

The NVIDIA GeForce RTX 5090, launched on January 30, 2025, represents the pinnacle of GPU technology with its 92 billion transistors and 3,352 trillion AI operations per second (TOPS). Novita AI makes this flagship Blackwell architecture GPU accessible at an unprecedented $0.25/hr through Spot Instances, compared to $0.50/hr for On-Demand pricing.
With 21,760 CUDA cores, 32GB of GDDR7 memory, and 1,792 GB/s memory bandwidth, the RTX 5090 delivers up to 2× the performance of its predecessor. Novita AI’s Spot Instance model provides up to 50% savings by utilizing spare GPU capacity, similar to how the platform offers RTX 4090 GPUs at $0.18/hr versus $0.35/hr On-Demand. Every Spot Instance includes a 1-hour protection window and advance interruption notices, enabling developers to harness enterprise-grade compute power at startup-friendly prices.
Launch your first Spot Instance Now
What Are the RTX 5090 Specifications?
The RTX 5090’s Blackwell architecture introduces groundbreaking capabilities that NVIDIA CEO Jensen Huang called “the most significant computer graphics innovation since programmable shading.” Built on 92 billion transistors, this GPU delivers unprecedented performance for both gaming and AI workloads.
Core Architecture and Processing Power
The RTX 5090 features 21,760 CUDA cores spread across 170 Streaming Multiprocessors (SMs), representing a 33% increase over the RTX 4090’s 16,384 cores. These cores operate at a 2.0 GHz base clock with boost speeds reaching 2.41 GHz. Despite the massive core count, NVIDIA maintained high frequencies, translating to exceptional throughput for parallel processing tasks.
The GPU includes 680 fifth-generation Tensor Cores specifically optimized for AI acceleration. These Tensor Cores deliver 3,352 AI TOPS (trillion operations per second), making the RTX 5090 exceptionally capable for deep learning tasks. Additionally, 170 fourth-generation RT Cores enable advanced ray tracing with improved ray-triangle intersection performance, delivering realistic lighting and shadows in real-time applications.
Memory Configuration: 32GB GDDR7
The 32GB of GDDR7 memory marks a significant upgrade, providing 33% more capacity than the RTX 4090’s 24GB. Operating on a 512-bit memory bus, this configuration delivers 1,792 GB/s of bandwidth—78% higher than the previous generation. This massive bandwidth ensures the 21,760 CUDA cores remain fully utilized even when processing large datasets or high-resolution textures.
The jump to GDDR7 technology provides not just capacity improvements but also efficiency gains. With an effective speed of 28 Gbps compared to the RTX 4090’s 21 Gbps, data moves faster between memory and processing cores, eliminating bottlenecks that previously constrained GPU performance in memory-intensive applications.
Power Requirements and Cooling
The RTX 5090 requires 575W Total Design Power (TDP) for the Founders Edition, substantially higher than the RTX 4090’s 450W. NVIDIA engineered a revolutionary dual-slot cooling solution featuring a 3D vapor chamber, integrated heat pipes, and dual-sided fans delivering double the airflow of traditional designs. The card uses a 16-pin PCIe 5.0 power connector and requires a robust power supply for local installation.
On Novita AI’s cloud platform, these power and cooling requirements become irrelevant to users. The data center infrastructure handles all power delivery and thermal management, allowing you to focus purely on leveraging the GPU’s computational capabilities.
How Much Does RTX 5090 Cost on Novita AI?
The RTX 5090’s $1,999 MSRP for the Founders Edition makes it one of the most expensive consumer GPUs ever released. Novita AI transforms this prohibitive upfront cost into affordable hourly rates through two pricing models.
Spot Instance vs On-Demand Pricing
| Pricing Model | RTX 5090 Rate | Monthly Cost (720 hrs) | Savings |
|---|---|---|---|
| Spot Instances | $0.25/hr | $180 | 50% |
| On-Demand | $0.50/hr | $360 | — |
Spot Instance pricing at $0.25/hr makes the RTX 5090 accessible for budget-conscious projects. Running continuously for an entire month costs just $180, compared to the $1,999 hardware purchase price. For context, you would need to operate the GPU for 8,000 hours (333 days) at Spot Instance rates to match the initial investment, not including electricity costs or depreciation.
On-Demand pricing at $0.50/hr provides guaranteed availability without interruption risk. This pricing tier suits production workloads, customer-facing applications, and time-critical computations where any interruption could impact operations.
