

O KAT-Coder já está disponível na plataforma Novita AI, trazendo capacidades de geração de código agêntica de nível principal para desenvolvedores por meio da nossa infraestrutura de API otimizada. Desenvolvido pela equipe Kwaipilot da Kuaishou, o KAT-Coder atinge uma taxa de resolução excepcional de 73,4% no SWE-Bench Verified, posicionando-se entre os principais modelos de codificação por IA do mundo e rivalizando com os melhores sistemas proprietários.
Como a variante mais poderosa da série KAT (Kwaipilot-AutoThink), o KAT-Coder representa o ápice de um treinamento multiestágio avançado, incluindo treinamento intermediário, ajuste fino supervisionado (SFT), ajuste fino por reforço (RFT) e aprendizado por reforço agêntico (RL) em larga escala em bases de código empresariais. Com uma janela de contexto de 262K e capacidades sofisticadas de orquestração de ferramentas, o KAT-Coder oferece desempenho excepcional para suas necessidades de codificação.
Seja você construindo assistentes de codificação de nível produção, automatizando correções de bugs complexas ou lidando com refatoração em escala de repositório, o KAT-Coder na Novita AI oferece desempenho pronto para empresas com integração de API transparente e preços transparentes.
O que é o KAT-Coder?
O KAT-Coder é o modelo de codificação por IA principal da série KAT, desenvolvido especificamente para geração de código agêntica avançada e fluxos de trabalho de engenharia de software de ponta a ponta. Ao contrário dos assistentes de codificação tradicionais que fornecem sugestões linha por linha ou preenchimento automático simples, o KAT-Coder opera como um verdadeiro agente autônomo, capaz de entender requisitos complexos, orquestrar múltiplas ferramentas de desenvolvedor e concluir tarefas de codificação sofisticadas com intervenção humana mínima.
Atingindo 73,4% no SWE-Bench Verified — um benchmark composto por issues reais do GitHub de repositórios de código aberto populares — o KAT-Coder demonstra capacidade excepcional de navegar por bases de código reais, entender o contexto do projeto e implementar soluções funcionais para problemas genuínos de engenharia de software. Esse nível de desempenho o coloca entre os modelos de codificação mais capazes do mundo.
A arquitetura do KAT-Coder suporta uma janela de contexto massiva de 262.144 tokens, permitindo uma compreensão abrangente de bases de código grandes, operações de refatoração de múltiplos arquivos e raciocínio arquitetônico complexo. O modelo se destaca em tarefas práticas de engenharia de software, incluindo correção de bugs, implementação de funcionalidades, refatoração de código, geração de testes e criação de documentação.
O que diferencia o KAT-Coder de outros modelos de codificação é seu treinamento em bases de código empresariais e sistemas de produção do mundo real — não apenas em repositórios públicos do GitHub. Essa exposição a lógicas de negócio genuínas, padrões arquitetônicos complexos e restrições de nível de produção fundamenta as capacidades do modelo em cenários de desenvolvimento realistas.
