если в базе данных нет нужной информации.
Создание интерфейса Streamlit
Теперь давайте создадим пользовательский интерфейс, который сделает нашу аналитическую систему доступной для бизнес-пользователей. Интерфейс Streamlit предлагает интуитивный чат-интерфейс, который скрывает техническую сложность, предоставляя при этом мощные аналитические возможности. Добавьте следующие фрагменты кода в файл main.py:
import streamlit as st
from query_processor import QueryProcessor
import os
from dotenv import load_dotenv
from sqlalchemy import create_engine
# Load environment variables
load_dotenv()
#st.text_input
# Initialize session state
if 'processor' not in st.session_state:
st.session_state.processor = None
if 'messages' not in st.session_state:
st.session_state.messages = []
# Set page config
st.set_page_config(
page_title="Document Analysis Chatbot",
page_icon="🤖",
layout="wide"
)
# Custom CSS for button and title styling
st.markdown("""
<style>
.stButton > button {
background-color: #23D57C;
color: white;
border: none;
border-radius: 8px;
padding: 0.5rem 1rem;
font-weight: 600;
transition: all 0.3s ease;
}
.stButton > button:hover {
background-color: #1fb36b;
box-shadow: 0 4px 8px rgba(35, 213, 124, 0.3);
transform: translateY(-2px);
}
.stButton > button:active {
background-color: #1a9960;
transform: translateY(0px);
}
h1 {
color: #23D57C !important;
font-weight: 700;
}
</style>
""", unsafe_allow_html=True)
# Title and description
st.title("Document Analysis Chatbot using Novita")
Эта начальная настройка создает профессионально выглядящий интерфейс с пользовательскими стилями. Управление состоянием сессии гарантирует, что пользователи не потеряют историю разговора или не будут вынуждены повторно инициализировать источники данных при взаимодействии с интерфейсом. Пользовательские CSS обеспечивают визуальную обратную связь и поддерживают единый стиль бренда.
Финальная интеграция системы
Давайте завершим интерфейс Streamlit, добавив инициализацию источника данных и функциональность чата. Этот заключительный раздел объединяет все наши компоненты в удобное приложение, которое бизнес-аналитики могут использовать без специальных технических знаний.
# Check if data source is initialized
if st.session_state.processor is None:
# Center the data source configuration
st.markdown("<br><br>", unsafe_allow_html=True)
# Create centered columns
col1, col2, col3 = st.columns([1, 2, 1])
with col2:
st.subheader("🚀 Get Started")
st.write("Initialize your data source to start chatting with your documents")
# SQL Database Configuration (hidden)
db_user = "root"
db_password = "1234cisco"
db_host = "localhost"
db_name = "retail_sales_db"
# Documents Folder Configuration
st.write("**Documents Folder Path:**")
documents_folder = st.text_input(
"Documents Folder Path",
placeholder="Enter path to your documents folder (e.g., docs)",
label_visibility="collapsed"
)
st.markdown("<br>", unsafe_allow_html=True)
# Center the button
button_col1, button_col2, button_col3 = st.columns([1, 1, 1])
with button_col2:
if st.button("Initialize Data Source", use_container_width=True):
try:
# Validate and resolve documents folder path
if not documents_folder:
st.error("Please provide a documents folder path")
else:
# Convert to absolute path
abs_documents_folder = os.path.abspath(documents_folder)
if not os.path.exists(abs_documents_folder):
st.error(f"Documents folder not found: {abs_documents_folder}")
elif not os.path.isdir(abs_documents_folder):
st.error(f"Path is not a directory: {abs_documents_folder}")
else:
# Initialize query processor with a dummy SQL engine
# Create SQL engine
connection_string = f"mysql+pymysql://{db_user}:{db_password}@{db_host}/{db_name}"
sql_engine = create_engine(connection_string)
st.session_state.processor = QueryProcessor(abs_documents_folder, sql_engine)
st.success("Data source initialized successfully!")
