

KAT-Coder ya está disponible en la plataforma Novita AI, brindando a los desarrolladores capacidades de generación de código agéntico de nivel insignia a través de nuestra infraestructura API optimizada. Desarrollado por el equipo Kwaipilot de Kuaishou, KAT-Coder logra una excepcional tasa de resolución del 73.4% en SWE-Bench Verified, posicionándose entre los principales modelos de codificación de IA del mundo y compitiendo con los mejores sistemas propietarios.
Como la variante más potente de la serie KAT (Kwaipilot-AutoThink), KAT-Coder representa la culminación de un entrenamiento avanzado en múltiples etapas que incluye entrenamiento intermedio, ajuste fino supervisado (SFT), ajuste fino por refuerzo (RFT) y aprendizaje por refuerzo (RL) agéntico a gran escala en bases de código empresariales. Con una ventana de contexto de 262K y capacidades sofisticadas de orquestación de herramientas, KAT-Coder ofrece un rendimiento excepcional para tus necesidades de codificación.
Ya sea que estés creando asistentes de codificación de nivel de producción, automatizando correcciones de errores complejas o abordando refactorizaciones a escala de repositorio, KAT-Coder en Novita AI proporciona un rendimiento listo para empresas con integración API fluida y precios transparentes.
¿Qué es KAT-Coder?
KAT-Coder es el modelo de codificación de IA insignia de la serie KAT, diseñado específicamente para la generación de código agéntico avanzada y flujos de trabajo de ingeniería de software de extremo a extremo. A diferencia de los asistentes de codificación tradicionales que ofrecen sugerencias línea por línea o autocompletado simple, KAT-Coder opera como un verdadero agente autónomo capaz de comprender requisitos complejos, orquestar múltiples herramientas de desarrollo y completar tareas de codificación sofisticadas con una intervención humana mínima.
Al alcanzar un 73.4% en SWE-Bench Verified —un benchmark compuesto por issues reales de GitHub de repositorios populares de código abierto—, KAT-Coder demuestra una capacidad excepcional para navegar bases de código reales, comprender el contexto del proyecto e implementar soluciones funcionales a problemas genuinos de ingeniería de software. Este nivel de rendimiento lo sitúa entre los modelos de codificación más capaces del mundo.
La arquitectura de KAT-Coder admite una ventana de contexto masiva de 262,144 tokens, lo que permite una comprensión integral de grandes bases de código, operaciones de refactorización de múltiples archivos y razonamiento arquitectónico complejo. El modelo sobresale en tareas prácticas de ingeniería de software, como corrección de errores, implementación de funciones, refactorización de código, generación de pruebas y creación de documentación.
Lo que distingue a KAT-Coder de otros modelos de codificación es su entrenamiento en bases de código empresariales del mundo real y sistemas de producción, no solo en repositorios públicos de GitHub. Esta exposición a lógica de negocio genuina, patrones arquitectónicos complejos y restricciones de nivel de producción fundamenta las capacidades del modelo en escenarios de desarrollo realistas.
¿Qué hace diferente a KAT-Coder de KAT-Dev-32B?
