

Points clés
Les avantages d’utiliser une API :
Éviter les erreurs réseau : Surmontez les indisponibilités causées par un trafic élevé (comme observé récemment avec l’application DeepSeek) en vous appuyant sur une infrastructure API scalable.
Éliminer les tracas du déploiement local : Contournez le besoin de GPU haut de gamme, d’installations complexes et de contraintes de mémoire.
Comment choisir un fournisseur d’API :
Sortie max : Privilégiez les fournisseurs supportant ≥8k tokens pour les tâches longues.
Efficacité des coûts : Comparez les coûts d’entrée et de sortie.
Latence : Critique pour les applications temps réel.
Débit : Assurez une haute concurrence.
Top 3 fournisseurs d’API de DeepSeek V3 :
Novita AI, Fireworks, Together AI
DeepSeek V3 est un puissant modèle de langage open-source connu pour ses performances et son efficacité. Cependant, sa taille massive de 671 milliards de paramètres le rend difficile à exécuter localement, nécessitant des ressources matérielles conséquentes. C’est là qu’interviennent les fournisseurs d’API, offrant un accès aux capacités de DeepSeek V3 sans infrastructure locale étendue. Cet article vous guidera à travers les avantages de l’utilisation d’une API, comment choisir le bon fournisseur, et quelques-unes des meilleures options disponibles.
Les avantages d’utiliser une API
Éviter les erreurs réseau dues à un trafic important
Récemment, l’application DeepSeek a rencontré des problèmes en raison d’un nombre excessif de requêtes, entraînant des indisponibilités et des performances peu fiables. Cela souligne l’importance de choisir un fournisseur d’API fiable pour garantir un accès constant aux capacités de DeepSeek V3.
Éviter les difficultés d’accès local
La taille massive de DeepSeek V3 constitue un obstacle majeur pour un accès local. Vous avez besoin de matériel puissant, y compris des GPU haut de gamme, pour exécuter le modèle. L’accès via API contourne ce problème, vous permettant d’utiliser le modèle sans vous soucier des exigences matérielles, des installations, des configurations ou des limites de mémoire.

Comment choisir un fournisseur d’API (4 métriques)
| Métrique | Définition | Impact élevé/faible | Notes |
|---|---|---|---|
| Sortie max | Nombre maximum de tokens que le modèle peut générer en une seule réponse. | Plus élevé = Meilleur | Exemple : DeepSeek V3 supporte 8k tokens. Vérifiez les limites du fournisseur. |
| Coût d’entrée | Coût par million de tokens d’entrée traités (ex. : invites utilisateur, contexte). | Plus bas = Meilleur | DeepSeek V3 : 0,07 $ – 0,27 $/million. Varie selon le fournisseur. |
| Coût de sortie | Coût par million de tokens de sortie générés (ex. : réponses du modèle). | Plus bas = Meilleur | DeepSeek V3 : 1,10 $/million. Comparez les fournisseurs pour les meilleurs tarifs. |
| Latence | Délai entre l’envoi d’une requête et la réception du premier octet de réponse. | Plus bas = Meilleur | Critique pour les chatbots, traductions en direct ou applications interactives. |
| Débit | Nombre de requêtes traitées par seconde (capacité du système). | Plus élevé = Meilleur | Un débit plus élevé permet de gérer des utilisateurs simultanés ou un traitement par lots. |
De plus, vous pouvez vous concentrer sur différentes métriques selon vos cas d’utilisation.
| Application | Exemples | Dimensions clés (ordre de priorité) |
|---|---|---|
| Applications temps réel | Chatbots, traduction en direct, support client | 1. Latence (<500ms) 2. Débit (100+ req/s) 3. Coût (secondaire sauf passage à l’échelle) |
| Génération de contenu long | Rédaction d’articles, génération de code, rapports | 1. Sortie max (≥8k tokens) 2. Coût de sortie (1,10 $/million tokens) 3. Latence (tolère 2–3s) |
| Traitement par lots sensible aux coûts | Annotation de données, résumé en masse | 1. Coût d’entrée (0,07 $/million tokens) 2. Débit (1k+ req/h) 3. Sortie max (faible priorité) |
| Raisonnement multimodal/complexe | Diagnostic médical, prévisions financières | 1. Capacité du modèle (précision) 2. Sortie max (raisonnement détaillé) 3. Latence (tolère 10s+) |
| Déploiement sur périphérique/Edge | Applications mobiles, objets connectés | 1. Latence (<200ms) 2. Débit (modèles légers) 3. Coût (moins pertinent) |
Vous pouvez obtenir des données spécifiques sur openrouter.
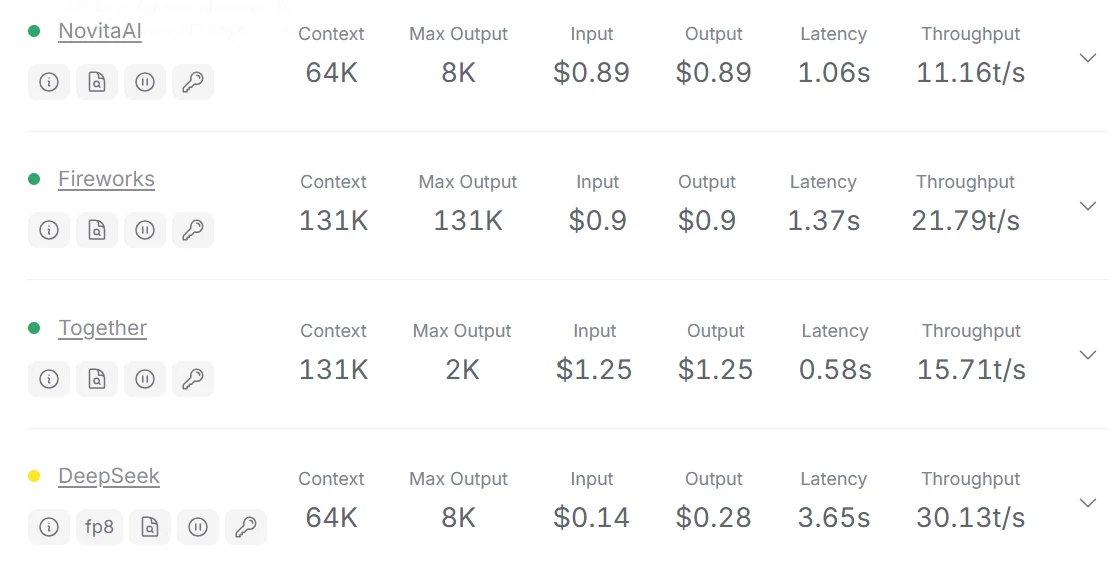
Top 3 fournisseurs d’API de DeepSeek V3
1.Novita AI
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant un GPU cloud abordable et fiable pour construire et passer à l’échelle.

