

- ¿Cuáles son las especificaciones de la RTX 5090?
- ¿Cuánto cuesta la RTX 5090 en Novita AI?
- ¿Cómo desplegar la RTX 5090 en Novita AI en 3 pasos?
- ¿Cómo funcionan las Instancias Spot de Novita AI?
- ¿Por qué la RTX 5090 es ideal para IA y Aprendizaje Automático?
- ¿Qué cargas de trabajo son mejores para las Instancias Spot RTX 5090?
- Conclusión
La NVIDIA GeForce RTX 5090, lanzada el 30 de enero de 2025, representa la cúspide de la tecnología GPU con sus 92 mil millones de transistores y 3,352 billones de operaciones de IA por segundo (TOPS). Novita AI hace accesible esta GPU emblemática de la arquitectura Blackwell a un precio sin precedentes de $0,25/hora a través de Instancias Spot, en comparación con los $0,50/hora del precio bajo demanda.
Con 21.760 núcleos CUDA, 32 GB de memoria GDDR7 y 1.792 GB/s de ancho de banda de memoria, la RTX 5090 ofrece hasta 2 veces el rendimiento de su predecesora. El modelo de Instancia Spot de Novita AI proporciona hasta un 50% de ahorro al utilizar la capacidad GPU sobrante, de manera similar a como la plataforma ofrece GPUs RTX 4090 a $0,18/hora frente a $0,35/hora bajo demanda. Cada Instancia Spot incluye una ventana de protección de 1 hora y avisos de interrupción anticipados, lo que permite a los desarrolladores aprovechar la potencia de cómputo de nivel empresarial a precios accesibles para startups.
Lanza tu primera Instancia Spot ahora
¿Cuáles son las especificaciones de la RTX 5090?
La arquitectura Blackwell de la RTX 5090 introduce capacidades innovadoras que el CEO de NVIDIA, Jensen Huang, calificó como “la innovación más significativa en gráficos por computadora desde el sombreado programable”. Construida sobre 92 mil millones de transistores, esta GPU ofrece un rendimiento sin precedentes tanto para cargas de trabajo de juegos como de IA.
Arquitectura central y potencia de procesamiento
La RTX 5090 cuenta con 21.760 núcleos CUDA distribuidos en 170 Multiprocesadores de Transmisión (SM), lo que representa un aumento del 33% con respecto a los 16.384 núcleos de la RTX 4090. Estos núcleos operan a una frecuencia base de 2,0 GHz con velocidades de impulso que alcanzan los 2,41 GHz. A pesar del enorme número de núcleos, NVIDIA mantuvo frecuencias altas, lo que se traduce en un rendimiento excepcional para tareas de procesamiento paralelo.
La GPU incluye 680 núcleos Tensor de quinta generación optimizados específicamente para la aceleración de IA. Estos Núcleos Tensor ofrecen 3,352 TOPS de IA (billones de operaciones por segundo), lo que hace que la RTX 5090 sea excepcionalmente capaz para tareas de aprendizaje profundo. Además, 170 Núcleos RT de cuarta generación permiten un trazado de rayos avanzado con un rendimiento mejorado en la intersección rayo-triángulo, ofreciendo iluminación y sombras realistas en aplicaciones en tiempo real.
Configuración de memoria: 32 GB GDDR7
Los 32 GB de memoria GDDR7 suponen una mejora significativa, ya que proporcionan un 33% más de capacidad que los 24 GB de la RTX 4090. Al operar en un bus de memoria de 512 bits, esta configuración ofrece un ancho de banda de 1.792 GB/s, un 78% más que la generación anterior. Este enorme ancho de banda garantiza que los 21.760 núcleos CUDA se mantengan completamente utilizados incluso al procesar grandes conjuntos de datos o texturas de alta resolución.
El salto a la tecnología GDDR7 no solo mejora la capacidad, sino también la eficiencia. Con una velocidad efectiva de 28 Gbps en comparación con los 21 Gbps de la RTX 4090, los datos se mueven más rápido entre la memoria y los núcleos de procesamiento, eliminando los cuellos de botella que antes limitaban el rendimiento de la GPU en aplicaciones con uso intensivo de memoria.