La serie KAT representa tanto la excelencia accesible como el rendimiento máximo en inteligencia de código. Si bien tanto KAT-Coder como KAT-Dev-32B comparten el mismo pipeline de entrenamiento fundamental (entrenamiento intermedio, SFT, RFT y RL agéntico), cumplen diferentes propósitos en el ecosistema:
Brecha de rendimiento
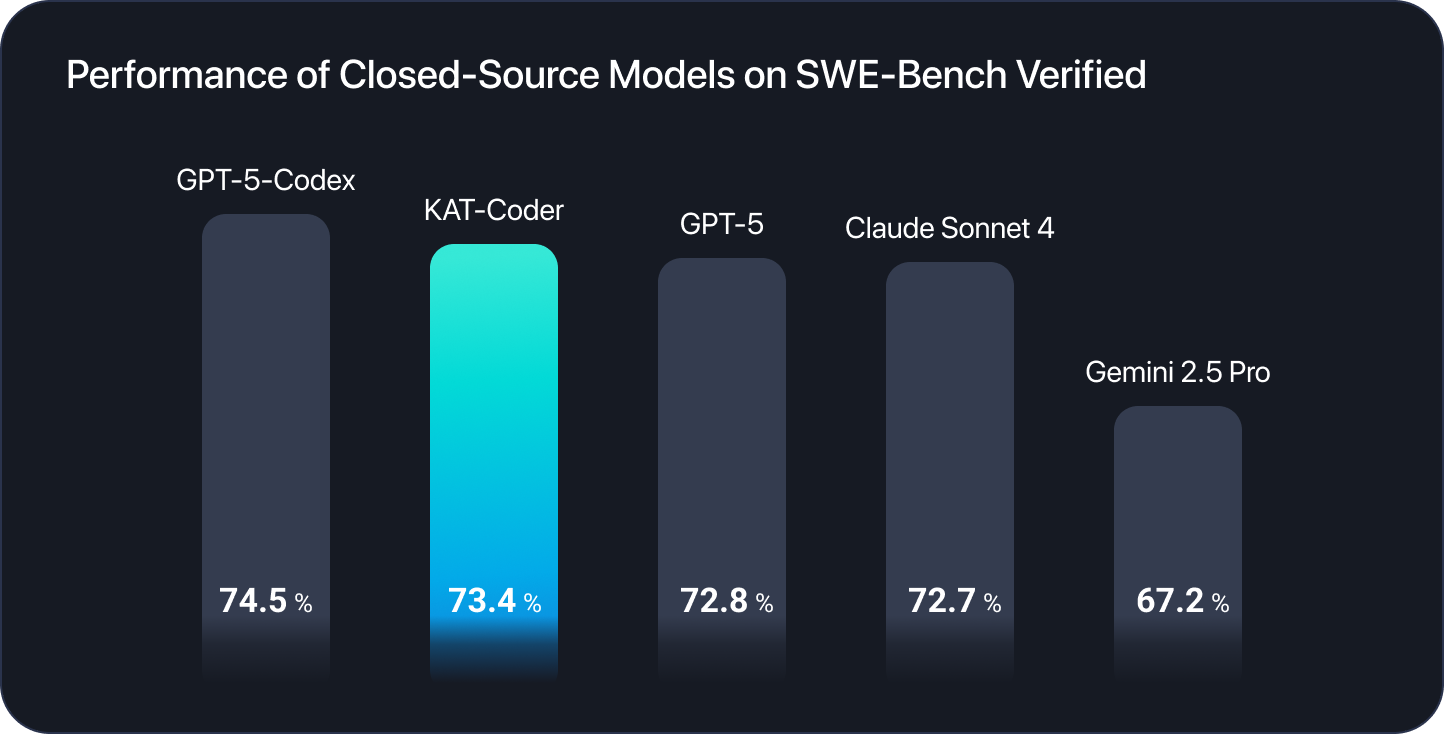
- KAT-Coder: 73.4% en SWE-Bench Verified
- KAT-Dev-32B: 62.4% en SWE-Bench Verified (cubierto en nuestro artículo anterior)
Esta diferencia de 11 puntos porcentuales se traduce en tasas de éxito significativamente mejores en tareas de codificación complejas del mundo real. KAT-Dev-32B ocupa el 5º lugar entre todos los modelos de código abierto de diferentes escalas, demostrando un rendimiento impresionante para su tamaño.