O que diferencia o KAT-Coder do KAT-Dev-32B
A série KAT representa tanto excelência acessível quanto desempenho máximo em inteligência de código. Embora o KAT-Coder e o KAT-Dev-32B compartilhem o mesmo pipeline de treinamento fundamental (treinamento intermediário, SFT, RFT e RL agêntico), eles servem a propósitos diferentes no ecossistema:
Lacuna de Desempenho
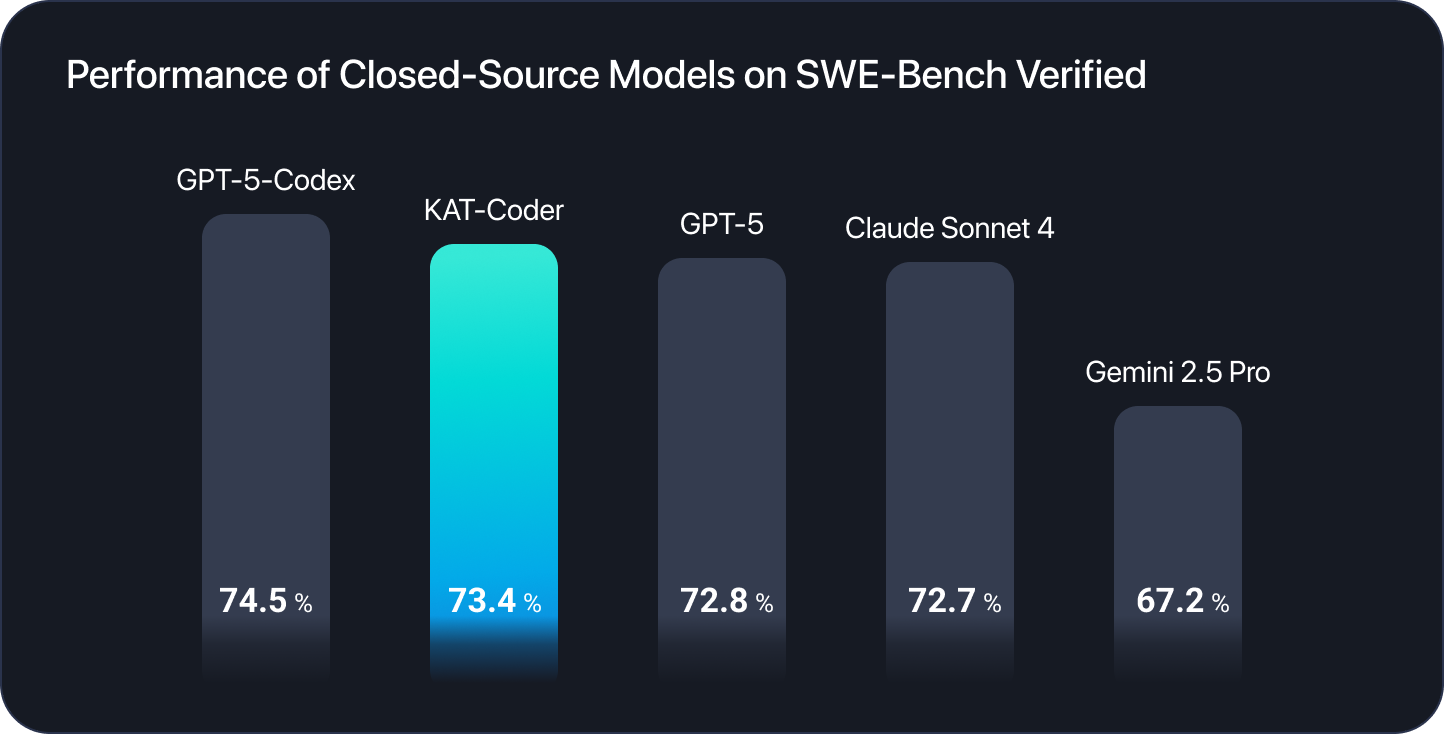
- KAT-Coder: 73,4% no SWE-Bench Verified
- KAT-Dev-32B: 62,4% no SWE-Bench Verified (abordado em nosso artigo anterior)
Essa diferença de 11 pontos percentuais se traduz em taxas de sucesso significativamente melhores em tarefas de codificação complexas do mundo real. O KAT-Dev-32B está classificado em 5º lugar entre todos os modelos de código aberto de diferentes escalas, demonstrando desempenho impressionante para o seu tamanho.
