

Refer your friends to Novita AI and both of you will earn $10 in LLM API credits—up to $500 in total rewards.
To support the developer community, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B is currently available for free on Novita AI.

Qwen 3 0.6B is designed for one core mission—solving specific, high-frequency tasks at minimal cost and latency. While massive models dominate headlines, many production needs—from real-time search to on-device summarization—demand a lightweight solution. Distilled from a powerful parent model, Qwen 3 0.6B delivers fast, resource-efficient performance, making it ideal for scenarios like high-concurrency services, offline inference, vertical fine-tuning, and content moderation. With support for 119 languages and built-in compatibility with tools like MCP, it brings the right balance of intelligence and deployability.
What is Qwen 3’s Improvements?
Hybrid
Hybrid Thinking Modes
Qwen3 adopts a dual-mode reasoning design. For complex tasks, it thinks step-by-step. For simple ones, it replies instantly—balancing speed and depth while optimizing compute costs.
119
Multilingual Support
Qwen3 supports 119 languages and dialects. It’s ideal for global deployment—whether in customer service, multilingual content, or cross-region coding applications.
MCP
Enhanced Agentic Abilities
Integrated with MCP, Qwen3 enhances tool use, function calling, and interaction with external environments—especially useful for autonomous agents and plug-in integrations.
Mac
Effortless Mac Deployment
From M1 to M4 chips, Qwen3 0.6b runs smoothly even on entry-level Apple Silicon Macs—making it ideal for developers using MacBooks or iMacs with limited VRAM.
Qwen 3 0.6B: A Tiny Model Born from Giants
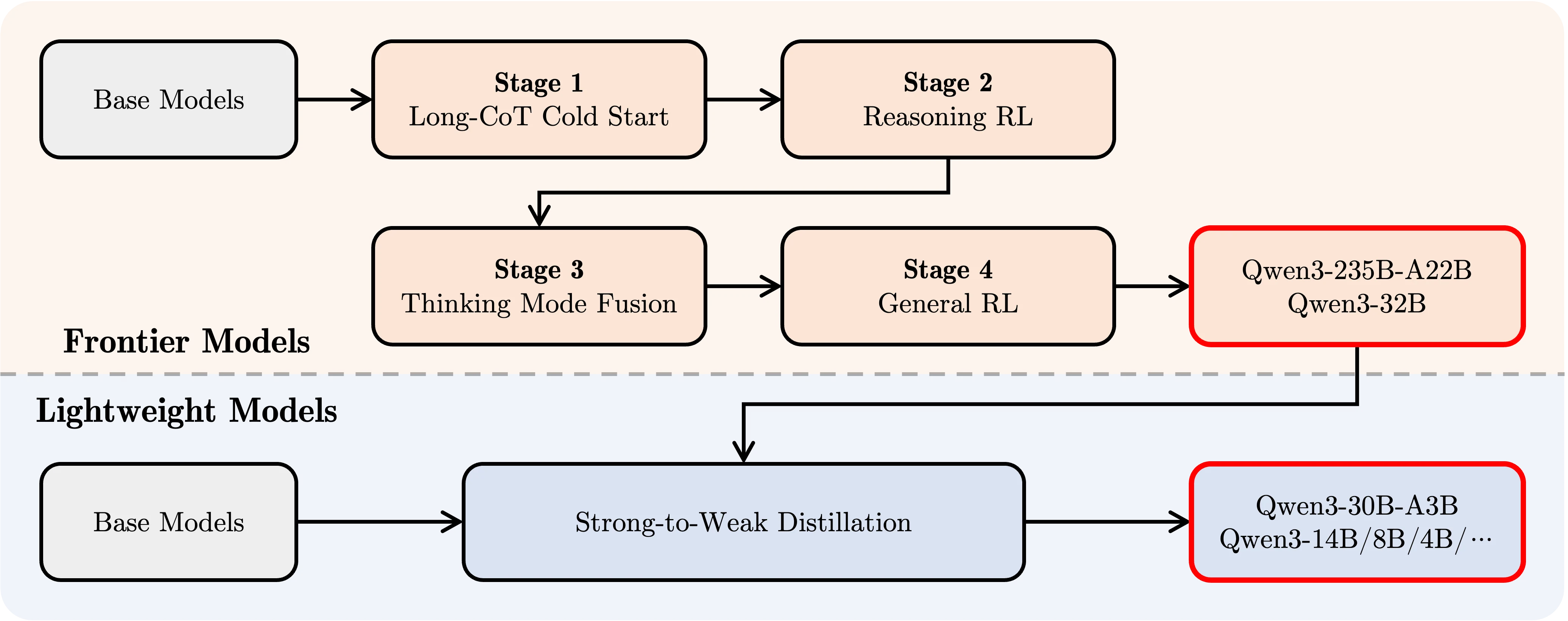
From the diagram, we can infer that Qwen 3 0.6B,1.7B,4B were trained through a Strong-to-Weak Distillation process, which is part of the pipeline for creating Lightweight Models. Here’s a step-by-step breakdown of the training process:
- Base Models:
The process begins with pre-trained Base Models, which act as the foundation for subsequent training and distillation. - Frontier Models:
- Base Models are first trained through a multi-stage process to create Frontier Models like Qwen3-235B-A22B and Qwen3-32B.