Ventana de contexto
- KAT-Coder: 262,144 tokens — permite un análisis completo de repositorios grandes
- KAT-Dev-32B: 65,536 tokens — adecuado para la mayoría de proyectos pero con un alcance más limitado
Profundidad de entrenamiento
KAT-Coder se beneficia de un entrenamiento RL agéntico más extenso en bases de código empresariales, lo que resulta en:
- Capacidades superiores de razonamiento en múltiples archivos
- Orquestación mejorada de herramientas y llamadas paralelas a herramientas
- Mejor manejo de patrones arquitectónicos complejos
- Depuración y análisis de causa raíz más sofisticados
Modelo de acceso
- KAT-Coder: Modelo propietario disponible exclusivamente a través de API (Novita AI y StreamLake)
- KAT-Dev-32B: Modelo de código abierto de 32B parámetros disponible en Hugging Face y Novita AI
Posicionamiento de casos de uso
- KAT-Coder: Aplicaciones de nivel de producción, asistentes de codificación empresarial, tareas críticas
- KAT-Dev-32B: Investigación, experimentación, implementaciones sensibles al costo, alojamiento local
Para los desarrolladores que previamente exploraron las impresionantes capacidades de código abierto de KAT-Dev-32B, KAT-Coder ofrece el siguiente nivel de rendimiento para cargas de trabajo de producción donde las tasas de éxito y la fiabilidad son primordiales.
Capacidades clave
Flujos de trabajo agénticos avanzados
KAT-Coder orquesta de forma autónoma herramientas de desarrollo para completar flujos de trabajo de codificación de extremo a extremo. El modelo puede invocar analizadores de código, ejecutar suites de pruebas, consultar documentación, ejecutar comandos de shell e interactuar con control de versiones, todo sin instrucciones paso a paso explícitas del desarrollador.
Durante el entrenamiento RL agéntico a gran escala, los investigadores observaron comportamientos emergentes donde KAT-Coder aprendió a llamar múltiples herramientas en paralelo en lugar de secuencialmente. Esta capacidad de llamada paralela de herramientas acelera drásticamente la finalización de tareas manteniendo una alta precisión.
Comprensión a escala de repositorio
Con una ventana de contexto de 262K, KAT-Coder puede procesar y comprender bases de código completas, manteniendo coherencia a través de docenas de archivos y miles de líneas de código. El modelo analiza dependencias, comprende patrones arquitectónicos y propaga cambios de manera consistente entre componentes relacionados.
Esta conciencia de contexto integral resulta esencial para proyectos a escala empresarial donde la información relevante puede estar distribuida en múltiples módulos, archivos de configuración y fuentes de documentación.
Ciclos de desarrollo de múltiples turnos
KAT-Coder sobresale en interacciones complejas de múltiples turnos que requieren resolución iterativa de problemas. El modelo puede:
- Hacer preguntas aclaratorias sobre los requisitos
- Proponer múltiples enfoques de solución
- Incorporar comentarios del desarrollador
- Refinar implementaciones progresivamente
- Manejar cambios de alcance a mitad de tarea
Notablemente, después del entrenamiento RL agéntico, KAT-Coder demuestra la capacidad de completar tareas con menos turnos de interacción, con una disminución promedio del 32% en los turnos de interacción en comparación con modelos entrenados después de la etapa SFT.
Generación de código de nivel empresarial
Entrenado en bases de código empresariales anonimizadas con lógica de negocio real y restricciones de producción, KAT-Coder genera código que refleja las mejores prácticas de la industria:
- Manejo adecuado de errores y casos límite
- Implementaciones conscientes de la seguridad
- Algoritmos optimizados para el rendimiento
- Documentación lista para producción
- Cobertura de pruebas integral
Cobertura integral de tareas
KAT-Coder maneja ocho tipos de tareas de usuario:
- Implementación de funciones
- Mejora de funciones
- Corrección de errores
- Refactorización
- Optimización de rendimiento
- Generación de casos de prueba
- Comprensión de código
- Configuración e implementación
Soporte de programación multi-dominio
El modelo está entrenado en ocho escenarios principales de programación:
- Desarrollo de aplicaciones
- Ingeniería de UI/UX
- Ciencia de datos e ingeniería
- Aprendizaje automático e IA
- Sistemas de bases de datos
- Desarrollo de infraestructura
- Dominios de programación especializados
- Ingeniería de seguridad
Metodología de entrenamiento
Pipeline de cuatro etapas
