

主なハイライト
APIを使用する利点: ネットワークエラーの回避: トラフィック過多によるダウンタイム(DeepSeekアプリで最近見られた問題)を、スケーラブルなAPIインフラストラクチャに依存することで克服します。 ローカルデプロイの手間を排除: ハイエンドGPU、複雑なインストール、メモリ制約の必要性を回避します。
APIプロバイダーの選び方: 最大出力: 長文タスクには8kトークン以上をサポートするプロバイダーを優先。 コスト効率: 入力コストと出力コストを比較。 レイテンシ: リアルタイムアプリケーションでは重要。 スループット: 高い同時実行性を確保。
DeepSeek V3のAPIプロバイダートップ3: Novita AI、Fireworks、Together AI
DeepSeek V3は、強力なパフォーマンスと効率性で知られるオープンソースの言語モデルです。しかし、6710億パラメータという巨大なサイズのため、ローカルで実行するには大規模なハードウェアリソースが必要となります。そこで役立つのがAPIプロバイダーです。大規模なローカルインフラを必要とせずにDeepSeek V3の機能にアクセスできます。この記事では、APIを使用する利点、適切なプロバイダーの選び方、そして利用可能な主要なオプションについて解説します。
APIを使用する利点
大量トラフィックによるネットワークエラーの回避
最近、DeepSeekアプリはリクエストの急増によりダウンタイムや不安定なパフォーマンスに見舞われています。これは、DeepSeek V3の機能に一貫してアクセスできるよう、信頼性の高いAPIプロバイダーを選択することの重要性を示しています。
ローカルアクセスの手間を回避
DeepSeek V3の巨大なサイズは、ローカルアクセスにおいて大きな障壁となります。モデルを実行するには、ハイエンドGPUを含む強力なハードウェアが必要です。APIアクセスはこの問題を回避し、ハードウェア要件、インストール、設定、メモリ制限を気にすることなくモデルを使用できるようにします。

APIプロバイダーの選び方(4つの指標)
| 指標 | 定義 | 高低の影響 | 備考 |
|---|---|---|---|
| 最大出力 | モデルが1回の応答で生成できる最大トークン数 | 高いほど良い | 例:DeepSeek V3は8kトークンをサポート。プロバイダーの制限を確認。 |
| 入力コスト | 処理される入力トークン100万あたりのコスト(例:ユーザープロンプト、コンテキスト) | 低いほど良い | DeepSeek V3:$0.07~$0.27/100万。プロバイダーにより異なる。 |
| 出力コスト | 生成される出力トークン100万あたりのコスト(例:モデル応答) | 低いほど良い | DeepSeek V3:$1.10/100万。最適な料金を比較。 |
| レイテンシ | リクエスト送信から最初の応答バイト受信までの時間遅延 | 低いほど良い | チャットボット、ライブ翻訳、インタラクティブアプリに重要。 |
| スループット | 1秒あたりに処理されるリクエスト数(システム容量) | 高いほど良い | 高いスループットにより、同時ユーザーやバルク処理の処理が可能。 |
また、ユースケースに応じて異なる指標に焦点を当てることもできます。
| **アプリケーション ** | ** 例 ** | ** 主要な次元(優先順位)** |
|---|---|---|
| リアルタイムアプリケーション | チャットボット、ライブ翻訳、カスタマーサポート | 1. レイテンシ(<500ms) 2. スループット(100+ req/sec) 3. コスト(スケールしない限り二次的) |
| 長文コンテンツ生成 | 記事作成、コード生成、レポート | 1. 最大出力(≥8kトークン) 2. 出力コスト($1.10/100万トークン) 3. レイテンシ(2~3秒許容) |
| コスト重視のバッチ処理 | データラベリング、一括要約 | 1. 入力コスト($0.07/100万トークン) 2. スループット(1k+ req/hour) 3. 最大出力(優先度低) |
| マルチモーダル/複雑な推論 | 医療診断、財務予測 | 1. モデル性能(精度) 2. 最大出力(詳細な推論) 3. レイテンシ(10秒以上許容) |
| エッジ/オンデバイス展開 | モバイルアプリ、IoTデバイス | 1. レイテンシ(<200ms) 2. スループット(軽量モデル) 3. コスト(あまり重要でない) |
具体的なデータはopenrouterから取得できます。
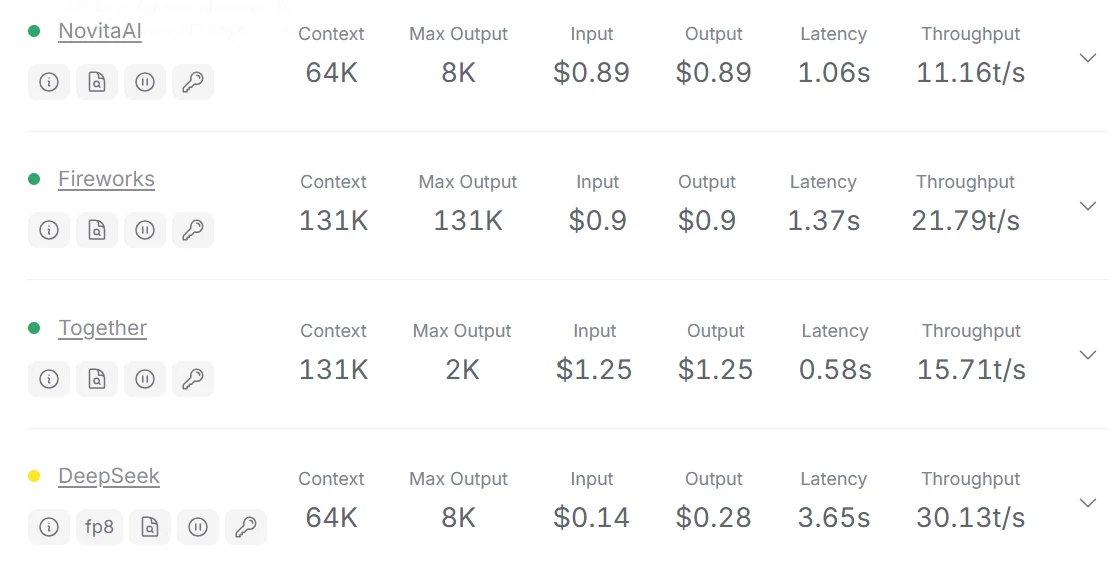
DeepSeek V3のAPIプロバイダートップ3
1.Novita AI
Novita AIは、シンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームです。また、アプリケーションの構築とスケーリングに手頃で信頼性の高いGPUクラウドも提供しています。