Requisitos de energía y refrigeración
La RTX 5090 requiere 575 W de Potencia de Diseño Térmico (TDP) para la Edición Founders, sustancialmente más que los 450 W de la RTX 4090. NVIDIA diseñó una solución de refrigeración revolucionaria de doble ranura que cuenta con una cámara de vapor 3D, tubos de calor integrados y ventiladores de doble cara que proporcionan el doble de flujo de aire que los diseños tradicionales. La tarjeta utiliza un conector de alimentación PCIe 5.0 de 16 pines y requiere una fuente de alimentación robusta para la instalación local.
En la plataforma en la nube de Novita AI, estos requisitos de energía y refrigeración son irrelevantes para los usuarios. La infraestructura del centro de datos se encarga de toda la entrega de energía y la gestión térmica, lo que le permite centrarse únicamente en aprovechar las capacidades computacionales de la GPU.
¿Cuánto cuesta la RTX 5090 en Novita AI?
El precio de venta al público recomendado (MSRP) de $1.999 para la Edición Founders de la RTX 5090 la convierte en una de las GPUs de consumo más caras jamás lanzadas. Novita AI transforma este coste inicial prohibitivo en tarifas por hora asequibles a través de dos modelos de precios.
Precios de Instancia Spot vs. Bajo Demanda
| Modelo de Precio | Tarifa RTX 5090 | Coste Mensual (720 horas) | Ahorro |
|---|---|---|---|
| Instancias Spot | $0,25/hora | $180 | 50% |
| Bajo Demanda | $0,50/hora | $360 | — |
El precio de Instancia Spot a $0,25/hora hace que la RTX 5090 sea accesible para proyectos con presupuesto ajustado. Ejecutarla de forma continua durante un mes entero cuesta solo $180, en comparación con los $1.999 del precio de compra del hardware. Para contextualizar, necesitarías operar la GPU durante 8.000 horas (333 días) a la tarifa de Instancia Spot para igualar la inversión inicial, sin incluir costes de electricidad ni depreciación.
El precio bajo demanda de $0,50/hora proporciona disponibilidad garantizada sin riesgo de interrupción. Este nivel de precios es adecuado para cargas de trabajo de producción, aplicaciones orientadas al cliente y cálculos críticos en los que cualquier interrupción podría afectar a las operaciones.
Comparativa del Portafolio de GPUs de Novita AI
Novita AI ofrece múltiples opciones de GPU a diferentes precios:
| Modelo GPU | Precio Spot | Precio Bajo Demanda | Ahorro | Memoria |
|---|---|---|---|---|
| RTX 5090 | $0,25/hora | $0,50/hora | 50% | 32 GB GDDR7 |
| RTX 4090 | $0,18/hora | $0,35/hora | ~49% | 24 GB GDDR6X |
| RTX 4090 Alta Frecuencia | $0,35/hora | $0,69/hora | ~49% | 24 GB GDDR6X |
La variante RTX 4090 de Alta Frecuencia acelera la generación de imágenes de IA hasta en un 150% mediante una coordinación optimizada entre CPU y GPU, lo que demuestra el compromiso de Novita AI con la optimización del rendimiento más allá de las especificaciones técnicas del hardware.
Análisis de Punto de Equilibrio
Para una startup de aprendizaje automático que entrena modelos 200 horas al mes, las Instancias Spot cuestan $50 frente a $100 en bajo demanda, un ahorro anual de $600. Un laboratorio de investigación que ejecuta simulaciones 500 horas al mes ahorra $125 al mes ($1.500 anuales) utilizando Instancias Spot. Estos ahorros pueden financiar experimentos adicionales, ejecuciones de entrenamiento prolongadas u otros recursos de investigación.
¿Cómo desplegar la RTX 5090 en Novita AI en 3 pasos?
Lanzar una Instancia Spot RTX 5090 en Novita AI sigue el mismo proceso optimizado que ha demostrado ser exitoso con otros despliegues de GPU.