st.rerun()
except Exception as e:
st.error(f"Error initializing data source: {str(e)}")
else:
# Show data source status in sidebar
with st.sidebar:
st.header("📊 Data Source")
st.success("✅ Data source initialized")
if st.button("Reset Data Source"):
st.session_state.processor = None
st.session_state.messages = []
st.rerun()
# Main chat interface
st.header("Chat Interface")
# Display chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
# Chat input
if prompt := st.chat_input("Ask a question about your documents"):
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Process query
try:
response = st.session_state.processor.process_query(prompt)
# Add assistant response to chat history
st.session_state.messages.append({"role": "assistant", "content": response})
with st.chat_message("assistant"):
st.write(response)
except Exception as e:
st.error(f"Error processing query: {str(e)}")
# Add a clear chat button only if there are messages
if st.session_state.messages:
if st.button("Clear Chat"):
st.session_state.messages = []
st.rerun()
Процесс инициализации включает надежную обработку ошибок и проверку путей для предотвращения распространенных ошибок пользователей. Боковая панель предоставляет четкую информацию о статусе, а интерфейс чата следует знакомым шаблонам, которые пользователи ожидают от современных AI-ассистентов. Система сохраняет историю разговора, позволяя пользователям опираться на предыдущие вопросы и создавать естественный аналитический рабочий процесс. Функция очистки чата позволяет начать заново при необходимости.
Запуск аналитической системы
Теперь, когда мы построили систему аналитики продаж на основе RAG, давайте протестируем её и посмотрим, как хорошо она справляется с реальными бизнес-запросами.
Сначала создайте файл data_generator.py и скопируйте код из Python-скрипта здесь, чтобы сгенерировать пример данных для системы, затем запустите скрипт командой:
| python data_generator.py |
Это создаст папку sample_documents со следующими файлами:
large_sales_dataset.csv— 10 000 записей о продажахbusiness_strategy_2024.txt— стратегический бизнес-документsales_meeting_notes.txt— заметки с встреч и пункты действий