選ばれる理由
- 開発効率: マルチモーダルモデル(DeepSeek V3、DeepSeek R1、Llama 3.3 70bなど)が事前統合。
- コスト優位性: 独自の最適化技術により、主要プロバイダーと比較して推論コストを30%~50%削減。
- 弾力的なスケーリング: 従量課金制+自動スケーリングで、スタートアップからエンタープライズレベルまで対応。
解決する課題
- 高い開発障壁 → すぐに使えるAPI+事前訓練モデル+ツールチェーン。AIチームは不要。
- 予測不能な推論コスト → 動的リソーススケジューリング+量子化により、コストの透明性を確保。
- 非効率なモデル管理 → 統一コンソールでモデルライフサイクル全体を管理。
提供機能
-
モデルホスティング
- オープンソースモデル
- プレイグラウンド:モデルをオンラインでテスト、APIコードを即時生成。
-
開発者ツール
- API管理:リアルタイムログ、使用状況監視。
- コスト管理:トークンベースの価格設定+予算アラート。
-
エンタープライズサービス
- プライベートデプロイ:オンプレミスクラスター、データコンプライアンス。
- カスタム最適化:主要顧客向けに調整されたモデル+ハードウェアアクセラレーション。
Novita AI経由でDeepSeek V3にアクセスする方法
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。

