

Qwen3の多様性は意図的です 。開発者は、 精度、コスト、メモリ、ハードウェア の間で適切なトレードオフを選択でき、統一されたコア機能である ハイブリッド推論を維持できます。このガイドは、チャットボット、コーディングアシスタント、AI研究エージェントのいずれを構築している場合でも、違いを理解し、特定のニーズに最も適したQwen3モデルを見つけるのに役立ちます。
なぜQwen 3シリーズにはこれほど多くのモデルがあるのか?
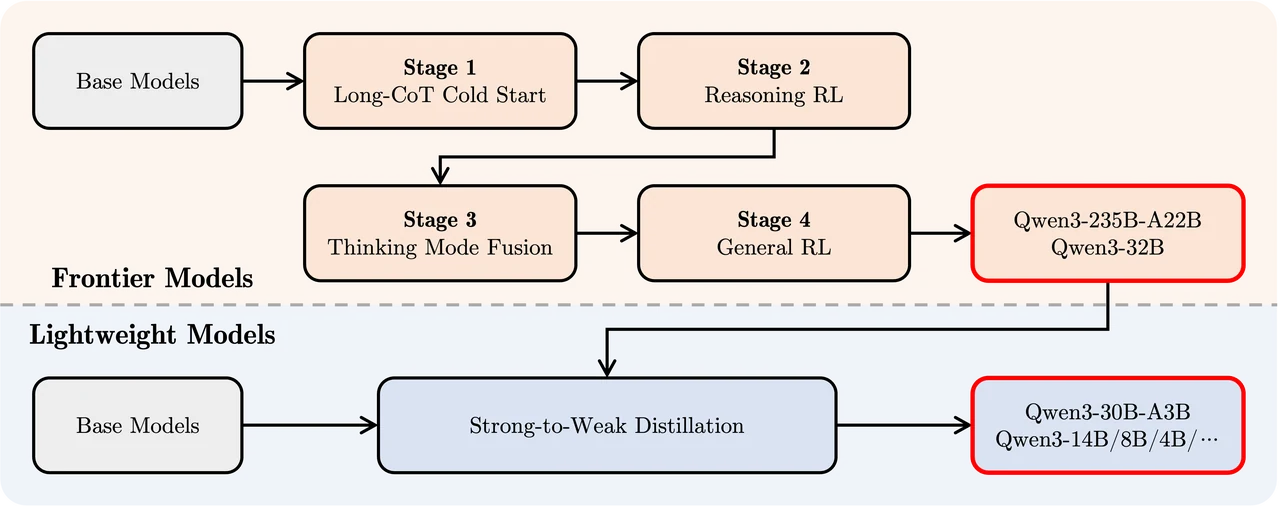
Qwenより
Qwen3 235B A22B/Qwen3 32B
- ベースモデル
これはトレーニングの出発点であり、元のベースモデルを表します。 - ステージ1: Long-CoTコールドスタート
長連鎖推論(Long-CoT)をコールドスタートフェーズとして使用し、複雑な推論タスクの初期能力をモデルに獲得させます。 - ステージ2: 推論RL
推論強化学習(Reasoning RL)により、タスクに対するモデルの推論能力をさらに強化します。 - ステージ3: 思考モードの融合
異なる思考モード(例:論理推論、直感的判断)を融合し、モデルの汎用性と柔軟性を向上させます。 - ステージ4: 一般RL
一般的な強化学習(General RL)を適用し、モデルがより広範なタスクに適応できるようにします。
Qwen3 30B A3B;Qwen3 14B/8B/4B/1.7B/0.6B
- ベースモデル
同様に、これもベースモデルから始まります。 - 強→弱蒸留
強→弱蒸留(Strong-to-Weak Distillation)は、フロンティアモデルから軽量モデルに知識を転送し、これらのモデルが効率性を維持しながら強力な推論能力を保持できるようにします。
Qwen 3モデルの基本紹介
Qwen 3 MoEモデル
| **特徴 ** | Qwen3 235B A22B | Qwen3 30B A3B |
|---|---|---|
| モデルサイズ | 235B/22B(活性化) | 30.5B/3.3B(活性化) |
| アーキテクチャ | 94層、クエリ用64アテンションヘッド、キー・バリュー用4ヘッド | 48層、クエリ用32アテンションヘッド、キー・バリュー用4ヘッド |
| 機能 | 関数呼び出しに対応 | 関数呼び出しに対応 |
| コンテキスト | 32,768トークン | 32,768トークン |
| 言語サポート | 119の言語と方言 | 119の言語と方言 |
| マルチモーダル機能 | テキストからテキスト | テキストからテキスト |
Qwen 3 Denseモデル
| **モデル ** | ** モデルサイズ ** | ** 層数 ** | ** アテンションヘッド (Q / KV)** | ** コンテキスト長 ** | ** 多言語サポート** |
|---|---|---|---|---|---|
| Qwen3 32B | 32.8B | 64 | 64 / 8 | 32K / 最大128K | 119言語・方言 |
| Qwen3 14B | 14.8B | 40 | 40 / 8 | 32K / 最大128K | 119言語・方言 |
| Qwen3 8B | 8.2B | 36 | 32 / 8 | 32K / 最大128K | 119言語・方言 |