Novita AI GPU Portfolio Comparison
Novita AI offers multiple GPU options at different price points:
| GPU Model | Spot Price | On-Demand Price | Savings | Memory |
|---|---|---|---|---|
| RTX 5090 | $0.25/hr | $0.50/hr | 50% | 32GB GDDR7 |
| RTX 4090 | $0.18/hr | $0.35/hr | ~49% | 24GB GDDR6X |
| RTX 4090 High-Frequency | $0.35/hr | $0.69/hr | ~49% | 24GB GDDR6X |
The High-Frequency RTX 4090 variant accelerates AI image generation by up to 150% through optimized CPU-GPU coordination, demonstrating Novita AI’s commitment to performance optimization beyond raw hardware specifications.
Break-Even Analysis
For a machine learning startup training models 200 hours monthly, Spot Instances cost $50 versus $100 for On-Demand—an annual savings of $600. A research lab running simulations 500 hours monthly saves $125 per month ($1,500 annually) using Spot Instances. These savings can fund additional experiments, extended training runs, or other research resources.
How to Deploy RTX 5090 on Novita AI in 3 Steps?
Launching an RTX 5090 Spot Instance on Novita AI follows the same streamlined process proven successful with other GPU deployments.
Step 1: Access Your Console
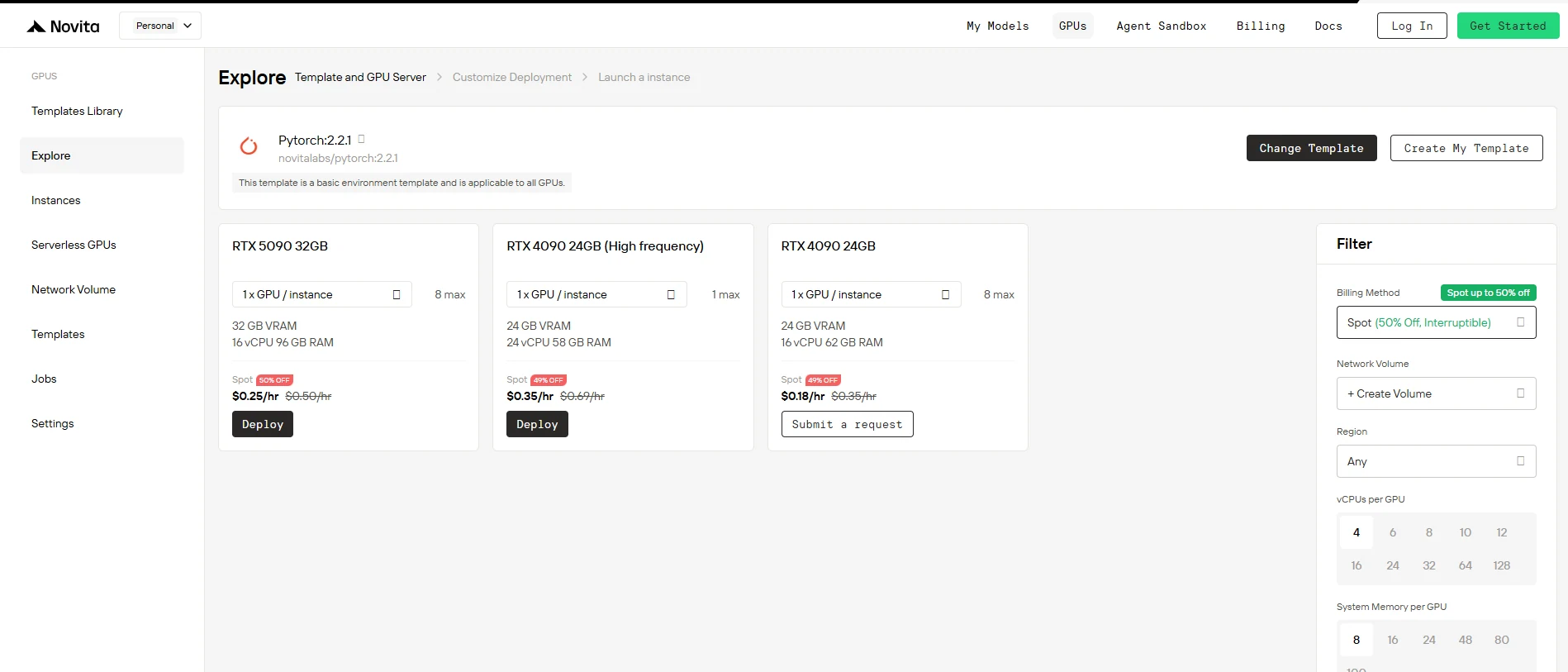
Log in to your Novita AI GPU Console. The dashboard displays real-time GPU availability, current Spot Instance capacity, and your recent deployments. This overview helps you make informed decisions about when and where to deploy your instances.
