

KAT-Coder is now available on the Novita AI platform, bringing flagship-level agentic code generation capabilities to developers through our optimized API infrastructure. Developed by Kuaishou’s Kwaipilot team, KAT-Coder achieves an exceptional 73.4% resolution rate on SWE-Bench Verified, positioning it among the world’s leading AI coding models and rivaling top proprietary systems.
As the most powerful variant in the KAT (Kwaipilot-AutoThink) series, KAT-Coder represents the culmination of advanced multi-stage training including mid-training, supervised fine-tuning (SFT), reinforcement fine-tuning (RFT), and large-scale agentic reinforcement learning (RL) on enterprise codebases. With a 262K context window and sophisticated tool orchestration capabilities, KAT-Coder delivers exceptional performance for your coding needs.
Whether you’re building production-grade coding assistants, automating complex bug fixes, or tackling repository-scale refactoring, KAT-Coder on Novita AI provides enterprise-ready performance with seamless API integration and transparent pricing.
What is KAT-Coder?
KAT-Coder is the flagship AI coding model in the KAT series, specifically engineered for advanced agentic code generation and end-to-end software engineering workflows. Unlike traditional coding assistants that provide line-by-line suggestions or simple autocomplete, KAT-Coder operates as a true autonomous agent capable of understanding complex requirements, orchestrating multiple developer tools, and completing sophisticated coding tasks with minimal human intervention.
Achieving 73.4% on SWE-Bench Verified—a benchmark consisting of real GitHub issues from popular open-source repositories—KAT-Coder demonstrates exceptional ability to navigate actual codebases, understand project context, and implement working solutions to genuine software engineering problems. This performance level places it among the world’s most capable coding models.
KAT-Coder’s architecture supports a massive 262,144-token context window, enabling comprehensive understanding of large codebases, multi-file refactoring operations, and complex architectural reasoning. The model excels at practical software engineering tasks including bug fixing, feature implementation, code refactoring, test generation, and documentation creation.
What distinguishes KAT-Coder from other coding models is its training on real-world enterprise codebases and production systems—not just public GitHub repositories. This exposure to genuine business logic, complex architectural patterns, and production-level constraints grounds the model’s capabilities in realistic development scenarios.
What Makes KAT-Coder Different from KAT-Dev-32B
The KAT series represents both accessible excellence and ultimate performance in code intelligence. While both KAT-Coder and KAT-Dev-32B share the same foundational training pipeline (mid-training, SFT, RFT, and agentic RL), they serve different purposes in the ecosystem:
Performance Gap
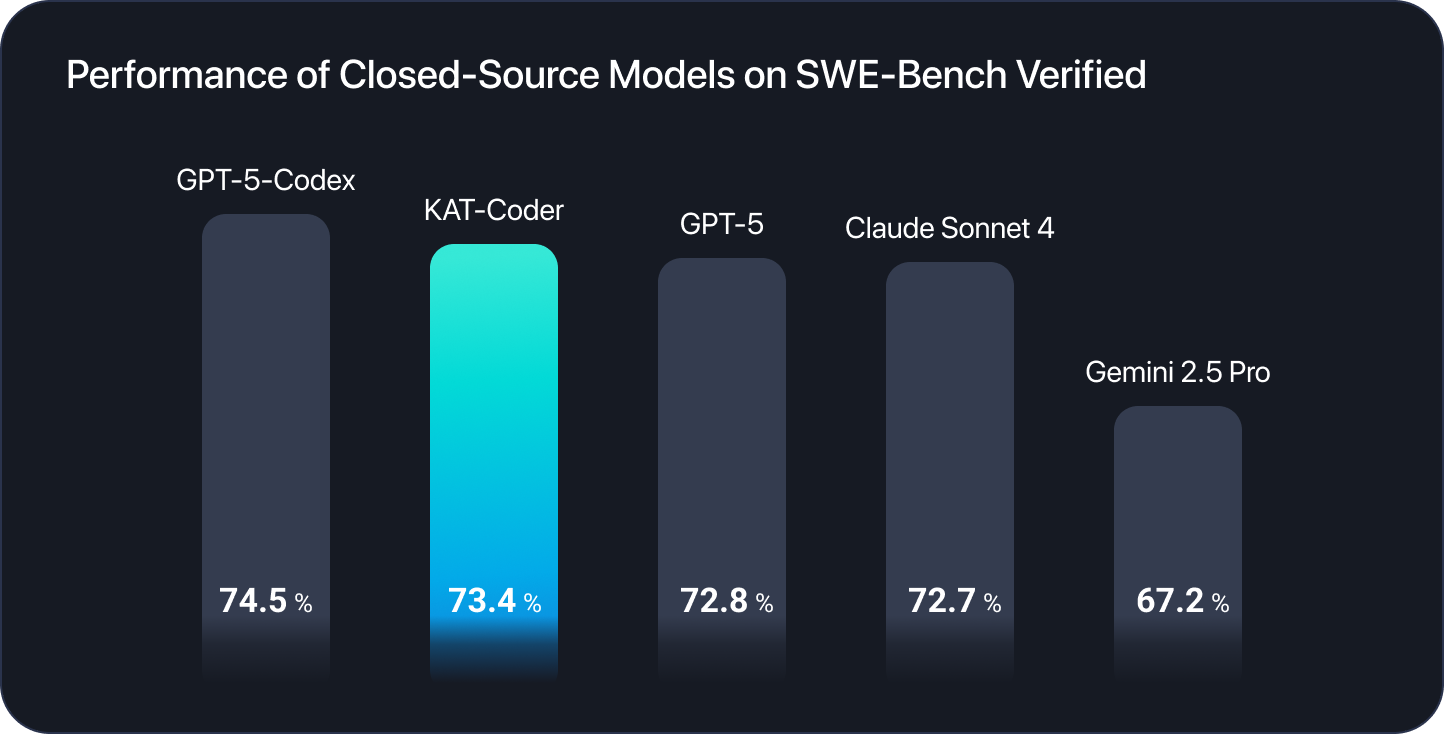
- KAT-Coder: 73.4% on SWE-Bench Verified