| Qwen3 4B | 4.0B | 36 | 32 / 8 | 32K | 119言語・方言 |
| Qwen3 1.7B | 1.7B | 28 | 16 / 8 | 32K | 119言語・方言 |
| Qwen3 0.6B | 0.6B | 28 | 16 / 8 | 32K | 119言語・方言 |
重要なのは、Qwen3シリーズのすべてのモデル(Qwen3 0.6B、1.7B、4B、8B、14B、32B、およびMoEバリアントのQwen3 30B A3B、Qwen3 235B A22Bを含む)が「ハイブリッド推論モード」をサポートしていることです。
- 思考モード: 詳細な分析を必要とする複雑な問題向け。モデルはステップごとに推論し、慎重に検討された回答を提供します。
- 非思考モード: 単純なタスクに適しています。モデルは高速でほぼ瞬時の応答を提供します。
さらに、Qwen3モデルは 「思考予算」 メカニズムを導入しており、ユーザーは推論中の最大トークン使用量を設定できます。これにより、推論の深さを制御し、計算リソースの消費を管理できます。
Qwenより
Qwen 3ベンチマーク
Qwen 3推論ベンチマーク
| **テスト ** | Qwen3 235B | Qwen3 32B | Qwen3 30B | Qwen3 14B | Qwen3 8B | Qwen3 7B | Qwen3 4B | Qwen3 0.6B |
|---|---|---|---|---|---|---|---|---|
| MMLU-Pro | 83% | 80% | 78% | 77% | 74% | 57% | 35% | - |
| GPQA Diamond | 70% | 67% | 62% | 60% | 59% | 36% | 24% | - |
| Humanity’s Last Exam | 11.7% | 8.3% | 6.6% | 5.7% | 5.1% | 4.3% | 4.2% | - |
| LiveCodeBench | 62% | 55% | 52% | 51% | 47% | 41% | 31% | 12% |
| SciCode | 40% | 35% | 32% | 28% | 23% | 4% | 4% | 3% |
| MATH-500 | 96% | 96% | 96% | 93% | 93% | 90% | 89% | 75% |
| AIME 2024 | 84% | 81% | 76% | 75% | 75% | 66% | 51% | 10% |
Qwen 3非推論ベンチマーク
| **テスト ** | Qwen3 235B | Qwen3 32B | Qwen3 30B | Qwen3 14B | Qwen3 8B | Qwen3 7B | Qwen3 4B | Qwen3 0.6B |
|---|---|---|---|---|---|---|---|---|
| MMLU-Pro | 76% | 73% | 71% | 68% | 64% | 41% | 23% | - |
| GPQA Diamond | 61% | 54% | 52% | 47% | 45% | 40% | 28% | 23% |
| Humanity’s Last Exam | 5.2% | 5.2% | 4.7% | 4.6% | 4.3% | 3.7% | 2.8% | - |
