

Wichtige Highlights
Die Vorteile der Nutzung einer API:
Netzwerkfehler vermeiden: Überwinden Sie Ausfälle durch hohen Datenverkehr (wie bei den jüngsten App-Problemen von DeepSeek) durch eine skalierbare API-Infrastruktur.
Lokale Bereitstellung vermeiden: Umgehen Sie die Notwendigkeit leistungsstarker GPUs, komplexer Installationen und Speicherbeschränkungen.
Wie wählt man einen API-Anbieter aus?:
Maximale Ausgabe: Bevorzugen Sie Anbieter, die ≥8k Tokens für umfangreiche Aufgaben unterstützen.
Kosteneffizienz: Vergleichen Sie die Kosten für Eingabe und Ausgabe.
Latenz: Entscheidend für Echtzeitanwendungen.
Durchsatz: Stellen Sie eine hohe Parallelverarbeitung sicher.
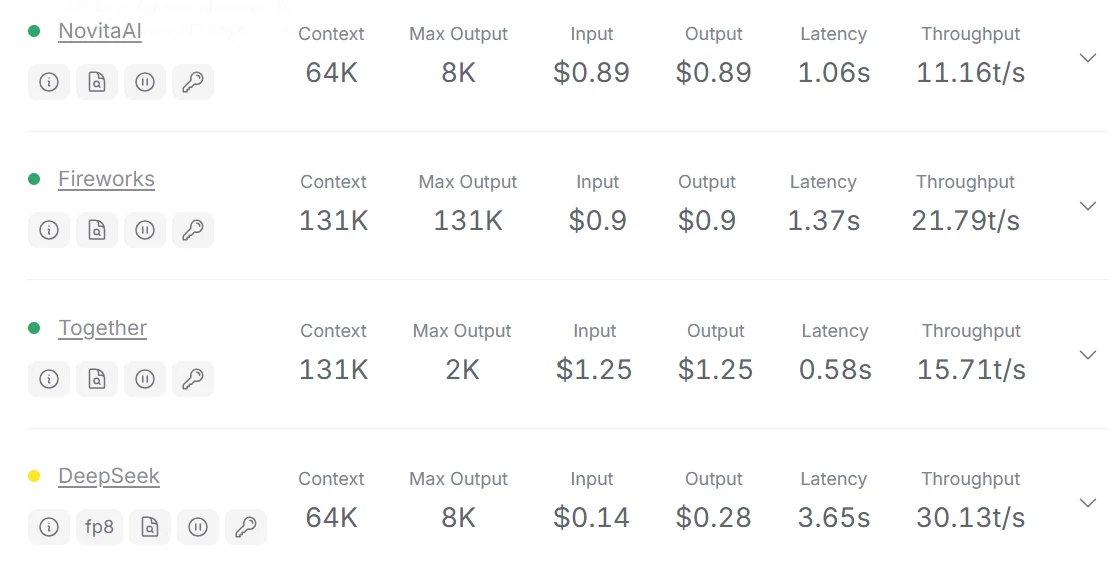
Die 3 besten API-Anbieter von DeepSeek V3:
Novita AI, Fireworks, Together AI
DeepSeek V3 ist ein leistungsstarkes Open-Source-Sprachmodell, das für seine hohe Leistung und Effizienz bekannt ist. Seine Größe von 671 Milliarden Parametern macht es jedoch schwierig, es lokal auszuführen, da es erhebliche Hardwareressourcen erfordert. Hier kommen API-Anbieter ins Spiel, die Zugriff auf die Fähigkeiten von DeepSeek V3 bieten, ohne dass eine umfangreiche lokale Infrastruktur erforderlich ist. Dieser Artikel führt Sie durch die Vorteile der Nutzung einer API, die Auswahl des richtigen Anbieters und einige der besten verfügbaren Optionen.
Die Vorteile der Nutzung einer API
Netzwerkfehler aufgrund von hohem Datenverkehr vermeiden
In letzter Zeit hatte die DeepSeek-App aufgrund einer überwältigenden Anzahl von Anfragen mit Problemen zu kämpfen, was zu Ausfallzeiten und unzuverlässiger Leistung führte. Dies unterstreicht die Bedeutung der Wahl eines zuverlässigen API-Anbieters, um einen konsistenten Zugriff auf die Fähigkeiten von DeepSeek V3 zu gewährleisten.
Ärger mit lokalem Zugriff vermeiden
Die enorme Größe von DeepSeek V3 stellt ein erhebliches Hindernis für den lokalen Zugriff dar. Sie benötigen leistungsstarke Hardware, einschließlich High-End-GPUs, um das Modell auszuführen. Der API-Zugriff umgeht dieses Problem und ermöglicht die Nutzung des Modells, ohne sich um Hardwareanforderungen, Installationen, Konfigurationen oder Speicherbegrenzungen kümmern zu müssen.