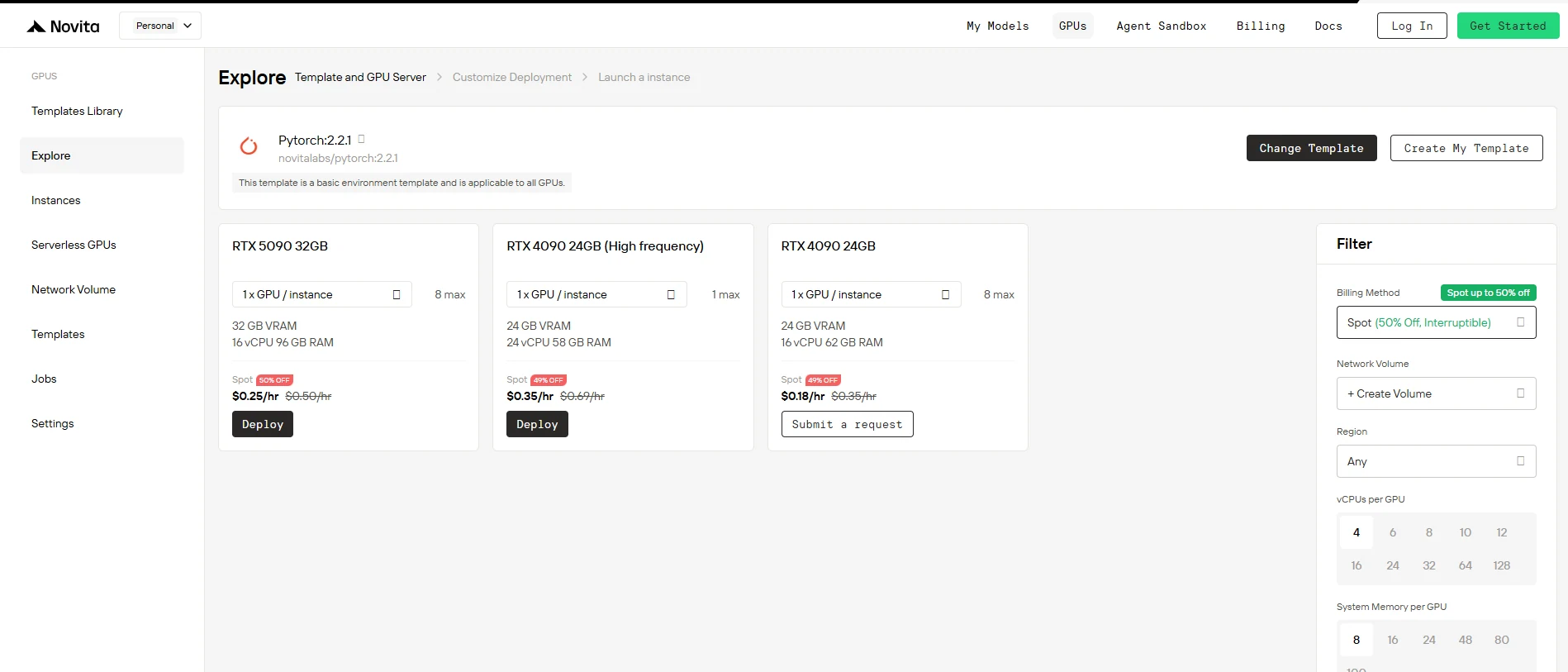
Paso 1: Accede a tu Consola
Inicia sesión en tu Consola de GPU de Novita AI. El panel muestra la disponibilidad de GPU en tiempo real, la capacidad actual de Instancias Spot y tus despliegues recientes. Esta visión general te ayuda a tomar decisiones informadas sobre cuándo y dónde desplegar tus instancias.
Paso 2: Cambia a Facturación Spot
En la barra lateral derecha, en Filtro, cambia el Método de Facturación de “Bajo Demanda” a “Spot” para ver los precios con descuento. La interfaz se actualiza de inmediato para mostrar la RTX 5090 a $0,25/hora en lugar de $0,50/hora, con el ahorro del 50% claramente resaltado. Esta transparencia garantiza que sepas exactamente lo que pagas antes del despliegue.