- This training involves:
- Stage 1 (Long-CoT Cold Start): Initial training with long chain-of-thought (CoT) reasoning.
- Stage 2 (Reasoning RL): Reinforcement learning (RL) to enhance reasoning capabilities.
- Stage 3 (Thinking Mode Fusion): Integration of Thinking Modes (e.g., reasoning and quick-response modes).
- Stage 4 (General RL): General reinforcement learning for broader capabilities.
- Strong-to-Weak Distillation:
- The large Frontier Models (e.g., Qwen3-235B and Qwen3-32B) are then used as teacher models to guide the training of Lightweight Models like Qwen3-4B.
- This distillation process ensures that the smaller models retain the knowledge and performance of the larger models while significantly reducing size and computational requirements.
- Qwen3 0.6B:
- As a result of this distillation process, Qwen 3 0.6B,1.7B,4B are a lightweight version, benefiting from the knowledge of the larger models while being optimized for efficiency.
Qwen 3 0.6B: Benchmarking at the Top of Small Models
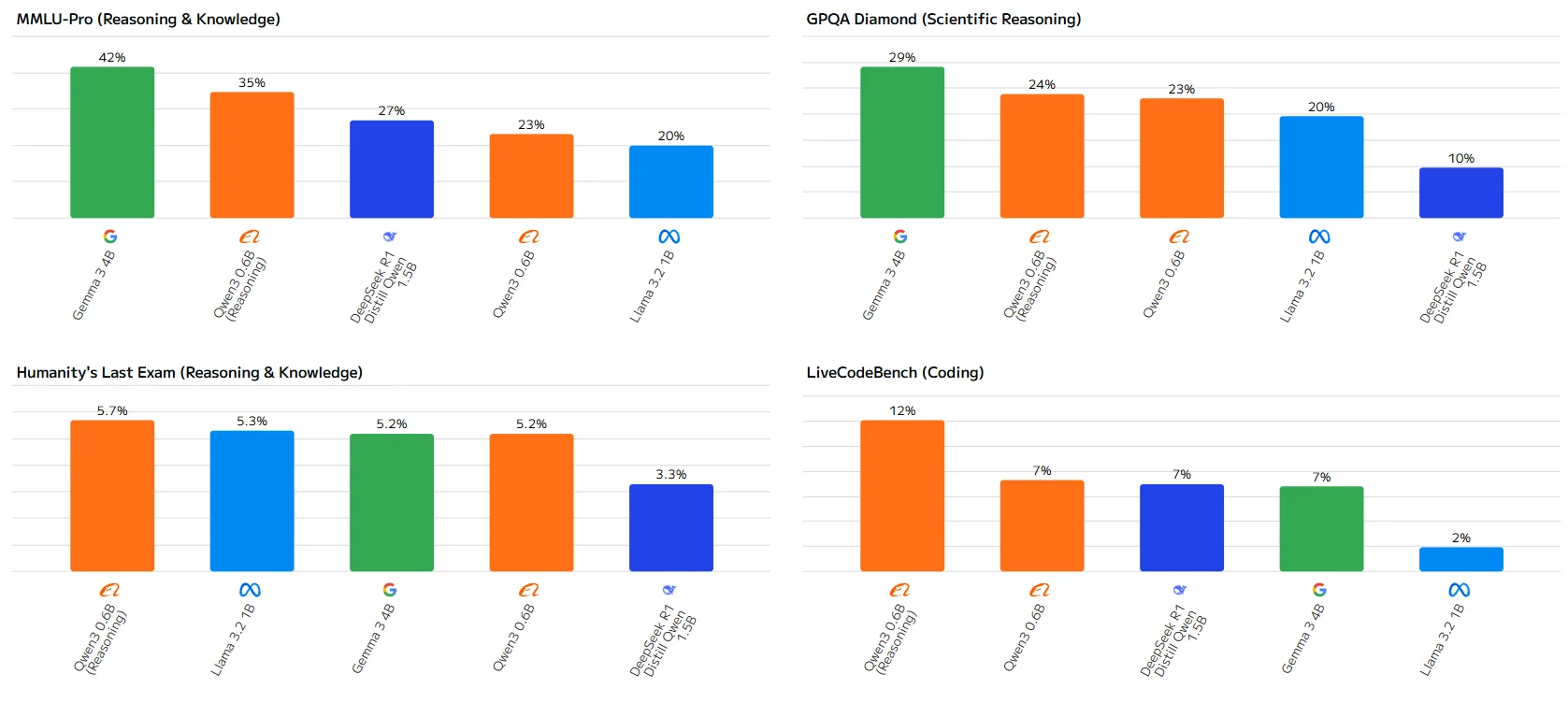
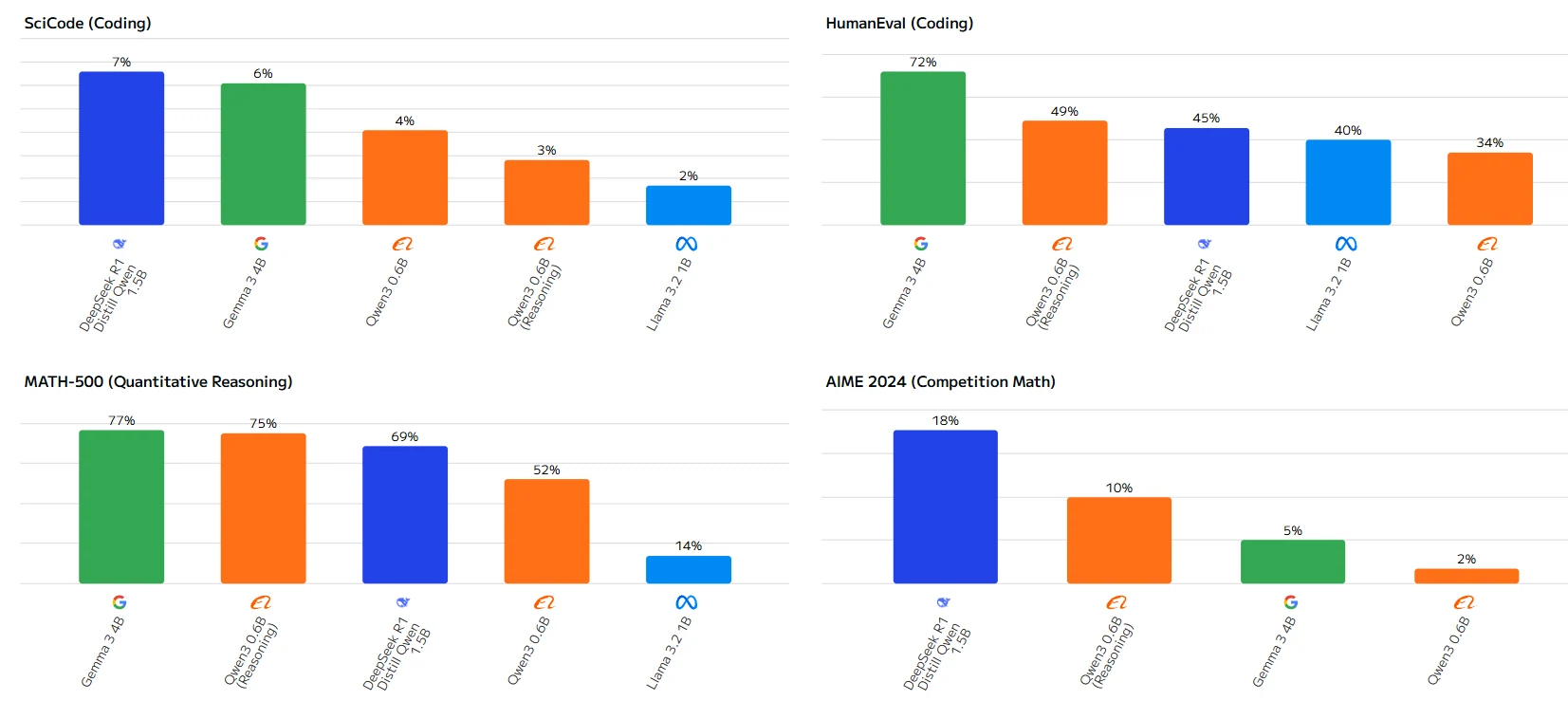
Overall, Qwen 3 0.6b performs well in reasoning - and quantitative - reasoning - related tests, but shows subpar performance in coding - related tests.
Hybird+119+MCP+MAC=High concurrency+On-device+Vertical scenarios
1. High-Concurrency, Low-Latency Online Services
Use Cases: Search ranking, ad delivery, real-time chat—scenarios requiring millions of queries per day.