| LiveCodeBench | 34% | 32% | 29% | 28% | 23% | 20% | 13% | 7% |
| SciCode | 30% | 28% | 27% | 26% | 17% | 17% | 7% | 4% |
| MATH-500 | 90% | 87% | 87% | 86% | 84% | 83% | 72% | 52% |
| AIME 2024 | 33% | 30% | 28% | 26% | 24% | 21% | 10% | 2% |
Humanity’s Last Exam は、極限の推論と知識をテストします。すべてのモデルのパフォーマンスは低めです。
- 最高レベルのパフォーマンスが求められる ハイステークスなタスク(例:科学研究、高度なコーディング)には、Qwen3 235B が最適です。
- 計算リソースが限られている コスト効率の良いソリューション には、Qwen3 30B または Qwen3 32B がパフォーマンスと効率のバランスが取れています。
- Qwen3 0.6B のような小型モデルは軽量アプリケーションに適していますが、複雑なタスクでは苦戦する可能性があります。
Qwen 3のハードウェア要件
| モデル名 | 必要メモリ (GB) |
| Qwen3 0.6B | 3.01GB |
| Qwen3 1.7B | 5.75GB |
| Qwen3 4B | 10.99GB |
| Qwen3 8B | 19.82GB |
| Qwen3 14B | 33.48GB |
| Qwen3 30B A3B | 74.21GB |
| Qwen3 32B | 73.5GB |
| Qwen3 235B A22B | 553.96GB |
0.6B~4B: ローカルアプリ、チャットボット、軽量エッジ用途。
8B~14B: ミッドサイズ推論サーバー向けの強力な汎用モデル。
32B: クリエイティブな出力とより深い推論を必要とする高性能ユースケース。
235B: 研究グレードまたはエンタープライズ規模のデプロイメント。ほとんどのユーザーにとってコスト効率は良くありません。
あなたのニーズに合うQwen 3はどれ?
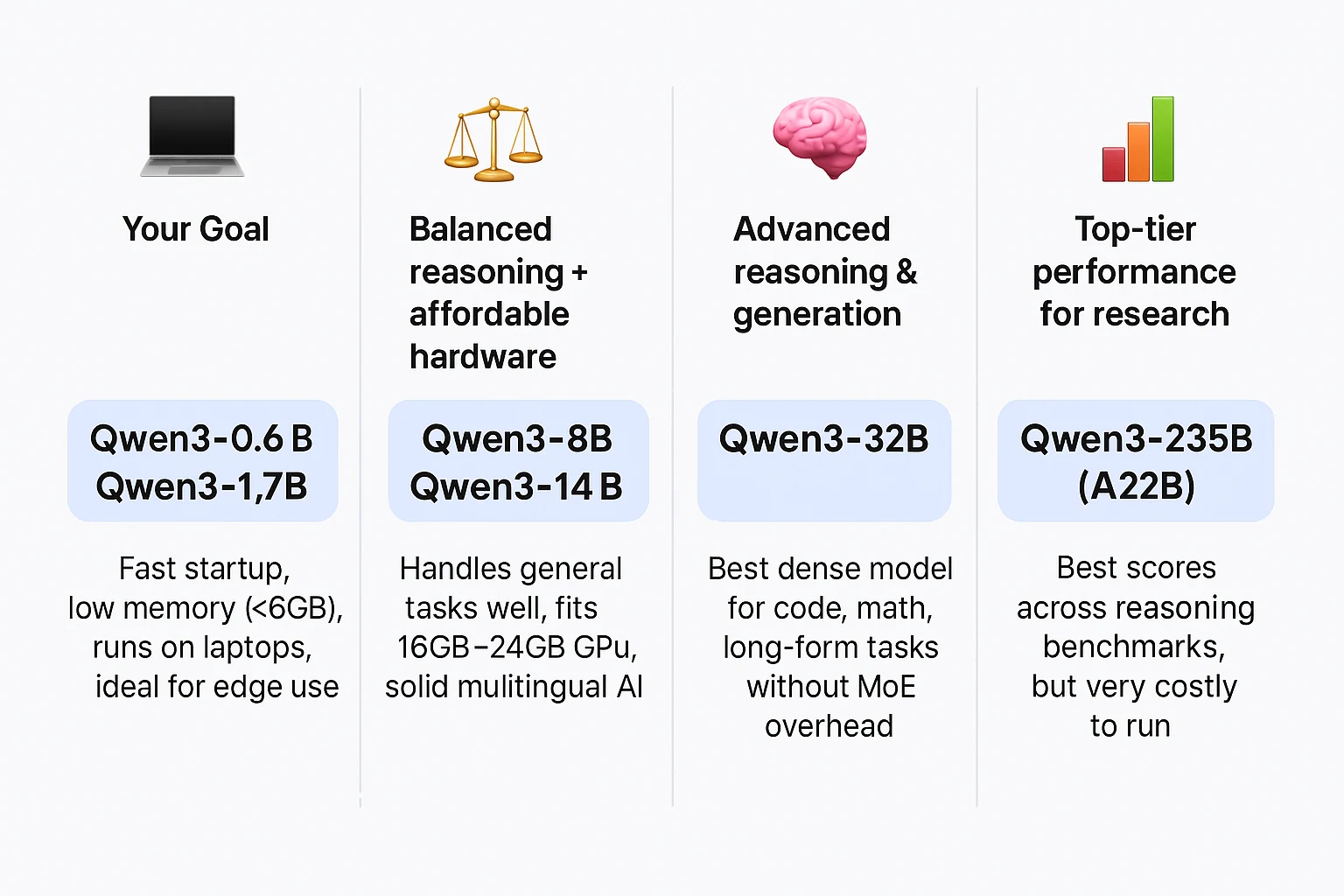
| **あなたの目標 ** | ** 推奨モデル ** | ** 理由** |
|---|---|---|
| ローカル軽量タスク / チャットボット | Qwen3-0.6B / Qwen3-1.7B | 高速起動、低メモリ(<6GB)、ラップトップで動作、エッジ用途に最適 |
| バランスの取れた推論 + 手頃なハードウェア | Qwen3-8B / Qwen3-14B | 一般的なタスクをうまく処理、16GB~24GB GPUに適合、堅実な多言語AI |
| 高度な推論と生成 | Qwen3-32B | MoE構造に頼らず、コード、数学、長文タスクに最適なDenseモデル |
| 研究向けトップクラスのパフォーマンス | Qwen3-235B (A22B) | 推論ベンチマークで最高スコアだが、実行コストは非常に高い |
| 効率的でありながら有能なMoEオプション | Qwen3-30B (A3B) | 約3Bのアクティブパラメータで強力な出力、GPUメモリあたりのスケーリングが優れている |
Qwen 3モデルにコスト効率よくアクセスする方法
