

KAT-CoderがNovita AIプラットフォームで利用可能になりました。最適化されたAPIインフラを通じて、開発者にフラッグシップレベルのエージェントコード生成機能を提供します。KuaishouのKwaipilotチームによって開発されたKAT-Coderは、SWE-Bench Verifiedで73.4%という優れた解決率を達成し、世界有数のAIコーディングモデルとして、トップクラスのプロプライエタリシステムと肩を並べています。
KAT (Kwaipilot-AutoThink) シリーズの中で最も強力なバリアントであるKAT-Coderは、中間訓練、教師ありファインチューニング(SFT)、強化学習ファインチューニング(RFT)、およびエンタープライズコードベースでの大規模エージェント強化学習(RL)を含む、高度なマルチステージ訓練の集大成です。262Kのコンテキストウィンドウと洗練されたツールオーケストレーション機能により、KAT-Coderはコーディングニーズに卓越したパフォーマンスを提供します。
プロダクショングレードのコーディングアシスタントの構築、複雑なバグ修正の自動化、リポジトリ規模のリファクタリングへの取り組みなど、Novita AI上のKAT-Coderは、シームレスなAPI統合と透明性の高い料金体系で、エンタープライズ対応のパフォーマンスを提供します。
KAT-Coderとは?
KAT-Coderは、KATシリーズのフラッグシップAIコーディングモデルであり、高度なエージェントコード生成とエンドツーエンドのソフトウェアエンジニアリングワークフローに特化して設計されています。行ごとの提案や単純な自動補完を提供する従来のコーディングアシスタントとは異なり、KAT-Coderは真の自律エージェントとして動作し、複雑な要件を理解し、複数の開発ツールをオーケストレーションし、最小限の人間の介入で高度なコーディングタスクを完了できます。
SWE-Bench Verified(人気のオープンソースリポジトリからの実際のGitHub Issueで構成されるベンチマーク)で73.4%を達成したKAT-Coderは、実際のコードベースをナビゲートし、プロジェクトのコンテキストを理解し、実際のソフトウェアエンジニアリング問題に動作するソリューションを実装する卓越した能力を示しています。このパフォーマンスレベルにより、世界で最も有能なコーディングモデルの1つに位置付けられます。
KAT-Coderのアーキテクチャは、262,144トークンの大規模なコンテキストウィンドウをサポートし、大規模なコードベースの包括的な理解、複数ファイルにわたるリファクタリング操作、複雑なアーキテクチャ上の推論を可能にします。このモデルは、バグ修正、機能実装、コードリファクタリング、テスト生成、ドキュメント作成など、実用的なソフトウェアエンジニアリングタスクに優れています。
KAT-Coderを他のコーディングモデルと区別するのは、公開GitHubリポジトリだけでなく、実際のエンタープライズコードベースやプロダクションシステムで訓練されている点です。実際のビジネスロジック、複雑なアーキテクチャパターン、プロダクションレベルの制約に触れることで、モデルの能力は現実的な開発シナリオに根ざしています。
KAT-CoderとKAT-Dev-32Bの違い