Las capacidades excepcionales de KAT-Coder surgen de un pipeline de entrenamiento cuidadosamente orquestado en cuatro etapas:
Etapa 1: Entrenamiento intermedio
La etapa de entrenamiento intermedio mejora las capacidades fundamentales de “LLM como agente”. Si bien esta etapa puede no generar grandes ganancias de rendimiento en los rankings actuales como SWE-Bench, tiene un impacto significativo en las etapas posteriores de SFT y RL:
- Capacidad de uso de herramientas: Se construyeron datos de interacción para miles de herramientas con ejecuciones reales en entornos sandbox
- Interacción de múltiples turnos: Se construyeron diálogos que abarcan hasta cientos de turnos entre humanos, asistentes y herramientas
- Inyección de conocimiento de codificación: Se agregó conocimiento de codificación de alta calidad y específico del dominio
- Datos de commits/PRs de Git: Se incorporaron grandes volúmenes de datos reales de pull requests de repositorios Git
- Seguimiento de instrucciones: Se recopilaron más de 30 categorías de instrucciones comunes de usuario
- Datos generales y de razonamiento: Se fortalecieron las capacidades de dominio general y razonamiento
Etapa 2: Ajuste fino supervisado (SFT)
El equipo seleccionó meticulosamente ocho tipos de tareas y ocho escenarios de programación durante la etapa SFT para garantizar la generalización y las capacidades integrales del modelo. Se recopilaron trayectorias de entrega reales etiquetadas por ingenieros humanos, y se sintetizaron datos extensos de trayectorias para mejorar las capacidades de entrega de requisitos de extremo a extremo.
Etapa 3: Ajuste fino por refuerzo (RFT)
Antes de RL, el equipo introdujo de manera innovadora una etapa RFT con “trayectorias de profesor” anotadas por ingenieros humanos como guía durante el entrenamiento. Esta etapa construye un puente entre SFT y RL:
- Al pasar de asignar directamente recompensas absolutas a evaluar las diferencias relativas entre las muestras generadas y la verdad fundamental, RFT proporciona una señal de recompensa más estable y precisa para RL
- La supervisión en tiempo real de la corrección de las muestras durante la generación termina rápidamente las generaciones que se desvían claramente de la verdad fundamental, lo que resulta en una mayor eficiencia de muestreo para RL
- Las trayectorias de profesor proporcionan orientación práctica sobre cómo explorar, asegurando la estabilidad en la fase posterior de RL
Etapa 4: Aprendizaje por refuerzo agéntico a gran escala
Escalar RL agéntico depende de tres desafíos: aprendizaje eficiente sobre historiales de trayectorias no lineales, aprovechamiento de señales intrínsecas del modelo y construcción de infraestructura escalable de alto rendimiento. El equipo aborda estos desafíos con varias innovaciones clave:
Poda de árbol basada en entropía
Para priorizar los nodos que contienen las señales de entrenamiento más fuertes, las trayectorias se comprimen en un árbol de prefijos donde cada nodo representa un prefijo compartido y cada borde corresponde a un segmento de tokens. Bajo un presupuesto de cómputo fijo, el objetivo es retener solo los nodos más valiosos para el entrenamiento.
El equipo estima la informatividad de los nodos basándose en señales de entropía agregadas a través del árbol y su probabilidad de ser alcanzados, luego poda el árbol expandiendo nodos en orden de importancia hasta que se agota el presupuesto. Heurísticas adicionales aseguran que las regiones estructuralmente importantes (por ejemplo, eventos de herramientas o memoria) se conserven y que el contexto local se mantenga para un entrenamiento estable.
Esta poda basada en entropía permite una reducción sustancial del cómputo redundante mientras retiene la mayor parte de la señal de entrenamiento efectiva, lo que conduce a ganancias significativas de rendimiento y un costo general más bajo.
Infraestructura RL - SeamlessFlow
Para escalar RL, el equipo implementó la arquitectura SeamlessFlow, que desacopla completamente el entrenamiento RL de la lógica interna diversa de los agentes mientras maximiza la utilización de arquitecturas computacionales heterogéneas. Una capa intermedia entre los agentes y el entrenamiento RL se dedica a la gestión del árbol de trayectorias, asegurando una separación estricta entre ambos. Un mecanismo de programación basado en etiquetas orquesta la asignación de tareas a través de clústeres heterogéneos, minimizando las burbujas en el pipeline y manteniendo un entrenamiento de alto rendimiento.