Pourquoi choisir Novita AI ?
- Efficacité de développement : Modèles multimodaux pré-intégrés (comme deepseek v3, deepseek r1, llama 3.3 70b……)
- Avantage de coût : Technologie d’optimisation propriétaire réduisant les coûts d’inférence de 30 % à 50 % par rapport aux grands fournisseurs.
- Mise à l’échelle élastique : Paiement à l’utilisation + auto-scaling, adapté aux startups comme aux besoins des entreprises.
Quels défis résout-elle ?
- Barrières de développement élevées → API prêtes à l’emploi + modèles pré-entraînés + chaîne d’outils, pas besoin d’équipe IA.
- Coûts d’inférence imprévisibles → Ordonnancement dynamique des ressources + quantification, garantissant la transparence des coûts.
- Gestion inefficace des modèles → Console unifiée pour la gestion complète du cycle de vie des modèles.
Quelles fonctionnalités propose-t-elle ?
- Hébergement de modèles
- Modèles open-source
- Playground : Testez les modèles en ligne, générez du code API instantanément.
- Outils développeur
- Gestion d’API : Journaux en temps réel, surveillance d’utilisation.
- Contrôle des coûts : Tarification basée sur les tokens + alertes de budget.
- Services entreprise
- Déploiement privé : Clusters sur site, conformité des données.
- Optimisation personnalisée : Modèles sur mesure + accélération matérielle pour les clients clés.
Comment accéder à Deepseek V3 via Novita AI ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Essayez DeepSeek V3 Demo maintenant !
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.

Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page “Settings”, copiez la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "deepseek/deepseek_v3"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Lors de l’inscription, Novita AI offre un crédit de 0,50 $ pour vous lancer !
Si le crédit gratuit est épuisé, vous pouvez payer pour continuer à l’utiliser.
2.Fireworks
Fireworks AI est un fournisseur leader de solutions d’IA générative, permettant aux développeurs d’intégrer efficacement des capacités d’IA dans leurs applications.
Pourquoi choisir Fireworks ?
- Faible latence et hautes performances : Fireworks offre une latence jusqu’à 4 fois inférieure et des performances 20 fois supérieures par rapport à d’autres solutions, en utilisant des GPU NVIDIA sur AWS.
- Efficacité des coûts : Réduit les coûts en optimisant l’inférence des modèles et les processus de fine-tuning.
- Flexibilité des modèles : Supporte plus de 100 modèles de pointe dans plusieurs modalités, permettant une personnalisation facile via le fine-tuning.
Quels défis résout-il ?
- Complexité du déploiement de modèles : Simplifie le déploiement des modèles d’IA en fournissant une API unifiée et en gérant les mises à jour et optimisations.
- Problèmes de scalabilité : Offre des options d’infrastructure scalables, y compris des déploiements serverless et à la demande, pour gérer l’augmentation du trafic sans compromettre les performances.
- Coût et latence : Résout les défis de coût et de latence en optimisant les performances des modèles et en proposant des solutions rentables.
Quelles fonctionnalités propose-t-il ?
- Accès API : Fournit une API REST pour une intégration facile des modèles d’IA dans les applications, prenant en charge plusieurs modalités comme le texte, l’image et l’audio.
- Fine-tuning de modèles : Permet un fine-tuning rapide des modèles à l’aide de techniques ultra-rapides LoRA, permettant aux développeurs de personnaliser les modèles selon leurs besoins spécifiques.
- Optimisation de l’inférence : Optimise les processus d’inférence à l’aide de technologies propriétaires comme FireAttention, garantissant des performances de haute qualité et à faible latence.
Comment accéder à Deepseek V3 via Fireworks ?
Générez une réponse de modèle en utilisant le point de terminaison de chat de deepseek-v3.
import requests
import json
url = "https://api.fireworks.ai/inference/v1/chat/completions"
payload = {
"model": "accounts/fireworks/models/deepseek-v3",
"max_tokens": 16384,
"top_p": 1,
"top_k": 40,
"presence_penalty": 0,
"frequency_penalty": 0,
"temperature": 0.6,
"messages": [
{
"role": "user",
"content": "Bonjour, comment allez-vous ?"
}
]
}
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": "Bearer <API_KEY>"
}
requests.request("POST", url, headers=headers, data=json.dumps(payload))
3.Together AI
Together AI est un fournisseur leader de solutions d’IA, permettant aux développeurs de construire, fine-tuner et déployer efficacement des modèles d’IA générative.

Pourquoi choisir Together AI ?
- Inférence plus rapide : La plateforme Together AI accélère les charges de travail d’inférence IA, améliorant souvent les performances de deux à trois fois tout en réduisant l’utilisation matérielle de 50 %.
- Efficacité des coûts : Propose des coûts inférieurs par rapport aux services cloud traditionnels, rendant l’IA plus accessible.
- Flexibilité : Supporte les déploiements serverless et dédiés, permettant une scalabilité flexible.
Quels défis résout-il ?
- Complexité technique : Simplifie le déploiement et la gestion des modèles d’IA en fournissant une plateforme unifiée pour l’entraînement et l’inférence.
- Confidentialité et sécurité des données : Assure la conformité avec des normes comme SOC 2 et HIPAA, répondant aux préoccupations de confidentialité.
- Conformité réglementaire : Se tient à jour avec l’évolution des paysages réglementaires pour garantir la conformité.
Quelles fonctionnalités propose-t-il ?
- Accès API : Fournit des API faciles à utiliser pour intégrer des capacités d’IA dans les applications, supportant les déploiements serverless et dédiés.
- Fine-tuning de modèles : Propose des options de fine-tuning complet et LoRA pour personnaliser les modèles pour des tâches spécifiques.
- Clusters GPU : Supporte l’entraînement de modèles à grande échelle avec des GPU hautes performances comme GB200, H200 et H100.
Comment accéder à Deepseek V3 via Together AI ?
Générez une réponse de modèle en utilisant le point de terminaison de chat de deepseek-v3.
from together import Together
client = Together()
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3",
messages=[{"role": "user", "content": "Quelles sont les choses amusantes à faire à New York ?"}],
)
print(response.choices[0].message.content)
En conclusion, choisir le bon fournisseur d’API pour DeepSeek V3 est crucial pour un développement IA efficace et rentable. En comprenant les avantages de l’utilisation d’une API et en considérant attentivement des facteurs tels que la longueur de sortie, le coût, la latence et le débit, vous pouvez sélectionner un fournisseur qui correspond le mieux à vos besoins. Que vous choisissiez Novita AI, Fireworks, Together AI ou l’API officielle de DeepSeek, vous pourrez tirer parti des capacités de DeepSeek V3 sans nécessiter de ressources locales étendues.
Foire aux questions
Puis-je utiliser DeepSeek V3 gratuitement ?
DeepSeek propose une plateforme de chat gratuite, mais avec une limite quotidienne de 50 messages en mode “Deep Think”. Vous pouvez également utiliser les modèles DeepSeek V3 sur HuggingFace et d’autres plateformes ouvertes gratuitement.
DeepSeek V3 est-il meilleur que GPT-4 ?
DeepSeek-V3 a démontré des performances rivalisant avec GPT-4 et surpassant plusieurs LLM open-source. Les modèles DeepSeek sont reconnus pour leur rapport coût-efficacité.
Pour quels types de tâches DeepSeek V3 est-il bon ?
DeepSeek V3 excelle dans une large gamme de tâches, notamment les mathématiques, le codage, le raisonnement logique et la gestion de plusieurs langues.
Novita AI est la plateforme cloud tout-en-un qui dynamise vos ambitions IA. APIs intégrées, serverless, instance GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et concrétisez votre vision IA.



