

تقدم العديد من شركات الذكاء الاصطناعي حاليًا أنظمة ذكاء أعمال تعتمد على الوكلاء (agentic BI) قادرة على تحليل بياناتك في الحال وتقديم رؤى شاملة دون الحاجة إلى استعلامات SQL معقدة أو تحليل يدوي لجداول البيانات. على سبيل المثال، يمكن لنظام تحليلات مبيعات يعمل بتقنية RAG الإجابة على أسئلة مثل “ما هو المنتج الأعلى مبيعًا لدينا في الربع الأخير؟” في ثوانٍ بدلاً من ساعات.
يحل نظام تحليلات المبيعات القائم على RAG هذه المشكلات باستخدام وكلاء ذكاء اصطناعي يمكنهم التفكير بشكل مستقل، واتخاذ القرارات، وتنسيق الأدوات الخارجية لتمكين الاستعلامات باللغة الطبيعية عبر نظامك البيئي للبيانات بالكامل. بدلاً من تعلم مخططات قواعد البيانات أو صيغ جداول البيانات، يقوم الوكيل بتفكيك استفسارك، وتحديد أفضل مصدر بيانات، وإجراء تحليل مستهدف، وتقديم إجابات شاملة مدعومة بالبيانات مع الاستشهادات المناسبة.
على سبيل المثال، يمكنك استخدام LLM مختلف، أو تنسيق مستند مخصص، أو ضبط كيفية تحليل الوكلاء وتصرفهم لإنتاج مخرجات تجارية محددة. في هذا البرنامج التعليمي، ستتعلم كيفية بناء نظام تحليلات مبيعات خاص بك يعمل بتقنية RAG باستخدام واجهة LLM الموحدة من Novita AI، وإطار عمل الوكيل LangChain، وقدرات معالجة المستندات المتقدمة. ستقوم بإنشاء نظام يقوم تلقائيًا بتوجيه الاستعلامات إلى مصادر البيانات المثلى وتقديم رؤى تجارية قابلة للتنفيذ.
ما هو نظام تحليلات المبيعات المدعوم بـ RAG؟
يستخدم نظام تحليلات المبيعات المدعوم بـ RAG تقنية الاسترجاع المعزز بالتوليد (RAG) لتقديم إجابات دقيقة ومدعومة لأسئلة مبيعات التجزئة من خلال الجمع بين قوة نماذج اللغة الكبيرة (LLMs) مع طبقة استرجاع يمكنها الوصول إلى بيانات عملك الفعلية.
يتضمن هذا النظام عادةً ما يلي:
- يقوم وكيل الذكاء الاصطناعي بتحليل الاستعلام وتحديد ما إذا كان يتطلب تحليل بيانات منظم (SQL) أو تحليل مستندات، أو كليهما.
- يقوم الوكيل بتوجيه الاستعلامات بذكاء إلى مصدر البيانات الأكثر ملاءمة – قواعد البيانات SQL للتحليل الكمي أو مخازن المستندات للرؤى النوعية.
- يستخدم الوكيل أدوات متنوعة لجمع المعلومات، بما في ذلك وكلاء Pandas لتحليل ملفات CSV، ووكلاء SQL للاستعلام عن قواعد البيانات، ومخازن المتجهات لاسترجاع المستندات. لا يمكن للوكيل أداء المهام الأساسية في سير العمل بدون هذه الأدوات.
- يقوم الوكيل بمعالجة المعلومات التي تم جمعها باستخدام تقنيات متخصصة، التحليل الإحصائي للبيانات الرقمية والبحث الدلالي للمستندات النصية.
- بعد تحليل البيانات، يقوم الوكيل بإنشاء استجابة منظمة تتضمن ملخصات وحسابات واستشهادات مناسبة.
الأدوات التي ستحتاجها
قبل أن نبدأ في جزء البناء من هذه المقالة، دعنا نجهز الأدوات اللازمة.
Novita AI
لبناء نظام التحليلات القائم على RAG، سنحتاج إلى الوصول إلى نماذج لغوية كبيرة (LLMs) قوية ونماذج تضمين. تقدم Novita AI واجهات برمجة تطبيقات عالية الأداء وبأسعار معقولة توفر الوصول إلى أحدث نماذج اللغات الكبيرة (LLMs) ونماذج التضمين والمزيد من خلال واجهة واحدة موحدة.
LangChain
LangChain هو إطار عمل مفتوح المصدر مصمم لبناء التطبيقات باستخدام LLMs. باستخدام LangChain، يمكنك إنشاء سير عمل وكيل يستنتج خطوة بخطوة، ويستخدم الأدوات، ويتفاعل مع واجهات برمجة التطبيقات. بالنسبة لنظام تحليلات المبيعات الخاص بنا، سنستخدم LangChain لتنظيم عملية التحليل، وتوظيف أدوات مثل وكلاء SQL ومعالجات المستندات، وتجميع جميع البيانات في رؤى منظمة.

Streamlit
سنستخدم Streamlit لبناء واجهة الويب التفاعلية. إنها مثالية للنماذج الأولية السريعة وتنشئ واجهات مستخدم ذات مظهر احترافي بأقل قدر من الكود، مما يجعل البرنامج التعليمي سهلاً للمتابعة.
FAISS
للبحث المستند إلى المتجهات، يوفر FAISS إمكانيات بحث تشابه سريعة، مما يمكننا من العثور بسرعة على أجزاء المستندات ذات الصلة بناءً على استفسارات المستخدم.
SQLAlchemy & PyMySQL
تتعامل هذه المكتبات مع عمليات قاعدة بيانات SQL والاتصال بـ MySQL، مما يسمح لنظامنا بالاستعلام مباشرة عن بيانات الأعمال المنظمة.
pandas
أساسي لمعالجة وتحليل بيانات CSV. يستخدم نظامنا وكلاء pandas لإجراء حسابات معقدة على البيانات الجدولية.