Interfaz de entorno unificada y construcción de datos RL
El equipo unificó las interfaces de implementación y evaluación en diferentes entornos de ejecución RL, permitiendo que cualquier entorno recién agregado se integre sin problemas a bajo costo. Para escenarios de desarrollo de software, se centran en tres componentes esenciales: descripciones de problemas emparejadas con el código de la rama correspondiente, entornos ejecutables y casos de prueba verificables.
Se recopilan pull requests y issues asociados de repositorios de código abierto y algunos repositorios internos, filtrando datos de baja calidad basados en estrellas, actividades de PR y contenido de issues. Se construyen sistemáticamente imágenes de entornos ejecutables y se generan casos de prueba unitarios para cada instancia recopilada. Más allá de los datos de ingeniería de software, se incorporan otros dominios verificables como matemáticas y tareas de razonamiento, enriqueciendo la diversidad de las señales RL.
Entrenamiento en bases de código empresariales
Más allá de los datos de código abierto, KAT-Coder aprovecha bases de código empresariales anonimizadas derivadas de sistemas industriales del mundo real para el entrenamiento RL. A diferencia del entrenamiento únicamente en repositorios públicos (como los de GitHub), que a menudo contienen proyectos más simples, estas bases de código grandes y complejas —que abarcan múltiples lenguajes de programación y representan lógica de negocio genuina— exponen a los modelos a escenarios de desarrollo significativamente más desafiantes.
Entrenar agentes para resolver estos problemas industriales del mundo real no solo mejora la robustez del aprendizaje, sino que también fundamenta la competencia de programación de los modelos resultantes en contextos realistas de nivel de producción.
Primeros pasos con KAT-Coder en Novita AI
Acceder a KAT-Coder a través de Novita AI es simple, con opciones tanto para usuarios no técnicos como para desarrolladores.
Acceso al Playground
- Acceso instantáneo: Regístrate y comienza a experimentar con KAT-Coder en segundos
- Interfaz interactiva: Prueba prompts de codificación, depura aplicaciones y visualiza respuestas en tiempo real
- Comparación de modelos: Compara KAT-Coder con otros modelos para evaluar su idoneidad
El Playground es ideal para prototipado, depuración y exploración de comportamientos del modelo sin necesidad de configuración.
Integración API
Para desarrolladores, Novita AI proporciona una API REST unificada para integrar KAT-Coder en aplicaciones.
Precios: $0.98/M tokens de entrada, $3.8/M tokens de salida
Esta integración flexible admite control de temperatura, penalizaciones, control de repetición y salidas en streaming para flujos de trabajo de producción.
Herramientas de terceros
Novita AI asegura compatibilidad con el ecosistema más amplio:
- Funciona con IDEs como Cursor, Qwen Code y Cline
- Se conecta con herramientas de orquestación como LangChain, Dify, CrewAI y Langflow
- Proporciona soporte de inferencia de Hugging Face para implementación en todo el ecosistema
Casos de uso y aplicaciones
Asistentes de codificación de nivel de producción
Implementa KAT-Coder como la capa de inteligencia para asistentes de codificación empresarial donde las tasas de éxito y la fiabilidad son críticas. El rendimiento del 73.4% en SWE-Bench del modelo garantiza resultados de alta calidad adecuados para entornos de producción.
Ejemplo de aplicación: Programador en pareja de IA que maneja el triaje de errores, implementa correcciones con pruebas, actualiza documentación y crea pull requests, todo de forma autónoma.
Flujos de trabajo automatizados de resolución de errores
Implementa pipelines de resolución de errores de extremo a extremo donde KAT-Coder:
- Analiza informes de errores y trazas de pila
- Navega por la base de código para identificar causas raíz
- Propone e implementa correcciones específicas
- Genera casos de prueba integrales
- Actualiza la documentación relevante
- Crea mensajes de commit detallados
La ventana de contexto de 262K asegura que el modelo mantenga el contexto completo durante sesiones de depuración complejas.