Janela de Contexto
- KAT-Coder: 262.144 tokens — permitindo análise abrangente de repositórios grandes
- KAT-Dev-32B: 65.536 tokens — adequado para a maioria dos projetos, mas com escopo mais limitado
Profundidade do Treinamento
O KAT-Coder se beneficia de um treinamento de RL agêntico mais extenso em bases de código empresariais, resultando em:
- Capacidades superiores de raciocínio em múltiplos arquivos
- Orquestração de ferramentas aprimorada e chamada paralela de ferramentas
- Melhor manipulação de padrões arquitetônicos complexos
- Depuração e análise de causa raiz mais sofisticadas
Modelo de Acesso
- KAT-Coder: Modelo proprietário disponível exclusivamente via API (Novita AI e StreamLake)
- KAT-Dev-32B: Modelo de código aberto com 32B parâmetros disponível no Hugging Face e na Novita AI
Posicionamento de Casos de Uso
- KAT-Coder: Aplicações de nível produção, assistentes de codificação empresariais, tarefas de missão crítica
- KAT-Dev-32B: Pesquisa, experimentação, implantações sensíveis a custos, hospedagem local
Para desenvolvedores que exploraram anteriormente as impressionantes capacidades de código aberto do KAT-Dev-32B, o KAT-Coder oferece o próximo nível de desempenho para cargas de trabalho de produção, onde taxas de sucesso e confiabilidade são fundamentais.
Principais Capacidades
Fluxos de Trabalho Agênticos Avançados
O KAT-Coder orquestra autonomamente ferramentas de desenvolvimento para concluir fluxos de trabalho de codificação de ponta a ponta. O modelo pode invocar analisadores de código, executar suítes de testes, consultar documentação, executar comandos de shell e interagir com controle de versões — tudo sem instruções passo a passo explícitas do desenvolvedor.
Durante o treinamento de RL agêntico em larga escala, os pesquisadores observaram comportamentos emergentes nos quais o KAT-Coder aprendeu a chamar múltiplas ferramentas em paralelo, em vez de sequencialmente. Essa capacidade de chamada paralela de ferramentas acelera drasticamente a conclusão de tarefas, mantendo alta precisão.
Compreensão em Escala de Repositório
Com uma janela de contexto de 262K, o KAT-Coder pode processar e entender bases de código inteiras, mantendo a coerência entre dezenas de arquivos e milhares de linhas de código. O modelo analisa dependências, entende padrões arquitetônicos e propaga alterações de forma consistente entre componentes relacionados.
Essa conscientização abrangente de contexto mostra-se essencial para projetos de escala empresarial, onde informações relevantes podem estar distribuídas por múltiplos módulos, arquivos de configuração e fontes de documentação.
Ciclos de Desenvolvimento Multi-turno
O KAT-Coder se destaca em interações complexas de multi-turno que exigem resolução iterativa de problemas. O modelo pode:
- Fazer perguntas esclarecedoras sobre os requisitos
- Propor múltiplas abordagens de solução
- Incorporar feedback de desenvolvedores
- Refinar implementações progressivamente
- Lidar com alterações de escopo durante a tarefa
Notavelmente, após o treinamento de RL agêntico, o KAT-Coder demonstra a capacidade de concluir tarefas com menos turnos de interação, com uma diminuição média de 32% nos turnos de interação em comparação com modelos treinados após o estágio de SFT.
Geração de Código de Nível Empresarial
Treinado em bases de código empresariais anonimizadas com lógica de negócio real e restrições de produção, o KAT-Coder gera código que reflete as melhores práticas do setor:
- Tratamento de erros adequado e gerenciamento de casos de borda
- Implementações com consciência de segurança
- Algoritmos otimizados para desempenho
- Documentação pronta para produção
- Cobertura de testes abrangente
Cobertura Abrangente de Tarefas
O KAT-Coder lida com oito tipos de tarefas de usuário:
- Implementação de Funcionalidades
- Aprimoramento de Funcionalidades
- Correção de Bugs
- Refatoração
- Otimização de Desempenho
- Geração de Casos de Teste
- Compreensão de Código
- Configuração e Implantação
Suporte a Programação em Múltiplos Domínios
O modelo é treinado em oito cenários principais de programação:
- Desenvolvimento de Aplicações
- Engenharia de UI/UX
- Ciência e Engenharia de Dados
- Aprendizado de Máquina e IA
- Sistemas de Banco de Dados
- Desenvolvimento de Infraestrutura
- Domínios de Programação Especializados
- Engenharia de Segurança