نظرة عامة على بنية النظام
يعالج نظام RAG الخاص بنا استفسارات المستخدم بذكاء من خلال سير عمل متعدد الخطوات يحدد تلقائيًا أفضل مصدر بيانات وطريقة معالجة لكل سؤال. بدلاً من إجبار المستخدمين على معرفة مكان وجود بياناتهم، يحدد النظام النهج الأمثل في الخلفية.
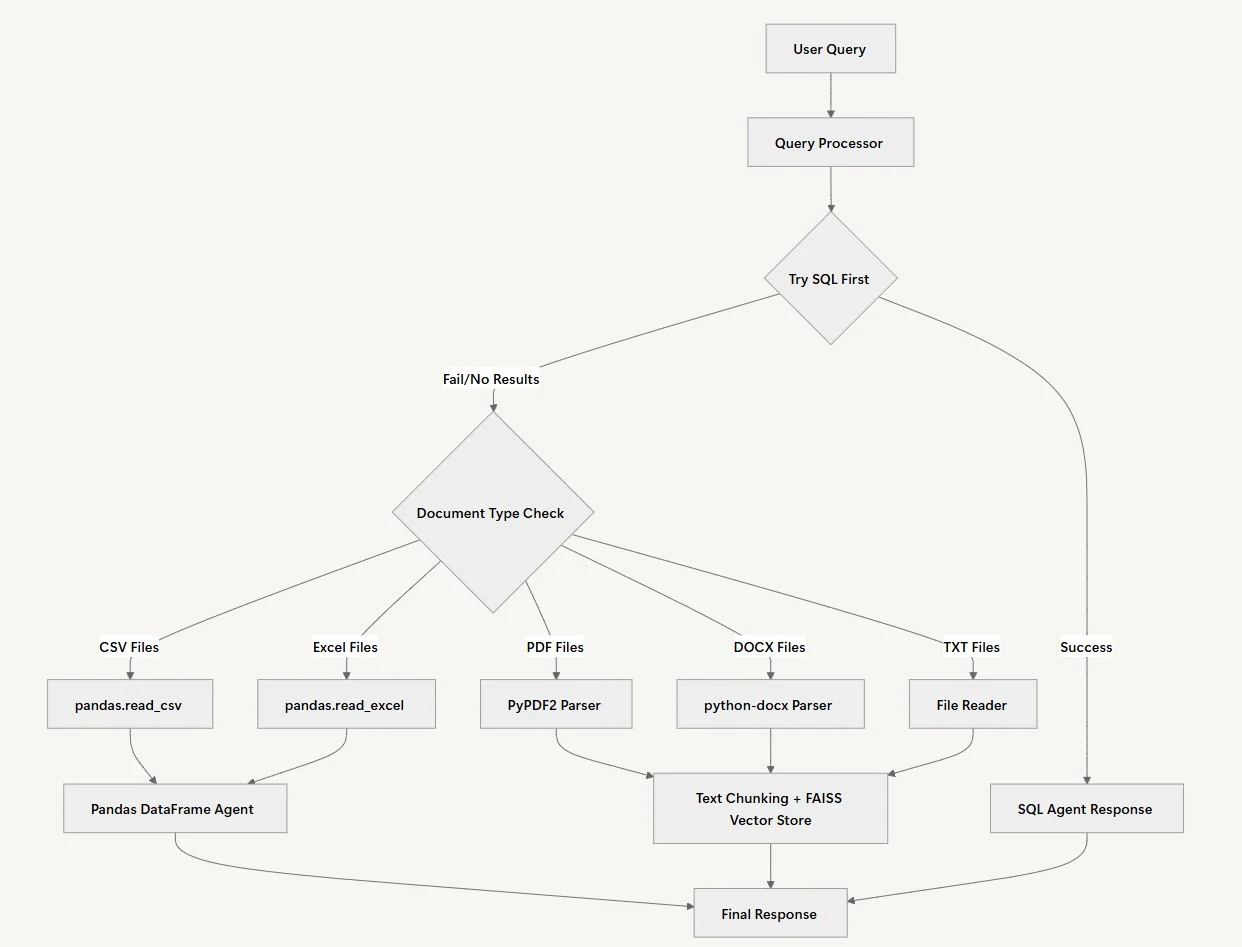
معالجة الاستعلام
الخطوة الأولية في عملية العمل لدينا مع الوكيل هي معالجة الاستعلام. في هذه الحالة، سيتحقق الوكيل من الاستعلام الذي قدمه المستخدم ويطور خطة معالجة مخصصة تناسب سياق الاستعلام. ثم سيحدد نوع البيانات التي يجب تحليل السؤال مقابلها، وهي بيانات منظمة، أو تحليل مستندات، أو كليهما.
اختيار مصدر البيانات
عندما يقدم المستخدم سؤالاً، يستخدم النظام نهجًا مباشرًا: يحاول حل المشكلة بالتشاور مع قاعدة بيانات SQL أولاً. هذا منطقي لأن البيانات المنظمة غالبًا ما توفر الإجابات الأكثر دقة للأسئلة الكمية. يمكن لوكيل SQL تنفيذ الاستعلامات بسرعة وإرجاع الأرقام الدقيقة مع الحسابات المناسبة.
تحليل المستندات
عندما يُرجع وكيل SQL نتائج فارغة أو لا يمكنه العثور على معلومات ذات صلة، يتحول النظام تلقائيًا إلى تحليل المستندات. يختلف مسار معالجة المستندات حسب نوع الملف. يتم تحميل ملفات CSV وExcel في DataFrames الخاصة بـ Pandas لتحليل البيانات المعقدة، بينما يتم تقسيم ملفات PDF وWord والمستندات النصية وفهرستها باستخدام FAISS للبحث الدلالي.