Refactorización a escala de repositorio
Aprovecha la comprensión integral de la base de código de KAT-Coder para proyectos de refactorización a gran escala:
- Migrar frameworks o bibliotecas a través de docenas de archivos
- Actualizar APIs obsoletas en todo el proyecto
- Implementar cambios arquitectónicos de manera consistente
- Modernizar código heredado preservando el comportamiento
- Dividir monolitos en microservicios
Automatización de revisión de código inteligente
Construye sistemas automatizados de revisión de código que igualan la calidad de un desarrollador senior:
- Identificar errores y vulnerabilidades de seguridad
- Sugerir optimizaciones de rendimiento
- Asegurar el cumplimiento de estándares de codificación
- Validar la cobertura de pruebas
- Evaluar el impacto arquitectónico
El entrenamiento de KAT-Coder en bases de código empresariales asegura que las revisiones reflejen preocupaciones reales de producción.
Generación de suites de pruebas complejas
Automatiza flujos de trabajo de pruebas integrales:
- Generar pruebas unitarias que cubran casos límite
- Crear pruebas de integración para interacciones de múltiples componentes
- Construir escenarios de prueba de extremo a extremo
- Desarrollar benchmarks de rendimiento
- Producir documentación de pruebas significativa
Aplicaciones de codificación interactivas
El equipo de KAT ha mostrado varios casos de usuario impresionantes que demuestran las capacidades de KAT-Coder:
- Starry Sky: Aplicaciones visuales interactivas
- Fruit Ninja: Desarrollo de juegos e implementación de lógica
- Code Refactor: Refactorización y optimización automatizada de código
Estos ejemplos destacan la versatilidad de KAT-Coder en diferentes dominios de programación y su capacidad para generar aplicaciones funcionales e interactivas.
Conclusión
KAT-Coder en Novita AI ofrece capacidades de codificación agéntica de nivel insignia, alcanzando un 73.4% en SWE-Bench Verified y posicionándose entre los principales modelos de codificación de IA del mundo. A través de un entrenamiento avanzado en múltiples etapas que culmina en RL agéntico a gran escala en bases de código empresariales, KAT-Coder ha aprendido a trabajar como desarrolladores senior experimentados: orquestando herramientas de forma autónoma, navegando repositorios complejos y completando flujos de trabajo de ingeniería de software sofisticados.
La ventana de contexto de 262K del modelo, las capacidades de llamada paralela de herramientas y el soporte integral de lenguajes lo convierten en la opción óptima para aplicaciones de nivel de producción donde las tasas de éxito y la calidad del código son primordiales. Ya sea que estés construyendo asistentes de codificación inteligentes, automatizando la resolución de errores o abordando refactorizaciones a escala de repositorio, KAT-Coder proporciona el rendimiento y la fiabilidad que las empresas demandan.
En comparación con el modelo de código abierto KAT-Dev-32B, que ocupa el 5º lugar entre todos los modelos de código abierto de diferentes escalas con un 62.4% en SWE-Bench Verified, KAT-Coder representa una mejora de rendimiento de 11 puntos porcentuales y una ventana de contexto 4 veces mayor, lo que lo convierte en la opción clara para cargas de trabajo de producción exigentes.
La serie KAT representa tanto la excelencia accesible (KAT-Dev-32B) como el rendimiento máximo (KAT-Coder) en inteligencia de código, brindando a los desarrolladores la flexibilidad de elegir el modelo adecuado para sus necesidades y restricciones específicas.
Comienza a construir con KAT-Coder en Novita AI hoy:
- API compatible con OpenAI: Reemplazo directo para flujos de trabajo existentes
- Ventana de contexto de 262K: Comprensión integral de la base de código
- Rendimiento listo para producción: 73.4% en SWE-Bench Verified
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.