Requirements: Single-digit millisecond response times and support for over 10,000 QPS (queries per second).
Value:
- A lightweight alternative to traditional BERT models (e.g., TinyBERT) for query rewriting, intent detection, lightweight scoring, and embedding generation.
- Supports bulk inference at the Query × Item level (e.g., one query matching thousands of candidates), enabling deployment where large models are impractical due to latency and cost.
2. On-Device Inference & Edge Computing
Use Cases: Mobile apps, IoT devices, and privacy-sensitive tasks (e.g., local data processing).
Requirements: Lightweight models capable of offline processing with multilingual support.
Value:
- Delivers 55–60 tokens/sec on mobile chips like Snapdragon 8, enabling note summarization and basic tool calls (e.g., MCP protocol).
- Supports 119 languages, ideal for global use cases like cross-border e-commerce and multilingual customer service—reducing reliance on cloud-based LLMs.
3. Low-Cost Fine-Tuning in Vertical Domains
Use Cases: Niche tasks like document parsing, data format conversion, and domain-specific translation.
Requirements: Fast training with low resource consumption and high cost-efficiency.
Value:
- Easily fine-tuned with tools like LLaMA-Factory by preparing datasets—no complex coding required.
Example: Extracting structured JSON from OCR text at less than 0.1% the cost of calling large model APIs. - Enables fast, private deployment in fields like healthcare or law for small-sample tasks (e.g., clinical note classification), reducing data exposure risks.
4. Content Moderation & Compliance Pre-Screening
Use Cases: Real-time review of user-generated content on social platforms or e-commerce reviews.
Requirements: Cost-effective filtering to reduce the load on expensive large models.
Value:
- Acts as the first layer of defense with 60–80% detection performance at a fraction of the cost, catching toxic language or sensitive topics.
- Pairs well with rule engines to block obvious violations and forward only complex cases to LLMs for further review.
How to Access Qwen 3 Small Models via Novita API?
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen3-0.6b-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen 3 0.6B proves that model size doesn’t have to compromise performance. Whether you’re building ultra-fast online services, running offline apps, or deploying domain-specific tools, this compact model delivers practical, production-ready AI—at a fraction of the cost.
Frequently Asked Questions
Is Qwen 3 0.6B suitable for mobile devices?
Yes, it’s optimized for edge deployment and performs well on chips like Snapdragon 8 and Apple Silicon (M1–M4).
What makes Qwen 3 0.6B better than other small models?
Its hybrid reasoning, MCP tool support, and competitive benchmarks make it stand out in the sub-1B parameter class.
Are Qwen3 models free to use?
Yes! Novita AI offers free access to Qwen3 models with easy API integration.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