إدارة المصادر
من الضروري الاستشهاد بجميع المصادر بشكل صحيح لضمان إمكانية تتبع المعلومات المقدمة إلى جهة موثوقة. تساعد هذه الخطوة في سير العمل على بناء الثقة مع الجمهور، وتمكينهم من التحقق من أي ادعاءات أو بيانات مقدمة في التقرير النهائي.
تجميع الاستجابة
لربط النقاط بين جميع المعلومات التي تم جمعها، يقوم الوكيل بتجميع الرؤى من جميع مصادر البيانات التي تم تحليلها لتشكيل استجابة متماسكة. بدون هذه المرحلة من سير العمل، قد يكون الإخراج تقريرًا غير مترابط.
تنفيذ سير عمل التحليلات المدعوم بـ RAG
حتى الآن، اكتسبت فهمًا لماهية نظام تحليلات المبيعات المدعوم بـ RAG. حان الوقت الآن لتنفيذه. للبدء، سنقوم بعدة خطوات رئيسية:
التثبيت والإعداد
قبل المتابعة، دعنا ننشئ هيكل الملفات الكامل لنظام تحليلات RAG الخاص بنا. ستحتاج إلى إنشاء الملفات التالية في دليل مشروعك:
| rag-analytics-system/ ├── .env # متغيرات البيئة ├── requirements.txt # تبعيات Python ├── query_processor.py # فئة QueryProcessor الرئيسية ├── main.py # واجهة Streamlit |
إعداد التبعيات
أولاً، قم بتحديث ملف requirements.txt بجميع التبعيات الضرورية:
| langchain==0.3.26 langchain-openai==0.3.25 python-dotenv==1.1.1 SQLAlchemy==2.0.41 pandas==2.3.0 PyPDF2==3.0.1 faiss-cpu==1.11.0 PyMySQL==1.1.1 cryptography==45.0.4 langchain-experimental==0.3.4 streamlit==1.46.0 openpyxl==3.1.5 python-docx==1.2.0 |
ثم سجّل الدخول إلى Novita AI. بمجرد تسجيل الدخول، انتقل إلى صفحة إدارة مفاتيح API، وانقر على زر إضافة مفتاح جديد، وأدخل اسم المفتاح الخاص بك.
ستوفر لك Novita AI أرصدة مجانية لتجربة نماذج مختلفة بعد التسجيل، لذلك لا داعي للقلق بشأن شراء الأرصدة قبل البدء في البناء أو التجربة. أضف بيانات الاعتماد الخاصة بك إلى ملف .env مثل مفتاح Novita API الذي أنشأته سابقًا:
| NOVITA_API_KEY=“your_novita_api_key_here” |
الآن، قم بتثبيت جميع التبعيات المطلوبة للمشروع:
| # إنشاء بيئة افتراضية python -m venv rag_analytics_env source rag_analytics_env/bin/activate # على Windows: rag_analytics_env\\Scripts\\activate # تثبيت التبعيات pip install -r requirements.txt |
بناء معالج الاستعلام (Query Processor)
يتم تغليف سير عمل تحليلات RAG بالكامل في فئة معيارية تسمى QueryProcessor. ستقوم هذه الفئة بإدارة عملية توجيه الاستعلامات، وإجراء تحليل SQL، ومعالجة المستندات، وتجميع النتائج، وتشغيل حلقة التحليل الكاملة.
يعمل QueryProcessor كمنسق مركزي لنظام التحليلات الخاص بنا. بدلاً من بناء أدوات منفصلة لأنواع البيانات المختلفة، يسمح لنا هذا النهج الموحد بتوجيه الاستعلامات بذكاء إلى طريقة التحليل الأكثر ملاءمة، سواء كانت قواعد بيانات SQL، أو ملفات CSV، أو مستندات غير منظمة.
أولاً، سنقوم باستيراد المكتبات اللازمة للمشروع في ملف query_processor.py. توفر لنا هذه الاستيرادات كل ما نحتاجه لتكامل نموذج اللغة، والاتصال بقاعدة البيانات، ومعالجة المستندات، وتخزين المتجهات:
connectivity, document processing, and vector storage:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.agent_toolkits.sql.base import create_sql_agent
from langchain_experimental.agents.agent_toolkits import create_csv_agent, create_pandas_dataframe_agent
from langchain_community.agent_toolkits.sql.toolkit import SQLDatabaseToolkit
from langchain.agents import AgentType
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.utilities import SQLDatabase
from langchain.prompts import PromptTemplate
from langchain_community.tools import ReadFileTool
from langchain.schema import Document
import os
from dotenv import load_dotenv
from sqlalchemy.engine import Engine
import glob
import pandas as pd
load_dotenv()
بعد ذلك، نقوم بتهيئة وكيل التحليلات مع الوصول إلى LLM عبر Novita API وأدوات معالجة البيانات المختلفة. تقوم طريقة التهيئة بإعداد جميع المكونات الأساسية التي سنحتاجها: نموذج اللغة لفهم الاستعلامات، والتضمينات للبحث عن تشابه المستندات، وتقسيم النص لمعالجة المستندات الكبيرة بكفاءة.
class QueryProcessor:
def __init__(self, documents_folder: str, sql_engine: Engine):
self.documents_folder = documents_folder
self.sql_engine = sql_engine
self.llm = ChatOpenAI(
model="google/gemma-3-27b-it",
temperature=0,
openai_api_key=os.getenv("NOVITA_API_KEY"),
openai_api_base="<https://api.novita.ai/v3/openai>",
default_headers={
"X-Model-Provider": "google"
}
)
self.embeddings = OpenAIEmbeddings(
model="baai/bge-m3",
openai_api_key=os.getenv("NOVITA_API_KEY"),
openai_api_base="<https://api.novita.ai/v3/openai>",
default_headers={
"X-Model-Provider": "baai"
}
)
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
self.sql_agent = None
self._prepare_data_sources()
يقوم المُنشئ بتهيئة عدة مكونات رئيسية. نستخدم درجة حرارة (temperature) تساوي 0 لـ LLM لضمان استجابات متسقة وواقعية بدلاً من الاختلافات الإبداعية. تم تكوين مقسم النص بأجزاء متداخلة للحفاظ على استمرارية السياق عند معالجة المستندات الكبيرة. يتم استدعاء طريقة _prepare_data_sources() في النهاية لإعداد وكلائنا المتخصصين.
