

La série MiniMax Music — Music 2.0, Music 2.5, Music 2.5+ et le générateur de paroles — est désormais disponible sur Novita AI. Avec un seul appel d’API, les développeurs peuvent générer des chansons complètes avec voix, contrôler l’instrumentation et écrire automatiquement des paroles à partir de zéro. Pas d’abonnements : juste un endpoint simple de paiement à l’usage, prêt pour la production.
Que vous construisiez une application musicale, un pipeline d’automatisation de contenu ou un outil créatif, la série MiniMax Music vous offre un contrôle granulaire sur chaque couche de la sortie : mélodie, voix, style, structure et même les paroles elles-mêmes.
Qu’est-ce que la série MiniMax Music
MiniMax est une entreprise de recherche en IA de premier plan à l’origine d’une gamme de modèles multimodaux couvrant le texte, la parole, la vidéo et la musique. Sa série Music est une gamme dédiée à la génération musicale par IA, allant d’une génération accessible et rentable jusqu’à une fidélité audio de qualité Grammy avec un contrôle de production complet.
La série a été lancée progressivement : Music 2.0 est arrivée en octobre 2025, marquant un grand bond en avant en matière d’authenticité vocale, tandis que Music 2.5 a suivi en janvier 2026 avec un contrôle de précision révolutionnaire. Music 2.5+ étend la gamme avec une prise en charge instrumentale complète, et le générateur de paroles complète la suite en tant qu’outil autonome d’écriture de paroles par IA.
Comparaison des modèles en un coup d’œil
Les trois modèles de génération musicale partagent le même endpoint d’API et la même structure de requête. La différence réside dans la qualité, la contrôlabilité et ce que vous optimisez :
| Modèle | Idéal pour | Prix | Capacité clé |
|---|---|---|---|
| Music 2.0 | Applications à haut volume et rentables | 0,0300 $ / chanson | Voix haute fidélité, large gamme de styles de chant et d’expression émotionnelle |
| Music 2.5 | Utilisation de production équilibrée | 0,1500 $ / chanson | Contrôle de précision au niveau du paragraphe ; fidélité audio de qualité studio |
| Music 2.5+ | Instrumentation riche et qualité maximale | 0,1500 $ / chanson | Tout ce qu’offre 2.5, plus une prise en charge instrumentale complète avec des arrangements multi-instruments riches |
| Générateur de paroles | Écriture de paroles par IA | 0,0100 $ / chanson | Paroles structurées avec balises [verse], [chorus], [bridge] + descripteurs de style |
Quel modèle utiliser selon le cas :
- Music 2.0 — idéal pour la génération à haut volume où la rentabilité prime sur la qualité maximale
- Music 2.5 — le choix par défaut pour la plupart des cas d’utilisation en production ; meilleur équilibre entre contrôle, qualité et coût
- Music 2.5+ — choisissez-le pour les arrangements instrumentaux les plus riches ou lorsque la qualité de sortie est la priorité absolue
Fonctionnalités clés pour les développeurs
🎶 API de génération musicale (/v3/minimax-music)
Contrôle vocal et instrumental
Le paramètre is_instrumental contrôle si la sortie inclut des voix. Définissez-le sur true pour générer une piste entièrement instrumentale — idéale pour la musique de fond, les bandes-son de jeux ou l’audio ambiant. Laissez-le sur false (par défaut) pour des chansons vocales accompagnées de paroles.
Sortie audio flexible
Configurez le format et la qualité de la sortie pour correspondre aux exigences de votre application :
- Format :
mp3,wavoupcm - Fréquence d’échantillonnage : 16000, 24000, 32000 ou 44100 Hz
- Débit binaire : 32000, 64000, 128000 ou 256000 bps
Utilisez output_format: "url" pour recevoir une URL de téléchargement pré-signée au lieu de données audio brutes — plus rapide et plus facile à gérer dans la plupart des architectures.
Filigrane AIGC
Définissez aigc_watermark: true pour intégrer un filigrane de contenu généré par IA dans l’audio — utile pour les plateformes qui doivent étiqueter de manière transparente le contenu créé par IA.
🎼 API du générateur de paroles (/v3/minimax-music-lyrics)
Le générateur de paroles est un endpoint dédié qui écrit des paroles de chanson structurées à partir d’une simple description — aucune connaissance musicale n’est requise.
Deux modes d’écriture
- write_full_song — génère une chanson complète à partir de zéro. Passez un
promptdécrivant le style et untitlefacultatif ; l’API renvoie des paroles structurées avec des balises[verse],[chorus],[bridge], un titre de chanson suggéré et desstyle_tagsque vous pouvez passer directement en tant quepromptdans l’API Music. - edit — prend vos
lyricsexistants et les affine pour améliorer le rythme, le flux et la structure. Utile pour polir un brouillon avant de le transmettre à l’API Music.