- KAT-Dev-32B: 62.4% on SWE-Bench Verified (covered in our previous article)
This 11-percentage-point difference translates to significantly better success rates on complex, real-world coding tasks. KAT-Dev-32B ranks 5th among all open-source models of different scales, demonstrating impressive performance for its size.
Context Window
- KAT-Coder: 262,144 tokens—enabling comprehensive analysis of large repositories
- KAT-Dev-32B: 65,536 tokens—suitable for most projects but more limited scope
Training Depth
KAT-Coder benefits from more extensive agentic RL training on enterprise codebases, resulting in:
- Superior multi-file reasoning capabilities
- Enhanced tool orchestration and parallel tool calling
- Better handling of complex architectural patterns
- More sophisticated debugging and root cause analysis
Access Model
- KAT-Coder: Proprietary model available exclusively via API (Novita AI and StreamLake)
- KAT-Dev-32B: Open-source 32B-parameter model available on Hugging Face and Novita AI
Use Case Positioning
- KAT-Coder: Production-grade applications, enterprise coding assistants, mission-critical tasks
- KAT-Dev-32B: Research, experimentation, cost-sensitive deployments, local hosting
For developers who previously explored KAT-Dev-32B’s impressive open-source capabilities, KAT-Coder offers the next tier of performance for production workloads where success rates and reliability are paramount.
Key Capabilities
Advanced Agentic Workflows
KAT-Coder autonomously orchestrates development tools to complete end-to-end coding workflows. The model can invoke code analyzers, execute test suites, query documentation, run shell commands, and interact with version control—all without explicit step-by-step instructions from the developer.
During large-scale agentic RL training, researchers observed emergent behaviors where KAT-Coder learned to call multiple tools in parallel rather than sequentially. This parallel tool-calling capability dramatically accelerates task completion while maintaining high accuracy.
Repository-Scale Understanding
With a 262K context window, KAT-Coder can process and understand entire codebases, maintaining coherence across dozens of files and thousands of lines of code. The model analyzes dependencies, understands architectural patterns, and propagates changes consistently across related components.
This comprehensive context awareness proves essential for enterprise-scale projects where relevant information may be distributed across multiple modules, configuration files, and documentation sources.
Multi-Turn Development Cycles
KAT-Coder excels at complex, multi-turn interactions requiring iterative problem-solving. The model can:
- Ask clarifying questions about requirements
- Propose multiple solution approaches
- Incorporate developer feedback
- Progressively refine implementations
- Handle scope changes mid-task
Notably, after agentic RL training, KAT-Coder demonstrates the capability to complete tasks with fewer interaction turns, with an average decrease of 32% in the interaction turns compared to models trained after the SFT stage.