إنشاء تكامل متعدد المصادر للبيانات
تتضمن الخطوة التالية إنشاء طرق تقوم بتهيئة وكلاء معالجة بيانات مختلفين. يتخصص كل وكيل في التعامل مع أنواع بيانات محددة ومهام تحليلية، تمامًا مثل وجود خبراء مختلفين لأنواع مختلفة من الأسئلة.
def _prepare_data_sources(self):
"""Prepare both SQL and document data sources"""
# Prepare SQL agent
self._prepare_sql_agent()
# Prepare document agent
self._prepare_document_agent()
def _prepare_sql_agent(self):
"""Initialize SQL agent"""
# Convert SQLAlchemy Engine to LangChain SQLDatabase
db = SQLDatabase(self.sql_engine)
toolkit = SQLDatabaseToolkit(db=db, llm=self.llm)
self.sql_agent = create_sql_agent(
llm=self.llm,
toolkit=toolkit,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
def _prepare_document_agent(self):
"""Initialize document agent using ReadFileTool and vector store"""
# Get all supported files
supported_files = []
for ext in ['*.txt', '*.pdf', '*.docx', '*.xlsx', '*.xls', '*.csv']:
supported_files.extend(glob.glob(os.path.join(self.documents_folder, ext)))
print(f"\
Found {len(supported_files)} supported files in {self.documents_folder}")
if supported_files:
# Create ReadFileTool
read_file_tool = ReadFileTool()
# Create tools list
tools = [read_file_tool]
# Create the prompt template for the react agent
prompt = PromptTemplate.from_template("""
You are a helpful assistant that can answer questions about business documents.
You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought: I should read the relevant documents to find the answer
{agent_scratchpad}
""")
agent = create_react_agent(self.llm, tools, prompt)
self.document_agent = AgentExecutor.from_agent_and_tools(
agent=agent,
tools=tools,
verbose=True
)
print("\
Document agent initialized successfully")
else:
print("\
No documents found in the specified folder.")
تقوم طريقة _prepare_sql_agent() بإنشاء وكيل متخصص لاستعلامات قاعدة البيانات. نستخدم نوع الوكيل ZERO_SHOT_REACT_DESCRIPTION، مما يعني أن الوكيل يمكنه التفكير في استعلامات SQL دون الحاجة إلى أمثلة محددة، مما يجعله قابلاً للتكيف مع مخططات قواعد البيانات المختلفة. تقوم طريقة _prepare_document_agent() بمسح أنواع الملفات المدعومة وإنشاء وكيل مرن يمكنه قراءة تنسيقات المستندات المختلفة. يوجه قالب المطالبة ReAct (Reasoning and Acting) الوكيل خلال عملية تفكير منظمة، تشبه الطريقة التي يحلل بها المحلل البشري المستندات.
معالجة المستندات والتخزين المتجه
بعد ذلك، نحتاج إلى التعامل مع كيفية معالجة سير العمل لأنواع المستندات المختلفة. ينشئ هذا القسم طرقًا تتعامل مع ملفات CSV/Excel باستخدام وكلاء pandas والمستندات غير المنظمة باستخدام التخزين المتجه. الفكرة الرئيسية هنا هي أن أنواع البيانات المختلفة تتطلب استراتيجيات معالجة مختلفة.
CSV_PROMPT_PREFIX = """
IMPORTANT: You are working with a pandas DataFrame called 'df' that has been loaded with the actual data.
DO NOT create sample data or make up data. Use ONLY the actual DataFrame 'df' that is available to you.
First, explore the DataFrame by:
1. Setting pandas display options to show all columns: pd.set_option('display.max_columns', None)
2. Check the shape of the DataFrame: print(df.shape)
3. Get the column names: print(df.columns.tolist())
4. Check the data types: print(df.dtypes)
5. Look at the first few rows: print(df.head())
6. Then answer the question using the actual data in the DataFrame.
"""
CSV_PROMPT_SUFFIX = """
- **CRITICAL**: Use ONLY the actual data in the DataFrame. Do NOT create sample data or use fictional data.
- **ALWAYS** before giving the Final Answer, try another method to verify your results.
- Then reflect on the answers of the two methods you did and ask yourself if it answers correctly the original question.
- If you are not sure, try another method.
- FORMAT 4 FIGURES OR MORE WITH COMMAS.
- If the methods tried do not give the same result, reflect and try again until you have two methods that have the same result.
- If you still cannot arrive to a consistent result, say that you are not sure of the answer.
- If you are sure of the correct answer, create a beautiful and thorough response using Markdown.
- **DO NOT MAKE UP AN ANSWER OR USE PRIOR KNOWLEDGE, ONLY USE THE RESULTS OF THE CALCULATIONS YOU HAVE DONE**.
- **ALWAYS**, as part of your "Final Answer", explain how you got to the answer on a section that starts with: "\\
\\
Explanation:\\
".
- In the explanation, mention the column names that you used to get to the final answer.
- Show your work by displaying relevant DataFrame operations and their results.
"""
def _process_document_query(self, query: str) -> str:
"""Process document query using CSV/Excel agents for tabular data, and LLM for unstructured data."""
try:
print(f"\\
Processing query: {query}")
# Get all supported files
supported_files = []
for ext in ['*.txt', '*.pdf', '*.docx', '*.xlsx', '*.xls', '*.csv']:
supported_files.extend(glob.glob(os.path.join(self.documents_folder, ext)))
print(f"Found {len(supported_files)} supported files in {self.documents_folder}")
if not supported_files:
return "No documents found to search through."
