

Parrainez vos amis sur Novita AI et vous gagnerez tous les deux 10 $ de crédits API LLM – jusqu’à 500 $ de récompenses totales.
Pour soutenir la communauté des développeurs, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B sont actuellement disponibles gratuitement sur Novita AI.

Qwen 3 0.6B est conçu pour une mission centrale : résoudre des tâches spécifiques et très fréquentes à un coût et une latence minimaux. Alors que les modèles massifs font la une des journaux, de nombreux besoins de production – de la recherche en temps réel au résumé sur l’appareil – exigent une solution légère. Distillé à partir d’un modèle parent puissant, Qwen 3 0.6B offre des performances rapides et économes en ressources, ce qui le rend idéal pour des scénarios tels que les services à forte concurrence, l’inférence hors ligne, le fine-tuning vertical et la modération de contenu. Avec le support de 119 langues et une compatibilité intégrée avec des outils comme MCP, il offre le bon équilibre entre intelligence et déploiement.
Quelles sont les améliorations de Qwen 3 ?
Hybride
Modes de pensée hybrides
Qwen3 adopte une conception de raisonnement à deux modes. Pour les tâches complexes, il réfléchit étape par étape. Pour les tâches simples, il répond instantanément – équilibrant vitesse et profondeur tout en optimisant les coûts de calcul.
119
Support multilingue
Qwen3 prend en charge 119 langues et dialectes. Il est idéal pour un déploiement mondial – que ce soit pour le service client, le contenu multilingue ou les applications de codage interrégionales.
MCP
Capacités agentives améliorées
Intégré avec MCP, Qwen3 améliore l’utilisation des outils, l’appel de fonctions et l’interaction avec des environnements externes – particulièrement utile pour les agents autonomes et les intégrations de plugins.
Mac
Déploiement Mac sans effort
Des puces M1 à M4, Qwen3 0.6b fonctionne sans problème même sur les Mac Apple Silicon d’entrée de gamme – ce qui le rend idéal pour les développeurs utilisant des MacBook ou iMac avec une mémoire VRAM limitée.
Qwen 3 0.6B : Un petit modèle né des géants
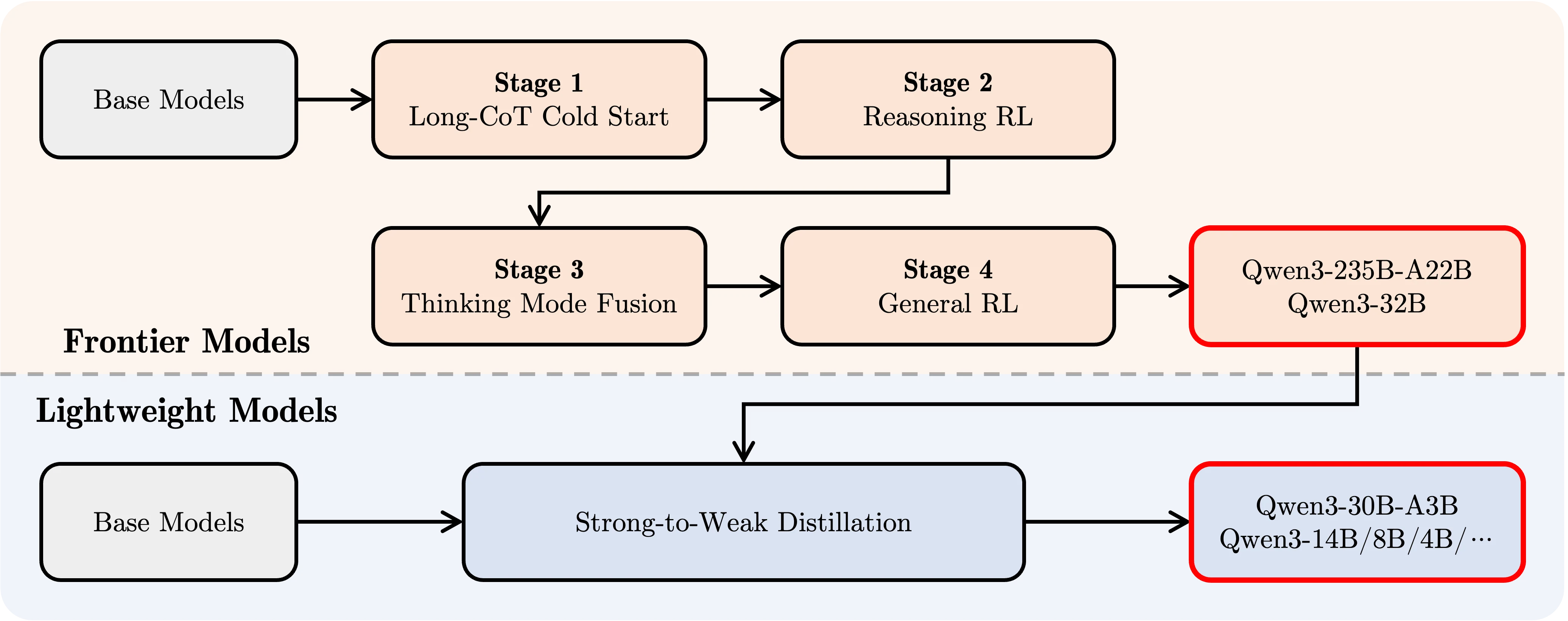
D’après le diagramme, on peut déduire que Qwen 3 0.6B, 1.7B, 4B ont été entraînés via un processus de distillation fort-vers-faible, qui fait partie du pipeline pour créer des modèles légers. Voici une analyse étape par étape du processus d’entraînement :
- Modèles de base :
Le processus commence avec des modèles de base pré-entraînés, qui servent de fondation pour l’entraînement et la distillation ultérieurs. - Modèles de pointe :
- Les modèles de base sont d’abord entraînés via un processus en plusieurs étapes pour créer des modèles de pointe comme Qwen3-235B-A22B et Qwen3-32B.