Novita AIは、シンプルなAPIを使用して開発者が簡単にAIモデルをデプロイできるようにすると同時に、構築とスケーリングのための手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。
Qwen 3 Reranker 8BおよびEmbedding 8Bに加えて、Novita AIはオープンソースコミュニティの開発をサポートするためにQwen 3(0.6B、1.7B、4B)を無料で提供しています!
ステップ1: ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2: モデルを選択し、無料トライアルを開始
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ3: APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」 ページに移動し、画像の指示に従ってAPIキーをコピーします。

ステップ4: APIをインストール
プログラミング言語に応じたパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。これは、Pythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_nkvtuVXXxS-LlR7txjZ3Rox8GhLMuv1R8IrIySNwTPN7xHJ0SVErFx3kNwJgkUEpcSM4F8c6zmcvyfuc1h59gw==",
)
model = "qwen/qwen3-32b-fp8"
stream = True # or False
max_tokens = 2048
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
ラップトップでチャットボットを構築する場合でも、大規模な科学エージェントをデプロイする場合でも、Qwen3にはリソースと目標に合わせたモデルが用意されています。小さなモデル(0.6B~4B)は軽量で高速、中規模モデル(8B~14B)はパワーと効率のバランスが取れており、大規模モデル(32B、235B)は推論ベンチマークでリードしています。コスト効率の良いアクセスを求める開発者には、Novita AIがAPIを通じてQwen3モデルのシームレスなデプロイを提供しており、一部は完全に無料で利用できます。
よくある質問
ローカルアプリケーションに最適なQwen3モデルはどれですか?
Qwen3-0.6BまたはQwen3-1.7Bです。これらのモデルは基本的なPCやApple Siliconで動作し、軽量タスクやチャットボットに最適です。
高いGPUコストをかけずに強力な推論を得るには何を選べばよいですか?
Qwen3-8BまたはQwen3-14Bです。これらは優れた推論能力を提供し、16~24GB VRAMのGPUに適合します。
Qwen3-32Bはいつ使用すべきですか?
Qwen3-32Bは、MoE構造に頼らずに高度なロジック、コーディング、長文生成が必要な場合に使用します。
Novita AI は、シンプルなAPIを使用して開発者が簡単にAIモデルをデプロイできるようにすると同時に、構築とスケーリングのための手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。