# Check for CSV/Excel files first
csv_files = [f for f in supported_files if f.endswith('.csv')]
excel_files = [f for f in supported_files if f.endswith(('.xlsx', '.xls'))]
if csv_files:
csv_file = csv_files[0]
print(f"\
Processing CSV file: {csv_file}")
try:
# First try with pandas DataFrame agent
df = pd.read_csv(csv_file)
print(f"CSV loaded successfully with {len(df)} rows and columns: {df.columns.tolist()}")
# Create the agent with improved configuration
print("Creating pandas DataFrame agent...")
agent = create_pandas_dataframe_agent(
self.llm,
df,
verbose=True,
include_df_in_prompt=False, # Avoid token limits with large DataFrames
allow_dangerous_code=True,
max_iterations=10,
handle_parsing_errors=True
)
# Process the query with our custom prompt
print(f"Processing query with agent: {query}")
# Improved prompt that ensures agent uses the actual DataFrame
prompt = f"""
You have access to a pandas DataFrame called 'df' with {len(df)} rows and the following columns: {df.columns.tolist()}.
Here are the first few rows of the data:
{df.head().to_string()}
Data types:
{df.dtypes.to_string()}
{self.CSV_PROMPT_PREFIX}
Question: {query}
{self.CSV_PROMPT_SUFFIX}
"""
response = agent.invoke({"input": prompt})
print(f"Agent response: {response}")
return response['output']
except Exception as e:
print(f"Error with pandas DataFrame agent: {str(e)}")
print("Trying alternative CSV agent...")
# Fallback to CSV agent
try:
agent = create_csv_agent(
self.llm,
csv_file,
verbose=True,
allow_dangerous_code=True
)
enhanced_query = f"""
{self.CSV_PROMPT_PREFIX}
Question: {query}
{self.CSV_PROMPT_SUFFIX}
"""
response = agent.invoke({"input": enhanced_query})
return response['output']
except Exception as e2:
print(f"Error processing CSV file: {str(e2)}")
import traceback
print(f"Full traceback: {traceback.format_exc()}")
return f"Error processing CSV file: {str(e2)}"
elif excel_files:
excel_file = excel_files[0]
print(f"\
Processing Excel file: {excel_file}")
try:
df = pd.read_excel(excel_file)
print(f"Excel loaded successfully with {len(df)} rows and columns: {df.columns.tolist()}")
# Create the agent with improved configuration
print("Creating pandas DataFrame agent...")
agent = create_pandas_dataframe_agent(
self.llm,
df,
verbose=True,
include_df_in_prompt=False, # Avoid token limits with large DataFrames
allow_dangerous_code=True,
max_iterations=10,
handle_parsing_errors=True
)
# Process the query with our custom prompt
print(f"Processing query with agent: {query}")
# Improved prompt that ensures agent uses the actual DataFrame
prompt = f"""
You have access to a pandas DataFrame called 'df' with {len(df)} rows and the following columns: {df.columns.tolist()}.
Here are the first few rows of the data:
{df.head().to_string()}
Data types:
{df.dtypes.to_string()}
{self.CSV_PROMPT_PREFIX}
Question: {query}
{self.CSV_PROMPT_SUFFIX}
"""
response = agent.invoke({"input": prompt})
print(f"Agent response: {response}")
return response['output']
except Exception as e:
print(f"Error processing Excel file: {str(e)}")
import traceback
print(f"Full traceback: {traceback.format_exc()}")
return f"Error processing Excel file: {str(e)}"
# For unstructured text files
print("\\
Processing unstructured text files...")
all_content = []
for file_path in supported_files:
try:
if file_path.endswith('.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
all_content.append(Document(page_content=content, metadata={"source": file_path}))
except Exception as e:
print(f"Error reading file {file_path}: {str(e)}")
continue
if not all_content:
return "Could not read any documents."
# Process unstructured text using vector store
print("Processing text with vector store...")
chunks = self.text_splitter.split_documents(all_content)
vector_store = FAISS.from_documents(chunks, self.embeddings)
relevant_docs = vector_store.similarity_search(query, k=3)
context = "\\
\\
".join([doc.page_content for doc in relevant_docs])
print(f"Generated context length: {len(context)}")
response = self.llm.invoke(
f"""Based on the following context, answer the question: {query}
\\
Context:\\
{context}\\
\\
Answer:"""
)
return response.content
except Exception as e:
print(f"Error processing document query: {str(e)}")
import traceback
print(f"Full traceback: {traceback.format_exc()}")
return f"Error processing document query: {str(e)}"
يتضمن قسم معالجة CSV هندسة مطالبات دقيقة لضمان تحليل دقيق. تعتبر مطالبات البادئة واللاحقة حاسمة لأنها تمنع الوكيل من تخيل البيانات أو تقديم نتائج غير صحيحة. تساعد خطوة التحقق، حيث يحاول الوكيل طرقًا متعددة، في ضمان الدقة، تمامًا مثل المحلل الحريص الذي سيتحقق من حساباته. نعطي الأولوية لوكلاء DataFrame الخاصة بـ pandas على وكلاء CSV لأنها توفر معالجة بيانات أكثر قوة وأداء أفضل مع مجموعات البيانات الكبيرة. تضمن آلية الاحتياطي أنه إذا فشل أحد الأساليب، فلدينا طرق بديلة لمعالجة البيانات. الآن دعنا نكمل طريقة _process_document_query للتعامل مع ملفات Excel والمستندات غير المنظمة:
elif excel_files:
excel_file = excel_files[0]
print(f"\
Processing Excel file: {excel_file}")
try:
df = pd.read_excel(excel_file)
print(f"Excel loaded successfully with {len(df)} rows and columns: {df.columns.tolist()}")
# Create the agent with improved configuration
print("Creating pandas DataFrame agent...")
agent = create_pandas_dataframe_agent(
self.llm,
df,
verbose=True,
include_df_in_prompt=False, # Avoid token limits with large DataFrames
allow_dangerous_code=True,
max_iterations=10,
handle_parsing_errors=True
)
# Process the query with our custom prompt
print(f"Processing query with agent: {query}")
# Improved prompt that ensures agent uses the actual DataFrame
prompt = f"""
You have access to a pandas DataFrame called 'df' with {len(df)} rows and the following columns: {df.columns.tolist()}.