Paso 3: Despliega
Selecciona tu configuración de RTX 5090 y haz clic en “Desplegar”. Tu instancia se lanza en segundos con:
- Período de protección de 1 hora garantizado
- Hasta un 50% de ahorro en costes activado
- Aviso de interrupción con 1 hora de antelación configurado
- Frameworks de IA preinstalados listos
Consejo profesional: Implementa puntos de control en tu aplicación para manejar posibles interrupciones de manera elegante.
Cada instancia viene preconfigurada con PyTorch 2.0+, TensorFlow, CUDA 12.x, cuDNN y bibliotecas populares como Hugging Face Transformers. Esto elimina horas de tiempo de configuración, lo que permite una productividad inmediata.
¿Cómo funcionan las Instancias Spot de Novita AI?
Las Instancias Spot utilizan la capacidad GPU sobrante de Novita AI, lo que hace que esta capacidad esté disponible a precios más bajos porque puede ser recuperada cuando la demanda de instancias regulares aumenta. Este modelo ha demostrado ser exitoso con las GPUs RTX 4090, que están disponibles desde $0,18/hora frente a $0,35/hora en bajo demanda.
Características clave
Disponibilidad variable: Las Instancias Spot pueden ser interrumpidas cuando Novita AI necesite recuperar la capacidad. Sin embargo, esto no significa una terminación aleatoria: la plataforma sigue un proceso estructurado con notificaciones anticipadas.
Ahorro significativo de costes: Accede al mismo rendimiento de GPU con hasta un 50% menos que los precios bajo demanda. El hardware y el rendimiento son idénticos; solo difiere la garantía de disponibilidad.
Período de protección: Cada Instancia Spot incluye una ventana de protección de 1 hora después del lanzamiento. Durante este tiempo, tu instancia no puede ser interrumpida independientemente de las demandas de capacidad.
Notificaciones anticipadas: Recibe avisos de interrupción 1 hora antes de la recuperación, con una advertencia adicional de 5 minutos. Estas notificaciones te permiten guardar el trabajo, registrar el progreso y cerrar las aplicaciones de manera ordenada.
Comparación con Instancias Bajo Demanda
| Característica | Instancias Spot | Instancias Bajo Demanda |
|---|---|---|
| Precio | Hasta un 50% menos | Tarifas estándar |
| Disponibilidad | Sujeta a capacidad | Siempre disponibles |
| Riesgo de interrupción | Pueden ser recuperadas con aviso | Sin interrupciones |
| Período de protección | 1 hora después del lanzamiento | Continuo |
| Caso de uso | Cargas de trabajo flexibles y tolerantes a fallos | Cargas de trabajo críticas e ininterrumpibles |
Al elegir Instancias Spot para las cargas de trabajo adecuadas, accedes a los mismos recursos de GPU potentes mientras optimizas los costes de cómputo.
Más información: Guía de Instancias Spot de Novita AI
¿Por qué la RTX 5090 es ideal para IA y Aprendizaje Automático?
La arquitectura de la RTX 5090 está dirigida específicamente a cargas de trabajo de IA y aprendizaje automático con características anteriormente exclusivas de las GPUs de centros de datos. La combinación de una potencia de cómputo masiva, una memoria sustancial y un soporte avanzado de precisión la hace excepcionalmente capaz para aplicaciones modernas de IA.
Evolución de los Núcleos Tensor y Cómputo de IA
Los Núcleos Tensor de quinta generación son compatibles con formatos de precisión más nuevos, incluidos FP8 y FP4 experimental, que pueden duplicar el rendimiento de IA para ciertos modelos con un impacto mínimo en la precisión. Los 3.352 TOPS de IA representan una potencia de cómputo cercana a la de los aceleradores de centros de datos A100 y H100 de NVIDIA, pero en un formato más accesible.
En términos prácticos, esto significa tiempos de entrenamiento más rápidos y un mayor rendimiento de inferencia. Un modelo transformer que tarda 6 horas en entrenarse en una RTX 4090 podría completarse en 4 horas en la RTX 5090. La generación de imágenes con Stable Diffusion XL mejora de 3,5 segundos por imagen a aproximadamente 2 segundos, lo que permite una iteración y experimentación más rápidas.