KATシリーズは、コードインテリジェンスにおいて、アクセスしやすい優れた性能(KAT-Dev-32B)と究極の性能(KAT-Coder)の両方を提供します。KAT-CoderとKAT-Dev-32Bは同じ基本訓練パイプライン(中間訓練、SFT、RFT、エージェントRL)を共有していますが、エコシステムにおける目的は異なります。
パフォーマンスの差
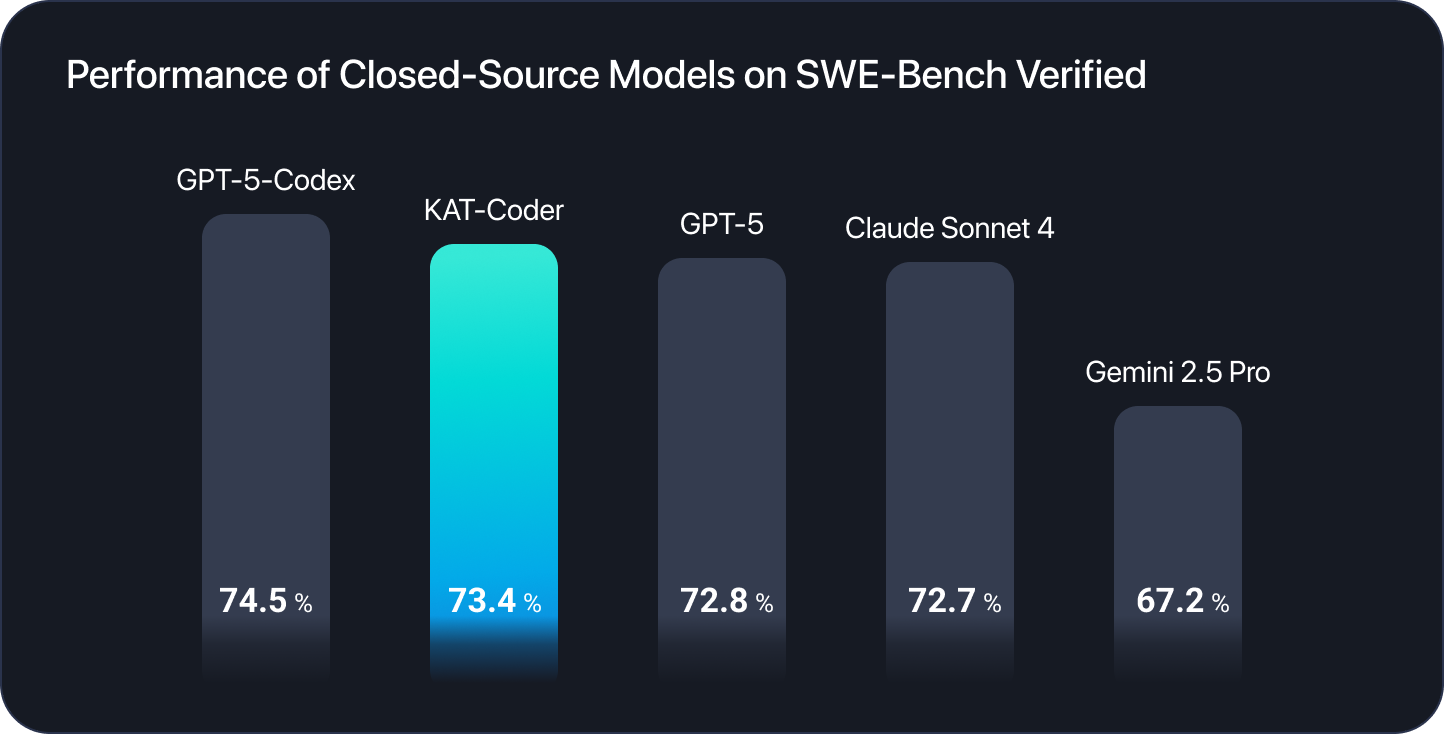
- KAT-Coder: SWE-Bench Verifiedで73.4%
- KAT-Dev-32B: SWE-Bench Verifiedで62.4%(以前の記事で紹介)
この11パーセントポイントの差は、複雑で現実的なコーディングタスクにおける成功率の大幅な向上につながります。KAT-Dev-32Bは、さまざまな規模のオープンソースモデルの中で5位にランクされ、そのサイズとしては印象的なパフォーマンスを示しています。
コンテキストウィンドウ
- KAT-Coder: 262,144トークン – 大規模リポジトリの包括的な分析が可能
- KAT-Dev-32B: 65,536トークン – ほとんどのプロジェクトに適しているが、範囲はより限定的
訓練の深さ
KAT-Coderは、エンタープライズコードベースでのより広範なエージェントRL訓練の恩恵を受けており、次のような優れた能力を発揮します。
- 優れたマルチファイル推論能力
- 強化されたツールオーケストレーションと並行ツール呼び出し
- 複雑なアーキテクチャパターンのより良い処理
- より洗練されたデバッグと根本原因分析
アクセスモデル
- KAT-Coder: プロプライエタリモデル。API(Novita AIおよびStreamLake)経由でのみ利用可能
- KAT-Dev-32B: オープンソースの32Bパラメータモデル。Hugging FaceおよびNovita AIで利用可能
ユースケースの位置付け
- KAT-Coder: プロダクショングレードのアプリケーション、エンタープライズコーディングアシスタント、ミッションクリティカルなタスク
- KAT-Dev-32B: 研究、実験、コスト重視のデプロイ、ローカルホスティング
以前にKAT-Dev-32Bの優れたオープンソース機能を試した開発者にとって、KAT-Coderは、成功率と信頼性が最優先されるプロダクションワークロード向けの次世代パフォーマンスを提供します。
主な機能
高度なエージェントワークフロー
KAT-Coderは、開発ツールを自律的にオーケストレーションして、エンドツーエンドのコーディングワークフローを完了します。このモデルは、コードアナライザーの呼び出し、テストスイートの実行、ドキュメントのクエリ、シェルコマンドの実行、バージョン管理とのやり取りを、開発者からの明示的なステップバイステップの指示なしで行うことができます。
大規模なエージェントRL訓練中、研究者はKAT-Coderがツールを順次呼び出すのではなく、並行して複数のツールを呼び出すことを学習する創発的な行動を観察しました。この並行ツール呼び出し機能により、高い精度を維持しながらタスク完了が大幅に高速化されます。
リポジトリ規模の理解
262Kのコンテキストウィンドウにより、KAT-Coderはコードベース全体を処理して理解し、数十のファイルと数千行のコードにわたって一貫性を維持できます。このモデルは依存関係を分析し、アーキテクチャパターンを理解し、関連コンポーネント間で変更を一貫して伝播します。
この包括的なコンテキスト認識は、関連情報が複数のモジュール、設定ファイル、ドキュメントソースに分散している可能性があるエンタープライズ規模のプロジェクトにとって不可欠です。