Here are the first few rows of the data:
{df.head().to_string()}
Data types:
{df.dtypes.to_string()}
{self.CSV_PROMPT_PREFIX}
Question: {query}
{self.CSV_PROMPT_SUFFIX}
"""
response = agent.invoke({"input": prompt})
print(f"Agent response: {response}")
return response['output']
except Exception as e:
print(f"Error processing Excel file: {str(e)}")
import traceback
print(f"Full traceback: {traceback.format_exc()}")
return f"Error processing Excel file: {str(e)}"
# For unstructured text files
print("\\
Processing unstructured text files...")
all_content = []
for file_path in supported_files:
try:
if file_path.endswith('.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
all_content.append(Document(page_content=content, metadata={"source": file_path}))
except Exception as e:
print(f"Error reading file {file_path}: {str(e)}")
continue
if not all_content:
return "Could not read any documents."
# Process unstructured text using vector store
print("Processing text with vector store...")
chunks = self.text_splitter.split_documents(all_content)
vector_store = FAISS.from_documents(chunks, self.embeddings)
relevant_docs = vector_store.similarity_search(query, k=3)
context = "\\
\\
".join([doc.page_content for doc in relevant_docs])
print(f"Generated context length: {len(context)}")
response = self.llm.invoke(
f"""Based on the following context, answer the question: {query}
\\
Context:\\
{context}\\
\\
Answer:"""
)
return response.content
except Exception as e:
print(f"Error processing document query: {str(e)}")
import traceback
print(f"Full traceback: {traceback.format_exc()}")
return f"Error processing document query: {str(e)}"
تكامل قاعدة بيانات SQL
الآن بعد أن تعاملنا مع معالجة المستندات، نحتاج إلى إنشاء نظام التوجيه الذكي للاستعلامات الذي يقرر بين تحليل SQL وتحليل المستندات. هذا هو الذكاء الأساسي لنظامنا - تحديد مصدر البيانات الأكثر احتمالية لاحتواء الإجابة على سؤال معين.
def process_query(self, query: str) -> str:
"""
Process query using agents to intelligently decide between SQL and documents
"""
# First try SQL agent
try:
print("\\
Trying SQL Agent...")
sql_result = self.sql_agent.run(query)
no_answer_phrases = [
"no results", "i don't know", "unknown", "not sure", "cannot answer", "don't have", "no data", "n/a"
]
if sql_result and not any(phrase in sql_result.lower() for phrase in no_answer_phrases) and sql_result.strip():
return f"From SQL Database: {sql_result}"
else:
print("SQL Agent could not answer, trying documents...")
except Exception as e:
print(f"SQL Agent Error: {str(e)}")
print("Falling back to documents...")
# If SQL agent fails or returns no results, try document processing
try:
print("\\
Processing documents...")
doc_result = self._process_document_query(query)
if doc_result:
return f"From Documents: {doc_result}"
else:
print("Document processing returned no results")
except Exception as e:
print(f"Document Processing Error: {str(e)}")
return "Could not find relevant information in either SQL database or documents."
يتبع منطق توجيه الاستعلام نظام أولويات: يتم تجربة قواعد بيانات SQL أولاً لأنها تحتوي عادةً على بيانات منظمة وكمية يمكنها الإجابة على أسئلة الأعمال بسرعة ودقة. إذا أعاد وكيل SQL استجابات غير واضحة أو سلبية (يتم اكتشافها من خلال قائمة no_answer_phrases)، يتحول النظام تلقائيًا إلى معالجة المستندات. يحاكي هذا النهج الطريقة التي يعمل بها المحلل البشري - التحقق أولاً من مصادر البيانات المنظمة، ثم الانتقال إلى المستندات والتقارير عندما لا تحتوي قاعدة البيانات على المعلومات المطلوبة.
إنشاء واجهة Streamlit
الآن دعنا نبني واجهة المستخدم التي تجعل نظام التحليلات الخاص بنا في متناول مستخدمي الأعمال. تقدم واجهة Streamlit تجربة قائمة على الدردشة وبديهية تخفي التعقيد التقني مع تقديم قدرات تحليلية قوية. أضف مقتطفات الكود التالية إلى ملف main.py:
import streamlit as st
from query_processor import QueryProcessor
import os
from dotenv import load_dotenv
from sqlalchemy import create_engine
# Load environment variables
load_dotenv()
#st.text_input
# Initialize session state
if 'processor' not in st.session_state:
st.session_state.processor = None
if 'messages' not in st.session_state:
st.session_state.messages = []
# Set page config
st.set_page_config(
page_title="Document Analysis Chatbot",
page_icon="🤖",
layout="wide"
)
# Custom CSS for button and title styling
st.markdown("""
<style>
.stButton > button {
background-color: #23D57C;
color: white;
border: none;
border-radius: 8px;
padding: 0.5rem 1rem;
font-weight: 600;
transition: all 0.3s ease;
}
.stButton > button:hover {
background-color: #1fb36b;
box-shadow: 0 4px 8px rgba(35, 213, 124, 0.3);
transform: translateY(-2px);
}
.stButton > button:active {
background-color: #1a9960;
transform: translateY(0px);
}
h1 {
color: #23D57C !important;
font-weight: 700;
}
</style>
""", unsafe_allow_html=True)
# Title and description
st.title("Document Analysis Chatbot using Novita")
يقوم هذا الإعداد الأولي بإنشاء واجهة ذات مظهر احترافي مع تخصيص الأنماط. يضمن إدارة حالة الجلسة (session state) ألا يفقد المستخدمون سجل محادثاتهم أو يحتاجون إلى إعادة تهيئة مصادر بياناتهم عند التفاعل مع الواجهة. يوفر CSS المخصص ملاحظات بصرية ويحافظ على تجربة علامة تجارية متسقة.