Capacidades para Modelos de Lenguaje de Gran Escala
La memoria GDDR7 de 32 GB permite entrenar modelos transformer de hasta 13 mil millones de parámetros en media precisión sin necesidad de paralelismo de modelo ni puntos de control de gradiente. Esto es una mejora significativa con respecto a los 24 GB de la RTX 4090, que a menudo requerían técnicas de optimización para modelos que superaban los 7 mil millones de parámetros.
El ajuste fino de modelos preentrenados se vuelve notablemente eficiente. El ajuste fino LoRA que antes llevaba los límites de memoria al máximo ahora funciona cómodamente con espacio para tamaños de lote más grandes. El aumento de memoria también permite trabajar con longitudes de contexto más largas y arquitecturas de modelo más complejas sin encontrarse con errores de falta de memoria.
Comparación con GPUs de Centro de Datos
Sorprendentemente, los 92 mil millones de transistores de la RTX 5090 superan incluso los 80 mil millones de la H100. Aunque carece de características como memoria ECC, interconexiones NVLink y soporte para Multi-Instancia GPU (MIG), la RTX 5090 proporciona un rendimiento cercano al de un centro de datos a una fracción del coste.
La RTX 5090 ofrece 83 TFLOPS de cómputo FP32, en comparación con los 19,5 TFLOPS de la A100 y acercándose a los 67 TFLOPS de la H100. Para muchos profesionales de la IA, esto proporciona un rendimiento similar al de un centro de datos a precios de GPU de consumo, especialmente cuando se accede a través de las Instancias Spot de Novita AI a $0,25/hora.
¿Qué cargas de trabajo son mejores para las Instancias Spot RTX 5090?
Las Instancias Spot funcionan mejor con cargas de trabajo que pueden manejar interrupciones o completarse dentro de la ventana de protección de 1 hora. Comprender qué aplicaciones se benefician más ayuda a maximizar el valor al tiempo que se minimiza la complejidad operativa.
Casos de uso ideales
Procesamiento por lotes y entrenamiento distribuido: El entrenamiento de modelos a gran escala con puntos de control regulares se beneficia del ahorro del 50%. El entrenamiento distribuido en múltiples Instancias Spot puede reducir el tiempo de entrenamiento mientras se mantienen los costes manejables. La búsqueda de hiperparámetros y la exploración de arquitecturas se adaptan naturalmente al modelo Spot, ya que los experimentos individuales son independientes.
Entornos de desarrollo y pruebas: El desarrollo de prototipos, la evaluación comparativa de rendimiento y los pipelines de CI/CD para modelos de ML funcionan de manera excelente en Instancias Spot. Los ahorros de costes permiten más experimentación y pruebas más largas sin preocupaciones presupuestarias.
Aplicaciones tolerantes a fallos: Los servicios de inferencia sin estado con equilibrio de carga, los pipelines de renderizado y procesamiento de video, las simulaciones de Monte Carlo y los algoritmos genéticos pueden aprovechar eficazmente las Instancias Spot. La resiliencia inherente de estas cargas de trabajo a las interrupciones las convierte en candidatas perfectas.
Cargas de trabajo con plazos flexibles: Los cálculos de investigación sin plazos estrictos, las ejecuciones de entrenamiento nocturnas, las tareas de migración y transformación de datos y el procesamiento de archivos se benefician de la economía de las Instancias Spot sin arriesgar plazos críticos.
Antes de empezar
Asegúrate de que tu carga de trabajo pueda manejar interrupciones y reanudarse desde puntos de control. Las tareas deben completarse dentro de la ventana de protección de 1 hora o tolerar posibles interrupciones. Implementa el guardado de puntos de control en almacenamiento persistente y utiliza una distribución de trabajos basada en colas para la resiliencia.
Cargas de trabajo más adecuadas para Bajo Demanda
Algunas cargas de trabajo requieren la disponibilidad garantizada de las instancias bajo demanda: servicios de producción en tiempo real, aplicaciones orientadas al cliente, cargas de trabajo que no pueden manejar interrupciones y cálculos críticos sin puntos de control. Para estos casos de uso, el precio bajo demanda de $0,50/hora proporciona tranquilidad y estabilidad operativa.