Wie wählt man einen API-Anbieter aus? (4 Metriken)
| Metrik | Definition | Auswirkung (hoch/niedrig) | Anmerkungen |
|---|---|---|---|
| Maximale Ausgabe | Maximale Token, die das Modell in einer einzigen Antwort generieren kann. | Höher = Besser | Beispiel: DeepSeek V3 unterstützt 8k Token. Prüfen Sie die Grenzen des Anbieters. |
| Eingabekosten | Kosten pro Million verarbeiteter Eingabe-Token (z. B. Benutzeraufforderungen, Kontext). | Niedriger = Besser | DeepSeek V3: 0,07 – 0,27 $/Mio. Variiert je nach Anbieter. |
| Ausgabekosten | Kosten pro Million generierter Ausgabe-Token (z. B. Modellantworten). | Niedriger = Besser | DeepSeek V3: 1,10 $/Mio. Vergleichen Sie die Anbieter für die besten Tarife. |
| Latenz | Zeitverzögerung zwischen dem Senden einer Anfrage und dem Erhalt des ersten Antwortbytes. | Niedriger = Besser | Entscheidend für Chatbots, Live-Übersetzungen oder interaktive Anwendungen. |
| Durchsatz | Anzahl der verarbeiteten Anfragen pro Sekunde (Systemkapazität). | Höher = Besser | Höherer Durchsatz ermöglicht die Bearbeitung gleichzeitiger Benutzer oder Stapelverarbeitung. |
Außerdem können Sie sich je nach Ihren Anwendungsfällen auf verschiedene Metriken konzentrieren.
| Anwendung | Beispiele | Schlüsseldimensionen (Prioritätsreihenfolge) |
|---|---|---|
| Echtzeitanwendungen | Chatbots, Live-Übersetzung, Kundensupport | 1. Latenz (<500ms) 2. Durchsatz (100+ Anfragen/s) 3. Kosten (nachrangig, außer bei Skalierung) |
| Generierung langer Inhalte | Artikel schreiben, Code generieren, Berichte | 1. Maximale Ausgabe (≥8k Token) 2. Ausgabekosten (1,10 $/Mio. Token) 3. Latenz (2–3s tolerierbar) |
| Kostensensitive Stapelverarbeitung | Datenkennzeichnung, Massenzusammenfassung | 1. Eingabekosten (0,07 $/Mio. Token) 2. Durchsatz (1k+ Anfragen/Stunde) 3. Maximale Ausgabe (niedrige Priorität) |
| Multimodales/komplexes Denken | Medizinische Diagnose, Finanzprognosen | 1. Modellfähigkeit (Genauigkeit) 2. Maximale Ausgabe (detaillierte Begründung) 3. Latenz (10s+ tolerierbar) |
| Edge-/On-Device-Bereitstellung | Mobile Apps, IoT-Geräte | 1. Latenz (<200ms) 2. Durchsatz (leichte Modelle) 3. Kosten (weniger relevant) |
Sie können spezifische Daten von openrouter erhalten.
Die 3 besten API-Anbieter von DeepSeek V3
1. Novita AI
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.