Step 2: Switch to Spot Billing
In the right sidebar under Filter, change the Billing Method from “On-Demand” to “Spot” to see discounted prices. The interface immediately updates to show the RTX 5090 at $0.25/hr instead of $0.50/hr, with the 50% savings clearly highlighted. This transparency ensures you know exactly what you’re paying before deployment.
Step 3: Deploy
Select your RTX 5090 configuration and click “Deploy”. Your instance launches within seconds with:
- 1-hour protection period guaranteed
- Up to 50% cost savings activated
- 1-hour advance interruption notice configured
- Pre-installed AI frameworks ready
Pro tip: Implement checkpointing in your application to handle potential interruptions gracefully.
Each instance comes pre-configured with PyTorch 2.0+, TensorFlow, CUDA 12.x, cuDNN, and popular libraries like Hugging Face Transformers. This eliminates hours of setup time, allowing immediate productivity.
How Do Novita AI Spot Instances Work?
Spot Instances utilize Novita AI’s spare GPU capacity, making this capacity available at lower prices because it can be reclaimed when demand for regular instances increases. This model has proven successful with RTX 4090 GPUs, which are available for as low as $0.18/hr versus $0.35/hr On-Demand.
Key Characteristics
Variable availability: Spot Instances may be interrupted when Novita AI requires the capacity back. However, this doesn’t mean random termination—the platform follows a structured process with advance notifications.
Significant cost savings: Access the same GPU performance at up to 50% less than On-Demand prices. The hardware and performance are identical; only the availability guarantee differs.
Protection period: Each Spot Instance includes a 1-hour protection window after launch. During this time, your instance cannot be interrupted regardless of capacity demands.
Advance notifications: Receive interruption notices 1 hour before reclamation, with an additional 5-minute warning. These notifications allow you to save work, checkpoint progress, and gracefully shut down applications.
Comparison with On-Demand Instances
| Feature | Spot Instances | On-Demand Instances |
|---|---|---|
| Pricing | Up to 50% less | Standard rates |
| Availability | Subject to capacity | Always available |
| Interruption risk | May be reclaimed with notice | No interruptions |
| Protection period | 1 hour after launch | Continuous |
| Use case | Flexible, fault-tolerant workloads | Critical, uninterruptible workloads |
By choosing Spot Instances for appropriate workloads, you access the same powerful GPU resources while optimizing compute costs.
Learn more: Novita AI Spot Instances Guide
Why Is RTX 5090 Ideal for AI and Machine Learning?
The RTX 5090’s architecture specifically targets AI and machine learning workloads with features previously exclusive to data center GPUs. The combination of massive compute power, substantial memory, and advanced precision support makes it exceptionally capable for modern AI applications.
Tensor Core Evolution and AI Compute
Fifth-generation Tensor Cores support newer precision formats including FP8 and experimental FP4, which can double AI throughput for certain models with minimal accuracy impact. The 3,352 AI TOPS represents computational power approaching NVIDIA’s A100 and H100 data center accelerators but in a more accessible format.
In practical terms, this means faster training times and higher inference throughput. A transformer model that takes 6 hours to train on an RTX 4090 might complete in 4 hours on the RTX 5090. Stable Diffusion XL image generation improves from 3.5 seconds per image to approximately 2 seconds, enabling faster iteration and experimentation.
Large Language Model Capabilities
The 32GB GDDR7 memory enables training transformer models up to 13 billion parameters in half-precision without model parallelism or gradient checkpointing. This is a significant improvement over the RTX 4090’s 24GB, which often required optimization techniques for models exceeding 7 billion parameters.
Fine-tuning pre-trained models becomes remarkably efficient. LoRA fine-tuning that previously pushed memory limits now runs comfortably with room for larger batch sizes. The increased memory also enables working with longer context lengths and more complex model architectures without running into out-of-memory errors.
Comparison with Data Center GPUs
Surprisingly, the RTX 5090’s 92 billion transistors exceed even the H100’s 80 billion. While lacking features like ECC memory, NVLink interconnects, and Multi-Instance GPU (MIG) support, the RTX 5090 provides near-data center performance at a fraction of the cost.
The RTX 5090 delivers 83 TFLOPS of FP32 compute, compared to the A100’s 19.5 TFLOPS and approaching the H100’s 67 TFLOPS. For many AI practitioners, this provides data center-like performance at consumer GPU pricing, especially when accessed through Novita AI’s Spot Instances at $0.25/hr.