マルチターン開発サイクル
KAT-Coderは、反復的な問題解決を必要とする複雑なマルチターンインタラクションに優れています。このモデルは次のことが可能です。
- 要件についての明確化の質問
- 複数の解決アプローチの提案
- 開発者からのフィードバックの組み込み
- 実装の段階的な改良
- タスク途中のスコープ変更への対応
特筆すべきは、エージェントRL訓練後、KAT-Coderはより少ないインタラクションターンでタスクを完了できるようになり、SFT段階後に訓練されたモデルと比較して、インタラクションターン数が平均32%減少したことです。
エンタープライズグレードのコード生成
匿名化されたエンタープライズコードベースで訓練され、実際のビジネスロジックとプロダクション制約を持つKAT-Coderは、業界のベストプラクティスを反映したコードを生成します。
- 適切なエラーハンドリングとエッジケース管理
- セキュリティを意識した実装
- パフォーマンス最適化アルゴリズム
- プロダクション対応のドキュメント
- 包括的なテストカバレッジ
包括的なタスクカバレッジ
KAT-Coderは、8種類のユーザータスクを処理します。
- 機能実装
- 機能強化
- バグ修正
- リファクタリング
- パフォーマンス最適化
- テストケース生成
- コード理解
- 設定とデプロイ
マルチドメインプログラミングサポート
このモデルは、8つの主要なプログラミングシナリオにわたって訓練されています。
- アプリケーション開発
- UI/UXエンジニアリング
- データサイエンスとエンジニアリング
- 機械学習とAI
- データベースシステム
- インフラストラクチャ開発
- 専門プログラミングドメイン
- セキュリティエンジニアリング
訓練方法
4段階パイプライン
KAT-Coderの卓越した能力は、慎重に調整された4段階の訓練パイプラインから生まれます。
ステージ1: 中間訓練
中間訓練段階では、「LLM as an agent」の基礎能力を強化します。この段階ではSWE-Benchのような現在のリーダーボードで大きなパフォーマンス向上が見られないかもしれませんが、その後のSFTおよびRL段階に大きな影響を与えます。
- ツール使用能力: サンドボックス環境での実際の実行を伴う数千のツールのインタラクションデータを構築
- マルチターンインタラクション: 人間、アシスタント、ツール間の、最大数百ターンにわたる対話を構築
- コーディング知識の注入: 高品質でドメイン固有のコーディング知識を追加
- Gitコミット/PRデータ: Gitリポジトリからの実際のプルリクエストデータを大量に組み込み
- 指示追従: 30以上のカテゴリの一般的なユーザー指示を収集
- 一般および推論データ: 一般ドメインの能力と推論を強化
ステージ2: 教師ありファインチューニング(SFT)
SFT段階では、チームは8つのタスクタイプと8つのプログラミングシナリオを注意深くキュレーションし、モデルの汎化と包括的な能力を確保しました。人間のエンジニアによってラベル付けされた実際のデリバリ軌跡が収集され、エンドツーエンドの要件デリバリ能力を強化するために、広範な軌跡データが合成されました。
ステージ3: 強化学習ファインチューニング(RFT)
RLの前に、チームは人間のエンジニアによって注釈が付けられた「教師軌跡」を訓練中のガイダンスとして使用するRFT段階を革新的に導入しました。この段階は、SFTとRLの間の橋渡しを行います。