Warum sollte man sich dafür entscheiden?
- Entwicklungseffizienz: Vorintegrierte multimodale Modelle (wie DeepSeek V3, DeepSeek R1, Llama 3.3 70b…)
- Kostenvorteil: Proprietäre Optimierungstechnologie senkt die Inferenzkosten um 30-50 % im Vergleich zu großen Anbietern.
- Elastische Skalierung: Pay-as-you-go + Auto-Scaling, geeignet für Startups bis hin zu Unternehmensanforderungen.
Welche Herausforderungen werden damit gelöst?
- Hohe Einstiegsbarrieren → Fertige APIs + vortrainierte Modelle + Toolchain, kein KI-Team erforderlich.
- Unvorhersehbare Inferenzkosten → Dynamische Ressourcenplanung + Quantisierung, gewährleistet Kostentransparenz.
- Ineffizientes Modellmanagement → Einheitliche Konsole für das gesamte Modelllebenszyklusmanagement.
Welche Funktionen bietet es?
-
Modell-Hosting
- Open-Source-Modelle
- Playground: Modelle online testen, API-Code sofort generieren.
-
Entwickler-Tools
- API-Verwaltung: Echtzeit-Logs, Nutzungsüberwachung.
- Kostenkontrolle: Token-basierte Preisgestaltung + Budgetwarnungen.
-
Unternehmensdienste
- Privates Deployment: On-Premises-Cluster, Datencompliance.
- Kundenoptimierung: Maßgeschneiderte Modelle + Hardwarebeschleunigung für KA-Kunden.
Wie greift man über Novita AI auf DeepSeek V3 zu?
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Loggen Sie sich in Ihr Konto ein und klicken Sie auf die Schaltfläche Model Library.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

DeepSeek V3 Demo jetzt testen!
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.

Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API erhalten Sie einen neuen API-Schlüssel. Rufen Sie die Seite Settings auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem Paketmanager Ihrer Programmiersprache.

Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Nach der Registrierung erhalten Sie von Novita AI ein Guthaben von 0,50 $, um loszulegen!
Wenn das kostenlose Guthaben aufgebraucht ist, können Sie bezahlen, um die Nutzung fortzusetzen.
2. Fireworks
Fireworks AI ist ein führender Anbieter von generativen KI-Lösungen, der Entwicklern ermöglicht, KI-Funktionen effizient in ihre Anwendungen zu integrieren.
Warum sollte man sich dafür entscheiden?
- Niedrige Latenz und hohe Leistung: Fireworks bietet bis zu 4-mal niedrigere Latenz und 20-mal höhere Leistung im Vergleich zu anderen Lösungen, unter Verwendung von NVIDIA GPUs auf AWS.
- Kosteneffizienz: Senkt die Kosten durch Optimierung der Modellinferenz und der Feinabstimmungsprozesse.
- Modellflexibilität: Unterstützt über 100 hochmoderne Modelle über mehrere Modalitäten hinweg und ermöglicht eine einfache Anpassung durch Feinabstimmung.
Welche Herausforderungen werden damit gelöst?
- Komplexität der Modellbereitstellung: Vereinfacht die Bereitstellung von KI-Modellen durch eine einheitliche API und übernimmt Modellaktualisierungen und -optimierungen.
- Skalierbarkeitsprobleme: Bietet skalierbare Infrastrukturoptionen, einschließlich serverloser und On-Demand-Bereitstellungen, um erhöhten Datenverkehr ohne Leistungseinbußen zu bewältigen.
- Kosten und Latenz: Bewältigt Kosten- und Latenzherausforderungen durch Optimierung der Modellleistung und Bereitstellung kosteneffizienter Lösungen.
Welche Funktionen bietet es?
- API-Zugriff: Stellt eine REST-API für die einfache Integration von KI-Modellen in Anwendungen bereit, die mehrere Modalitäten wie Text, Bild und Audio unterstützt.
- Modell-Feinabstimmung: Ermöglicht die schnelle Feinabstimmung von Modellen mit ultraraschen LoRA-Techniken, sodass Entwickler Modelle an ihre spezifischen Anforderungen anpassen können.
- Inferenzoptimierung: Optimiert Inferenzprozesse mit proprietären Technologien wie FireAttention und gewährleistet so eine hohe Qualität und geringe Latenz.
Wie greift man über Fireworks auf DeepSeek V3 zu?
Generieren Sie eine Modellantwort mit dem Chat-Endpunkt von deepseek-v3.
import requests
import json
url = "https://api.fireworks.ai/inference/v1/chat/completions"
payload = {
"model": "accounts/fireworks/models/deepseek-v3",
"max_tokens": 16384,
"top_p": 1,
"top_k": 40,
"presence_penalty": 0,
"frequency_penalty": 0,
"temperature": 0.6,
"messages": [
{
"role": "user",
"content": "Hello, how are you?"
}
]
}
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": "Bearer <API_KEY>"
}
requests.request("POST", url, headers=headers, data=json.dumps(payload))
3. Together AI
Together AI ist ein führender Anbieter von KI-Lösungen, der Entwicklern hilft, generative KI-Modelle effizient zu erstellen, feinabzustimmen und bereitzustellen.