Which Workloads Are Best for RTX 5090 Spot Instances?
Spot Instances work best for workloads that can handle interruptions or complete within the 1-hour protection window. Understanding which applications benefit most helps maximize value while minimizing operational complexity.
Ideal Use Cases
Batch processing and distributed training: Large-scale model training with regular checkpointing benefits from the 50% cost savings. Distributed training across multiple Spot Instances can slash training time while keeping costs manageable. Hyperparameter tuning and architecture search naturally suit the Spot model since individual experiments are independent.
Development and testing environments: Prototype development, performance benchmarking, and CI/CD pipelines for ML models work excellently on Spot Instances. The cost savings enable more experimentation and longer test runs without budget concerns.
Fault-tolerant applications: Stateless inference services with load balancing, rendering and video processing pipelines, Monte Carlo simulations, and genetic algorithms can all leverage Spot Instances effectively. These workloads’ inherent resilience to interruption makes them perfect candidates.
Flexible-deadline workloads: Research computations without strict deadlines, overnight training runs, data migration and transformation tasks, and archive processing benefit from Spot Instance economics without risking critical deadlines.
Before You Start
Ensure your workload can handle interruptions and resume from checkpoints. Tasks should either complete within the 1-hour protection window or tolerate potential interruptions. Implement checkpoint saving to persistent storage and use queue-based job distribution for resilience.
Workloads Better Suited for On-Demand
Some workloads require the guaranteed availability of On-Demand instances: real-time production services, customer-facing applications, workloads that cannot handle interruptions, and time-critical computations without checkpointing. For these use cases, the $0.50/hr On-Demand pricing provides peace of mind and operational stability.
Conclusion
The NVIDIA RTX 5090 represents a monumental leap in GPU technology with its 92 billion transistors, 21,760 CUDA cores, and 32GB of GDDR7 memory delivering 3,352 trillion AI operations per second. This flagship Blackwell architecture GPU, launched at $1,999, delivers up to 2× the performance of its predecessor.
Novita AI democratizes access to this cutting-edge hardware through Spot Instances at just $0.25/hr—a 50% savings compared to On-Demand pricing. Following the successful model proven with RTX 4090 GPUs at $0.18/hr, Novita AI’s Spot Instances utilize spare capacity to make enterprise-grade computing affordable for everyone.
Start leveraging RTX 5090 power today through Novita AI’s simple three-step deployment process. Experience how 92 billion transistors of computing capability at $0.25/hr can accelerate your innovation without accelerating your expenses.
Frequently Asked Questions
When was the NVIDIA RTX 5090 released?
NVIDIA officially released the GeForce RTX 5090 on January 30, 2025. It was announced earlier that month during CES 2025 and hit store shelves in limited quantities at the end of January.
What is the price of the RTX 5090?
The MSRP for the RTX 5090 is $1,999 USD for the Founders Edition at launch. Partner cards from ASUS, MSI, and others may cost even more. On Novita AI, you can access RTX 5090 performance at $0.25/hr with Spot Instances or $0.50/hr for On-Demand—avoiding the massive upfront investment.
How much faster is the RTX 5090 compared to the RTX 4090?
NVIDIA advertises up to 2× the performance of RTX 4090 in certain scenarios. In practical use, many games and benchmarks show 20-50% higher framerates at 4K resolution. When DLSS 4’s Multi Frame Generation is used, the performance gap can widen significantly. For GPU compute tasks like rendering, expect approximately 35-45% improvement.
How does Spot Instance pricing work on Novita AI?
Spot Instances utilize spare GPU capacity at up to 50% discount. RTX 5090 Spot Instances cost $0.25/hr versus $0.50/hr On-Demand. Each instance includes a 1-hour protection window and 1-hour advance interruption notice. This model works perfectly for batch processing, ML training with checkpoints, and flexible research workloads.
Can I use multiple RTX 5090 GPUs for distributed training?
Yes, you can deploy multiple RTX 5090 instances on Novita AI for distributed training. This approach allows you to scale training across multiple GPUs, reducing time to completion. With Spot Instances at $0.25/hr per GPU, distributed training becomes economically viable even for smaller teams.
Do Spot Instances have the same performance as On-Demand?
Yes, Spot Instances provide identical hardware and performance as On-Demand instances. The only difference is availability—Spot Instances may be interrupted with notice, while On-Demand instances run continuously. Both deliver the full power of the RTX 5090.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