ステップ3:無料トライアルを開始
選択したモデルの機能を探索するために、無料トライアルを開始します。

ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに移動し、画像のようにAPIキーをコピーします。

ステップ5:APIをインストール
プログラミング言語に応じたパッケージマネージャーを使用してAPIをインストールします。

インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。以下は、Pythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
登録時、Novita AIは$0.5のクレジットを提供してスタートをサポートします!
無料クレジットを使い切った場合は、支払いをして継続利用できます。
2.Fireworks
Fireworks AIは、生成AIソリューションの主要プロバイダーであり、開発者がAI機能をアプリケーションに効率的に統合できるようにします。
選ばれる理由
- 低レイテンシと高性能: Fireworksは、他のソリューションと比較して最大4倍のレイテンシ削減と20倍のパフォーマンス向上を実現し、AWS上のNVIDIA GPUを活用しています。
- コスト効率: モデル推論とファインチューニングプロセスを最適化することでコストを削減。
- モデルの柔軟性: 複数のモダリティにわたる100以上の最先端モデルをサポートし、ファインチューニングによる容易なカスタマイズを可能にします。
解決する課題
- モデルデプロイの複雑さ: 統一APIを提供し、モデルの更新や最適化を処理することで、AIモデルのデプロイを簡素化。
- スケーラビリティの問題: パフォーマンスを損なうことなくトラフィック増加に対処するため、サーバーレスおよびオンデマンドデプロイなどのスケーラブルなインフラストラクチャオプションを提供。
- コストとレイテンシ: モデルパフォーマンスを最適化し、コスト効率の高いソリューションを提供することで、コストとレイテンシの課題に対応。
提供機能
- APIアクセス: アプリケーションへのAIモデルの簡単な統合のためのREST APIを提供。テキスト、画像、音声などの複数のモダリティをサポート。
- モデルファインチューニング: 超高速LoRA技術を使用した迅速なファインチューニングを可能にし、開発者が特定のニーズに合わせてモデルをカスタマイズ。
- 推論最適化: FireAttentionなどの独自技術を使用して推論プロセスを最適化し、高品質で低レイテンシのパフォーマンスを実現。
Fireworks経由でDeepSeek V3にアクセスする方法
deepseek-v3 のチャットエンドポイントを使用してモデル応答を生成します。
import requests
import json
url = "https://api.fireworks.ai/inference/v1/chat/completions"
payload = {
"model": "accounts/fireworks/models/deepseek-v3",
"max_tokens": 16384,
"top_p": 1,
"top_k": 40,
"presence_penalty": 0,
"frequency_penalty": 0,
"temperature": 0.6,
"messages": [
{
"role": "user",
"content": "Hello, how are you?"
}
]
}
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": "Bearer <API_KEY>"
}
requests.request("POST", url, headers=headers, data=json.dumps(payload))
3.Together AI
Together AIは、AIソリューションの主要プロバイダーであり、開発者が生成AIモデルを効率的に構築、ファインチューニング、デプロイすることを可能にします。

選ばれる理由
- より高速な推論: Together AIのプラットフォームはAI推論ワークロードを加速し、パフォーマンスを2~3倍向上させながらハードウェア使用量を50%削減することがよくあります。
- コスト効率: 従来のクラウドサービスと比較して低コストを提供し、AIへのアクセスをより容易にします。
- 柔軟性: サーバーレスおよび専用デプロイの両方をサポートし、柔軟なスケーラビリティを実現。
解決する課題
- 技術的な複雑さ: モデルトレーニングと推論のための統一プラットフォームを提供することで、AIモデルのデプロイと管理を簡素化。
- データプライバシーとセキュリティ: SOC 2やHIPAAなどの基準への準拠を確保し、データプライバシーの懸念に対応。
- 規制コンプライアンス: 変化する規制環境に常に対応し、コンプライアンスを維持。
提供機能
- APIアクセス: アプリケーションへのAI機能の統合を容易にする使いやすいAPIを提供。サーバーレスおよび専用デプロイの両方をサポート。
- モデルファインチューニング: 特定のタスクにモデルをカスタマイズするためのフルファインチューニングとLoRAファインチューニングオプションを提供。
- GPUクラスター: GB200、H200、H100などの高性能GPUを使用した大規模モデルトレーニングをサポート。
Together AI経由でDeepSeek V3にアクセスする方法
deepseek-v3 のチャットエンドポイントを使用してモデル応答を生成します。
from together import Together
client = Together()
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3",
messages=[{"role": "user", "content": "What are some fun things to do in New York?"}],
)
print(response.choices[0].message.content)
結論として、DeepSeek V3に適したAPIプロバイダーを選択することは、効率的でコスト効果の高いAI開発にとって重要です。APIを使用する利点を理解し、出力長、コスト、レイテンシ、スループットなどの要素を慎重に考慮することで、ニーズに最適なプロバイダーを選択できます。Novita AI、Fireworks、Together AI、またはDeepSeekの公式APIのいずれを選んでも、大規模なローカルリソースを必要とせずにDeepSeek V3の機能を活用できます。
よくある質問
DeepSeek V3は無料で使用できますか?
DeepSeekは無料で使用できるチャットプラットフォームを提供していますが、“Deep Think” モデルでは1日50メッセージの制限があります。また、HuggingFaceやその他のオープンプラットフォームでDeepSeek V3モデルを無料で使用することもできます。
DeepSeek V3はGPT-4より優れていますか?
DeepSeek V3はGPT-4に匹敵するパフォーマンスを示し、複数のオープンソースLLMを上回っています。DeepSeekモデルはコスト効率の良さで知られています。
DeepSeek V3はどんなタスクに適していますか?
DeepSeek V3は、数学、コーディング、論理的推論、複数言語の処理など、幅広いタスクに優れています。
Novita AIは、AIの野心を実現するオールインワンクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンスというコスト効率の高いツールを提供します。インフラを排除し、無料で始めて、AIのビジョンを現実にしましょう。