Metodologia de Treinamento
Pipeline de Quatro Estágios
As capacidades excepcionais do KAT-Coder emergem de um pipeline de treinamento de quatro estágios cuidadosamente orquestrado:
Estágio 1: Treinamento Intermediário
O estágio de treinamento intermediário aprimora as capacidades fundamentais de “LLM como agente”. Embora esse estágio não possa gerar ganhos de desempenho grandes em leaderboards atuais como o SWE-Bench, ele tem um impacto significativo nos estágios subsequentes de SFT e RL:
- Capacidade de uso de ferramentas: Criou dados de interação para milhares de ferramentas com execuções reais em ambientes de sandbox
- Interação multi-turno: Construiu diálogos que abrangem até centenas de turnos entre humanos, assistentes e ferramentas
- Injeção de conhecimento de codificação: Adicionou conhecimento de codificação de alta qualidade e específico de domínio
- Dados de commit/PR do Git: Incorporou grandes volumes de dados reais de pull request de repositórios Git
- Seguimento de instruções: Coletou mais de 30 categorias de instruções comuns de usuários
- Dados gerais e de raciocínio: Fortaleceu capacidades de domínio geral e raciocínio
Estágio 2: Ajuste Fino Supervisionado (SFT)
A equipe curou meticulosamente oito tipos de tarefas e oito cenários de programação durante o estágio de SFT para garantir a generalização do modelo e suas capacidades abrangentes. Trajetórias de entrega reais rotuladas por engenheiros humanos foram coletadas, e dados extensos de trajetória foram sintetizados para aprimorar as capacidades de entrega de requisitos de ponta a ponta.
Estágio 3: Ajuste Fino por Reforço (RFT)
Antes do RL, a equipe introduziu de forma inovadora um estágio de RFT com “trajetórias de professor” anotadas por engenheiros humanos como orientação durante o treinamento. Esse estágio constrói uma ponte entre o SFT e o RL:
- Ao transitar da atribuição direta de recompensas absolutas para a avaliação das diferenças relativas entre amostras de rollout e o ground truth, o RFT fornece um sinal de recompensa mais estável e preciso para o RL
- A supervisão em tempo real da correção das amostras durante os rollouts encerra prontamente gerações que se desviam claramente do ground truth, resultando em maior eficiência de amostras para o RL
- As trajetórias de professor fornecem orientação prática sobre como explorar, garantindo estabilidade na fase subsequente de RL
Estágio 4: Aprendizado por Reforço Agêntico em Larga Escala
Escalar o RL agêntico depende de três desafios: aprendizado eficiente sobre históricos de trajetórias não lineares, alavancagem de sinais intrínsecos do modelo e construção de infraestrutura escalável de alto throughput. A equipe resolve esses desafios com várias inovações-chave:
Poda de Árvore Baseada em Entropia
Para priorizar os nós que carregam os sinais de treinamento mais fortes, as trajetórias são comprimidas em uma árvore de prefixos, onde cada nó representa um prefixo compartilhado e cada borda corresponde a um segmento de tokens. Sob um orçamento de computação fixo, o objetivo é reter apenas os nós mais valiosos para o treinamento.
A equipe estima a informatividade dos nós com base em sinais de entropia agregados em toda a árvore e sua probabilidade de serem alcançados, depois poda a árvore expandindo os nós em ordem de importância até que o orçamento se esgote. Heurísticas adicionais garantem que regiões estruturalmente importantes (por exemplo, eventos de ferramenta ou memória) sejam preservadas e que o contexto local seja mantido para um treinamento estável.
Essa poda baseada em entropia permite uma redução substancial da computação redundante, mantendo a maior parte do sinal de treinamento eficaz, resultando em ganhos significativos de throughput e custo geral menor.
Infraestrutura de RL - SeamlessFlow
Para escalar o RL, a equipe implementou a arquitetura SeamlessFlow, que desacopla completamente o treinamento de RL da lógica interna diversa dos agentes, ao mesmo tempo que maximiza a utilização de arquiteturas computacionais heterogêneas. Uma camada intermediária entre agentes e treinamento de RL é dedicada ao gerenciamento de árvore de trajetórias, garantindo separação estrita entre os dois. Um mecanismo de agendamento orientado por tags orquestra a alocação de tarefas em clusters heterogêneos, minimizando bolhas de pipeline e sustentando treinamento de alto throughput.