التكامل النهائي للنظام
دعنا نكمل واجهة Streamlit مع تهيئة مصدر البيانات ووظيفة الدردشة. يجمع هذا القسم الأخير جميع مكوناتنا في تطبيق سهل الاستخدام يمكن لمحللي الأعمال استخدامه دون الحاجة إلى خبرة فنية.
# Check if data source is initialized
if st.session_state.processor is None:
# Center the data source configuration
st.markdown("<br><br>", unsafe_allow_html=True)
# Create centered columns
col1, col2, col3 = st.columns([1, 2, 1])
with col2:
st.subheader("🚀 Get Started")
st.write("Initialize your data source to start chatting with your documents")
# SQL Database Configuration (hidden)
db_user = "root"
db_password = "1234cisco"
db_host = "localhost"
db_name = "retail_sales_db"
# Documents Folder Configuration
st.write("**Documents Folder Path:**")
documents_folder = st.text_input(
"Documents Folder Path",
placeholder="Enter path to your documents folder (e.g., docs)",
label_visibility="collapsed"
)
st.markdown("<br>", unsafe_allow_html=True)
# Center the button
button_col1, button_col2, button_col3 = st.columns([1, 1, 1])
with button_col2:
if st.button("Initialize Data Source", use_container_width=True):
try:
# Validate and resolve documents folder path
if not documents_folder:
st.error("Please provide a documents folder path")
else:
# Convert to absolute path
abs_documents_folder = os.path.abspath(documents_folder)
if not os.path.exists(abs_documents_folder):
st.error(f"Documents folder not found: {abs_documents_folder}")
elif not os.path.isdir(abs_documents_folder):
st.error(f"Path is not a directory: {abs_documents_folder}")
else:
# Initialize query processor with a dummy SQL engine
# Create SQL engine
connection_string = f"mysql+pymysql://{db_user}:{db_password}@{db_host}/{db_name}"
sql_engine = create_engine(connection_string)
st.session_state.processor = QueryProcessor(abs_documents_folder, sql_engine)
st.success("Data source initialized successfully!")
st.rerun()
except Exception as e:
st.error(f"Error initializing data source: {str(e)}")
else:
# Show data source status in sidebar
with st.sidebar:
st.header("📊 Data Source")
st.success("✅ Data source initialized")
if st.button("Reset Data Source"):
st.session_state.processor = None
st.session_state.messages = []
st.rerun()
# Main chat interface
st.header("Chat Interface")
# Display chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
# Chat input
if prompt := st.chat_input("Ask a question about your documents"):
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Process query
try:
response = st.session_state.processor.process_query(prompt)
# Add assistant response to chat history
st.session_state.messages.append({"role": "assistant", "content": response})
with st.chat_message("assistant"):
st.write(response)
except Exception as e:
st.error(f"Error processing query: {str(e)}")
# Add a clear chat button only if there are messages
if st.session_state.messages:
if st.button("Clear Chat"):
st.session_state.messages = []
st.rerun()
تتضمن عملية التهيئة معالجة قوية للأخطاء والتحقق من صحة المسار لمنع أخطاء المستخدم الشائعة. يوفر الشريط الجانبي معلومات واضحة عن الحالة، وتتبع واجهة الدردشة الأنماط المألوفة التي يتوقعها المستخدمون من مساعدي الذكاء الاصطناعي الحديثين. يحافظ النظام على سجل المحادثة، مما يسمح للمستخدمين بالبناء على الأسئلة السابقة وإنشاء سير عمل تحليلي طبيعي. تتيح وظيفة مسح الدردشة للمستخدمين البدء من جديد عند الحاجة.
تشغيل نظام التحليلات
الآن بعد أن بنينا نظام تحليلات المبيعات القائم على RAG، دعنا نختبره ونرى مدى أدائه في استعلامات الأعمال الحقيقية.
أولاً، قم بإنشاء ملف data_generator.py وانسخ الكود من هذا الرابط لإنشاء بيانات نموذجية سنقدمها للنظام، وقم بتشغيل النص البرمجي بالأمر:
| python data_generator.py |
سيؤدي هذا إلى إنشاء مجلد sample_documents يحتوي على:
- large_sales_dataset.csv - 10,000 سجل مبيعات
- business_strategy_2024.txt - وثيقة استراتيجية أعمال
- sales_meeting_notes.txt - ملاحظات الاجتماع والإجراءات
ثم ابدأ تطبيق Streamlit:
| streamlit run main.py |
سيفتح التطبيق في متصفحك على الرابط http://localhost:8501.