Conclusión
La NVIDIA RTX 5090 representa un salto monumental en la tecnología GPU con sus 92 mil millones de transistores, 21.760 núcleos CUDA y 32 GB de memoria GDDR7 que ofrecen 3,352 billones de operaciones de IA por segundo. Esta GPU emblemática de la arquitectura Blackwell, lanzada a $1.999, ofrece hasta 2 veces el rendimiento de su predecesora.
Novita AI democratiza el acceso a este hardware de vanguardia a través de Instancias Spot por solo $0,25/hora, un ahorro del 50% en comparación con el precio bajo demanda. Siguiendo el modelo exitoso probado con las GPUs RTX 4090 a $0,18/hora, las Instancias Spot de Novita AI utilizan la capacidad sobrante para hacer que la informática de nivel empresarial sea asequible para todos.
Comienza a aprovechar el poder de la RTX 5090 hoy mismo a través del sencillo proceso de despliegue en tres pasos de Novita AI. Experimenta cómo 92 mil millones de transistores de capacidad informática a $0,25/hora pueden acelerar tu innovación sin acelerar tus gastos.
Preguntas frecuentes
¿Cuándo se lanzó la NVIDIA RTX 5090?
NVIDIA lanzó oficialmente la GeForce RTX 5090 el 30 de enero de 2025. Se anunció a principios de ese mes durante el CES 2025 y llegó a las tiendas en cantidades limitadas a finales de enero.
¿Cuál es el precio de la RTX 5090?
El MSRP de la RTX 5090 es de $1.999 USD para la Edición Founders en su lanzamiento. Las tarjetas de socios como ASUS, MSI y otras pueden costar aún más. En Novita AI, puedes acceder al rendimiento de la RTX 5090 a $0,25/hora con Instancias Spot o $0,50/hora bajo demanda, evitando la enorme inversión inicial.
¿Cuánto más rápida es la RTX 5090 en comparación con la RTX 4090?
NVIDIA anuncia hasta 2 veces el rendimiento de la RTX 4090 en ciertos escenarios. En la práctica, muchos juegos y pruebas de rendimiento muestran entre un 20% y un 50% más de fotogramas por segundo en resolución 4K. Cuando se utiliza la Generación de Múltiples Fotogramas de DLSS 4, la brecha de rendimiento puede ampliarse significativamente. Para tareas de cómputo GPU como el renderizado, se espera una mejora de aproximadamente el 35-45%.
¿Cómo funciona el precio de las Instancias Spot en Novita AI?
Las Instancias Spot utilizan la capacidad GPU sobrante con un descuento de hasta el 50%. Las Instancias Spot RTX 5090 cuestan $0,25/hora frente a $0,50/hora bajo demanda. Cada instancia incluye una ventana de protección de 1 hora y un aviso de interrupción con 1 hora de antelación. Este modelo funciona perfectamente para procesamiento por lotes, entrenamiento de ML con puntos de control y cargas de trabajo de investigación flexibles.
¿Puedo usar múltiples GPUs RTX 5090 para entrenamiento distribuido?
Sí, puedes desplegar múltiples instancias RTX 5090 en Novita AI para entrenamiento distribuido. Este enfoque te permite escalar el entrenamiento a través de múltiples GPUs, reduciendo el tiempo de finalización. Con Instancias Spot a $0,25/hora por GPU, el entrenamiento distribuido se vuelve económicamente viable incluso para equipos pequeños.
¿Tienen las Instancias Spot el mismo rendimiento que las Bajo Demanda?
Sí, las Instancias Spot proporcionan un hardware y rendimiento idénticos a las instancias bajo demanda. La única diferencia es la disponibilidad: las Instancias Spot pueden interrumpirse con aviso, mientras que las instancias bajo demanda se ejecutan de forma continua. Ambas ofrecen toda la potencia de la RTX 5090.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA utilizando nuestra API simple, al tiempo que proporciona una nube de GPU asequible y confiable para crear y escalar.