Interface de Ambiente Unificada e Construção de Dados de RL
A equipe unificou as interfaces de implantação e avaliação em diferentes ambientes de execução de RL, permitindo que qualquer ambiente recém-adicionado seja integrado de forma transparente e com baixo custo. Para cenários de desenvolvimento de software, eles focam em três componentes essenciais: descrições de problemas pareadas com o código de branch correspondente, ambientes executáveis e casos de teste verificáveis.
Pull requests e issues associados são coletados de repositórios de código aberto e alguns repositórios internos, com dados de baixa qualidade filtrados com base em estrelas, atividades de PR e conteúdo de issues. Imagens de ambientes executáveis são construídas sistematicamente, e casos de teste de unidade são gerados para cada instância coletada. Além de dados de engenharia de software, outros domínios verificáveis, como tarefas de matemática e raciocínio, são incorporados, enriquecendo a diversidade de sinais de RL.
Treinamento em Bases de Código Empresariais
Além de dados de código aberto, o KAT-Coder aproveita bases de código empresariais anonimizadas, derivadas de sistemas industriais do mundo real, para treinamento de RL. Ao contrário do treinamento apenas em repositórios públicos (como os do GitHub), que geralmente contêm projetos mais simples, essas bases de código grandes e complexas — que abrangem múltiplas linguagens de programação e representam lógicas de negócio genuínas — expõem os modelos a cenários de desenvolvimento significativamente mais desafiadores.
Treinar agentes para resolver esses problemas industriais do mundo real não apenas aprimora a robustez do aprendizado, mas também fundamenta a proficiência de programação dos modelos resultantes em contextos realistas de nível de produção.
Começando a Usar o KAT-Coder na Novita AI
Acessar o KAT-Coder por meio da Novita AI é simples, com opções para usuários tanto não técnicos quanto desenvolvedores.
Acesso ao Playground
- Acesso Instantâneo: Cadastre-se e comece a experimentar o KAT-Coder em segundos
- Interface Interativa: Teste prompts de codificação, depure aplicações e visualize respostas em tempo real
- Comparação de Modelos: Compare o KAT-Coder com outros modelos para avaliar a adequação
O Playground é ideal para prototipagem, depuração e exploração de comportamentos de modelo sem nenhuma configuração.
Integração com API
Para desenvolvedores, a Novita AI fornece uma API REST unificada para integrar o KAT-Coder em aplicações.
Preços: $0,98/M por tokens de entrada, $3,8/M por tokens de saída
Essa integração flexível suporta temperatura, penalidades, controle de repetição e saídas de streaming para fluxos de trabalho de produção.
Ferramentas de Terceiros
A Novita AI garante compatibilidade com o ecossistema mais amplo:
- Funciona com IDEs como Cursor, Qwen Code e Cline
- Conecta-se com ferramentas de orquestração como LangChain, Dify, CrewAI e Langflow
- Fornece suporte de inferência do Hugging Face para implantação em todo o ecossistema
Casos de Uso e Aplicações
Assistentes de Codificação de Nível Produção
Implante o KAT-Coder como a camada de inteligência para assistentes de codificação empresariais, onde taxas de sucesso e confiabilidade são críticas. O desempenho de 73,4% do modelo no SWE-Bench garante saídas de alta qualidade adequadas para ambientes de produção.
Exemplo de aplicação: Programador em par de IA que lida com triagem de bugs, implementa correções com testes, atualiza documentação e cria pull requests — tudo autonomamente.