Warum sollte man sich dafür entscheiden?
- Schnellere Inferenz: Die Plattform von Together AI beschleunigt KI-Inferenz-Workloads, oft mit einer zwei- bis dreifachen Leistungssteigerung bei gleichzeitiger Reduzierung des Hardwareeinsatzes um 50 %.
- Kosteneffizienz: Bietet niedrigere Kosten im Vergleich zu traditionellen Cloud-Diensten und macht KI zugänglicher.
- Flexibilität: Unterstützt sowohl serverlose als auch dedizierte Bereitstellungen und ermöglicht eine flexible Skalierung.
Welche Herausforderungen werden damit gelöst?
- Technische Komplexität: Vereinfacht die Bereitstellung und Verwaltung von KI-Modellen durch eine einheitliche Plattform für Modelltraining und Inferenz.
- Datenschutz und Sicherheit: Stellt die Einhaltung von Standards wie SOC 2 und HIPAA sicher und adressiert Datenschutzbedenken.
- Einhaltung gesetzlicher Vorschriften: Bleibt auf dem neuesten Stand der sich ändernden regulatorischen Landschaft, um die Einhaltung sicherzustellen.
Welche Funktionen bietet es?
- API-Zugriff: Bietet einfach zu verwendende APIs für die Integration von KI-Funktionen in Anwendungen, die sowohl serverlose als auch dedizierte Bereitstellungen unterstützen.
- Modell-Feinabstimmung: Bietet vollständige und LoRA-Feinabstimmungsoptionen zur Anpassung von Modellen an spezifische Aufgaben.
- GPU-Cluster: Unterstützt groß angelegtes Modelltraining mit leistungsstarken GPUs wie GB200, H200 und H100.
Wie greift man über Together AI auf DeepSeek V3 zu?
Generieren Sie eine Modellantwort mit dem Chat-Endpunkt von deepseek-v3.
from together import Together
client = Together()
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3",
messages=[{"role": "user", "content": "What are some fun things to do in New York?"}],
)
print(response.choices[0].message.content)
Zusammenfassend ist die Wahl des richtigen API-Anbieters für DeepSeek V3 entscheidend für eine effiziente und kosteneffektive KI-Entwicklung. Wenn Sie die Vorteile der Nutzung einer API verstehen und Faktoren wie Ausgabelänge, Kosten, Latenz und Durchsatz sorgfältig abwägen, können Sie einen Anbieter auswählen, der am besten zu Ihren Anforderungen passt. Egal, ob Sie sich für Novita AI, Fireworks, Together AI oder die offizielle DeepSeek-API entscheiden, Sie werden in der Lage sein, die Fähigkeiten von DeepSeek V3 ohne umfangreiche lokale Ressourcen zu nutzen.
Häufig gestellte Fragen
Kann ich DeepSeek V3 kostenlos nutzen?
DeepSeek bietet eine Chat-Plattform, die kostenlos nutzbar ist, aber im Modell Deep Think ein tägliches Limit von 50 Nachrichten hat. Sie können die DeepSeek V3-Modelle auch auf HuggingFace und einigen anderen offenen Plattformen kostenlos nutzen.
Ist DeepSeek V3 besser als GPT-4?
DeepSeek-V3 hat eine Leistung gezeigt, die mit GPT-4 vergleichbar ist und mehrere Open-Source-LLMs übertrifft. DeepSeek-Modelle sind für ihre Kosteneffizienz bekannt.
Für welche Aufgaben ist DeepSeek V3 geeignet?
DeepSeek V3 zeichnet sich in einer Vielzahl von Aufgaben aus, darunter Mathematik, Programmierung, logisches Denken und die Verarbeitung mehrerer Sprachen.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, serverlos, GPU-Instanz – die kosteneffizienten Werkzeuge, die Sie brauchen. Verzichten Sie auf Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