- 絶対的な報酬を直接割り当てる代わりに、ロールアウトサンプルとグラウンドトゥルースの間の相対的な差異を評価することで、RFTはRLに対してより安定した正確な報酬信号を提供
- ロールアウト中のサンプルの正しさをリアルタイムで監視し、グラウンドトゥルースから明らかに逸脱した生成を迅速に終了することで、RLのサンプル効率が向上
- 教師軌跡は、探索方法に関する実践的なガイダンスを提供し、その後のRLフェーズの安定性を確保
ステージ4: 大規模エージェント強化学習
エージェントRLのスケーリングは、非線形な軌跡履歴での効率的な学習、内在モデル信号の活用、スケーラブルな高スループットインフラストラクチャの構築という3つの課題に依存しています。チームは、いくつかの主要な革新でこれらに取り組んでいます。
エントロピーベースのツリープルーニング
最も強い訓練信号を持つノードを優先するために、軌跡は接頭辞ツリーに圧縮され、各ノードは共有接頭辞を表し、各エッジはトークンのセグメントに対応します。固定計算予算の下では、訓練にとって最も価値のあるノードのみを保持することが目標です。
チームは、ツリー全体で集約されたエントロピー信号とノードに到達する可能性に基づいてノードの情報価値を推定し、予算が尽きるまで重要度順にノードを展開してツリーをプルーニングします。追加のヒューリスティックにより、構造的に重要な領域(ツールイベントやメモリイベントなど)が保持され、安定した訓練のためにローカルコンテキストが維持されます。
このエントロピーベースのプルーニングにより、冗長な計算を大幅に削減しながら、効果的な訓練信号の大部分を保持できるため、スループットが大幅に向上し、全体的なコストが削減されます。
RLインフラストラクチャ - SeamlessFlow
RLをスケーリングするために、チームはSeamlessFlowアーキテクチャを実装しました。これは、RL訓練をエージェントの多様な内部ロジックから完全に分離すると同時に、異種コンピューティングアーキテクチャの利用を最大化します。エージェントとRL訓練の間の中間層は、軌跡ツリー管理に専念し、両者の厳密な分離を保証します。タグ駆動のスケジューリングメカニズムは、異種クラスタ全体でのタスク割り当てを調整し、パイプラインバブルを最小限に抑え、高スループットの訓練を維持します。
統一環境インターフェースとRLデータ構築
チームは、異なるRL実行環境間でデプロイと評価のインターフェースを統一し、新しく追加された環境を低コストでシームレスに統合できるようにしました。ソフトウェア開発シナリオでは、問題の説明と対応するブランチコード、実行可能な環境、検証可能なテストケースの3つの必須コンポーネントに焦点を当てています。
プルリクエストと関連Issueは、オープンソースリポジトリと一部の内部リポジトリから収集され、スター数、PRアクティビティ、Issueの内容に基づいて低品質データがフィルタリングされます。実行可能な環境イメージが体系的に構築され、収集された各インスタンスに対して単体テストケースが生成されます。ソフトウェアエンジニアリングデータに加えて、数学や推論タスクなどの他の検証可能なドメインも組み込まれ、RL信号の多様性が豊かになります。
エンタープライズコードベース訓練
