

主な要点
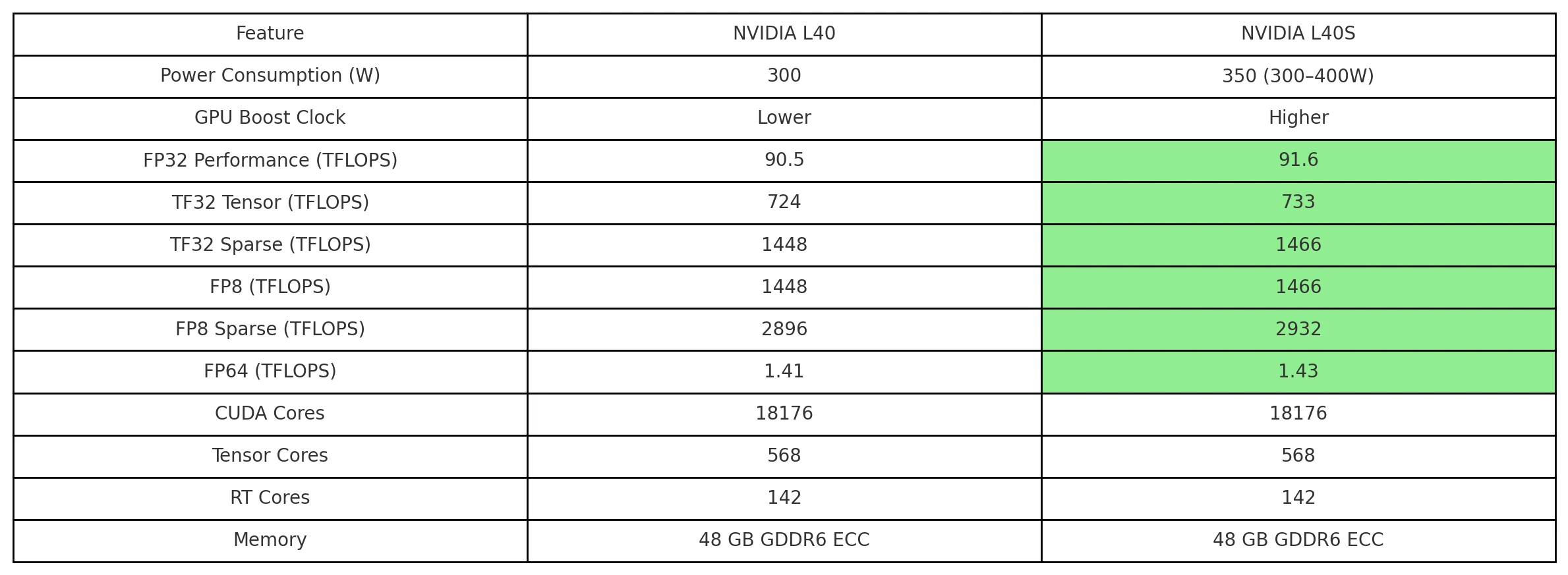
同一のハードウェア仕様: 両方とも18,176 CUDAコア、48GB ECC GDDR6、568 Tensorコアを搭載。
パフォーマンスの優位性: L40S はブーストクロックと TDP が高いため、FP32/TF32/FP8 で約 1.2% 高いパフォーマンスを発揮。
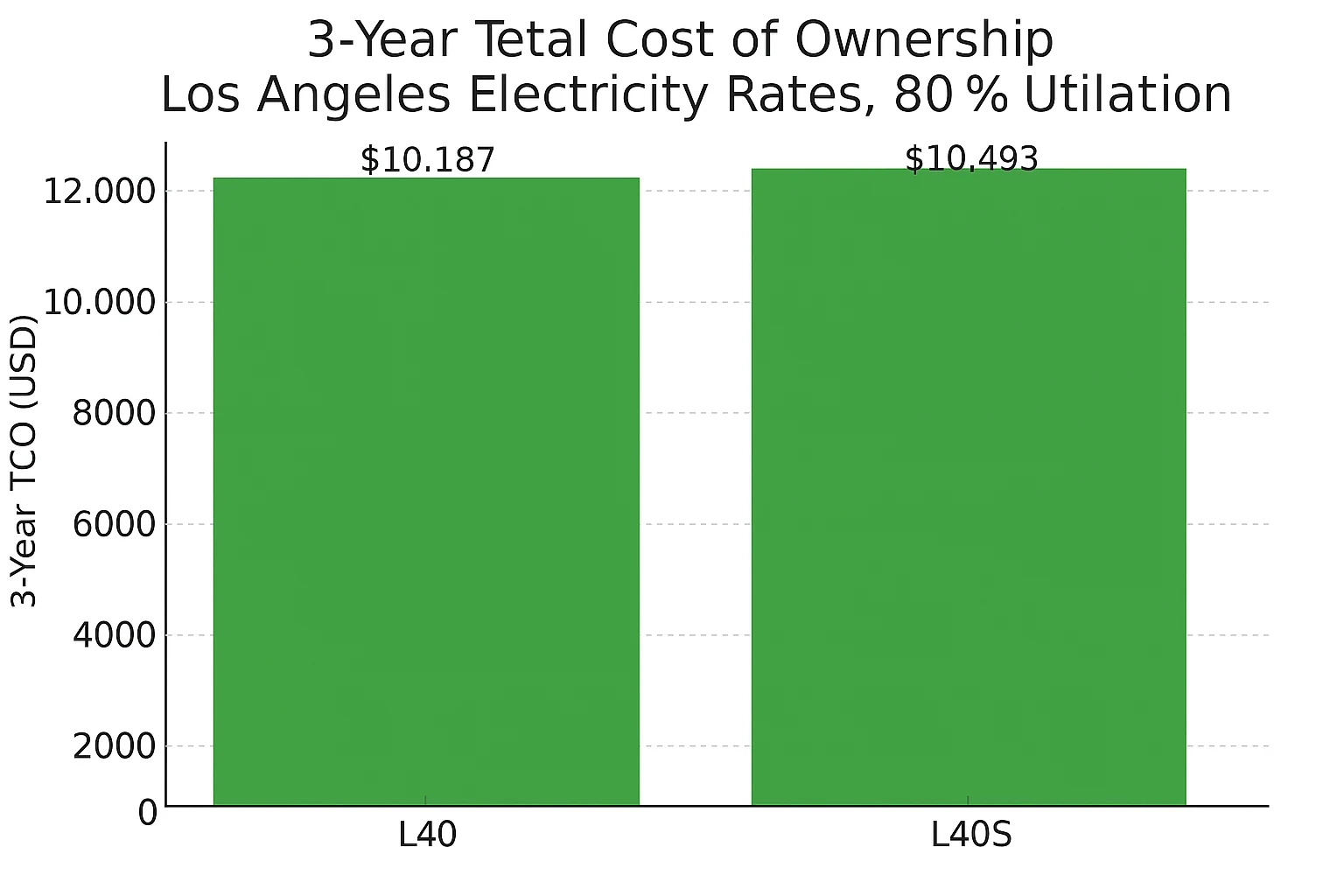
消費電力: L40S は約 350W に対し、L40 は 300W — ロサンゼルスでは年間約 102 ドルの電気代増加。
TCO の差: 3 年間で L40S は約 306 ドル(3%)高くなるが、AI やグラフィックス処理でジョブをより早く完了できる可能性がある。
AIに最適: L40S は生成 AI、LLM 推論、リアルタイムレンダリングに優れている。
効率性に最適: L40 は熱的制約またはエネルギーに敏感な環境に適している。