- Cet entraînement comprend :
- Étape 1 (Démarrage à froid Long-CoT) : Entraînement initial avec un raisonnement long en chaîne de pensée (CoT).
- Étape 2 (RL de raisonnement) : Apprentissage par renforcement (RL) pour améliorer les capacités de raisonnement.
- Étape 3 (Fusion des modes de pensée) : Intégration des modes de pensée (par exemple, modes raisonnement et réponse rapide).
- Étape 4 (RL général) : Apprentissage par renforcement général pour des capacités plus larges.
- Distillation fort-vers-faible :
- Les grands modèles de pointe (par exemple, Qwen3-235B et Qwen3-32B) sont ensuite utilisés comme modèles enseignants pour guider l’entraînement des modèles légers tels que Qwen3-4B.
- Ce processus de distillation garantit que les petits modèles conservent les connaissances et les performances des grands modèles tout en réduisant considérablement la taille et les besoins en calcul.
- Qwen3 0.6B :
- Grâce à ce processus de distillation, Qwen 3 0.6B, 1.7B, 4B sont des versions légères, bénéficiant des connaissances des grands modèles tout en étant optimisées pour l’efficacité.
Qwen 3 0.6B : Benchmark au sommet des petits modèles
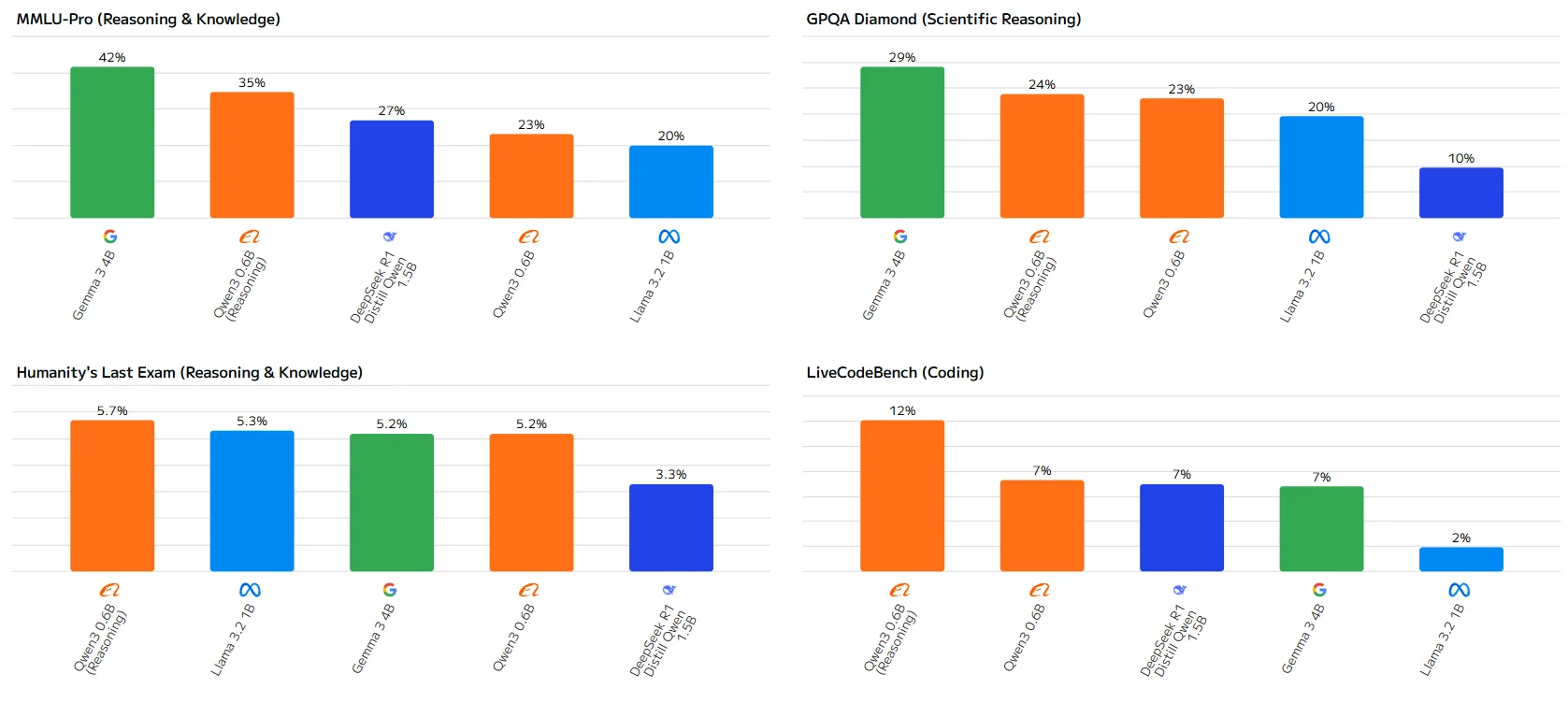
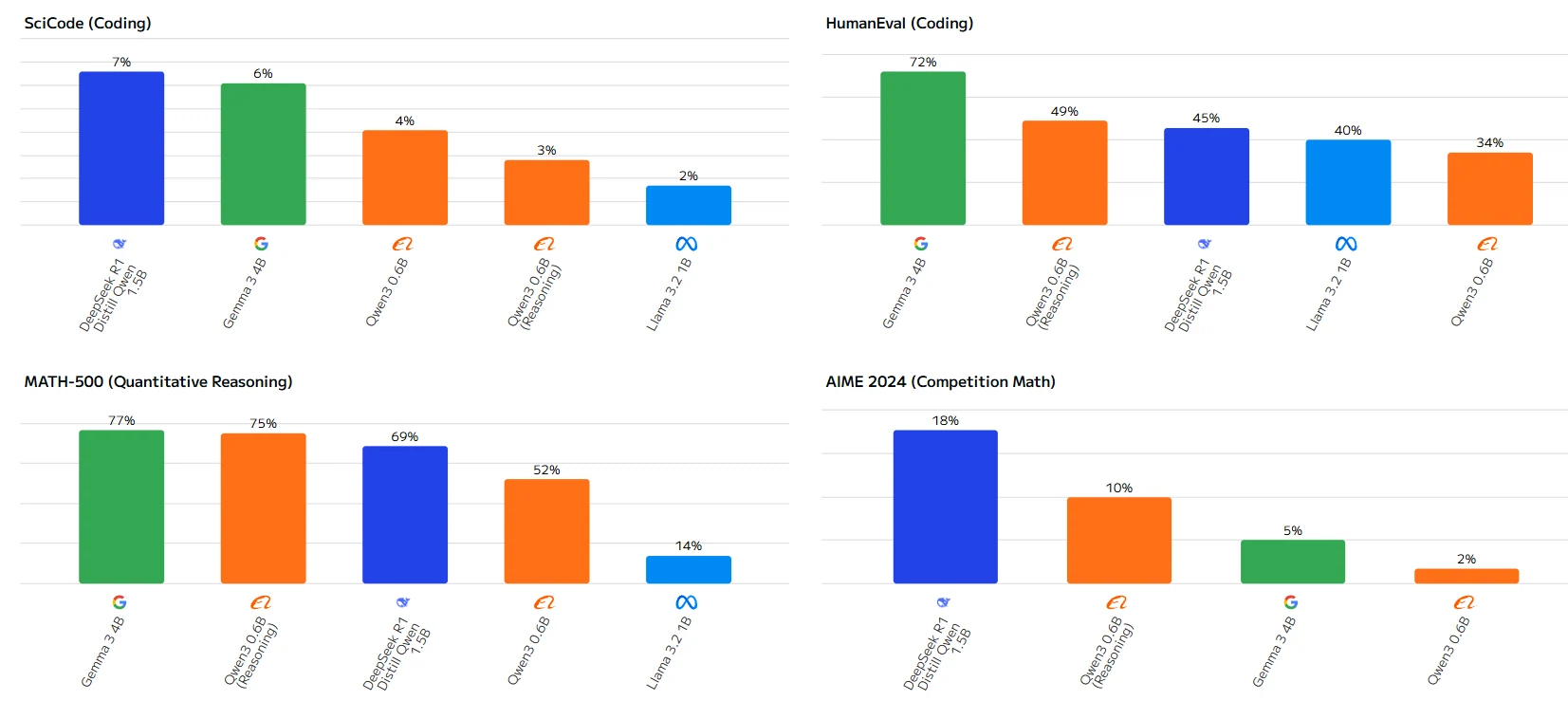
Dans l’ensemble, Qwen 3 0.6b obtient de bons résultats dans les tests de raisonnement et de raisonnement quantitatif, mais montre des performances inférieures dans les tests liés au codage.