Затем запустите приложение Streamlit:
| streamlit run main.py |
Приложение откроется в вашем браузере по адресу http://localhost:8501.

После инициализации вы можете протестировать систему, указав путь к документам sample_documents и задавая различные бизнес-вопросы:
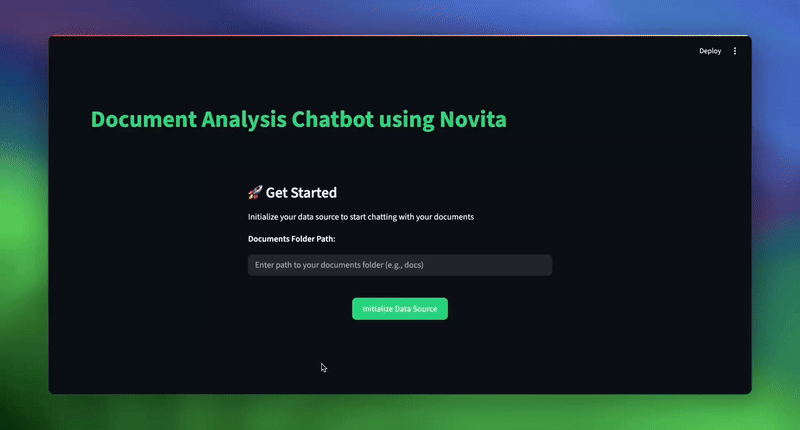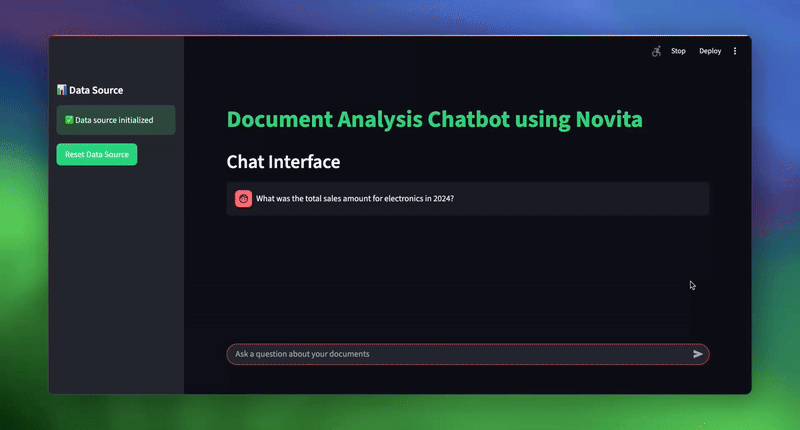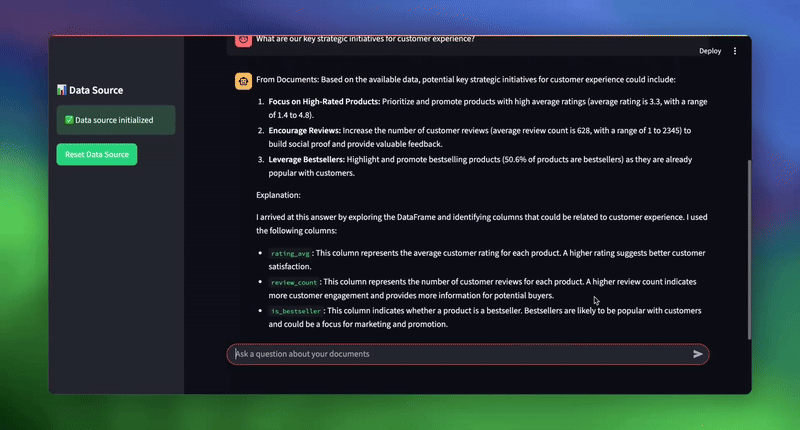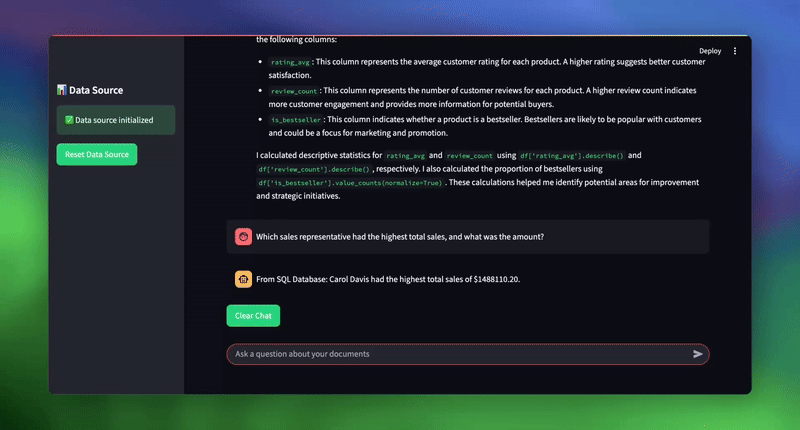
| # Sample queries to test the system topic_1 = “What was the total sales amount for electronics in 2024?” topic_2 = “What are our key strategic initiatives for customer experience?” topic_3 = “Which sales representative had the highest total sales, and what was the amount?” |
Заключение
В ходе этого руководства мы построили систему аналитики на основе RAG, которая демонстрирует, как современный AI может трансформировать рабочие процессы бизнес-аналитики. Объединив несколько подходов к обработке данных под единым интеллектуальным интерфейсом, мы создали инструмент, способный обрабатывать весь спектр бизнес-вопросов, с которыми ежедневно сталкиваются аналитики. Ключевые сильные стороны системы включают:
- Интеллектуальную маршрутизацию запросов, которая автоматически определяет наилучший источник данных для каждого вопроса
- Многоформатную поддержку для работы с базами данных SQL, CSV-файлами, электронными таблицами Excel и текстовыми документами
- Надежную обработку ошибок с механизмами fallback и понятными сообщениями об ошибках
- Чат-интерфейс, не требующий технических знаний
- Встроенную проверку и валидацию для обеспечения достоверных результатов
Вы можете расширить это приложение, добавив дополнительные источники, более продвинутые методы анализа и собственную бизнес-логику. Теперь, обладая этими знаниями, попробуйте создать своих собственных агентов с помощью Novita AI или интегрировать их в существующие проекты.
Novita AI — это универсальная облачная платформа, которая расширяет ваши AI-амбиции. Интегрированные API, бессерверные вычисления, GPU-инстансы — экономичные инструменты, которые вам нужны. Устраните инфраструктурные проблемы, начните бесплатно и воплотите ваше AI-видение в реальность.