オープンソースデータに加えて、KAT-CoderはRL訓練のために、実際の産業システムから派生した匿名化されたエンタープライズグレードのコードベースを活用しています。GitHubなどの公開リポジトリのみで訓練された場合(多くの場合、より単純なプロジェクトが含まれる)と比較して、これらの大規模で複雑なコードベースは、複数のプログラミング言語にまたがり、実際のビジネスロジックを表しており、モデルを著しく困難な開発シナリオにさらします。
このような現実世界の産業問題を解決するエージェントの訓練は、学習の堅牢性を高めるだけでなく、結果として得られるモデルのプログラミング能力を現実的でプロダクションレベルのコンテキストに根付かせます。
Novita AIでKAT-Coderを使い始める
Novita AIを通じてKAT-Coderにアクセスするのは簡単で、非技術系ユーザーと開発者の両方にオプションがあります。
Playgroundアクセス
- 即時アクセス: サインアップして、数秒でKAT-Coderの実験を開始
- 対話型インターフェース: コーディングプロンプトをテストし、アプリケーションをデバッグし、応答をリアルタイムで視覚化
- モデル比較: KAT-Coderを他のモデルと比較して適合性を評価
Playgroundは、セットアップ不要でプロトタイピング、デバッグ、モデル動作の探索に最適です。
API統合
開発者向けに、Novita AIは統一REST APIを提供し、KAT-Coderをアプリケーションに統合できます。
料金: 入力トークン $0.98/M、出力トークン $3.8/M
この柔軟な統合は、プロダクションワークフロー向けに、temperature、ペナルティ、繰り返し制御、ストリーミング出力をサポートします。
サードパーティツール
Novita AIは、より広範なエコシステムとの互換性を保証します。
- Cursor、Qwen Code、ClineなどのIDEと連携
- LangChain、Dify、CrewAI、Langflowなどのオーケストレーションツールと接続
- エコシステム全体のデプロイ向けにHugging Face推論をサポート
ユースケースとアプリケーション
プロダクショングレードのコーディングアシスタント
成功率と信頼性が重要なエンタープライズコーディングアシスタントのインテリジェンス層としてKAT-Coderをデプロイします。モデルの73.4%のSWE-Benchパフォーマンスは、プロダクション環境に適した高品質な出力を保証します。
アプリケーション例: バグのトリアージ、テスト付き修正の実装、ドキュメントの更新、プルリクエストの作成をすべて自律的に行うAIペアプログラマー。
自動バグ解決ワークフロー
エンドツーエンドのバグ解決パイプラインを実装し、KAT-Coderが次のことを行います。
- バグレポートとスタックトレースを分析
- コードベースをナビゲートして根本原因を特定
- 対象を絞った修正を提案・実装
- 包括的なテストケースを生成
- 関連ドキュメントを更新
- 詳細なコミットメッセージを作成
262Kのコンテキストウィンドウにより、モデルは複雑なデバッグセッション全体で完全なコンテキストを維持します。
リポジトリ規模のリファクタリング
大規模なリファクタリングプロジェクトにKAT-Coderの包括的なコードベース理解を活用します。
- フレームワークやライブラリを数十のファイルにわたって移行
- プロジェクト全体で非推奨のAPIを更新
- アーキテクチャ変更を一貫して実装
- 動作を維持しながらレガシーコードをモダナイズ
- モノリスをマイクロサービスに分割
インテリジェントコードレビューの自動化