Novita AI

Runpod
Novita AI での L40S の利用コストは、RunPod の約半分です。
NVIDIA L40 と L40S はどちらも強力な Ada Lovelace ベースの GPU であり、AI、レンダリング、可視化タスク向けに設計されています。コア、メモリ、アーキテクチャなどほとんどの仕様を共有していますが、L40S は TDP とクロック速度が高いため、わずかにパフォーマンスが向上しています。
この記事では、技術的な違い、現実的なコスト(ロサンゼルスの電気代を例に)、およびユースケースの推奨事項を詳しく説明します。
NVIDIA L40 対 L40S: 機能比較
L40S 対 L40: コスト概要(ロサンゼルス例)

L40S 対 L40: アプリケーション

L40S を非常に低価格で実行する方法
Novita AI は、高性能 GPU インスタンスを備えたクラウドベースのプラットフォームを提供しています。強力な GPU により、複雑なタスクの効率的なパフォーマンスを実現し、さまざまなハードウェアへの展開を容易にし、大規模な AI 展開においてローカルハードウェアを維持するよりもコスト効率の高いソリューションを提供します。
ステップ1: アカウント登録
当社ウェブサイトから Novita AI アカウントを作成します。登録後、左サイドバーの「探索」セクションに移動して GPU 提供プランを確認し、AI 開発の旅を始めましょう。

ステップ2: テンプレートと GPU サーバーの探索
PyTorch、TensorFlow、CUDA など、プロジェクトのニーズに合ったテンプレートを選択します。次に、希望する GPU 構成を選択します。オプションには強力な L40S、RTX 4090、A100 SXM4 などがあり、それぞれ VRAM、RAM、ストレージの仕様が異なります。

ステップ3: デプロイメントのカスタマイズ
好みのオペレーティングシステムと設定オプションを選択して環境をカスタマイズし、特定の AI ワークロードと開発ニーズに最適なパフォーマンスを実現します。

ステップ4: インスタンスを起動
「インスタンスを起動」を選択してデプロイを開始します。高性能 GPU 環境は数分で準備が整い、すぐに機械学習、レンダリング、または計算プロジェクトを開始できます。
ワークロードが高速なテンソル演算やリアルタイムレンダリングの恩恵を受ける場合、L40S のわずかなコスト増加は実際のゲインをもたらします。しかし、L40 はバランスの取れたパフォーマンスと電力効率において依然として強力な選択肢です。電力、冷却、または予算に制約がある場合、L40 の方が費用対効果が高くなります。まだ決められませんか?Novita AI のクラウドインスタンスで両方を試すことができます。事前に GPU を購入する必要はありません。
よくある質問
L40S は L40 よりもどのくらい高速ですか?
FP32、TF32、FP8 ワークロードで約 1~2% 高速で、低精度 AI タスクではさらに高いゲインがあります。
追加の 50W 消費電力は重要ですか?
それほど重要ではありません。ロサンゼルスでは年間約 102 ドルしか追加されません。3 年間では TCO が約 3% 増加する程度です。
L40S と L40 は ECC メモリをサポートしていますか?
はい、L40 と L40S はいずれも ECC を搭載しており、信頼性の高い AI およびシミュレーションワークロードに不可欠です。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、構築とスケーリングのための手頃で信頼性の高い GPU クラウドも提供しています。
おすすめの記事