بمجرد التهيئة، يمكنك اختبار النظام عن طريق إدخال مسار المستندات الخاص بك كـ sample_documents وطرح أسئلة أعمال متنوعة:
| # استعلامات نموذجية لاختبار النظام topic_1 = “ما هو إجمالي مبلغ مبيعات الإلكترونيات في عام 2024؟” topic_2 = “ما هي مبادراتنا الاستراتيجية الرئيسية لتجربة العملاء؟” topic_3 = “أي مندوب مبيعات لديه أعلى إجمالي مبيعات، وما هو المبلغ؟” |
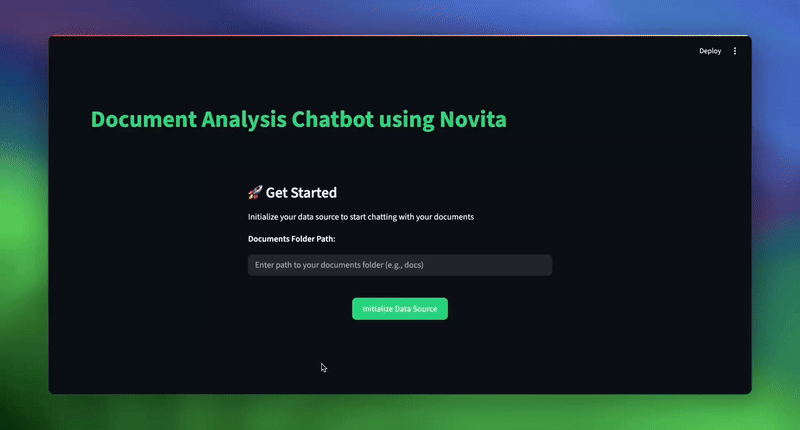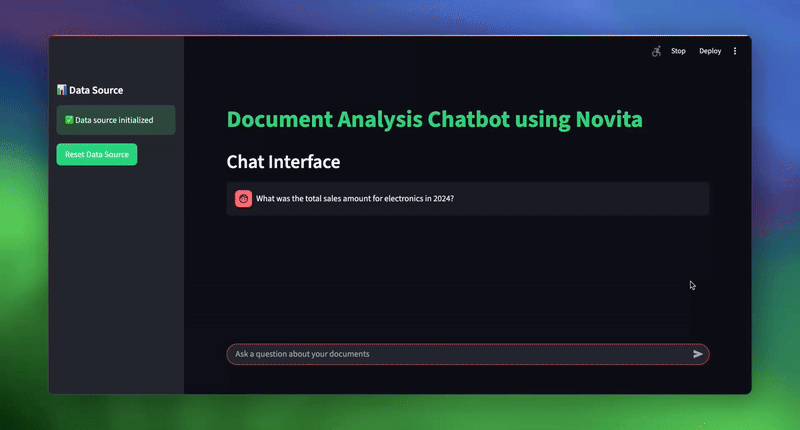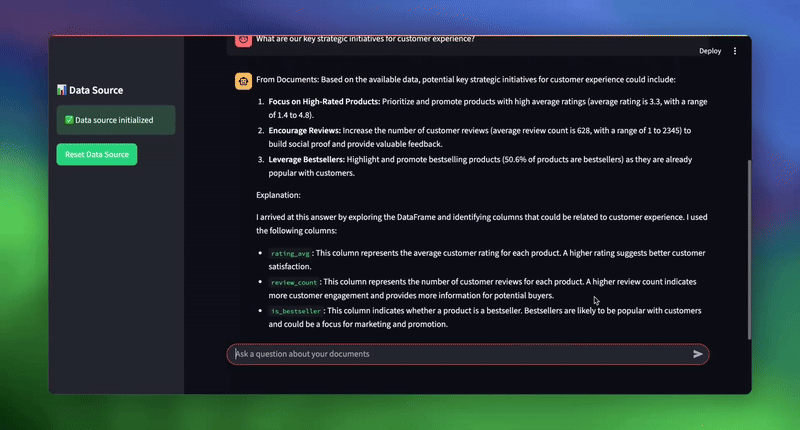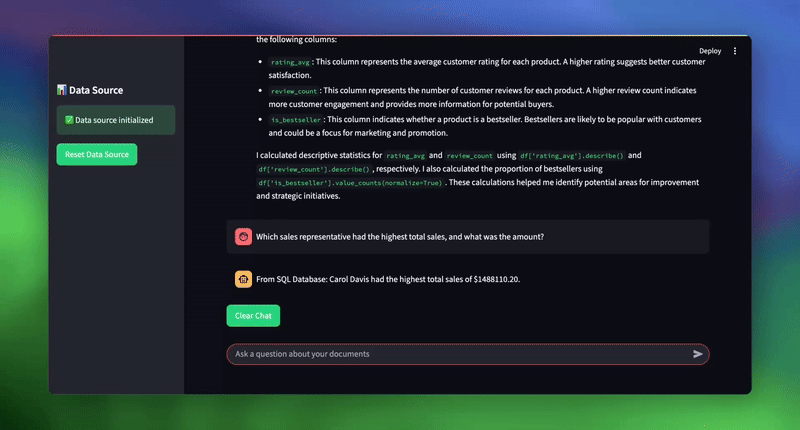
الاستنتاج
خلال هذا البرنامج التعليمي، قمنا ببناء نظام تحليلات قائم على RAG يوضح كيف يمكن للذكاء الاصطناعي الحديث تحويل سير عمل ذكاء الأعمال. من خلال الجمع بين أساليب معالجة البيانات المتعددة تحت واجهة ذكية واحدة، أنشأنا أداة يمكنها التعامل مع النطاق الكامل لأسئلة الأعمال التي يواجهها المحللون يوميًا. تشمل نقاط القوة الرئيسية للنظام ما يلي:
- التوجيه الذكي للاستعلامات الذي يحدد تلقائيًا أفضل مصدر بيانات لكل سؤال
- دعم متعدد التنسيقات للتعامل مع قواعد بيانات SQL وملفات CSV وجداول Excel والمستندات النصية
- معالجة قوية للأخطاء لتوفير آليات احتياطية ورسائل خطأ واضحة
- تفاعل قائم على الدردشة لا يتطلب خبرة فنية
- تحقق وموثوقية مدمجة لضمان نتائج موثوقة
يمكنك توسيع هذا التطبيق لدمج مصادر إضافية، وتقنيات تحليل أكثر تقدماً، ومنطق أعمال مخصص. الآن بعد أن اكتسبت هذه المعرفة، انطلق وحاول بناء وكلائك الخاصين باستخدام Novita AI أو دمجها في مشاريعك الحالية.
Novita AI هي المنصة السحابية الشاملة التي تدعم طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، حوسبة بدون خادم، مثيلات GPU - الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، وحقق رؤيتك في الذكاء الاصطناعي.