Optimiseur de paroles intégré (API Music)
Lorsque vous envoyez des paroles à l’API Music, définissez lyrics_optimizer: true pour que le modèle améliore automatiquement le rythme, le flux des syllabes et la musicalité avant de générer la piste — sans modifier le sens de vos paroles.
Démo en direct : D’un prompt à une chanson complète
Pour montrer le pipeline complet en action, nous avons généré une chanson à l’aide de l’API Novita AI. Voici exactement ce qui s’est passé :
Prompt d’entrée : "Synthwave, Dreamy, Cinematic, Late Night Drive, City Lights, Hopeful" Titre : "Neon Horizon"
Étape 1 — Paroles générées (via /v3/minimax-music-lyrics, mode : write_full_song) :
[Verse]
La ville bourdonne une douce mélodie
Sous le argenté de la lune
Les réverbères peignent l'asphalte de lueur
Nous vivons un rêve éveillé
[Pre-Chorus]
Le moteur murmure, les pneus glissent
Laissant tous les doutes à l'intérieur
Chaque ombre commence à s'estomper
Dans ce moment que nous avons créé
[Chorus]
Oh, la rivière de néon coule
Où va ce sentiment de solitude
Pourchassant des futurs, brillants et audacieux
Une histoire qui attend de se dévoiler
[Bridge]
Peut-être demain, les cieux se dégageront
Laveront le doute et la peur
Mais ce soir, nous sommes libres d'errer
Cette ville en mouvement ressemble à un chez-soi
[Outro]
Balises de style renvoyées : "Synthwave, Dreamy, Cinematic, Late Night Drive, City Lights, Hopeful"
Étape 2 — Chanson complète générée (via /v3/minimax-music, modèle : music-2.5) :
🎵 Audio de démo : Neon Horizon — généré par MiniMax Music 2.5 via Novita AI :
Essayez-le sans code — Terrain de jeu Novita AI
Vous n’êtes pas encore prêt à intégrer l’API ? Vous pouvez tester MiniMax Music directement dans le terrain de jeu Novita AI — aucun code requis. Remplissez un prompt de style et des paroles, choisissez un modèle et générez votre première chanson en quelques secondes.
Essayez MiniMax Music dans le terrain de jeu Novita AI
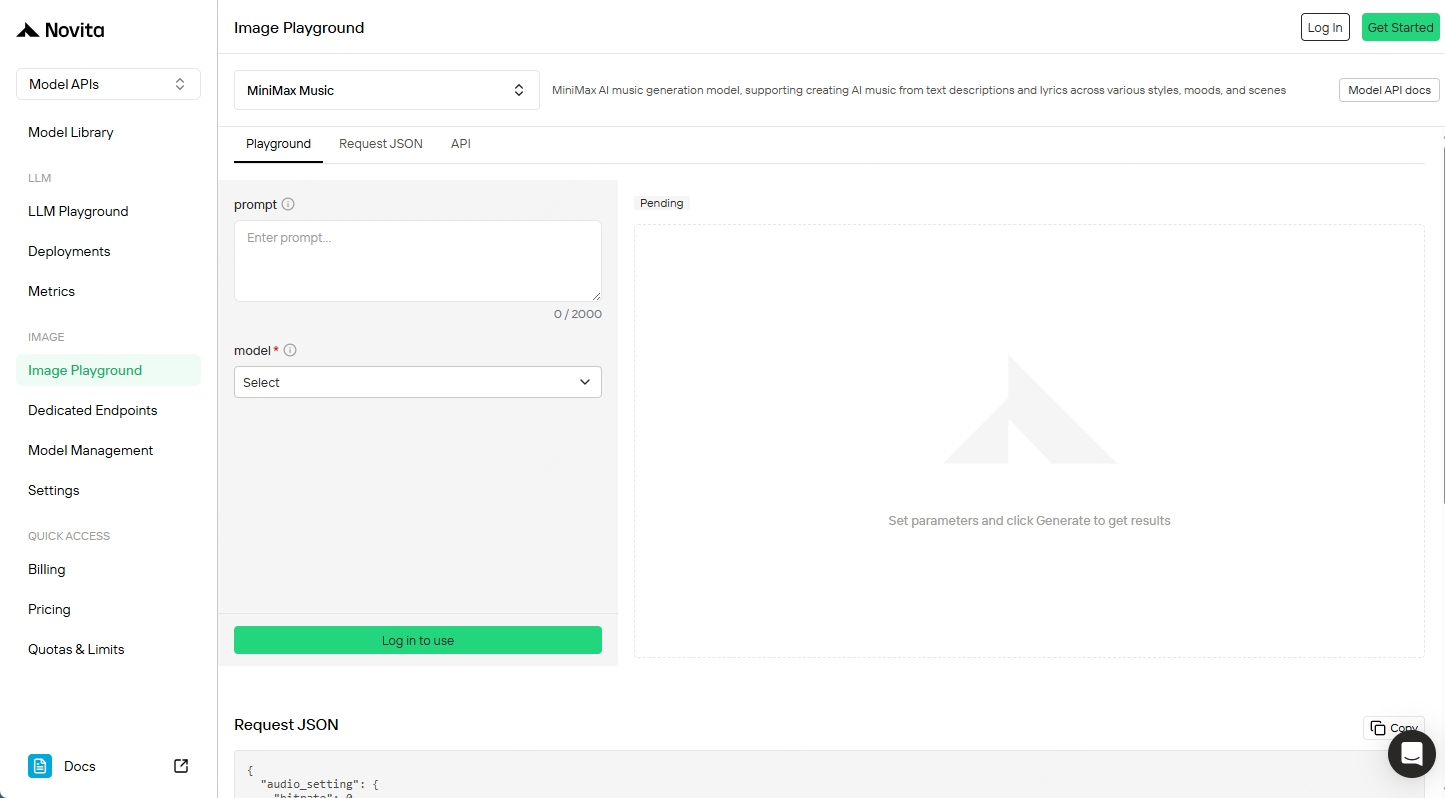
Terrain de jeu Novita
Comment commencer sur Novita AI
Prérequis : clé API
- Inscrivez-vous sur novita.ai
- Allez dans Paramètres → Clés API
- Cliquez sur Créer une nouvelle clé et copiez votre clé
Gardez votre clé privée — stockez-la en tant que variable d’environnement, ne l’encodez jamais en dur dans le code.