Hybird+119+MCP+MAC=Haute concurrence+Sur l’appareil+Scénarios verticaux
1. Services en ligne à haute concurrence et faible latence
Cas d’usage : Classement de recherche, diffusion d’annonces, chat en temps réel – scénarios nécessitant des millions de requêtes par jour.
Exigences : Temps de réponse de l’ordre de quelques millisecondes et support de plus de 10 000 QPS (requêtes par seconde).
Valeur :
- Alternative légère aux modèles BERT traditionnels (ex. TinyBERT) pour la réécriture de requêtes, la détection d’intention, le scoring léger et la génération d’embeddings.
- Prend en charge l’inférence par lots au niveau Requête × Élément (ex. une requête correspondant à des milliers de candidats), permettant un déploiement là où les grands modèles sont impraticables en raison de la latence et du coût.
2. Inférence sur l’appareil et calcul en périphérie
Cas d’usage : Applications mobiles, appareils IoT et tâches sensibles à la vie privée (ex. traitement de données local).
Exigences : Modèles légers capables de traitement hors ligne avec support multilingue.
Valeur :
- Fournit 55 à 60 tokens/s sur des puces mobiles comme Snapdragon 8, permettant le résumé de notes et les appels d’outils de base (ex. protocole MCP).
- Prend en charge 119 langues, idéal pour des cas d’usage mondiaux comme le commerce électronique transfrontalier et le service client multilingue – réduisant la dépendance aux LLM cloud.
3. Fine-tuning à faible coût dans des domaines verticaux
Cas d’usage : Tâches de niche comme l’analyse de documents, la conversion de formats de données et la traduction spécialisée.
Exigences : Entraînement rapide avec une faible consommation de ressources et un rapport coût-efficacité élevé.
Valeur :
- Se fine-tune facilement avec des outils comme LLaMA-Factory en préparant des jeux de données – aucun codage complexe requis.
Exemple : Extraction de JSON structuré à partir de texte OCR à moins de 0,1 % du coût d’appel des API de grands modèles. - Permet un déploiement rapide et privé dans des domaines comme la santé ou le droit pour des tâches à petits échantillons (ex. classification de notes cliniques), réduisant les risques d’exposition des données.
4. Modération de contenu et pré-vérification de conformité
Cas d’usage : Examen en temps réel du contenu généré par les utilisateurs sur les plateformes sociales ou les avis e-commerce.
Exigences : Filtrage rentable pour réduire la charge des grands modèles coûteux.
Valeur :
- Agit comme première ligne de défense avec 60 à 80 % des performances de détection à une fraction du coût, détectant les langages toxiques ou les sujets sensibles.
- S’associe bien aux moteurs de règles pour bloquer les violations évidentes et ne transmettre que les cas complexes aux LLM pour un examen plus approfondi.
Comment accéder aux petits modèles Qwen 3 via l’API Novita ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Essayez Qwen 3 0.6B maintenant !
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page « Paramètres » et copiez la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE Clé API Novita AI>",
)
model = "qwen3-0.6b-fp8"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen 3 0.6B prouve que la taille du modèle ne doit pas nécessairement compromettre les performances. Que vous construisiez des services en ligne ultra-rapides, que vous exécutiez des applications hors ligne ou que vous déployiez des outils spécialisés, ce modèle compact offre une IA pratique et prête pour la production – à une fraction du coût.
Foire aux questions
Qwen 3 0.6B est-il adapté aux appareils mobiles ?
Oui, il est optimisé pour le déploiement en périphérie et fonctionne bien sur des puces comme Snapdragon 8 et Apple Silicon (M1–M4).
Qu’est-ce qui rend Qwen 3 0.6B meilleur que les autres petits modèles ?
Son raisonnement hybride, son support d’outils MCP et ses benchmarks compétitifs le distinguent dans la classe des modèles de moins d’un milliard de paramètres.
Les modèles Qwen3 sont-ils gratuits ?
Oui ! Novita AI offre un accès gratuit aux modèles Qwen3 avec une intégration API facile.
Novita AI est une plateforme cloud d’IA qui permet aux développeurs de déploier facilement des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