Enterprise-Grade Code Generation
Trained on anonymized enterprise codebases with real business logic and production constraints, KAT-Coder generates code that reflects industry best practices:
- Proper error handling and edge case management
- Security-conscious implementations
- Performance-optimized algorithms
- Production-ready documentation
- Comprehensive test coverage
Comprehensive Task Coverage
KAT-Coder handles eight types of user tasks:
- Feature Implementation
- Feature Enhancement
- Bug Fixing
- Refactoring
- Performance Optimization
- Test Case Generation
- Code Understanding
- Configuration & Deployment
Multi-Domain Programming Support
The model is trained across eight major programming scenarios:
- Application Development
- UI/UX Engineering
- Data Science & Engineering
- Machine Learning & AI
- Database Systems
- Infrastructure Development
- Specialized Programming Domains
- Security Engineering
Training Methodology
Four-Stage Pipeline
KAT-Coder’s exceptional capabilities emerge from a carefully orchestrated four-stage training pipeline:
Stage 1: Mid-Training
The mid-training stage enhances foundational “LLM as an agent” capabilities. While this stage may not yield large performance gains on current leaderboards like SWE-Bench, it has a significant impact on subsequent SFT and RL stages:
- Tool-use capability: Built interaction data for thousands of tools with real executions in sandbox environments
- Multi-turn interaction: Constructed dialogues spanning up to hundreds of turns among humans, assistants, and tools
- Coding knowledge injection: Added high-quality, domain-specific coding knowledge
- Git commit/PR data: Incorporated large volumes of real pull request data from Git repositories
- Instruction following: Collected 30+ categories of common user instructions
- General and reasoning data: Strengthened general-domain capabilities and reasoning
Stage 2: Supervised Fine-Tuning (SFT)
The team meticulously curated eight task types and eight programming scenarios during the SFT stage to ensure the model’s generalization and comprehensive capabilities. Real delivery trajectories labeled by human engineers were collected, and extensive trajectory data was synthesized to enhance end-to-end requirement delivery capabilities.
Stage 3: Reinforcement Fine-Tuning (RFT)
Before RL, the team innovatively introduced an RFT stage with “teacher trajectories” annotated by human engineers as guidance during training. This stage builds a bridge between SFT and RL:
- By transitioning from directly assigning absolute rewards to evaluating the relative differences between rollout samples and ground truth, RFT provides a more stable and accurate reward signal for RL
- Real-time supervision of sample correctness during rollouts promptly terminates generations that clearly deviate from ground truth, yielding higher sample efficiency for RL
- Teacher trajectories provide hands-on guidance on how to explore, ensuring stability in the subsequent RL phase
Stage 4: Large-Scale Agentic Reinforcement Learning
Scaling agentic RL hinges on three challenges: efficient learning over nonlinear trajectory histories, leveraging intrinsic model signals, and building scalable high-throughput infrastructure. The team addresses these with several key innovations:
Entropy-Based Tree Pruning
To prioritize nodes that carry the strongest training signals, trajectories are compressed into a prefix tree where each node represents a shared prefix and each edge corresponds to a segment of tokens. Under a fixed compute budget, the goal is to retain only the most valuable nodes for training.
The team estimates the informativeness of nodes based on entropy signals aggregated across the tree and their likelihood of being reached, then prunes the tree by expanding nodes in order of importance until the budget is exhausted. Additional heuristics ensure that structurally important regions (e.g., tool or memory events) are preserved and that local context is maintained for stable training.
This entropy-based pruning enables substantial reduction of redundant computation while retaining most of the effective training signal, leading to significant throughput gains and lower overall cost.
RL Infrastructure - SeamlessFlow
To scale RL, the team implemented SeamlessFlow architecture, which fully decouples RL training from the diverse internal logic of agents while maximizing the utilization of heterogeneous computational architectures. An intermediate layer between agents and RL training is dedicated to trajectory-tree management, ensuring strict separation between the two. A tag-driven scheduling mechanism orchestrates task allocation across heterogeneous clusters, minimizing pipeline bubbles and sustaining high-throughput training.
Unified Environment Interface and RL Data Construction
The team unified the deployment and evaluation interfaces across different RL execution environments, enabling any newly added environment to be seamlessly integrated at low cost. For software development scenarios, they focus on three essential components: problem descriptions paired with corresponding branch code, executable environments, and verifiable test cases.
Pull requests and associated issues are collected from open-source repositories and some internal repositories, with low-quality data filtered based on stars, PR activities, and issue content. Executable environment images are systematically constructed, and unit test cases are generated for each collected instance. Beyond software engineering data, other verifiable domains such as math and reasoning tasks are incorporated, enriching the diversity of RL signals.
Enterprise Codebase Training
Beyond open-source data, KAT-Coder leverages anonymized, enterprise-grade codebases derived from real-world industrial systems for RL training. Unlike training solely on public repositories (like those on GitHub), which often contain simpler projects, these large-scale, complex codebases—spanning multiple programming languages and representing genuine business logic—expose models to significantly more challenging development scenarios.