Fluxos de Trabalho de Resolução Automatizada de Bugs
Implemente pipelines de resolução de bugs de ponta a ponta nos quais o KAT-Coder:
- Analisa relatórios de bugs e rastros de pilha
- Navega pela base de código para identificar causas raiz
- Propõe e implementa correções direcionadas
- Gera casos de teste abrangentes
- Atualiza a documentação relevante
- Cria mensagens de commit detalhadas
A janela de contexto de 262K garante que o modelo mantenha o contexto completo durante sessões de depuração complexas.
Refatoração em Escala de Repositório
Aproveite a compreensão abrangente de bases de código do KAT-Coder para projetos de refatoração em larga escala:
- Migrando frameworks ou bibliotecas por dezenas de arquivos
- Atualizando APIs obsoletas em todo o projeto
- Implementando alterações arquitetônicas de forma consistente
- Modernizando código legado enquanto preserva o comportamento
- Dividindo monolitos em microsserviços
Automação Inteligente de Revisão de Código
Construa sistemas de revisão de código automatizados que correspondam à qualidade de um desenvolvedor sênior:
- Identificar bugs e vulnerabilidades de segurança
- Sugerir otimizações de desempenho
- Garantir a aderência a padrões de codificação
- Validar a cobertura de testes
- Avaliar o impacto arquitetônico
O treinamento do KAT-Coder em bases de código empresariais garante que as revisões reflitam preocupações reais de produção.
Geração de Suítes de Teste Complexas
Automatize fluxos de trabalho de teste abrangentes:
- Gerar testes de unidade que cubram casos de borda
- Criar testes de integração para interações de múltiplos componentes
- Construir cenários de teste de ponta a ponta
- Desenvolver benchmarks de desempenho
- Produzir documentação de teste significativa
Aplicações de Codificação Interativas
A equipe KAT apresentou vários casos de uso impressionantes que demonstram as capacidades do KAT-Coder:
- Starry Sky: Aplicações visuais interativas
- Fruit Ninja: Desenvolvimento de jogos e implementação de lógica
- Code Refactor: Refatoração e otimização automatizada de código
Esses exemplos destacam a versatilidade do KAT-Coder em diferentes domínios de programação e sua capacidade de gerar aplicações funcionais e interativas.
Conclusão
O KAT-Coder na Novita AI oferece capacidades de codificação agêntica de nível principal, atingindo 73,4% no SWE-Bench Verified e classificando-se entre os principais modelos de codificação por IA do mundo. Por meio de treinamento multiestágio avançado que culmina em RL agêntico em larga escala em bases de código empresariais, o KAT-Coder aprendeu a trabalhar como desenvolvedores sênior experientes — orquestrando ferramentas autonomamente, navegando por repositórios complexos e concluindo fluxos de trabalho de engenharia de software sofisticados.
A janela de contexto de 262K do modelo, suas capacidades de chamada paralela de ferramentas e suporte abrangente a linguagens tornam-no a escolha ideal para aplicações de nível produção, onde taxas de sucesso e qualidade de código são fundamentais. Seja você construindo assistentes de codificação inteligentes, automatizando a resolução de bugs ou lidando com refatoração em escala de repositório, o KAT-Coder oferece o desempenho e a confiabilidade que as empresas exigem.
Em comparação com o KAT-Dev-32B de código aberto, que está classificado em 5º lugar entre todos os modelos de código aberto de diferentes escalas com 62,4% no SWE-Bench Verified, o KAT-Coder representa uma melhoria de desempenho de 11 pontos percentuais e uma janela de contexto 4x maior, tornando-o a escolha clara para cargas de trabalho de produção exigentes.
A série KAT representa tanto excelência acessível (KAT-Dev-32B) quanto desempenho máximo (KAT-Coder) em inteligência de código, dando aos desenvolvedores a flexibilidade de escolher o modelo certo para suas necessidades e restrições específicas.
Comece a construir com o KAT-Coder na Novita AI hoje mesmo:
- API Compatível com OpenAI: Substituição direta para fluxos de trabalho existentes
- Janela de Contexto de 262K: Compreensão abrangente de bases de código
- Desempenho Pronto para Produção: 73,4% no SWE-Bench Verified
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem de GPU acessível e confiável para construção e escalonamento.