Générer des paroles
Python :
import requests
url = "https://api.novita.ai/v3/minimax-music-lyrics"
payload = {
"mode": "<string>",
"title": "<string>",
"lyrics": "<string>",
"prompt": "<string>"
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
cURL :
curl --request POST
--url https://api.novita.ai/v3/minimax-music-lyrics
--header 'Authorization: <authorization>'
--header 'Content-Type: <content-type>'
--data '
{
"mode": "<string>",
"title": "<string>",
"lyrics": "<string>",
"prompt": "<string>"
}
'
Générer une chanson
Python :
import requests
url = "https://api.novita.ai/v3/minimax-music"
payload = {
"model": "<string>",
"lyrics": "<string>",
"prompt": "<string>",
"audio_setting": {
"format": "<string>",
"bitrate": 123,
"sample_rate": 123
},
"output_format": "<string>",
"aigc_watermark": True,
"is_instrumental": True,
"lyrics_optimizer": True
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
cURL :
curl --request POST
--url https://api.novita.ai/v3/minimax-music
--header 'Authorization: <authorization>'
--header 'Content-Type: <content-type>'
--data '
{
"model": "<string>",
"lyrics": "<string>",
"prompt": "<string>",
"audio_setting": {
"format": "<string>",
"bitrate": 123,
"sample_rate": 123
},
"output_format": "<string>",
"aigc_watermark": true,
"is_instrumental": true,
"lyrics_optimizer": true
}
'
Conclusion
La série MiniMax Music est désormais disponible sur Novita AI — aucune configuration requise, ne payez que ce que vous utilisez. Que vous génériez des musiques de fond, que vous construisiez un outil de création musicale ou que vous automatisiez la production de contenu, la gamme Music 2.0 / 2.5 / 2.5+ et le générateur de paroles vous offrent une stack complète prête pour la production. Essayez le pipeline ci-dessus ou explorez-le dans le terrain de jeu Novita AI.
Novita AI est une plateforme cloud IA et d’agents qui aide les développeurs et les startups à créer, déployer et mettre à l’échelle des modèles et des applications agentiques avec des performances élevées, une fiabilité et une rentabilité optimales.
Questions fréquemment posées
Quelle est la différence entre Music 2.5 et Music 2.5+ ?
Music 2.5 offre un contrôle de précision au niveau du paragraphe et une fidélité audio de qualité studio — idéal pour la plupart des cas d’utilisation en production. Music 2.5+ ajoute une prise en charge instrumentale complète, permettant des arrangements multi-instruments riches accompagnés de voix, ou des pistes entièrement instrumentales lorsque le paramètre is_instrumental est défini sur true. Si la qualité de sortie est votre priorité absolue, choisissez 2.5+.
Puis-je générer de la musique entièrement instrumentale sans voix ?
Oui. Définissez is_instrumental: true dans votre requête à l’API Music. Cela fonctionne sur les trois modèles (Music 2.0, 2.5 et 2.5+), Music 2.5+ produisant les arrangements instrumentaux les plus riches.
Le générateur de paroles fonctionne-t-il avec tous les modèles Music ?
Oui. Le générateur de paroles (/v3/minimax-music-lyrics) est un endpoint autonome — sa sortie est indépendante du modèle. Le champ style_tags dans la réponse correspond directement au champ prompt dans toute requête de modèle Music, ce qui fait que les deux endpoints sont conçus pour fonctionner ensemble de manière transparente.