Training agents to solve such real-world industrial problems not only enhances learning robustness but also grounds the resulting models’ programming proficiency in realistic, production-level contexts.
Getting Started with KAT-Coder on Novita AI
Accessing KAT-Coder through Novita AI is simple, with options for both non-technical and developer users.
Playground Access
- Instant Access: Sign up and start experimenting with KAT-Coder in seconds
- Interactive Interface: Test coding prompts, debug applications, and visualize responses in real time
- Model Comparison: Compare KAT-Coder against other models to evaluate suitability
The Playground is ideal for prototyping, debugging, and exploring model behaviors without any setup.
API Integration
For developers, Novita AI provides a unified REST API to integrate KAT-Coder into applications.
Pricing: $0.98/M input tokens, $3.8/M output tokens
This flexible integration supports temperature, penalties, repetition control, and streaming outputs for production workflows.
Third-Party Tools
Novita AI ensures compatibility with the broader ecosystem:
- Works with IDEs such as Cursor, Qwen Code, and Cline
- Connects with orchestration tools like LangChain, Dify, CrewAI, and Langflow
- Provides Hugging Face inference support for ecosystem-wide deployment
Use Cases and Applications
Production-Grade Coding Assistants
Deploy KAT-Coder as the intelligence layer for enterprise coding assistants where success rates and reliability are critical. The model’s 73.4% SWE-Bench performance ensures high-quality outputs suitable for production environments.
Example application: AI pair programmer that handles bug triage, implements fixes with tests, updates documentation, and creates pull requests—all autonomously.
Automated Bug Resolution Workflows
Implement end-to-end bug resolution pipelines where KAT-Coder:
- Analyzes bug reports and stack traces
- Navigates the codebase to identify root causes
- Proposes and implements targeted fixes
- Generates comprehensive test cases
- Updates relevant documentation
- Creates detailed commit messages
The 262K context window ensures the model maintains full context throughout complex debugging sessions.
Repository-Scale Refactoring
Leverage KAT-Coder’s comprehensive codebase understanding for large-scale refactoring projects:
- Migrating frameworks or libraries across dozens of files
- Updating deprecated APIs throughout the project
- Implementing architectural changes consistently
- Modernizing legacy code while preserving behavior
- Splitting monoliths into microservices
Intelligent Code Review Automation
Build automated code review systems that match senior developer quality:
- Identify bugs and security vulnerabilities
- Suggest performance optimizations
- Ensure adherence to coding standards
- Validate test coverage
- Assess architectural impact
KAT-Coder’s training on enterprise codebases ensures reviews reflect real-world production concerns.
Complex Test Suite Generation
Automate comprehensive testing workflows:
- Generate unit tests covering edge cases
- Create integration tests for multi-component interactions
- Build end-to-end test scenarios
- Develop performance benchmarks
- Produce meaningful test documentation
Interactive Coding Applications
The KAT team has showcased several impressive user cases demonstrating KAT-Coder’s capabilities:
- Starry Sky: Interactive visual applications
- Fruit Ninja: Game development and logic implementation
- Code Refactor: Automated code refactoring and optimization
These examples highlight KAT-Coder’s versatility across different programming domains and its ability to generate functional, interactive applications.
Conclusion
KAT-Coder on Novita AI delivers flagship-level agentic coding capabilities, achieving 73.4% on SWE-Bench Verified and ranking among the world’s leading AI coding models. Through advanced multi-stage training culminating in large-scale agentic RL on enterprise codebases, KAT-Coder has learned to work like experienced senior developers—autonomously orchestrating tools, navigating complex repositories, and completing sophisticated software engineering workflows.
The model’s 262K context window, parallel tool-calling capabilities, and comprehensive language support make it the optimal choice for production-grade applications where success rates and code quality are paramount. Whether you’re building intelligent coding assistants, automating bug resolution, or tackling repository-scale refactoring, KAT-Coder provides the performance and reliability enterprises demand.
Compared to the open-source KAT-Dev-32B, which ranks 5th among all open-source models of different scales with 62.4% on SWE-Bench Verified, KAT-Coder represents an 11-percentage-point performance improvement and 4x larger context window, making it the clear choice for demanding production workloads.
The KAT series represents both accessible excellence (KAT-Dev-32B) and ultimate performance (KAT-Coder) in code intelligence, giving developers the flexibility to choose the right model for their specific needs and constraints.
Start building with KAT-Coder on Novita AI today:
- OpenAI-Compatible API: Drop-in replacement for existing workflows
- 262K Context Window: Comprehensive codebase understanding
- Production-Ready Performance: 73.4% SWE-Bench Verified
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