シニア開発者の品質に匹敵する自動コードレビューシステムを構築。
- バグやセキュリティ脆弱性を特定
- パフォーマンス最適化を提案
- コーディング標準の順守を確認
- テストカバレッジを検証
- アーキテクチャへの影響を評価
エンタープライズコードベースでの訓練により、KAT-Coderのレビューは実際のプロダクションの懸念を反映します。
複雑なテストスイート生成
包括的なテストワークフローを自動化。
- エッジケースをカバーする単体テストを生成
- 複数コンポーネントの相互作用のための統合テストを作成
- エンドツーエンドのテストシナリオを構築
- パフォーマンスベンチマークを開発
- 意味のあるテストドキュメントを作成
インタラクティブコーディングアプリケーション
KATチームは、KAT-Coderの能力を示すいくつかの印象的なユーザーケースを紹介しています。
- 星空: インタラクティブなビジュアルアプリケーション
- フルーツ忍者: ゲーム開発とロジック実装
- コードリファクタ: 自動コードリファクタリングと最適化
これらの例は、さまざまなプログラミングドメインにわたるKAT-Coderの汎用性と、機能的なインタラクティブアプリケーションを生成する能力を強調しています。
結論
Novita AI上のKAT-Coderは、フラッグシップレベルのエージェントコーディング機能を提供し、SWE-Bench Verifiedで73.4%を達成し、世界有数のAIコーディングモデルにランクされています。エンタープライズコードベースでの大規模エージェントRLに至る高度なマルチステージ訓練を通じて、KAT-Coderは経験豊富なシニア開発者のように動作することを学習しました。ツールを自律的にオーケストレーションし、複雑なリポジトリをナビゲートし、洗練されたソフトウェアエンジニアリングワークフローを完了します。
モデルの262Kコンテキストウィンドウ、並行ツール呼び出し機能、包括的な言語サポートにより、成功率とコード品質が最優先されるプロダクショングレードのアプリケーションに最適な選択肢となります。インテリジェントなコーディングアシスタントの構築、バグ解決の自動化、リポジトリ規模のリファクタリングへの取り組みなど、KAT-Coderはエンタープライズが求めるパフォーマンスと信頼性を提供します。
SWE-Bench Verifiedで62.4%を達成し、さまざまな規模のオープンソースモデルの中で5位にランクされているオープンソースのKAT-Dev-32Bと比較して、KAT-Coderは11パーセントポイントのパフォーマンス向上と4倍のコンテキストウィンドウを実現しており、要求の厳しいプロダクションワークロードに最適な選択肢です。
KATシリーズは、コードインテリジェンスにおいて、アクセスしやすい優れた性能(KAT-Dev-32B)と究極の性能(KAT-Coder)の両方を提供し、開発者は特定のニーズと制約に合わせて適切なモデルを選択する柔軟性を得られます。
今すぐNovita AI上のKAT-Coderで構築を始めましょう。
- OpenAI互換API: 既存のワークフローへのドロップイン置換
- 262Kコンテキストウィンドウ: コードベースの包括的な理解
- プロダクション対応のパフォーマンス: SWE-Bench Verifiedで73.4%
Novita AIは、シンプルなAPIを使用してAIモデルを簡単にデプロイする方法を開発者に提供し、手頃で信頼性の高いGPUクラウドも提供するAIクラウドプラットフォームです。



